-
【半监督图像分割】2021-CPS CVPR
【半监督图像分割】2021-CPS CVPR
论文题目:Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
中文题目:基于交叉伪监督的半监督语义分割
论文链接:https://arxiv.org/abs/2106.01226v2
论文代码:https://github.com/charlesCXK/TorchSemiSeg
发表时间:2021年6月
引用:Chen X, Yuan Y, Zeng G, et al. Semi-supervised semantic segmentation with cross pseudo supervision[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 2613-2622.
引用数:157
1. 简介
1.1 简介
在这篇论文中,我们为半监督语义分割任务设计了一种非常简洁而又性能很好的算法:cross pseudo supervision (CPS)。训练时,我们使用两个相同结构、但是不同初始化的网络,添加约束使得两个网络对同一样本的输出是相似的。具体来说,当前网络产生的one-hot pseudo label,会作为另一路网络预测的目标,这个过程可以用cross entropy loss监督,就像传统的全监督语义分割任务的监督一样。我们在两个benchmark (PASCAL VOC, Cityscapes) 都取得了SOTA的结果。
1.2 相关工作
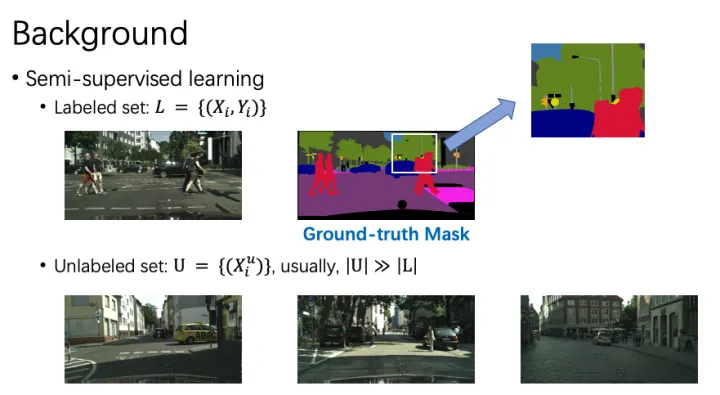
在最开始,我们先来回顾一下半监督语义分割任务的相关工作。不同于图像分类任务,数据的标注对于语义分割任务来说是比较困难而且成本高昂的。我们需要为图像的每一个像素标注一个标签,包括一些特别细节的物体,比如下图中的电线杆 (Pole)。但是,我们可以很轻松的获得RGB数据,比如摄像头拍照。那么,如何利用大量的无标注数据去提高模型的性能,成为半监督语义分割领域研究的问题。
我们将半监督分割的工作总结为两种:self-training和consistency learning。一般来说,self-training是离线处理的过程,而consistency learning是在线处理的。
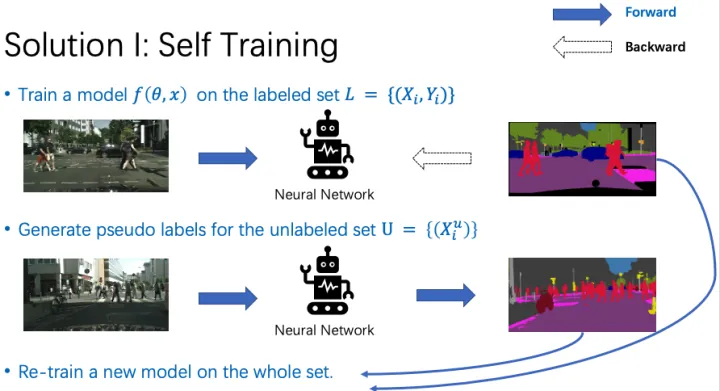
(1)Self-training
Self-training主要分为3步。第一步,我们在有标签数据上训练一个模型。第二步,我们用预训练好的模型,为无标签数据集生成伪标签。第三步,使用有标注数据集的真值标签,和无标注数据集的伪标签,重新训练一个模型。
(2)Consistency learning
Consistency learning的核心idea是:鼓励模型对经过不同变换的同一样本有相似的输出。这里“变换”包括高斯噪声、随机旋转、颜色的改变等等。
Consistency learning基于两个假设:smoothness assumption 和 cluster assumption。
- Smoothness assumption: samples close to each other are likely to have the same label.
- Cluster assumption: Decision boundary should lie in low-density regions of the data distribution.
