-
七大常见基于比较的排序算法
七大常见基于比较的排序算法
1.插入排序
1.1直接插入排序
算法介绍:
直接插入排序的基本思想是:把n个待排序的元素看成为一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取下一个元素tmp,从已排序的元素序列从后往前扫描
- 如果该元素大于tmp,则将该元素移到下一位
- 重复步骤3,直到找到已排序元素中小于等于tmp的元素
- tmp插入到该元素的后面,如果已排序所有元素都大于tmp,则将tmp插入到下标为0的位置
- 重复步骤2~5,直到整体已经有序
动图如下:
代码实现
public static void insertSort(int[] array) { //参数判断 if(array == null) return; for (int i = 1; i < array.length; i++) {//从第二个元素开始 int tmp = array[i]; int j = i-1;//for循环结束后还需要tmp赋值 for (; j >= 0 ; j--) {//从后往前开始比较 //如果该元素大于tmp,则将该元素移到下一位 if(array[j] > tmp) { array[j+1] = array[j]; }else { break; } } array[j+1] = tmp; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
分析:初始数据越接近有序,时间效率越高
/** * 时间复杂度: * 最好情况下【有序的情况下】:O(N) * 最坏情况下[无序的时候->逆序的时候]:O(n^2) * 平均情况下(期望的时间):O(n^2) * 空间复杂度:O(1) * 稳定性:稳定的排序 * * 直接插入排序的特点:越有序越快!-》一般插入排序用到一些要优化的地方 * * 记住:一个稳定的排序,可以被实现为不稳定的排序 * 但是本身如果就是一个不稳定的排序,那么 就没办法实现为稳定的排序。 * */快捷判断稳定性:如果再排序的过程当中,没有发生跳跃式的交换,那么就是稳定的排序- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.2折半插入排序
算法优化:折半插入排序
由于插入排序中整个区间被分为有序区间和无序区间,在有序区间中利用折半查找的思想
public static void bsInsertSort(int[] arr){ for(int i=1; i<arr.length; i++){ int v = arr[i];//保存i坐标的值 int left = 0; int right = i; //[left,right) while(left<right){//利用折半查找找到合适的位置,left int m = (left+right)/2; if(v >= arr[m]){ left = m+1; }else{ right = m; } } //从left开始,每个元素向后覆盖,搬移 for(int j=i;j>left;j--){ arr[j] = arr[j-1]; } arr[left] = v;//将对应坐标赋值 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.希尔排序
