-
JavaSE入门必读篇——Java数组(详解)
数组的概念
假设现在要存5个学生的javaSE考试成绩,并对其进行输出,我们也许会:
public class TestStudent{ public static void main(String[] args){ int score1 = 70; int score2 = 80; int score3 = 85; int score4 = 60; int score5 = 90; System.out.println(score1); System.out.println(score2); System.out.println(score3); System.out.println(score4); System.out.println(score5); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们成功实现了,可是50个呢?500个呢?5000个呢?我们总不能把这么多变量依次定义吧,况且他们都是数据类型相同的变量,那么java是通过什么来方便我们的使用的呢?这就是本文章所要讲到的数组。
1.什么是数组呢?
数组:可以看成是相同类型元素的一个集合。在内存中是一段连续的空间。例如车库:1.每个车位都是用来停车的;2.车位是连在一起的;3.车位都有属于自己的编号
- 数组中存放的元素其类型相同
- 数组的空间是连在一起的
- 每个空间有自己的编号,其实位置的编号为0,即数组的下标
2.如何创建数组
数组的两种常见初始化方式:
- 1.动态初始化(指定长度)
- 2.静态初始化(指定内容)
具体语法如下:
1.动态初始化数组存储的数据类型[ ] 数组名字 = new 数组存储的数据类型[数组长度];
数组存储的数据类型 数组名字[ ] = new 数组存储的数据类型[数组长度];//不建议使用第一种列举方式实例如下:
int[] array1 = new int[10]; // 创建一个可以容纳10个int类型元素的数组 double[] array2 = new double[5]; // 创建一个可以容纳5个double类型元素的数组 String[] array3 = new double[3]; // 创建一个可以容纳3个字符串元素的数组- 1
- 2
- 3
注:
1.new:关键字,创建数组使用的关键字; 2.数组有定长特性,长度一旦指定,不可更改。
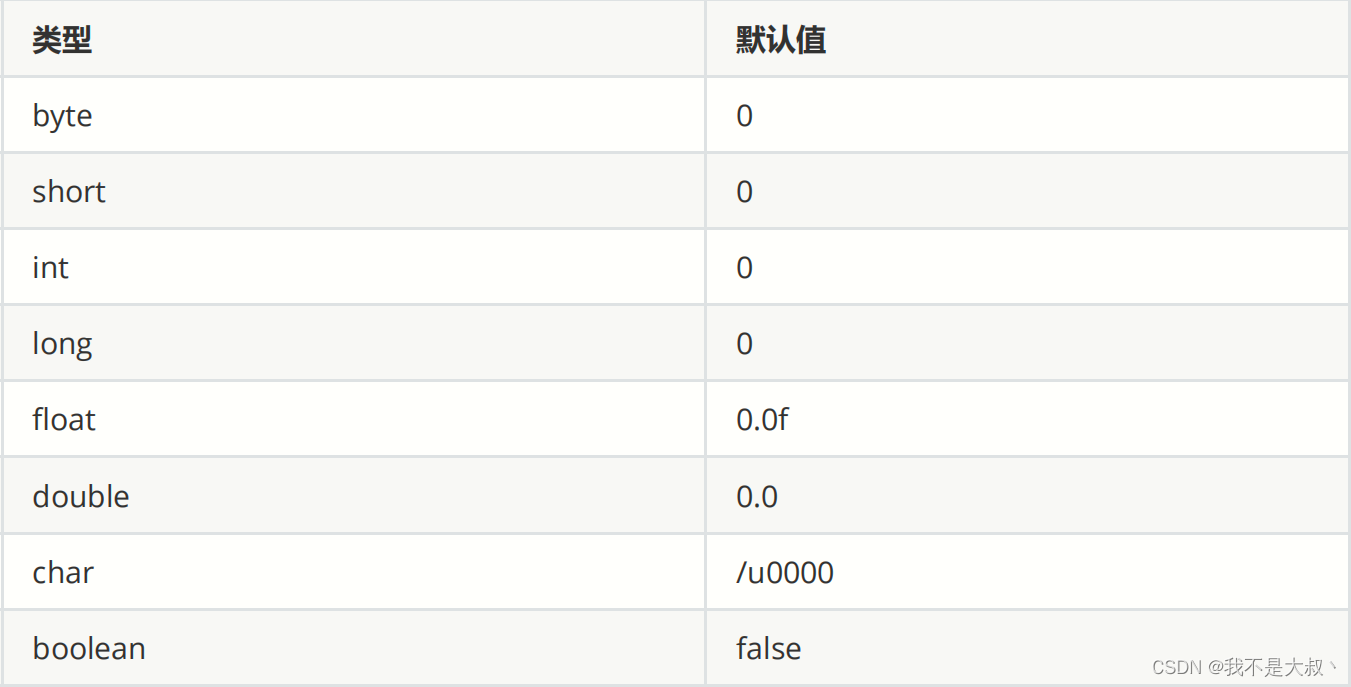
当我们定义长度而没有具体数值时,我们java会提供默认值赋值:
2.静态初始化数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3…};
示例如下:
int[] array1 = new int[]{0,1,2,3,4,5,6,7,8,9}; double[] array2 = new double[]{1.0, 2.0, 3.0, 4.0, 5.0}; String[] array3 = new String[]{"hell", "Java", "!!!"};- 1
- 2
- 3
我们最为常用的是静态初始化的省略方式:
数据类型[] 数组名 = {1,元素2,元素3…};
举例如下:
// 注意:虽然省去了new T[], 但是编译器编译代码时还是会还原 int[] array1 = {0,1,2,3,4,5,6,7,8,9}; double[] array2 = {1.0, 2.0, 3.0, 4.0, 5.0}; String[] array3 = {"hell", "Java", "!!!"};- 1
