-
ThreadLocal 详解
ThreadLocal 详解
文章目录
1. 简介
ThreadLocal 直译过来就是 线程变量 ,也就是说 ThreadLocal 中保存的变量属于当前线程私有的,而对于其他线程是隔离的。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程只可以访问自己内部的副本变量。
简单来说
ThreadLocal就是一个与线程绑定的变量,用于解决多线程并发访问问题。结构图:
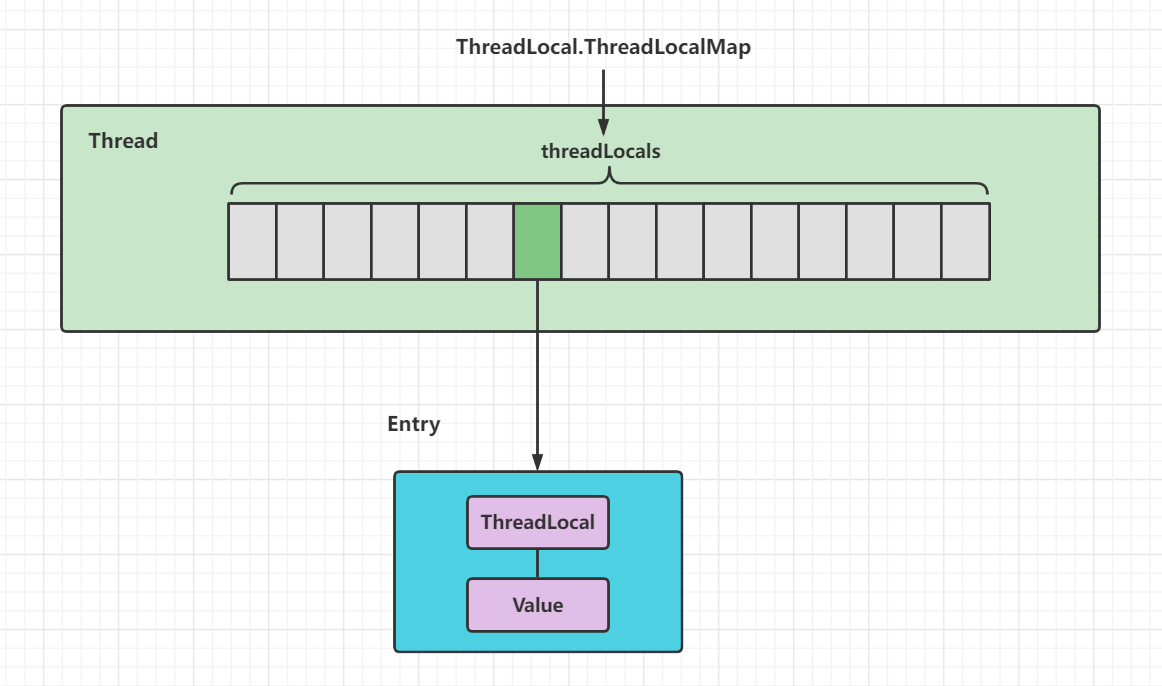
如果不清楚ThreadLocal的结构,可能会以为ThreadLocal的原理就是创建了一个Map,key是每一个Thread,value是每个线程要保存的变量副本,实际上在早期JDK版本是这样实现的。
现在的 ThreadLocal 经过了优化,每个线程想要独占的数据实际上是保存在自己对应的 Thread 对象中的。
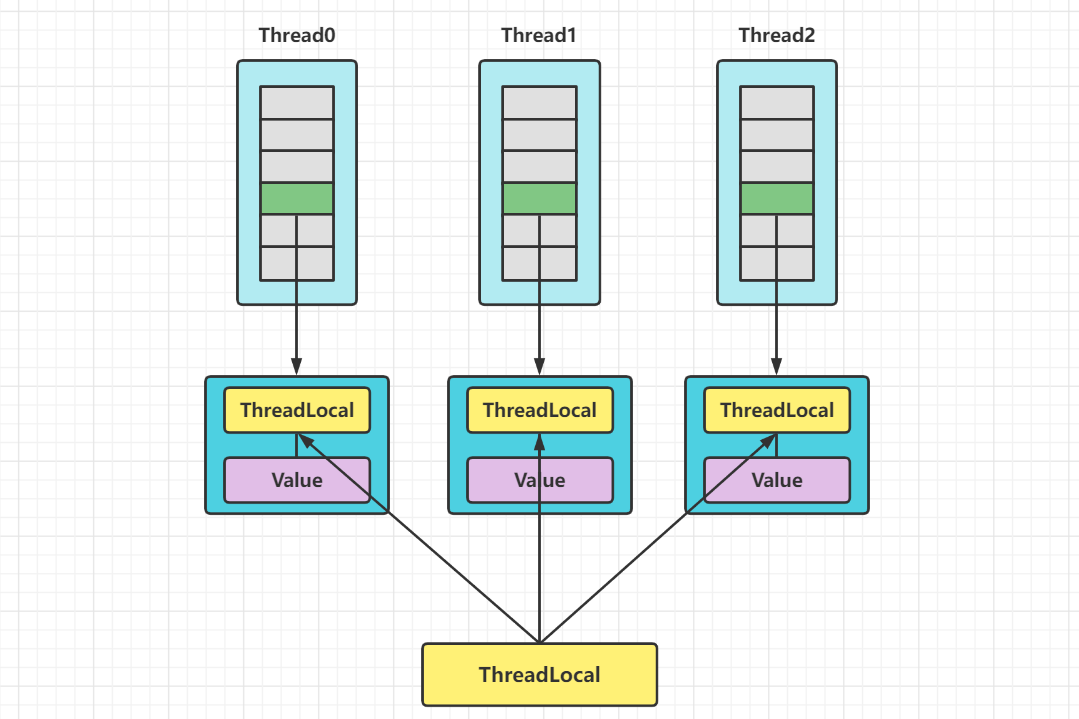
也和我们第一时间想的恰恰相反:
- 保存数据的map其实是保存在Thread对象中的,而不是保存在ThreadLocal对象中
- 作为key的是ThreadLocal对象,而不是Thread对象
Thread类中的成员变量 :
// 属于此线程的ThreadLocal值。这个map由ThreadLocal类维护。 ThreadLocal.ThreadLocalMap threadLocals = null;- 1
- 2
再附一张图加深理解:
2. ThreadLocal与synchronized
ThreadLocal 和 synchonized 都用于解决多线程并发访问,但是两者的实现机制和使用场景截然不同。
- synchonized解决多线程并发访问的原理是对共享变量或代码块加锁。
- ThreadLocal是实现线程间的数据隔离,也就是根本不会共享同一个变量。
ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
3. 常用方法