算法介绍:
希尔排序,是插入排序的一种进阶排序算法,通过一个不断缩小的增量序列,对无序序列反复的进行拆分并且对拆分后的序列使用插入排序的一种算法,所以也叫作“缩小增量排序”或者“递减增量排序”。先分组,组内进行直接插入排序。步骤:
1.先选定一个小于N(最好是素数)的整数gap作为第一增量,然后将所有距离为gap的元素分在同一组,并对每一组的元素进行直接插入排序。然后再取一个比第一增量小的整数作为第二增量,重复上述操作…
2.当增量的大小减到1时,就相当于整个序列被分到一组,进行一次直接插入排序,排序完成。如下15个无序数据

将其分为5,3,1组经5组插入排序后
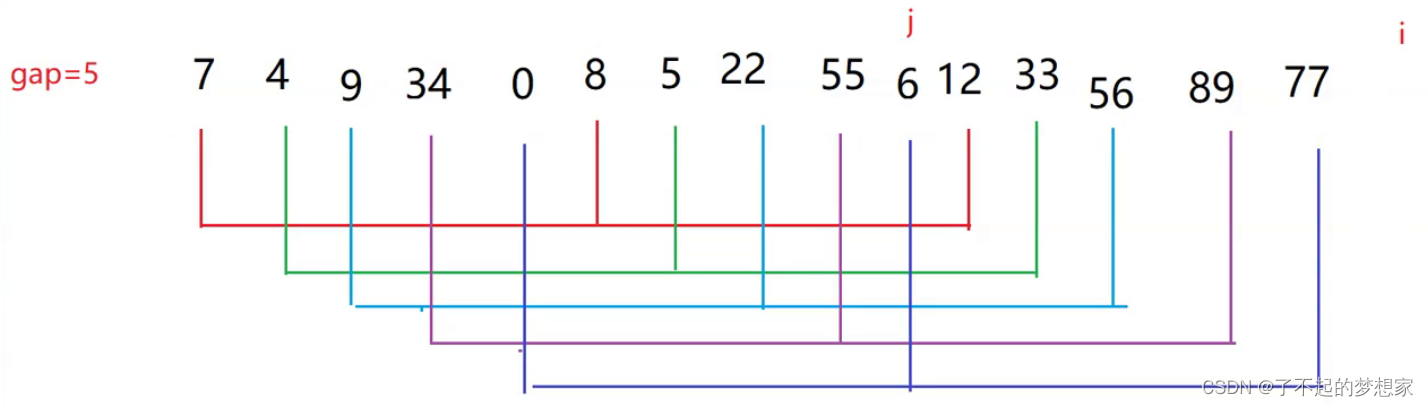
经3组插入排序后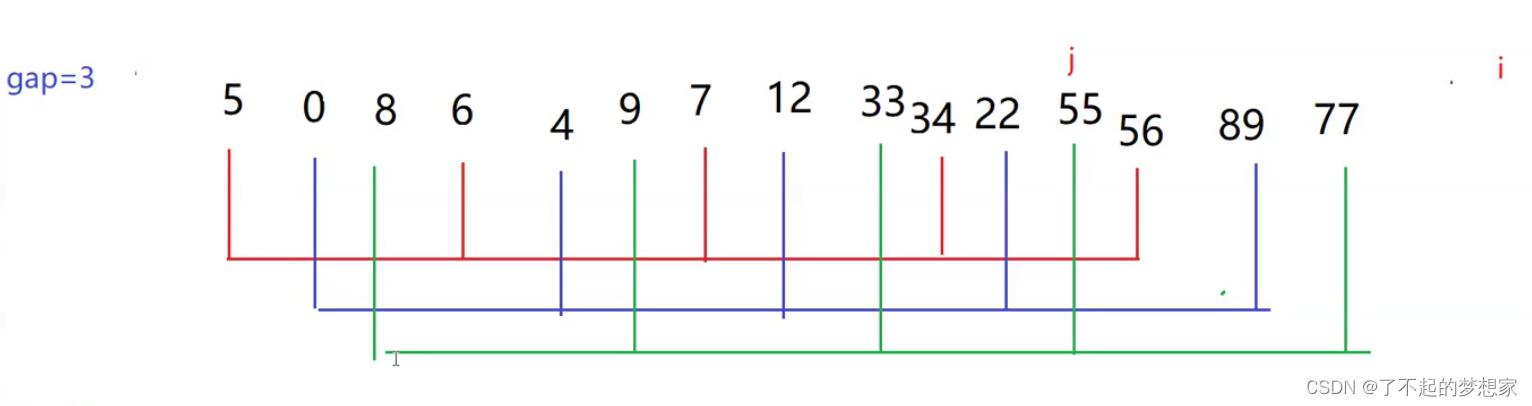
此时整体上已经趋于有序,小数在前,大数在后。
最后就相当于整体进行了直接插入排序10个无序数据的动图如下:

代码实现:
public static void shell(int[] array,int gap) { //参数判断 if(array == null) return; for (int i = gap; i < array.length; i++) { int tmp = array[i]; int j = i-gap; for (; j >= 0 ; j-=gap) { if(array[j] > tmp) {//交换的是距离为gap array[j+gap] = array[j]; }else { break; } } array[j+gap] = tmp; } } public static void shellSort(int[] array) { int gap = array.length-1;//分组组数 while (gap > 1) {//直到gap==1,离开循环 shell(array,gap); gap = gap/2;//每次对gap进行折半操作,直到==1 } shell(array,1);//部分已经有序最后进行一次插入排序 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
分析:
/** * 希尔排序:先分组,组内进行直接插入排序,最后在进行一次插入排序 * 相当于直接插入排序的优化版本 * 时间复杂度:O(N^1.3-1.5) * 空间复杂度:O(1) * 稳定性:不稳定 */- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.选择排序
3.1直接选择排序
思路:
每次从待排序列中选出一个最小值,然后放在序列的起始位置,直到全部待排数据排完即可。动图如下:

代码实现:
public static void selectSort(int[] array){ for(int i=0;i<array.length;i++){ int min = i; for(int j=i+1;j<array.length;j++){ if(array[j]<array[min]){//找到最小元素坐标 min = j; } } if(i!=min){ int tmp = array[i]; array[i] = array[min]; array[min] = tmp; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
