-
读《高性能MySQL》笔记---索引
索引是存储引擎用于快速找到记录的的一种数据结构。
索引的优点
- 索引大大减少服务器需要扫描的数据量。
- 索引帮助服务器避免排序和临时表。
- 索引将随机IO变为顺序IO。
说明:
顺序IO:是指读写操作的访问地址连续。在顺序IO访问中,HDD所需的磁道搜索时间显着减少,因为读/写磁头可以以最小的移动访问下一个块。数据备份和日志记录等业务是顺序IO业务。
随机IO:是指读写操作时间连续,但访问地址不连续,随机分布在磁盘的地址空间中。产生随机IO的业务有OLTP服务,SQL,即时消息服务等。为什么说索引将随机IO变为顺序IO?
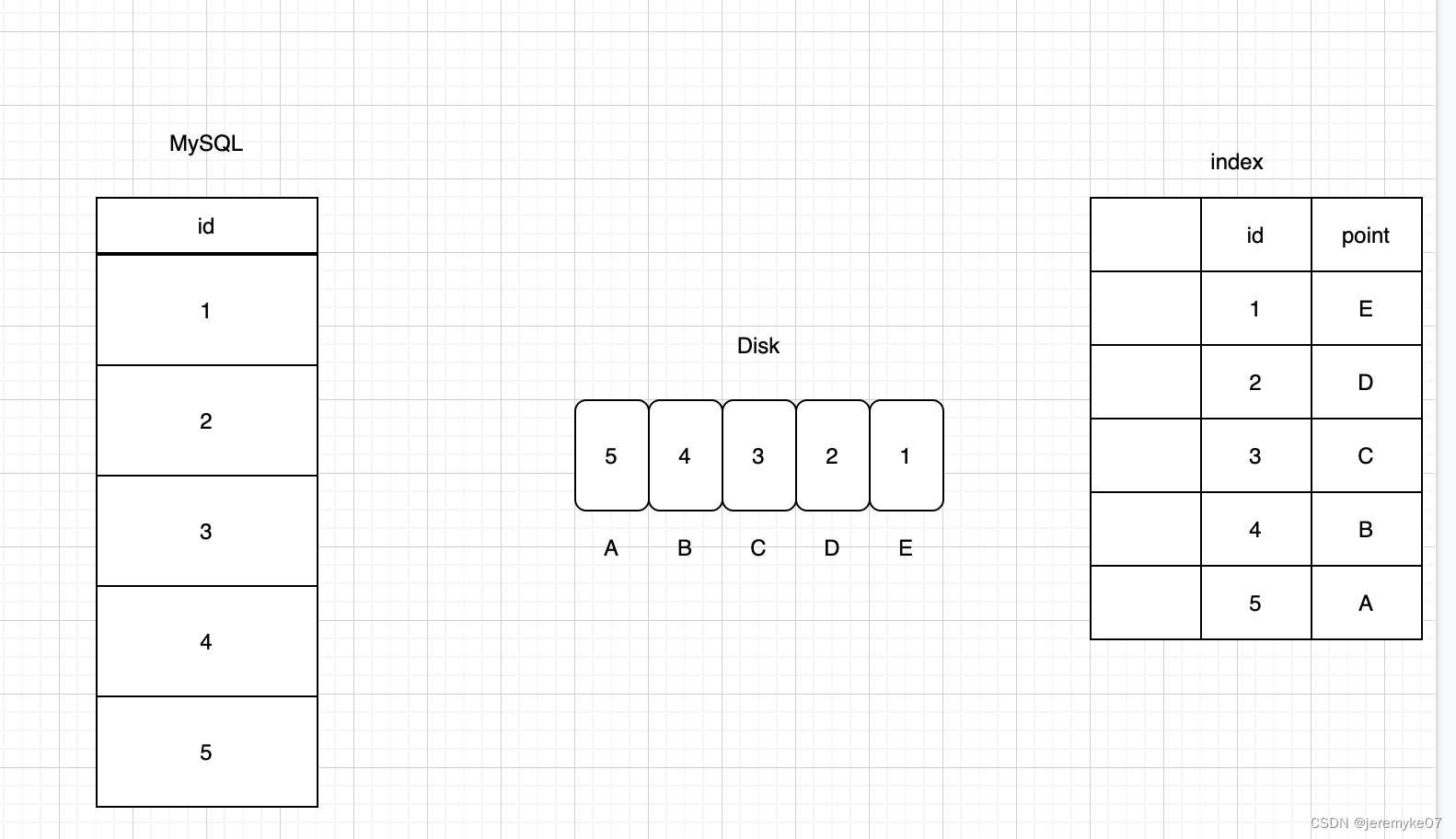
如图:在没有索引的情况下,全表扫描。先找1号记录所在的位置,磁盘从我们面前滚过,第一个是A,A里面存放的是5号记录,不是我们想要的,我们不取;第二个是B,B里面存放的是4号记录,也不是我们想要的,我们也不取……直到转到E,这时候我们发现E里面的记录是1号记录了,我们取出来,对比一下编号,发现这是1号记录,不是我们想要的2号记录,于是我们丢弃,开始下一周期,直到找到2号记录为止。这里这个取回的动作就是IO动作,你会发现它是不连续的,并不是每次磁盘滚过都要取,有一定的随机性,所以这就是随机IO。
有索引的时候,使用索引查找。磁盘依然从我们面前滚过,第一个是A,我们不取;第二个是B,我们也不取……因为我们已经准确地预知我们想要的是2号记录,所以当磁盘滚到D时,我们直接一次性取出,不用再等下一个周期,这就变成了顺序IO。索引类型
B-Tree索引
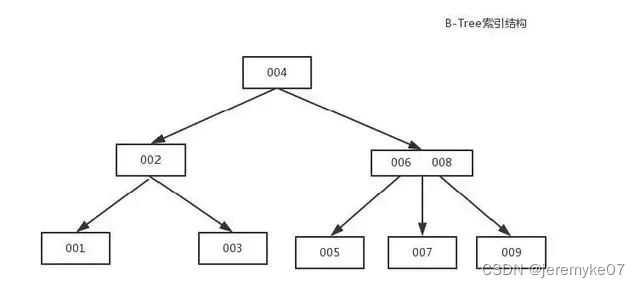
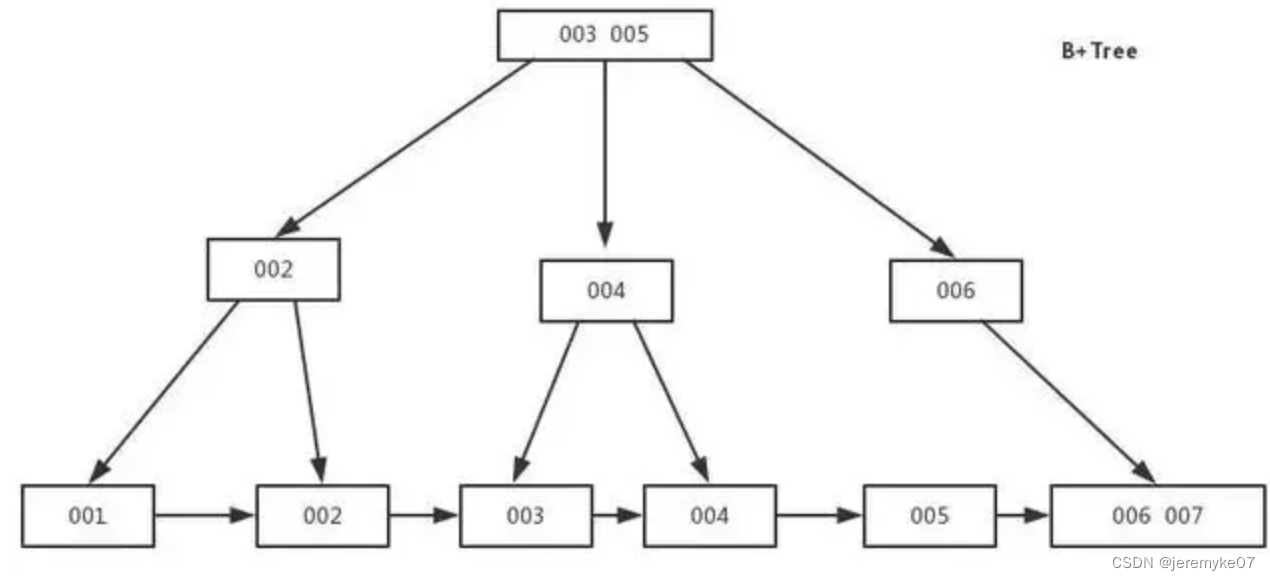
b-tree是一种索引类型。不同的存储引擎可能使用不同的存储结构来实现,比如InnoDB是B+tree(即:每一个叶子结点包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历);不同的存储引擎使用B-tree的方式也各不相同,比如MyISAM使用前缀压缩技术使得索引更小,索引的叶子节点存放了指向行数据的物理地址;InnoDB则按照原数据格式进行存储,索引的叶子节点存放的是行所有数据。
b-tree索引所有适用于全值匹配、最左前缀匹配、列前缀匹配、匹配范围值、精确匹配某一列并范围匹配另外一列、只访问索引的查询(索引覆盖)。
b-tree索引的使用限制:①如果不是按照索引的最左开始查找,则无法使用索引。②不能跳过索引中的列。③如果查询中有某个列的范围查询,则其右边所有的列都无法使用索引优化查找。哈希索引