方法声明 方法描述 ThreadLocal() 构造器,创建ThreadLocal对象 public void set(T value) 设置当前线程绑定的变量 public T get() 获取当前线程绑定的变量 public void remove() 移除当前线程绑定的变量 简单使用举例:
public class ThreadLocalTest { private static ThreadLocal<String> threadLocal = new ThreadLocal<>(); public static void main(String[] args) { threadLocal.set("hello"); for (int i = 0; i < 3; i++) { int j = i; new Thread(() -> { threadLocal.set("Thread: " + j); String obj = threadLocal.get(); System.out.println(obj); }).start(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
控制台打印:
Thread: 0 Thread: 1 Thread: 2- 1
- 2
- 3
4. ThreadLocal 原理分析
4.1 属性与主要方法
public class ThreadLocal<T> { /** * ThreadLocals依赖于附加到每个线程的每个线程的线性探测哈希映射 * ThreadLocal对象充当键,通过threadLocalHashCode进行搜索。 * 这是一个自定义哈希代码(只在threadlocalmap中有用), * 它消除了在通常情况下(连续构造的ThreadLocals由相同的线程使用)的冲突, * 同时在不太常见的情况下保持良好的行为。 */ private final int threadLocalHashCode = nextHashCode(); /** * 下一个要给出的哈希码。自动更新。从0开始。 */ private static AtomicInteger nextHashCode = new AtomicInteger(); /** * 连续生成的哈希码之间的差异-将隐式的顺序线程本地id转换为接近最优分布的乘法哈希值 * 每为线程创建一个ThreadLocalMap对象,这个ThreadLocal.nextHashCode这个值就会增长, * 这个值很特殊,它是斐波那契数。hash增量为这个数字,带来的好处就是hash分布非常均匀 */ private static final int HASH_INCREMENT = 0x61c88647; /** * 返回下一个哈希码。 * 创建 ThreadLocal 对象时会使用到,每创建一个 ThreadLocalMap 对象, * 就会使用 nextHashCode 分配一个hash值给这个 ThreadLocal 对象。 */ private static int nextHashCode() { return nextHashCode.getAndAdd(HASH_INCREMENT); } /** * 返回此线程局部变量的当前线程的“初始值”。 * 该方法将在线程第一次使用get方法访问变量时被调用, * 除非线程之前调用了set方法,在这种情况下,不会为线程调用initialValue方法。 * 通常,每个线程最多调用一次此方法,但在后续调用remove和get时可能会再次调用它。这个实现简单地返回null; * 如果程序员希望线程局部变量的初始值不是null,则必须子类化ThreadLocal,并重写此方法。 * 通常,将使用匿名内部类。 * * 返回值: 此线程本地的初始值 */ protected T initialValue() { return null; } /** * 创建一个线程局部变量。 */ public ThreadLocal() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
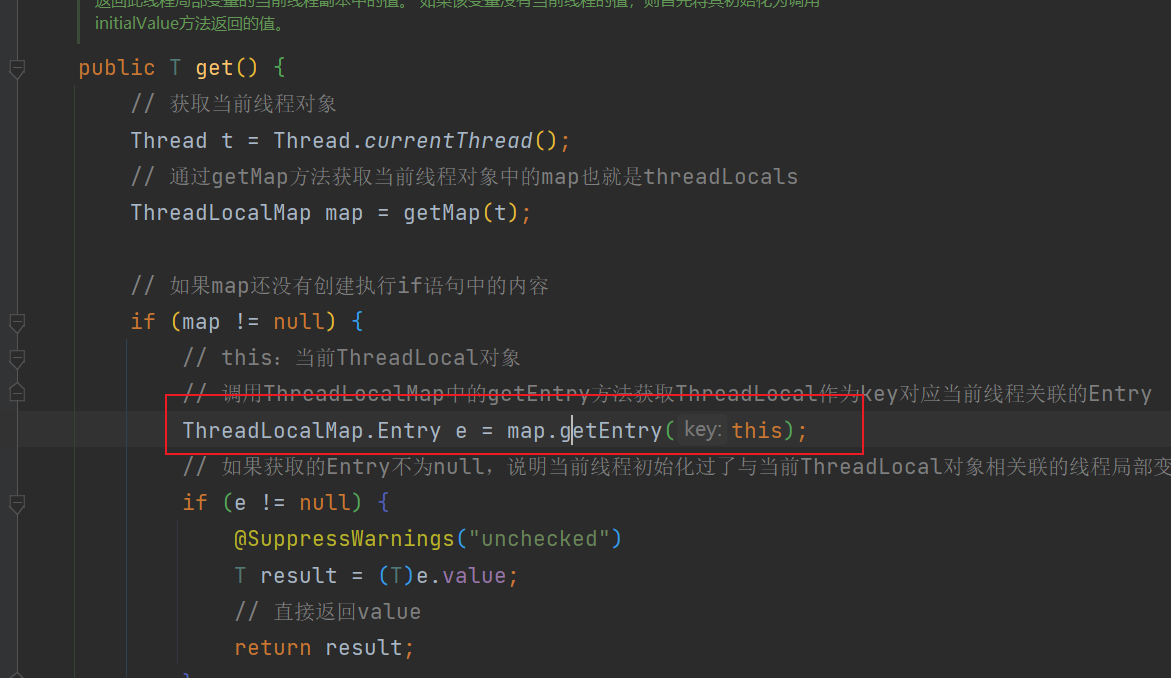
4.2 get() 方法
执行流程图:
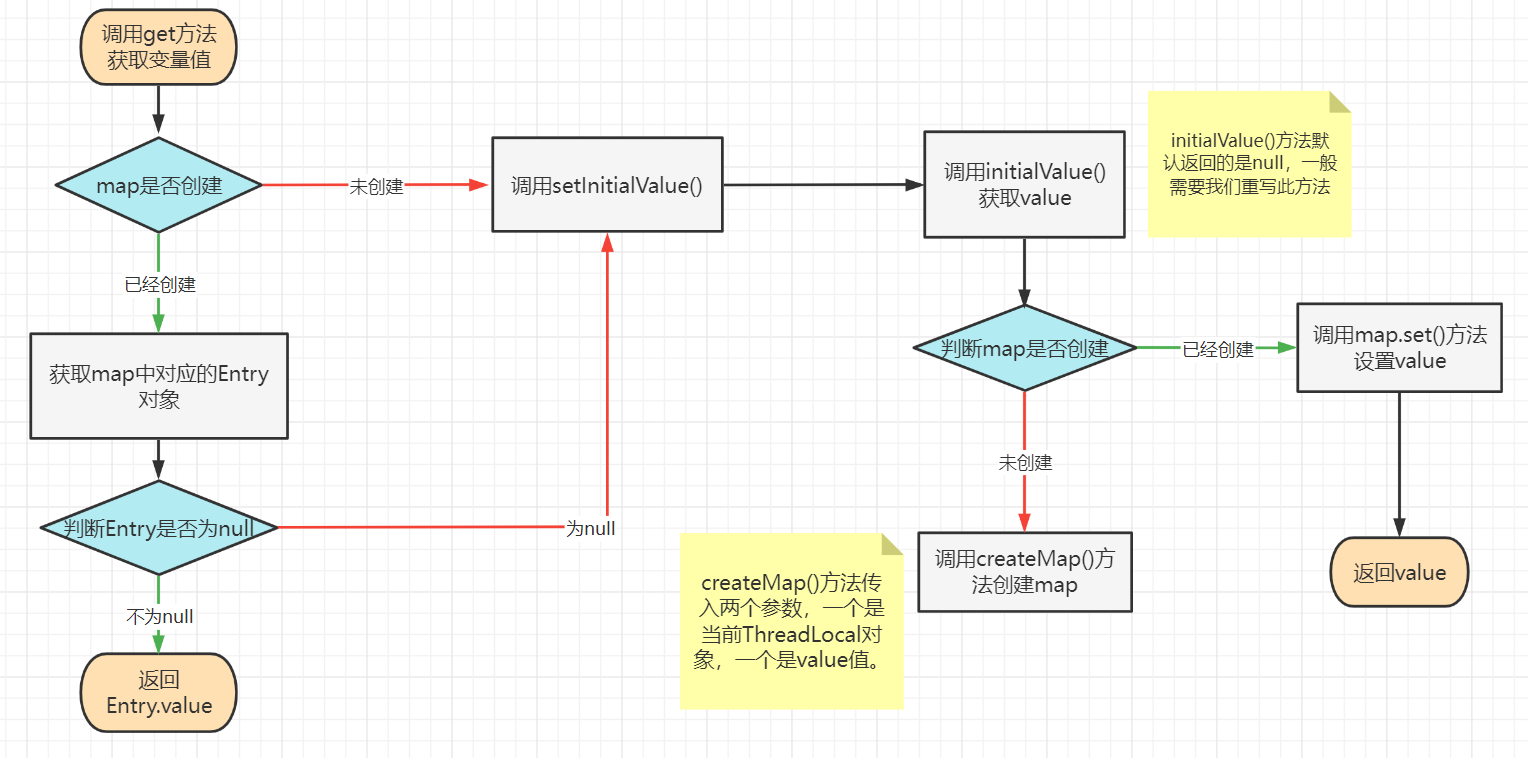