/** * 选择排序 * 时间复杂度:O(n^2) 不管有序还是无序的情况 * 空间复杂度:o(1) * 稳定性:不稳定的排序 *原理:每次从无序序列中选出最小元素,放在无序序列中的最前端,直到所有序列排完 * @param array */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2双向选择排序
算法优化:双向选择,我们可以一趟选出两个值,一个最大值一个最小值,然后将其放在序列开头和末尾,这样可以使选择排序的效率快一倍。
public static void selectSortOP(int[] array){ int low = 0; int high = array.length-1; //[low,high] //无序区间只有一个数就可以停止排序了 while(low<=high){ int min = low; int max = low; for(int i=low+1;i<=max;i++){ if(array[i]<array[min]){//找到最小坐标 min = i; } if(array[i]>array[max]){//找到最大坐标 max = i; } } swap(array,min,low); //见下面例子讲解 if(max==low){ max = min; } swap(array,max,high); } } private void swap(int[] array,int i,int j){ int tmp = array[i]; array[i] = array[j]; array[j] = tmp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
//---------------例子讲解----------------
防止最开始因为数据中的max在0坐标,但先交换的min坐标却把0坐标给覆盖了array = { 9, 5, 2, 7, 3, 6, 8};//交换之前 //low = 0; high = 6 //max = 0; min = 2 array = { 2, 5, 9, 7, 3, 6, 8};//将最小的数交换到无序区间的最开始后 //max = 0,但实际上最大的数已经不在 0 位置,而是被交换到 min 即 2 位置了 //所以需要让 max = min 即 max = 2 array = { 2, 5, 8, 7, 3, 6, 9}; //将最大的交换到无序区间的最后结尾后- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.冒泡排序
冒泡排序 重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
思路:
左边大于右边交换一趟排下来最大的在右边动图演示:
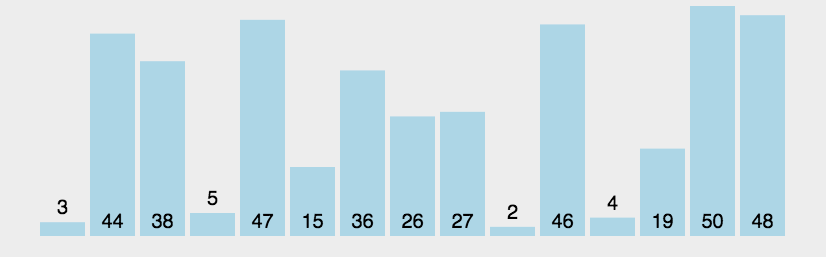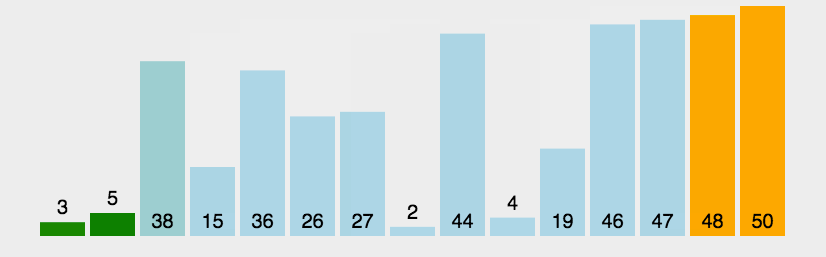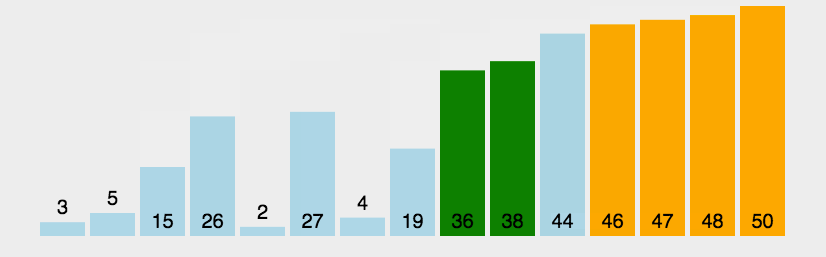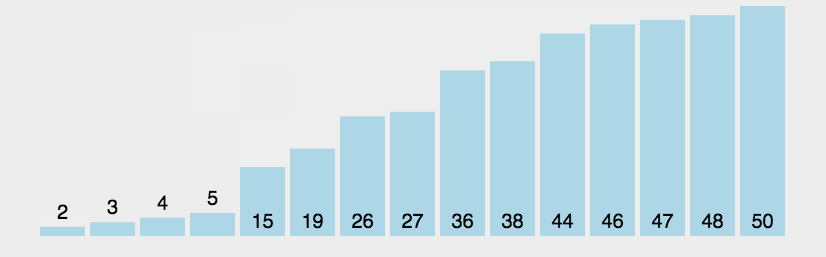
代码实现:
public static void bubbleSort(int[] array) { for (int i = 0; i < array.length-1; i++) { boolean flg = false;//标记,比较过程中是否发生交换 for (int j = 0; j < array.length-1-i; j++) { if(array[j] > array[j+1]) { int tmp = array[j]; array[j] = array[j+1]; array[j+1] = tmp; flg = true; } } if(flg == false) {//若没有发生交换说明已经有序 break; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
/** * 冒泡排序 * 原理:在无序区间内,通过相邻数的比较将最大的数字排序到最后,直到整体上有序 * 时间复杂度:O(N^2) * 空间复杂度:O(1) * 稳定性:稳定的排序 */- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.堆排序
类似于选择排序
堆排序的基本思想是:- 将待排序序列构造成一个堆(升序排序用大根堆,若降序排序采用小根堆),
- 此时,整个序列的最大值就是堆顶的根节点。
- 将堆顶元素与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
如图所示:
步骤一:构建初始堆,将一个无序序列构造成一个大根堆(升序采用大根堆,将需采用小根堆)
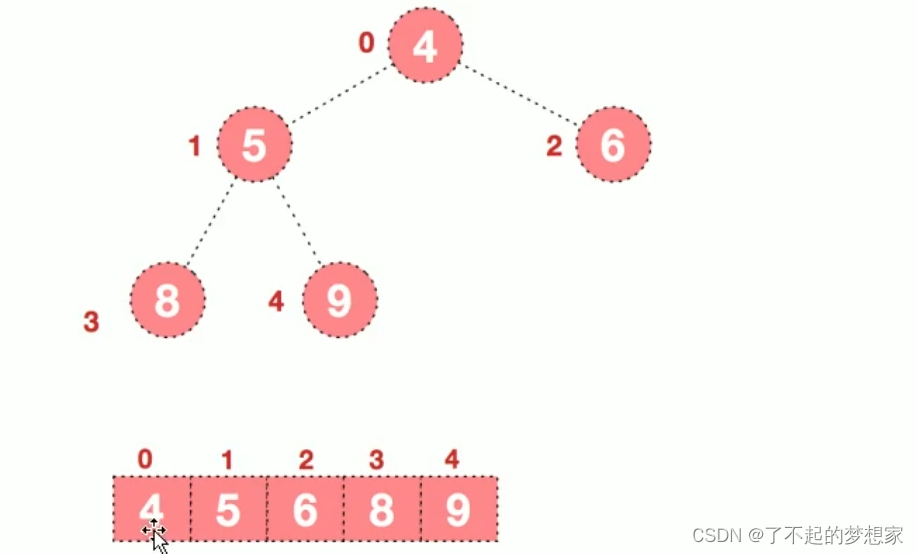
1.假定给定的无序序列结构如下
arr [4,6,8,5,9]
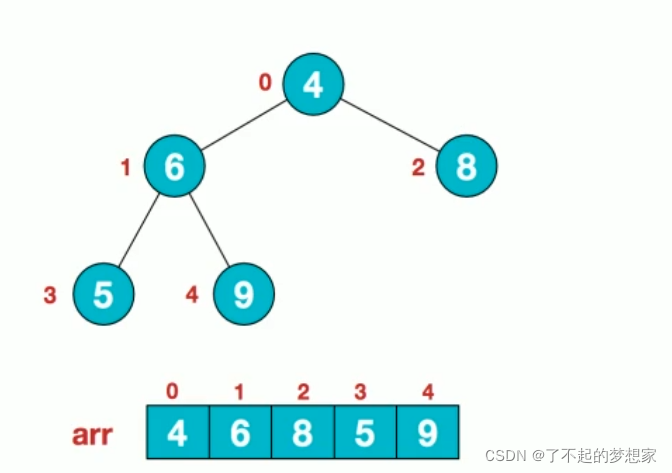
2.此时我们从最后一个非叶子节点开始(叶子结点不用调整,第一个非叶子节点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从上至下进行调整。
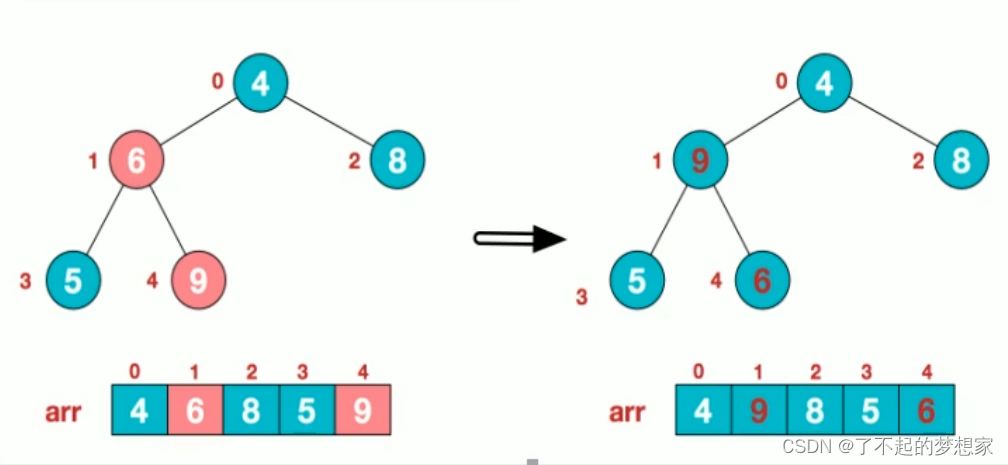
3.找到第二个非叶子节点4,由于[4,9,8]中9元素最大,4和9交换
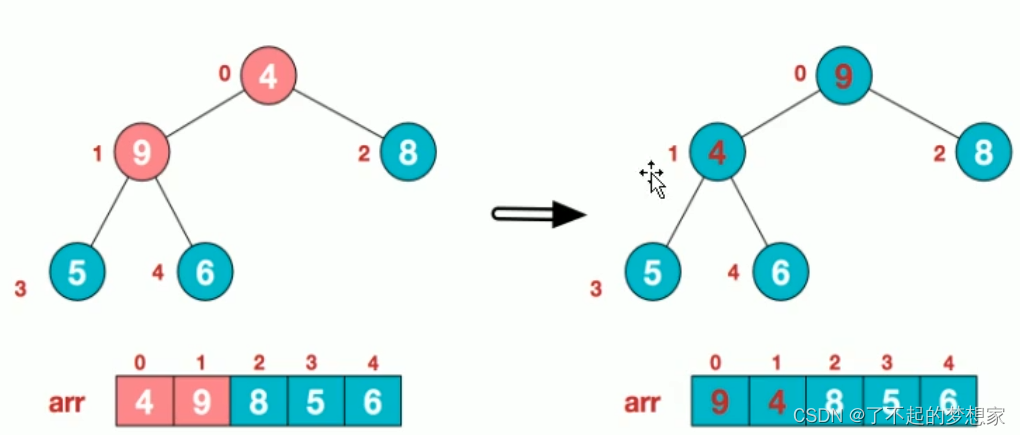
4.这时,交换导致了子根[4,5,6]结构混乱继续调整,[4,5,6]中6最大,交换4和6

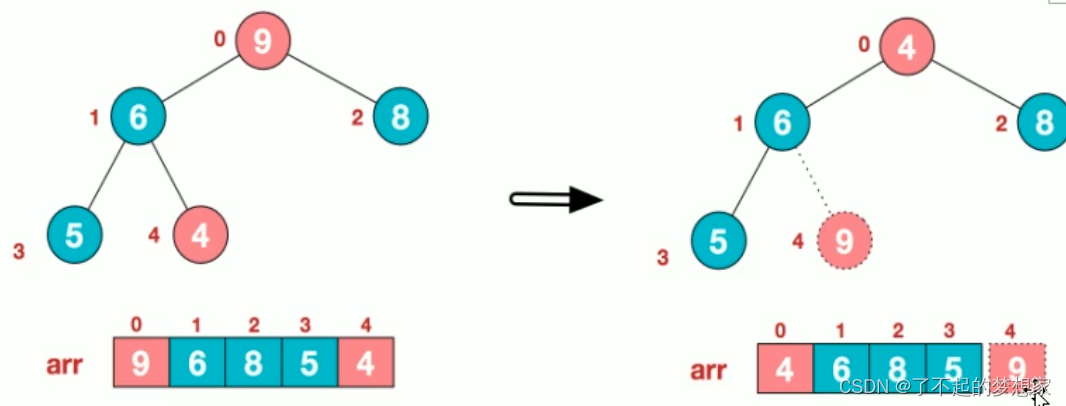
此时,我们就将一个无序序列构造成了一个大根堆。步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大,然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素,如此反复进行交换重建,交换。
1.将堆顶元素9和末尾元素4进行交换
2.重新调整结构,使其继续满足堆定义