哈希索引是基于哈希表实现的,只有精确匹配索引所有列的查询才有效。对于每一行数据存储引擎都会对所有的所有列计算一个哈希码。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在MySQL中,自有Memory引擎显式支持哈希索引。哈希索引只存储对于的哈希值,所以索引的结构十分紧凑,这也让哈希索引的查找速度非常快。
哈希索引的缺点:- 哈希索引不包含行数据,查找过程先找到数据行指针,再去磁盘中读取查找数据。
- 哈希索引不是按照所有值顺序排序存储的,所以无法用于排序。
- 哈希索引只能全值匹配,不支持部分索引列匹配查找。
- 哈希索引只支持等值比较查询,如:=、IN()、<=>
- 哈希冲突很多的话,一些索引维护操作的代价也会很高。
InnoDB引擎有一种特殊的公共:自适应哈希索引,对永无无感知。
空间数据索引
MyISAM表支持空间索引,用作地理数据存储。空间索引会冲所有维度来索引数据,查询时,可以有效的使用任意比较索引中的值。
全文索引
全文索引是一种特殊类型的索引,它查找文本中的关键词,而不是直接比较索引的值。
高性能索引策略
- 索引列不能是表达式的一部分,也不能是函数的参数,必须只能是独立的列。
- 使用前缀索引时,要选择合适的前缀值长度:
- 索引的选择性:不重复的索引值 / 表数据总数 的值。选这个值约小,择性越高,反之越低。
- 对于BLOB和TEXT或者很长的VARCHAR类型的列,必须使用前缀索引。
- 当完整索引列的前n个字符的选择性和完整索引列的选择性相差值比n-1和n+1都小时,前缀索引的前缀字符数就为n
- 创建前缀索引:
ALTER TABLE test_table ADD KEY(citu(7))- 1
- 合适的情况可以创建多列索引。且一般将选择性最高的列放在索引的最前列,但有时候也需要把选择性小的列放前面,查询的时候如果要命中索引的话就必须IN选择性小的索引,比如:肤色,in(white,yellow,black)
4.聚簇索引
聚簇索引并不是一种索引类型,而是一种数据存储方式。聚簇索引的数据行存放在了索引的叶子节点上,把数据行和相邻的键值紧凑的储存在一起,所以成为“聚簇”。
优点:- 可以把整个数据保持在一起。
- 数据访问快。
- 使用覆盖索引扫描查询可以直接使用子节点主键值。
缺点:
- 插入速度严重依赖于插入顺序。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动 到新的位置。
- 插入新行,可能面临页分裂的问题。