/** * 返回此线程局部变量的当前线程副本中的值。 * 如果该变量没有当前线程的值,则首先将其初始化为调用initialValue方法返回的值。 */ public T get() { // 获取当前线程对象 Thread t = Thread.currentThread(); // 通过getMap方法获取当前线程对象中的map也就是threadLocals ThreadLocalMap map = getMap(t); // 如果map还没有创建执行if语句中的内容 if (map != null) { // this:当前ThreadLocal对象 // 调用ThreadLocalMap中的getEntry方法获取ThreadLocal作为key对应当前线程关联的Entry ThreadLocalMap.Entry e = map.getEntry(this); // 如果获取的Entry不为null,说明当前线程初始化过了与当前ThreadLocal对象相关联的线程局部变量 if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; // 直接返回value return result; } } // 执行到这里的两种情况: // 1.当前线程对应的threadLoaclMap为NULL, // 2.当前线程与当前threadLocal对象没有生成过相关联的线程局部变量 // return setInitialValue(); } /** * threadLocals是Thread类内部的一个属性, * (ThreadLocal.ThreadLocalMap threadLocals;) * 可以理解为一个Map- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
4.3 set(T value) 方法
流程图:
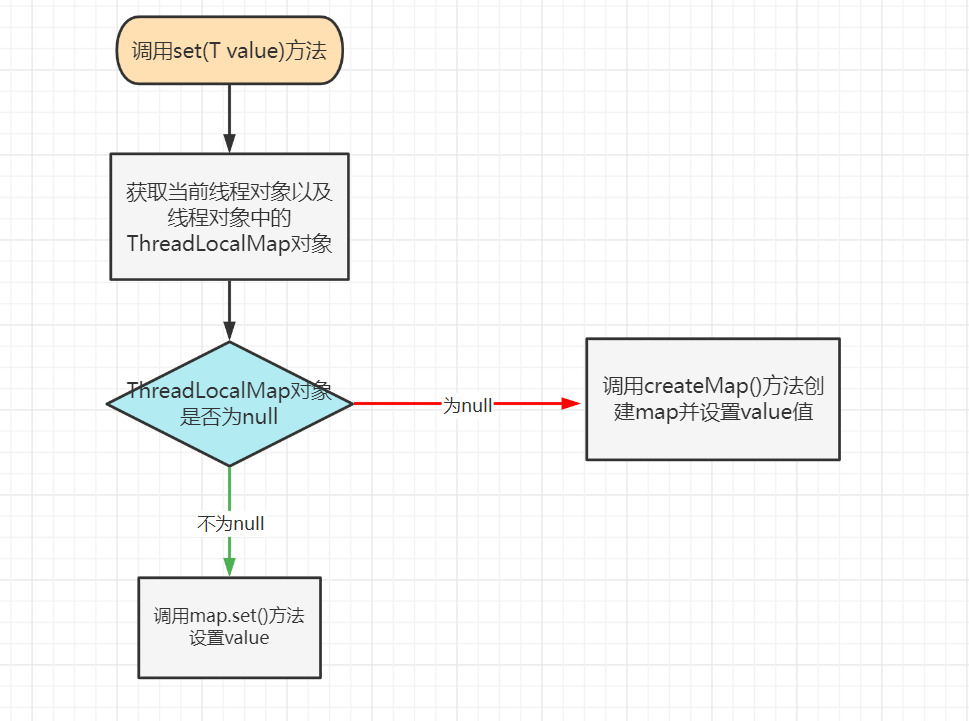
public void set(T value) { // 获取当前线程以及内部的threadLocals(threadLocalMap) Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); // 条件成立:说明当前线程的threadLocalMap已经初始化了 if (map != null) // 替换value map.set(this, value); else // 创建线程内部的threadLocalMap并设置value。 