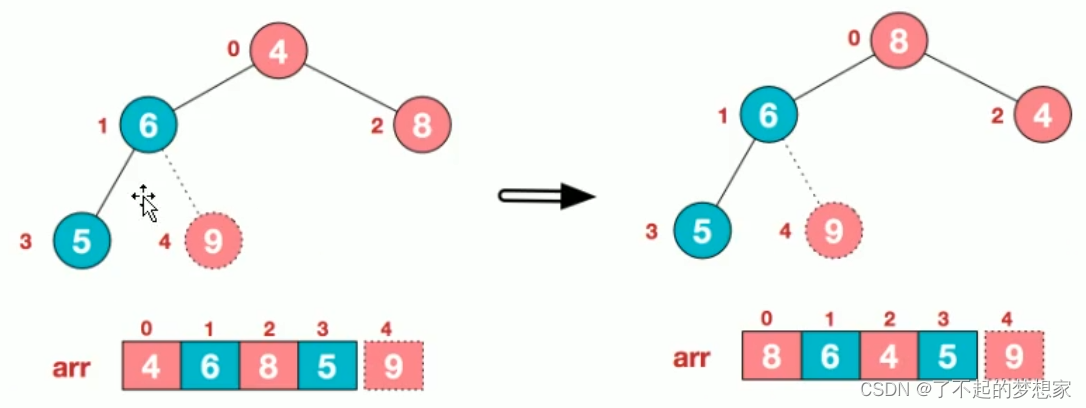
3.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8
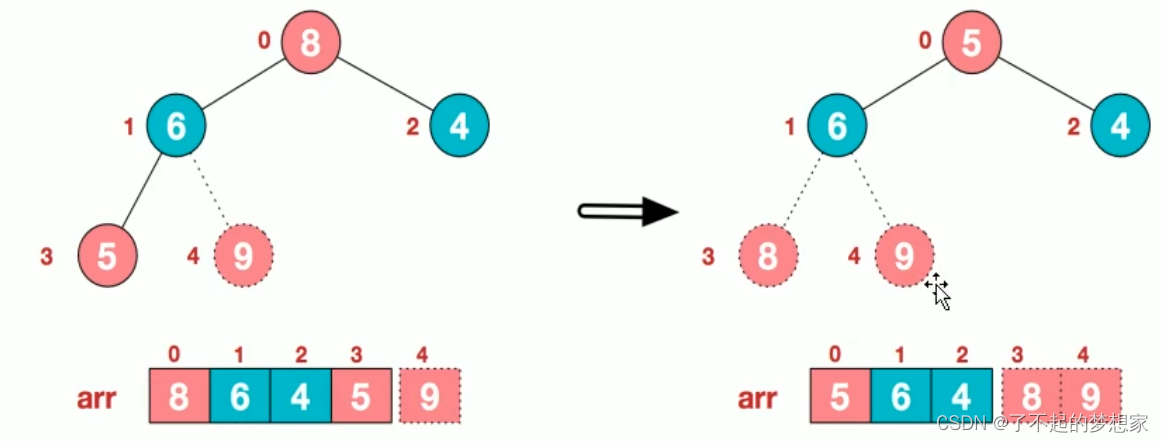
4.后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
代码示例:
//堆排序 public static void heapSort(int[] array) { createBigHeap(array);//建一个大根堆 int end = array.length-1; while (end > 0) { int tmp = array[0]; array[0] = array[end]; array[end] = tmp; shiftDown(array,0,end); end--; } } //建一个大根堆 public static void createBigHeap(int[] array) { // for (int i = (array.length-1-1)/2; i >= 0 ; i--) { shiftDown(array,i,array.length); } } public static void shiftDown(int[] array,int parent,int len) { int child = 2*parent+1; while (child < len) { if(child+1 < len && array[child] < array[child+1]) { child++; } //child下标 表示的就是左右孩子最大值的下标 if(array[child] > array[parent]) { int tmp = array[child]; array[child] = array[parent]; array[parent] = tmp; }else { break; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
分析:
堆排序是一种选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n-1),log2(n-2)…1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)级。
6.快速排序
6.1快速排序
算法思路:
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。步骤:
-
首先设定一个分界值,通过该分界值将数组分成左右两部分。
-
将大于或等于的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
-
然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
-
重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
概括来说为 挖坑填数 + 分治法。
整体过程的动画展示
我们借用五分钟学算法的gif动图,感谢五分钟学算法。