Smoothness assumption就是说靠的近的样本通常有相同的类别标签。比如下图里,蓝色点内部距离小于蓝色点和棕色点的距离。Cluster assumption是说,模型预测的决策边界,通常处于样本分布密度低的区域。怎么理解这个“密度低”?我们知道,类别与类别之间的区域,样本是比较稀疏的,那么一个好的决策边界应该尽可能处于这种样本稀疏的区域,这样才能更好地区分不同类别的样本。例如下图中有三条黑线,代表三个决策边界,实线的分类效果明显好于另外两条虚线,这就是处于低密度区域的决策边界。

那么,consistency learning是如何提高模型效果的呢?在consistency learning中,我们通过对一个样本进行扰动(添加噪声等等),即改变了它在feature space中的位置。但我们希望模型对于改变之后的样本,预测出同样的类别。这个就会导致,在模型输出的特征空间中,同类别样本的特征靠的更近,而不同类别的特征离的更远。只有这样,扰动之后才不会让当前样本超出这个类别的覆盖范围。这也就导致学习出一个更加compact的特征编码。
当前,Consistency learning主要有三类做法:mean teacher,CPC,PseudoSeg。

Mean teacher是17年提出的模型。给定一个输入图像X,添加不同的高斯噪声后得到X1和X2。我们将X1输入网络f(θ)中,得到预测P1;我们对f(θ)计算EMA,得到另一个网络,然后将X2输入这个EMA模型,得到另一个输出P2。最后,我们用P2作为P1的目标,用MSE loss约束。
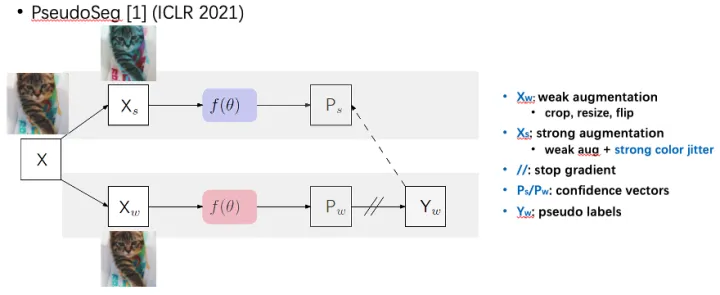
PseudoSeg是google发表在ICLR 2021的工作。他们对输入的图像X做两次不同的数据增强,一种“弱增强”(random crop/resize/flip),一种“强增强”(color jittering)。他们将两个增强后图像输入同一个网络f(θ),得到两个不同的输出。因为“弱增强”下训练更加稳定,他们用“弱增强”后的图像作为target。

CPC是发表在ECCV 2020的工作(Guided Collaborative Training for Pixel-wise Semi-Supervised Learning)的简化版本。在这里,我只保留了他们的核心结构。他们将同一图像输入两个不同网络,然后约束两个网络的输出是相似的。这种方法虽然简单,但是效果很不错。
1.3 创新
从上面的介绍我们可以简单总结一下:
- Self-training可以通过pseudo labelling扩充数据集。
- CPC可以通过consistcency learning,鼓励网络学习到一个更加compact的特征编码。
大家近年来都focus在consistency learning上,而忽略了self-training。实际上,我们实验发现,self-training在数据量不那么小的时候,性能非常的强。那么我们很自然的就想到,为什么不把这两种方法结合起来呢?于是就有了我们提出的CPS:cross pseudo supervision。
2. 网络
2.1 网络架构
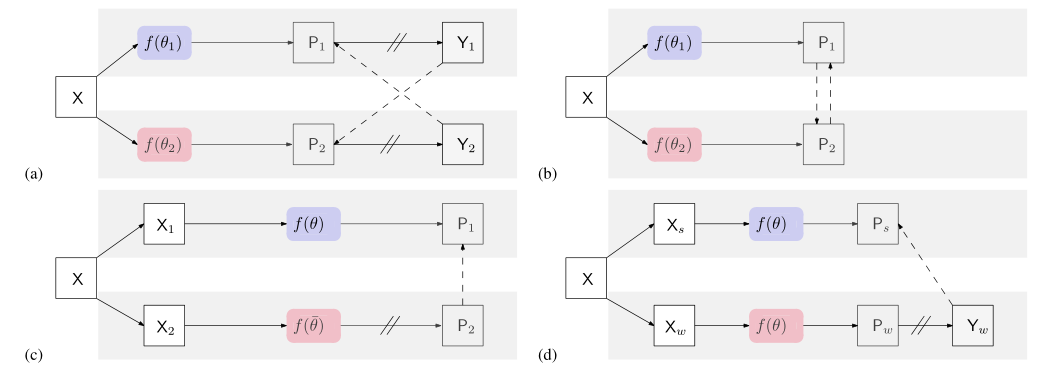
- a) 本论文网络结构图CPS,叙述如上
- b) GCT网络结构图,和本方法相同,唯一的区别在于GCT使用confidence map作为监督信号,而CPS使用one-hot label
- c)MeanTeacher 使用学生网络和老师网络,两个网络结构相同,参数初始化不同,学生网络用老师网络得到的confidence map作为监督信号,老师网络随着学生网络的权重变化按照指数平均不断变化
- d)一张原图X分别经过弱数据增强和强数据增强放入同一个网络中,弱数据增强所得one hot结果作为强数据增强结果的真值,用于监督弱数据增强的结果
