-
5.python 列表切片双冒号[: :]和[:,j]
1.[::]
适用于Python中的list(也就是数组),也适用于numpy科学结构(array等)。
使用方法[start: end : step ],也就是[ 起始下标 : 终止下标 : 间隔距离 ]
切片范围是: start <= x < end,注意:一个小于等于,一个小于。
- 例1
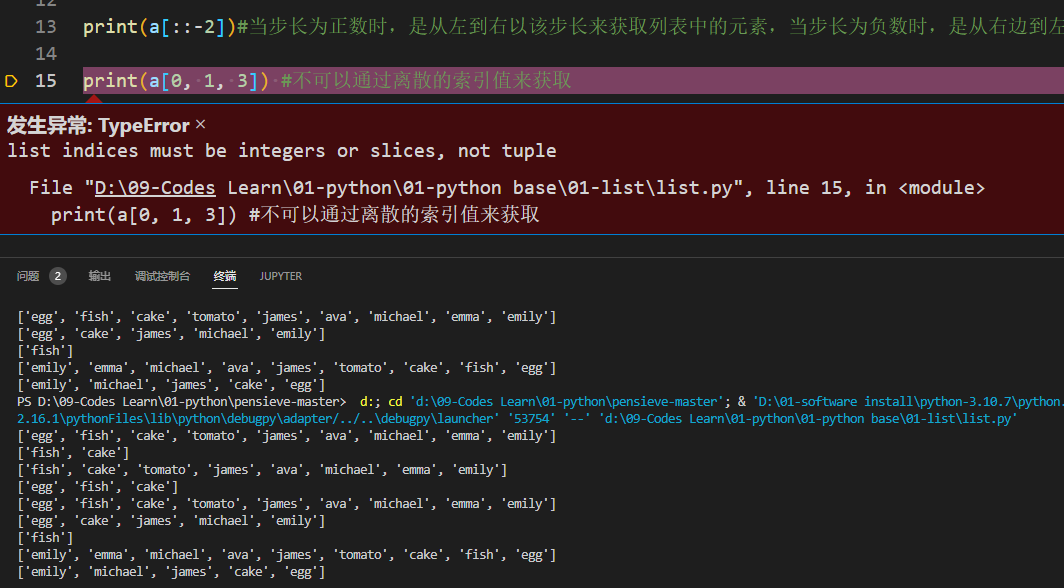
a=['egg', 'fish', 'cake', 'tomato', 'james', 'ava', 'michael', 'emma', 'emily'] print(a[1:3]) #按下标0开始,不包括最右边的3 print(a[1:]) #1以及之后的全部 print(a[:3]) #3之前的但不包括3 print(a[:]) #所有 print(a[::2])#[start:end:step]start和end为空的时候,默认是全选,step为空时默认是1,这个表示的是从索引为0开始,以步长为2来选择元素 print(a[1:3:2])#以索引为1开始,索引3结束,步长为2来选择元素 print(a[::-1])#当step为-1时,将列表进行了逆序排序 print(a[::-2])#当步长为正数时,是从左到右以该步长来获取列表中的元素,当步长为负数时,是从右边到左以该步长的绝对值来获取的元素 print(a[0, 1, 3]) #不可以通过离散的索引值来获取,type error- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出
['egg', 'fish', 'cake', 'tomato', 'james', 'ava', 'michael', 'emma', 'emily'] ['fish', 'cake'] ['fish', 'cake', 'tomato', 'james', 'ava', 'michael', 'emma', 'emily'] ['egg', 'fish', 'cake'] ['egg', 'fish', 'cake', 'tomato', 'james', 'ava', 'michael', 'emma', 'emily'] ['egg', 'cake', 'james', 'michael', 'emily'] ['fish'] ['emily', 'emma', 'michael', 'ava', 'james', 'tomato', 'cake', 'fish', 'egg'] ['emily', 'michael', 'james', 'cake', 'egg']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 例2
a = [[1,2,3,4],[2,3,4,5],[5,6,7,8]] # a是Python的一个列表(数据结构上叫做数组) print(a) # 例子1 print(a[:2]) # 例子2 print(a[1][:3])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
输出
[[1, 2, 3, 4], [2, 3, 4, 5], [5, 6, 7, 8]] [[1, 2, 3, 4], [2, 3, 4, 5]] [2, 3, 4]- 1
- 2
- 3
2.[ :,j]
这也是切片操作,不同的是:保留第一个维度所有元素,第二维度元素保留到j;
只适用numpy的科学数据结构- 例3
import numpy as np # b是一个numpy科学数据结构,格式是array b = np.array([[1,2,3,4],[2,3,4,5],[5,6,7,8]]) print(b) # 例子1 print(b[:,2]) # 例子2 print(b[:,3]) # 非numpy数据结构的例子不能使用 [:,j] x=list([[1, 2, 3, 4], [2, 3, 4, 5], [5, 6, 7, 8]]) print(x) # 例子3 print(x[:, :2]) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-5-4b22ebda2101> in <module>() ----> 1 x[:,:2] TypeError: list indices must be integers or slices, not tuple- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出
[[1 2 3 4] [2 3 4 5] [5 6 7 8]] [3 4 7] [4 5 8] [[1, 2, 3, 4], [2, 3, 4, 5], [5, 6, 7, 8]]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 例4
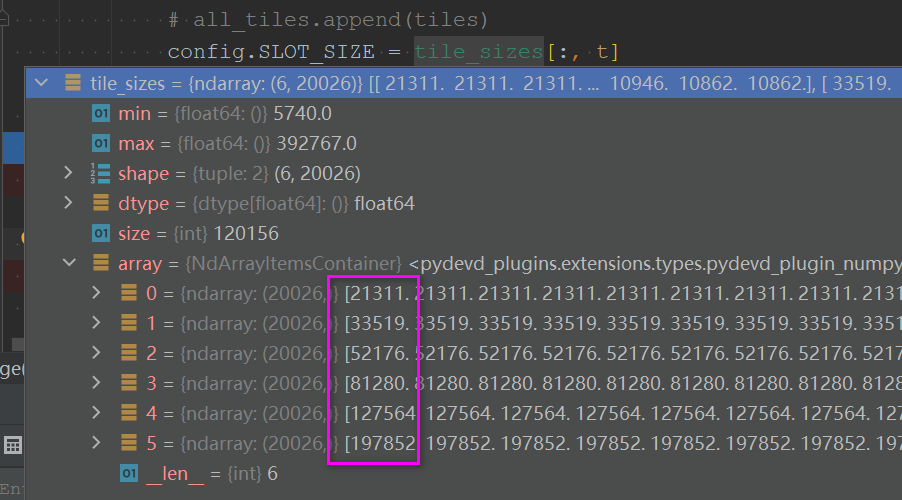
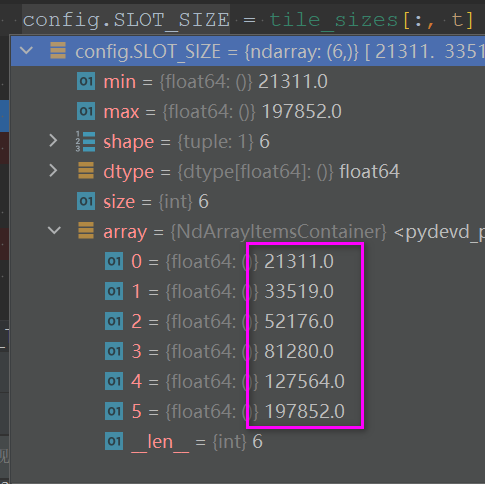