L代表左,R代表右,P代表基准值

代码实现:
//找到基准值,挖坑法 public static int partition(int[] array,int start,int end) { int tmp = array[start];//直接选择第一个作为基准值 while (start < end) { //1、先判断后面 while (start < end && array[end] >= tmp) { end--; } //1.1 后面的给start array[start] = array[end] array[start] = array[end]; //2、再判断前边 while (start < end && array[start] <= tmp) { start++; } //2.1 把这个大的给end array[end] = array[start] array[end] = array[start]; } array[start] = tmp; return start; } public static void quick(int[] array,int left,int right) { if(left >= right) { return; } //找基准值 int pivot = partition(array,left,right); quick(array,left,pivot-1);//递归左边 quick(array,pivot+1,right);//递归右边 } public static void quickSort1(int[] array) {//让参数更统一 quick(array,0,array.length-1); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
算法分析:
/**
* 快速排序:
* 1.从待排序区间选择一个数作为基准值
* 2.Partition:遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值达的(可以包含相等的)
* 放到基准值的右边
* 3.采用分治思想,对左右两个小区按照同样的方式处理,直到小区间的长度== 1,代表已经有序,或者小区间的长度==0,代表没有数据
* 时间复杂度:O(n*logn)
* 空间复杂度:O(logn)
* 稳定性:不稳定
* @param array
*/6.2快排的优化—三数取中
三数取中(median-of-three)(优化有序的数据)
引入的原因:虽然随机选取枢轴时,减少出现不好分割的几率,但是还是最坏情况下还是O(n^2),要缓解这种情况,就引入了三数取中选取枢轴
分析:最佳的划分是将待排序的序列分成等长的子序列,最佳的状态我们可以使用序列的中间的值,也就是第N/2个数。可是,这很难算出来,并且会明显减慢快速排序的速度。这样的中值的估计可以通过随机选取三个元素并用它们的中值作为枢纽元而得到。事实上,随机性并没有多大的帮助,因此一般的做法是使用左端、右端和中心位置上的三个元素的中值作为枢纽元。显然使用三数中值分割法消除了预排序输入的不好情形,并且减少快排大约14%的比较次数
举例:待排序序列为:8 1 4 9 6 3 5 2 7 0
左边为:8,右边为0,中间为6.