我们可以看到,CPS的设计非常的简洁。训练时,我们使用两个网络f(θ1) 和 f(θ2)。这样对于同一个输入图像X,我们可以有两个不同的输出P1和P2。我们通过argmax操作得到对应的one-hot标签Y1和Y2。类似于self-training中的操作,我们将这两个伪标签作为监督信号。举例来说,我们用Y2作为P1的监督,Y1作为P2的监督,并用cross entropy loss约束。
对于这两个网络,我们使用相同的结构,但是不同的初始化。我们用PyTorch框架中的kaiming_normal进行两次随机初始化,而没有对初始化的分布做特定的约束。
2.2 Loss
给定有标签的数据集 D L D^L DL,大小为 N N N 。和 M M M个未标记的图像 D u D^u Du
半监督语义分割任务的目标是通过对标记图像和未标记图像来学习分割网络
P 1 = f ( X ; θ 1 ) P 2 = f ( X ; θ 2 )
P1=f(X;θ1)P2=f(X;θ2)P 1 = f ( X ; θ 1 ) P 2 = f ( X ; θ 2 ) 这两个网络具有相同的结构, θ 1 \theta_{1} θ1和 θ 2 \theta_{2} θ2分别表示对应的权重,初始化的方式不同。输入X具有相同的数据增强方式,P1 ,P2为分割confidence map,为softmax归一化后的网络输出。本文的主要思想通过以下的方式表达:
X → X → f ( θ 1 ) → P 1 → Y 1 X → X → f ( θ 2 ) → P 2 → Y 2X→X→f(θ1)→P1→Y1X→X→f(θ2)→P2→Y2X → X → f ( θ 1 ) → P 1 → Y 1 X → X → f ( θ 2 ) → P 2 → Y 2
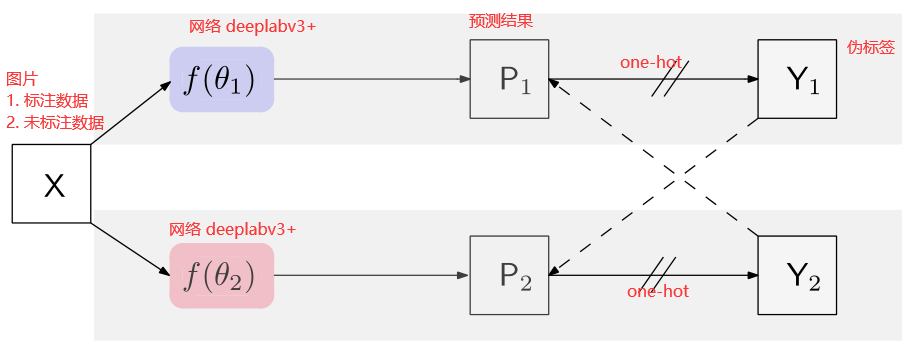
P 1 , P 2 P_1,P_2 P1,P2表示预测结果。 Y 1 , Y 2 Y_1,Y_2 Y1,Y2伪分割图
流程上图所示。训练过程包括
两个损失:监督损失L s L_s Ls,交叉伪监督损失L c p s L_{cps} Lcps监督损失使用Cross entropy。
L s L_s Ls是两个模型的
有监督损失
L s = 1 ∣ D l ∣ ∑ X ∈ D l 1 W × H ∑ i = 0 W × H ( ℓ c e ( p 1 i , y 1 i ∗ ) + ℓ c e ( p 2 i , y 2 i ∗ ) ) ,Ls=∣Dl∣1∑X∈DlW×H1∑i=0W×H(ℓce(p1i,y1i∗)+ℓce(p2i,y2i∗)),L s = 1 | D l | ∑ X ∈ D l 1 W × H ∑ i = 0 W × H ( ℓ c e ( p 1 i , y 1 i ∗ ) + ℓ c e ( p 2 i , y 2 i ∗ ) ) ,
交叉伪监督损失是双向的:一个是从 f ( θ 1 ) f(\theta_1) f(θ1)到 f ( θ 2 ) f(\theta_2) f(θ2),使用 Y 1 Y_1 Y1来监督 P 2 P_2 P2,另一个是使用 Y 2 Y_2 Y2监督 P 1 P_1 P1。损失表示为
L c p s u = 1 ∣ D u ∣ ∑ X ∈ D u 1 W × H ∑ i = 0 W × H ( ℓ c e ( p 1 i , y 2 i ) + ℓ c e ( p 2 i , y 1 i ) ) .Lcpsu=∣Du∣1∑X∈DuW×H1∑i=0W×H(ℓce(p1i,y2i)+ℓce(p2i,y1i)).L c p s u = 1 | D u | ∑ X ∈ D u 1 W × H ∑ i = 0 W × H ( ℓ c e ( p 1 i , y 2 i ) + ℓ c e ( p 2 i , y 1 i ) ) .