createMap(t, value); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.4 remove() 方法
remove方法逻辑简单,如果map未创建,则什么都不做;
如果map已经创建,则调用ThreadLocalMap对象中的remove方法。
而重要逻辑的实现都在ThreadLocal的内部类ThreadLocalMap中。
public void remove() { //获取当前线程内部的ThreadLocalMap对象, ThreadLocalMap m = getMap(Thread.currentThread()); if (m != null) //调用remove方法。(key = 当前threadLocal对象) m.remove(this); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
5. 核心内部类 ThreadLocalMap
ThreadLocalMap与HashMap不一样,HashMap中的数据结构有数组,链表还有红黑树;而ThreadLocalMap中的数据结构只有数组。HashMap处理哈希冲突时会采用链式地址法(拉链法),也就是形成链表;ThreadLocalMap则是使用开放地址法(线性探测法),如果在存放数据时在一个桶位上发生了冲突,则会像该桶位的后面探测是否有空位,如果到了桶位的尽头也没有空位,就会从哈希表的起始位置继续探测,如果发现还是没有空位,才会进行扩容相关的操作。
5.1 内部类Entry
ThreadLocalMap的内部类Entry继承了WeakReference(弱引用),在构造方法中调用了父类的构造器。
从构造器中可以看出Entry中的key是弱引用类型的,而value是强引用类型,也就是一旦发生了gc,弱引用的对象就会被销毁。
为什么要将ThreadLocalMap的key设置为弱引用呢?为什么不设置为强引用呢?