- 对于行比较稀疏或者是页分裂导致数据存储不连续时,全表扫描很慢。
- 二级索引访问需要两次索引查找,而不是一次。
MyISAM引擎的主键索引和一般索引没多大差别:叶子节点都是存放是行数据的指针。而InnoDB引擎的聚簇索引的每一个叶子节点包含主键值、事务ID、回滚指针、和剩余的列,二级索引的叶子节点存储的不是行指针而是主键值。

在InnoDB表中,主键需要保证单调,这样才能最大的提升插入速度,更小的减少数据库碎片。
5.覆盖索引
好处:
-
索引数目通常小于数据行大小,通过读取索引就能找到查询数据,极大减小访问量。
-
索引是按顺序存储的,所以对于IO密集型的范围查询会比随机IO要少得多。
-
尽量使用索引扫描来做排序,当索引的列顺序和order by子句顺序完全一致,且所有列的排序方向一样,MySQL才能使用索引来对结果做排序。
-
前缀压缩索引:先完全保存索引库的第一个值,然后其他值和第一个值得到相同的前缀的字节数和不同的后缀部分,然后把这两部分加起来即可,例如:第一个值abcd,第二个值可以为“3,edf”,实际为abcedf.
-
避免冗余和从夫索引。可以使用一些工具(例如:Percona)来检查是否有冗余和重复索引。
-
删除未使用的索引,统一可以用一些工具(比如:Percona Server)来检查。
-
通过索引尽量锁住少量的行数据,保证更大的并发度。
维护索引和表
- 使用CHECK TABLE检查是否发生表损坏,然后使用REPAIR TABLE来修复表。
- 使用ANALYZE TABLE来重新生成统计信息,从而更新索引的统计信息。使用show index from table_name查看索引信息。
- 减少索引和数据碎片。可以通过OPTIMIZE TABLE指令或者重新导出和导入来整理数据。或者通过no-op的alter table操作来重建表,比如alter table table_name engine=(之前的engine)
-
相关阅读:
CDGA|政务部门这样进行数据治理真不错!!!
cadence virtuoso layout drc error
4_hytrix_信号量_线程池
vSphere+、vSAN+来了!VMware 混合云聚焦:原生、快速迁移、混合负载
矢量绘图软件源码定制开发,类似visio绘图,大量复合图元模板,可编程动态控制图元
多中机器学习模型对比可视化
java---Stream流
专业级游戏测试书上架:精通游戏测试(第3版)
TCP/UDP协议
数据挖掘是什么?
- 原文地址:https://blog.csdn.net/jeremy_ke/article/details/127876553