以同样的方式定义了有标记数据上的交叉伪监督损失. L c p s l , L c p s = L c p s l + L c p s u L_{cps}^l,L_{cps}=L_{cps}^l+L_{cps}^u Lcpsl,Lcps=Lcpsl+Lcpsu最后损失为 L = L s + L c p s L=L_s+L_{cps} L=Ls+Lcps
应用CutMix augmentation图像增强方法来进行数据增强。
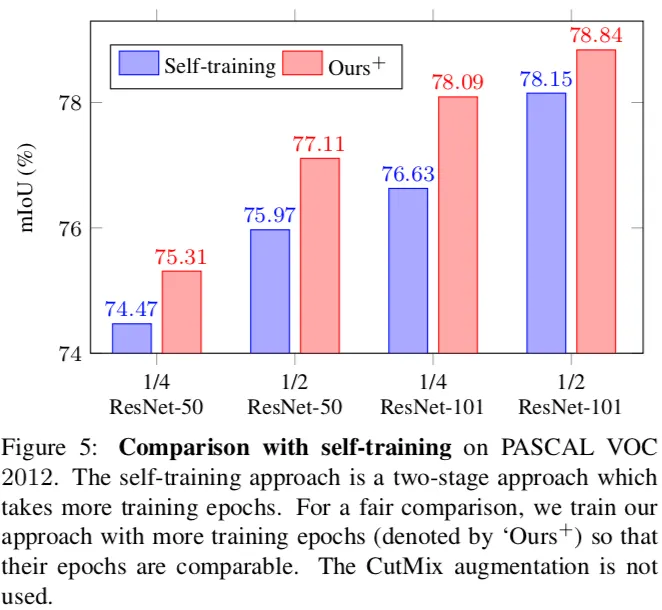
2.3 实验
a,b图分别使用ResNet50,ResNet101作为backbone
蓝:baseline(不加入cutmix数据增强):只使用有标签的数据
红:使用两个网络,半监督学习,不加入cutmix数据增强
绿:使用两个网络,半监督学习,加入cutmix数据增强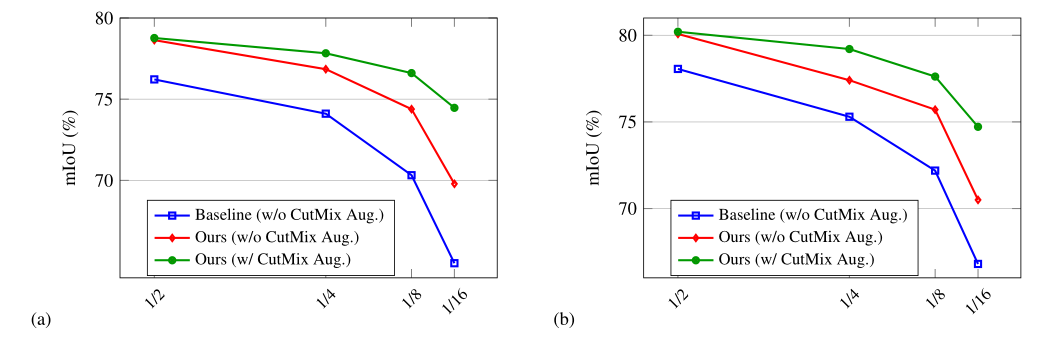
首先是有标签数据比较少的情况。
我们的方法在VOC和Cityscapes两个数据集的几种不同的数据量情况下都达到了SOTA。表格中 1/16, 1/4等表示用原始训练集的 1/16, 1/4作为labeled set,剩余的 15/16, 3/4作为unlabeled set。
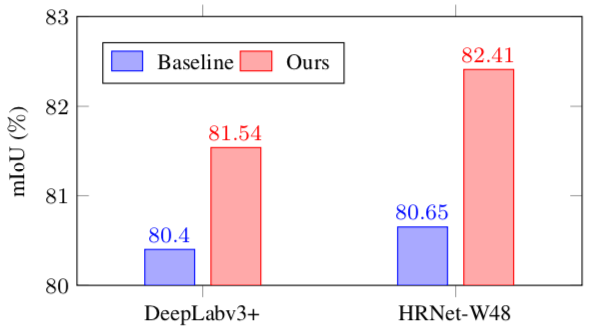
Table1:在Pascal VOC上使用不同backbone和不同有标签数据比例得到结果和其他SOTA方法对比
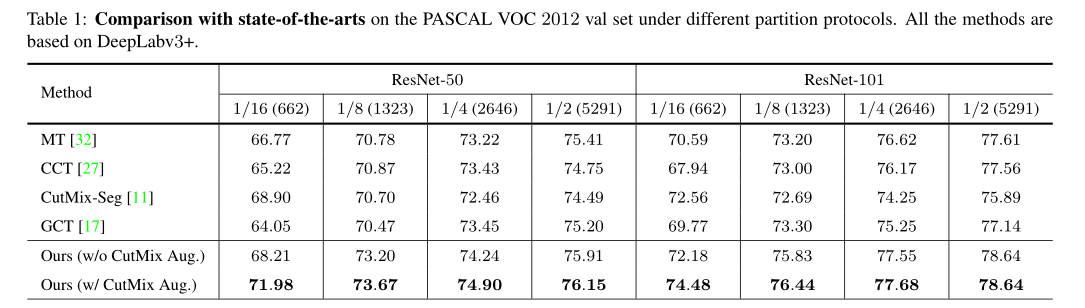