- 2
- 3
- 4
注:
该方法不可拆分定义3.遍历数组
数组在内存中是一段连续的空间,空间的编号都是从0开始的,依次递增,该编号称为数组的下标,数组可以通过下标访问其任意位置的元素。例如:
int[]array = new int[]{10, 20, 30, 40, 50}; System.out.println(array[0]); System.out.println(array[1]); System.out.println(array[2]); System.out.println(array[3]); System.out.println(array[4]); array[0] = 100;// 也可以通过[]对数组中的元素进行修改 System.out.println(array[0]);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
【注意事项】
- 数组是一段连续的内存空间,因此支持随机访问,即通过下标访问快速访问数组中任意位置的元素
- 下标从0开始,介于[0, N)之间不包含N,N为元素个数,不能越界,否则会报出下标越界异常。
比如:
int[] array = {1, 2, 3}; System.out.println(array[3]); // 数组中只有3个元素,下标一次为:0 1 2,array[3]下标越界 // 执行结果 Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 100 at Test.main(Test.java:4)- 1
- 2
- 3
- 4
- 5
遍历数组的三大方式
循环打印:int[]array = new int[]{10, 20, 30, 40, 50}; for(int i = 0; i < 5; i++){ System.out.println(array[i]); } int[]array = new int[]{10, 20, 30, 40, 50}; for(int i = 0; i < array.length; i++){ //数组名.length求数组长度 System.out.println(array[i]); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
int[] array = {1, 2, 3}; for (int x : array) { System.out.println(x); }- 1
- 2
- 3
- 4
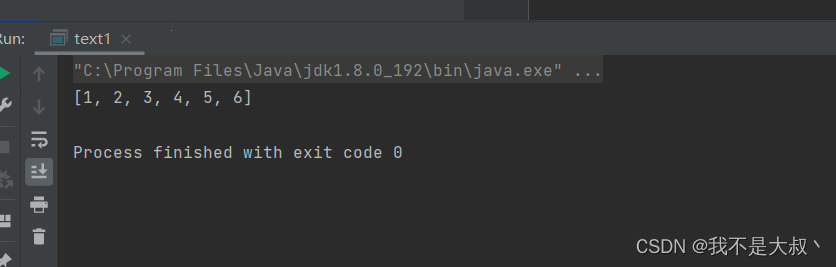
import java.util.Arrays; public class text1 { public static void main(String[] args) { int[] array={1,2,3,4,5,6}; System.out.println(Arrays.toString(array)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
效果展示如下:
4.扩展:快速批量初始化
Arrays.fill快速初始化,填充一个数组。
我们看jdk1.8帮助手册里的说明:

实例:import java.util.Arrays; public class HelloWorld { public static void main(String[] args) { int[] arr = new int[5]; Arrays.fill(arr, 1); System.out.println(Arrays.toString(arr)); // [1, 1, 1, 1, 1] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
数组原理内存图
1. 内存概述
内存是计算机中的重要原件,临时存储区域,作用是运行程序。我们编写的程序是存放在硬盘中的,在硬盘中的程序是不会运行的,必须放进内存中才能运行,运行完毕后会清空内存。 Java虚拟机要运行程序,必须要对内存进行空间的分配和管理。
简单来概括就是以下四点:- 程序运行时代码需要加载到内存
- 程序运行产生的中间数据要存放在内存
- 程序中的常量也要保存
- 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
2.Java虚拟机的内存划分
为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
-
JVM内存划分

-
虚拟机栈(JVM Stack): 与方法调用相关的一些信息,每个方法在执行时,都会先创建一个栈帧,栈帧中包含
有:局部变量表、操作数栈、动态链接、返回地址以及其他的一些信息,保存的都是与方法执行时相关的一
些信息。比如:局部变量。当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了。 -
堆(Heap): JVM所管理的最大内存区域. 使用 new 创建的对象都是在堆上保存 (例如前面的 new int[]{1, 2,
3} ),堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销
毁。
3.其存储方式图
引用变量并不直接存储对象本身,可以简单理解成存储的是对象在堆中空间的起始地址。通过该地址,引用变量便可以去操作对象。有点类似C语言中的指针,但是Java中引用要比指针的操作更简单。

注:变量array保存的是数组内存中的地址,而不是一个具体数值,因此称为引用数据类型。import java.util.Arrays; public class text1 { public static void main(String[] args) { int[] array1={1,2,3,4,5,6}; int[] array2=new int[6]; array2=array1; System.out.println(Arrays.toString(array2)); array2[1]=300; System.out.println(Arrays.toString(array1)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

请大家思考为什么会有这样的效果,可以私信博主呦!4.认识null
null 在 Java 中表示 “空引用” , 也就是一个不指向对象的引用,null 的作用类似于 C 语言中的 NULL (空指针), 都是表示一个无效的内存位置. 因此不能对这个内存进行任何读写操作。
int[] arr = null; System.out.println(arr[0]); // 执行结果 Exception in thread "main" java.lang.NullPointerException at Test.main(Test.java:6)- 1
- 2
- 3
- 4
- 5
二维数组
二维数组初始化
同一维数组一样,共有4总不同形式的定义方法:
int[][] array1 = new int[10][10]; int array2[][] = new int[10][10]; int array3[][] = { { 1, 1, 1 }, { 2, 2, 2 } }; int array4[][] = new int[][] { { 1, 1, 1 }, { 2, 2, 2 } };- 1
- 2
- 3
- 4
注:
二维数组定义不可省略行不规则二维数组:
int[][] array = new int[3][]; array[0] = new int[1]; array[1] = new int[2]; array[2] = new int[3];- 1
- 2
- 3
- 4
遍历二维数组
import java.util.Arrays; public class text1 { public static void main(String[] args) { int[][] array={{1,2,3},{2,4,5},{1,2}}; System.out.println(Arrays.deepToString(array)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

数组常见异常
1. 数组越界异常
public static void main(String[] args) {
int[] arr = {1,2,3};
System.out.println(arr[3])
}报错信息如下:

数组的索引是0.1.2,没有3索引,因此我们不能访问数组中不存在的索引出现该异常必须修改!
2. 数组空指针异常
我们在认识null中已经简要说明,我们来看内存:

Java常用API
1. 输出数组
Arrays.toString()int[] array = { 1, 2, 3 }; System.out.println(Arrays.toString(array));- 1
- 2
2.数组复制
copyOf()import java.util.Arrays; public class text1 { public static void main(String[] args) { int[] array={1,2,3,4,5,6}; int[] ret=Arrays.copyOf(array,array.length*2);//复制同时扩容 System.out.println(Arrays.toString(array)); System.out.println(Arrays.toString(ret)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
效果如下:

3.数组排序
sort()import java.util.Arrays; public class text1 { public static void main(String[] args) { int[] array={1,6,5,4,9}; System.out.println(Arrays.toString(array)); Arrays.sort(array); System.out.println(Arrays.toString(array)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

4.二维数组转字符打印
deepToString()import java.util.Arrays; public class text1 { public static void main(String[] args) { int[][] array={{1,2,3},{2,4,5},{1,2}}; System.out.println(Arrays.deepToString(array)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
数组与方法的使用
在java当中,数组可以作为返回值来使用举例:斐波那契数列->
public class text1 { public static int[] fib(int n){ if(n <= 0){ return null; } int[] array = new int[n]; array[0] = array[1] = 1; for(int i = 2; i < n; ++i){ array[i] = array[i-1] + array[i-2]; } return array; } public static void main(String[] args) { int[] array = fib(10); for (int i = 0; i < array.length; i++) { System.out.println(array[i]); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
部分截图如下:

-
相关阅读:
【无标题】
vue3父子props 非props emit slot 具名/动态/作用域slot 动态/异步组件suspense $refs 生命周期
【在Ubuntu部署Docker项目】— PROJECT#1
Pytorch-基于RNN的不同语种人名生成模型
传输层协议 —— UDP
关于IDEA中gradle项目bootrun无法进入断点以及gradle配置页面不全的解决方案
ZooKeeper之Java API的基本使用以及应用场景的实现
echarts vue里画一个简单的环状饼图
【附源码】计算机毕业设计JAVA学生信息管理系统
【Spring】初阶三 - AOP
- 原文地址:https://blog.csdn.net/m0_65038072/article/details/127719874