我们这里取三个数排序后,中间那个数作为枢轴,则枢轴为6
注意:在选取中轴值时,可以从由左中右三个中选取扩大到五个元素中或者更多元素中选取,一般的,会有(2t+1)平均分区法(median-of-(2t+1),三平均分区法英文为median-of-three)。
具体思想:对待排序序列中left、mid、right三个位置上数据进行排序,取他们中间的那个数据作为枢轴,并用0下标元素存储枢轴。
代码实现:
//优化基准值,三数取中,使待排序序列均匀的分割 //确保最后的顺序:array[mid] <= array[left] <= array[right] public static void medianOfThree(int[] array,int left,int right) { int mid = (left+right)/2; if(array[mid] > array[left]) { int tmp = array[mid]; array[mid] = array[left]; array[left] = tmp; }//array[mid] <= array[left] if(array[left] > array[right]) { int tmp = array[left]; array[left] = array[right]; array[right] = tmp; }//array[left] <= array[right] if(array[mid] > array[right]) { int tmp = array[mid]; array[mid] = array[right]; array[right] = tmp; } //array[mid] <= array[left] <= array[right] } //优化排序,当快速排序排到一个区间后,部分已经有序,进行直接插入排序 public static void insertSort2(int[] array,int left,int right) { //参数判断 if(array == null) return; for (int i = left+1; i <= right; i++) { int tmp = array[i]; int j = i-1; for (; j >= left ; j--) { if(array[j] > tmp) { array[j+1] = array[j]; }else { break; } } array[j+1] = tmp; } } //找到基准值,挖坑法 public static int partition(int[] array,int start,int end) { int tmp = array[start];//直接选择第一个作为基准值 while (start < end) { //1、先判断后面 while (start < end && array[end] >= tmp) { end--; } //1.1 后面的给start array[start] = array[end] array[start] = array[end]; //2、再判断前边 while (start < end && array[start] <= tmp) { start++; } //2.1 把这个大的给end array[end] = array[start] array[end] = array[start]; } array[start] = tmp; return start; } public static void quick(int[] array,int left,int right) { if(left >= right) { return; } //递归执行到一个区间之后 进行直接插入排序 if((right - left + 1) <= 100) { insertSort2(array,left,right); return;// } //三数取中法 medianOfThree(array,left,right); int pivot = partition(array,left,right); quick(array,left,pivot-1);//左边递归 quick(array,pivot+1,right);//右边递归 } public static void quickSort(int[] array) { quick(array,0,array.length-1); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