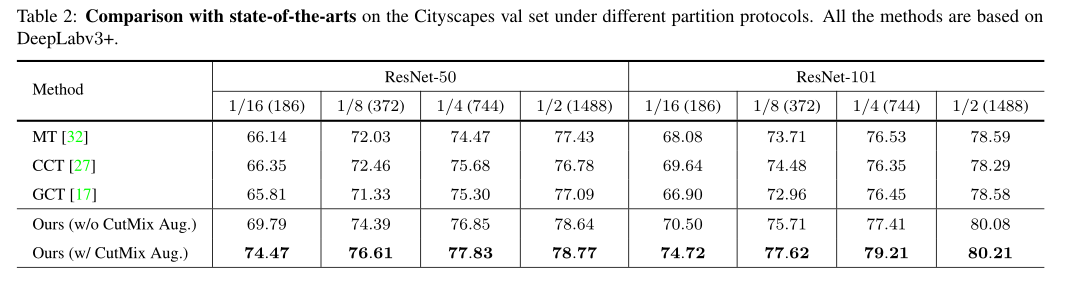
Table2:在Cityscapes上使用不同backbone和不同有标签数据比例得到结果和其他SOTA方法对比
在跟PseudoSeg的对比中,和他们同样的数据划分list,我们也超越了他们的性能:
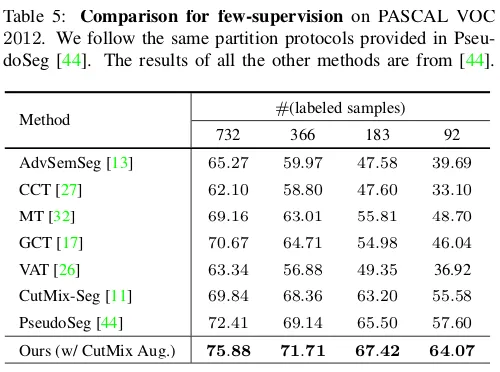
这是我们的方法跟self-training进行比较的结果。可以看到,我们的方法由于鼓励模型学习一个更加compact的特征编码,显著地优于self-training。
对于这两个网络,我们使用相同的结构,但是不同的初始化。我们用PyTorch框架中的kaiming_normal进行两次随机初始化,而没有对初始化的分布做特定的约束。
3. 代码
- 1
参考资料
-
相关阅读:
全链路压测:构建三大模型
Springboot中上一个定时任务没执行完,是否会影响下一个定时任务执行分析及结论
Mathematica 语言程序设计
嵌入式设计与开发项目-液位检测告警系统
国际十大优质期货投资app软件最新排名(综合版)
redis-cluster搭建及拓扑刷新java测试
华为云云耀云服务器L实例评测|使用Docker部署Leanote笔记工具
编译和链接
wangEditor 粘贴从 word 复制的带图片内容的最佳实践
备份系统运行数据采集及分析方法
- 原文地址:https://blog.csdn.net/wujing1_1/article/details/127960059