labels = [] # prepare the network trace for each user in this round net_traces = [] for trace_file in trace_files[k]: user_trace = [] with open(trace_file) as f: lines = f.readlines() duration = 0 t = 0 # random.shuffle(lines) for line in lines: tokens = line.split(' ') temp_duration = int(tokens[5]) throughput = tokens[4] throughput_MB = float(int(throughput) / 1e6) while (t + 1) * config.TIME_INTERVAL - duration < temp_duration: # add some variance # user_trace.append(max(throughput_MB + np.random.normal(0,throughput_MB/10),1.356)) # without variance user_trace.append(throughput_MB) t += 1 duration = t * config.TIME_INTERVAL if t >= config.T: break net_traces.append(user_trace[:int(config.T)]) net_traces = np.array(net_traces) ................. ................. for t in range(int(config.T)): config.SLOT_SIZE = tile_sizes[:, t]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出调试
tile_sizes
config.SLOT_SIZE
3. [::]操作高阶用法
- 例5
# 关于array的科学数据 In [5]: x = np.random.randint(1,10,(3,6)) In [6]: x Out[6]: array([[9, 3, 2, 3, 8, 4], [3, 5, 6, 8, 4, 3], [8, 5, 5, 2, 5, 8]]) In [7]: x[:, 0:2:2] Out[7]: array([[9], [3], [8]]) In [8]: x[:, :2:2] Out[8]: array([[9], [3], [8]]) In [9]: x[:, ::2] Out[9]: array([[9, 2, 8], [3, 6, 4], [8, 5, 5]]) # 关于List In [10]: d =[[3, 4, 8, 8, 8, 9], ...: [8, 9, 6, 3, 4, 9], ...: [6, 7, 6, 6, 7, 1]] ...: # 在元素层面,切片是可以用的 In [11]: d Out[11]: [[3, 4, 8, 8, 8, 9], [8, 9, 6, 3, 4, 9], [6, 7, 6, 6, 7, 1]] In [12]: d[::2] Out[12]: [[3, 4, 8, 8, 8, 9], [6, 7, 6, 6, 7, 1]] In [13]: d[:2:2] Out[13]: [[3, 4, 8, 8, 8, 9]] In [14]: d[0:2:2] Out[14]: [[3, 4, 8, 8, 8, 9]] # 下面不可以用了,因为逗号就代表你认为元素还可以切分,这是和定义一冲突的。 In [15]: d[1,::2] --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-15-32535642f99b> in <module>() ----> 1 d[1,::2] TypeError: list indices must be integers or slices, not tuple- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 注意
1)定义一:在list里面,只存在元素,不存在元素中的元素;list里元素就是最小的成分,不可以再切片。
2)定义二:在array中(numpy的数据都可以)最后一个维度的数据才可以叫做元素,同样元素不可切分。
结合例子解释定义一:就算是二维、三维的list,元素就是axis=0的数据,例如数据x=[[1,2,3,4],[2,3,4,5],[5,6,7,8]],元素就是[1,2,3,4]或者[2,3,4,5]或者[5,6,7,8],而不是更里面的数字1等等;在二维列表中写下x[:],但是不可以写x[:,:],根据定义一,第二种x[:,:]切片操作是不合法的。
-
相关阅读:
不定期会议对团队开发的影响(项目管理篇)
年轻人开发谁用默认背景?我直接美图安排上
todoList清单(HTML+CSS+JavaScript)
ES优化实战-通过开启copy_to提升一倍的检索性能
3.7-RUN vs CMD vs Entrypoint
解锁学习电路设计的正确姿势!
VulnHub DC-9
【C语言】文件操作
java计算机毕业设计甜趣网上蛋糕店订购系统源码+系统+数据库+lw文档+mybatis+运行部署
【运维日常】mac刻录ubuntu系统进U盘,插入服务器安装系统
- 原文地址:https://blog.csdn.net/u014217137/article/details/127924468