想要更加深入了解快排的优化,点击这里快速排序优化
7.归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法,归并排序对序列的元素进行逐层折半分组,然后从最小分组开始比较排序,合并成一个大的分组,逐层进行,最终所有的元素都是有序的。
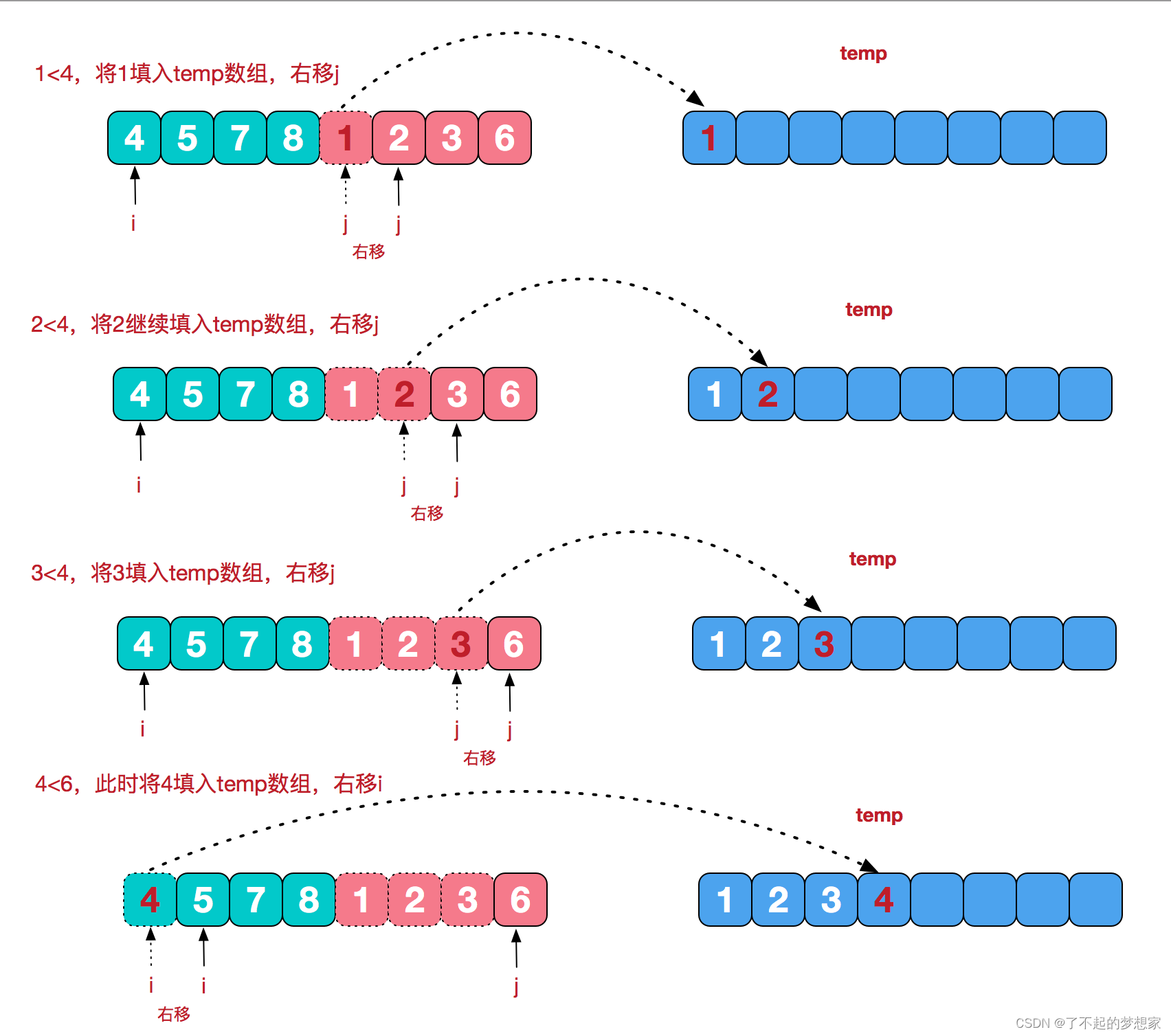
思路:先拆分,后合并
如下图所示:

拆分是每次把数组拆分成一半。
合并是把两个数组合并成一个数组,在合并时较小数值先填入,从而达到有序。如下图所示:

代码实现:
//拆分 public static void mergeSortInternal(int[] array,int left,int right) { if(left >= right) {//left和right相遇就返回 return; } int mid = (left+right)/2;//取中间坐标 mergeSortInternal(array,left,mid);//拆分左边 mergeSortInternal(array,mid+1,right);//拆分右边 merge(array,left,right,mid);//并到一起 } //合并 public static void merge(int[] array,int left,int right,int mid) { int[] tmp = new int[right-left+1]; int k = 0; int s1 = left; int e1 = mid; int s2 = mid+1; int e2 = right; while (s1 <= e1 && s2 <= e2) { if(array[s1] <= array[s2]) { tmp[k++] = array[s1++]; }else { tmp[k++] = array[s2++]; } } while (s1 <= e1) { tmp[k++] = array[s1++]; } while (s2 <= e2) { tmp[k++] = array[s2++]; } for (int i = 0; i < k; i++) { //排好序的数字 放到原数组合适的位置 array[i+left] = tmp[i];//数组添入坐标不是固定的 } } public static void mergeSort(int[] array) { mergeSortInternal(array,0,array.length-1); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
-
相关阅读:
西北工业大学遭境外电邮攻击
STM32微控制 -STM32命名规则-STM32寄存器缩写列表-STM32存储器和总线架构
Linux_文件权限
教师资格证报名浏览器不兼容 - 解决方案
R语言ggplot2可视化分面折线图:使用facet_wrap函数可视化分面折线图、color参数和size参数自定义线条的颜色和宽度粗细
MongoDB 全方位知识图谱
【附源码】计算机毕业设计JAVA郑工社团交流服务信息平台
【21天Python进阶学习挑战赛】[day9]操作MongoDB数据库
stm32 cubeide ad转换与串口问题
C#:实现Google S2算法(附完整源码)
- 原文地址:https://blog.csdn.net/m0_57105290/article/details/122796707