这是因为外界是通过ThreadLocal来对ThreadLocalMap进行操作的,假设外界使用ThreadLocal的对象被置null了,也就表示不想再使用这个ThreadLocal对象了,那ThreadLocalMap中的key再设置为强引用也没什么用了,反而浪费内存,不如设置成弱引用,gc时就直接回收掉。可以一定程度上避免内存泄漏问题。
补充:内存泄漏是指程序在申请内存后,无法释放已申请的内存空间。而内存溢出是指程序申请内存时,没有足够的内存供申请者使用。
可以看这篇文章来复习java引用相关知识:Java中的引用: 强引用,软引用,弱引用,虚引用,终结器引用
/** * 这个散列映射中的条目扩展 WeakReference ,使用它的主ref字段作为键(它总是一个ThreadLocal对象)。 * 注意,空键(即entry.get() == null)意味着该键不再被引用,因此可以从表中删除该条目。 * 这样的条目在下面的代码中称为“过期条目” */ static class Entry extends WeakReference<ThreadLocal<?>> { /** 与此ThreadLocal相关联的值。 */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.2 变量、常量、构造器与相关方法
/** * 初始容量,必须是2的幂。 */ private static final int INITIAL_CAPACITY = 16; /** * 哈希表,根据需要调整大小。表的长度必须总是2的幂。 */ private Entry[] table; /** * 哈希表中元素的数量。 */ private int size = 0; /** * 扩容阈值 构造器中初始化为 len * 2/3 * 触发后调用 rehash()方法 * rehash() 方法先做一次全局检查过期数据,把散列表中所有过期的entry移除 * 如果移除之后 当前散列表中的entry个数仍然达到 阈值的 3/4,就进行扩容。 */ private int threshold; // Default to 0 /** * 设置阈值为当前哈希表长的 2/3 */ private void setThreshold(int len) { threshold = len * 2 / 3; } /** * 对 i 取模 len 递增。 * 返回 位置 i 的下一个位置 */ private static int nextIndex(int i, int len) { return ((i + 1 < len) ? i + 1 : 0); } /** * 减去i对len的模。 * 返回 位置 i 的上一个位置 */ private static int prevIndex(int i, int len) { return ((i - 1 >= 0) ? i - 1 : len - 1); } /** * 构造一个初始包含(firstKey, firstValue)的新映射。 * threadlocalmap是惰性创建的,因此只有在至少有一个元素要放入时才创建一个。 */ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { // 创建一个初始大小为 16 的Entry数组 table = new Entry[INITIAL_CAPACITY]; // 寻址算法:key的哈希值 & 表长 - 1 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); // 构造一个Entry对象放到指定的位置上 (第一个entry初始化) table[i] = new Entry(firstKey, firstValue); // 大小设置为 1 size = 1; // 设置阈值为初始化容量(16)的 2 / 3 = 10 setThreshold(INITIAL_CAPACITY); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
5.3 getEntry() 方法
getEntry() 在前文的ThreadLocal中的get() 方法中被调用,作用是获取ThreadLocal对象对应的entry值。
getEntry() 方法分析
private Entry getEntry(ThreadLocal<?> key) { // 寻址操作 int i = key.threadLocalHashCode & (table.length - 1); // 获取table上的元素 Entry e = table[i]; // 不为null并且e.get()获取的key与传入的key相等,说明找到了元素,就直接返回 if (e != null && e.get() == key) return e; else // 当前位置上可能发生了hash冲突,没找到元素,去当前位置的后面去找 return getEntryAfterMiss(key, i, e); } /** * getEntry方法的版本,用于在其直接哈希槽中找不到键时使用。 * ThreadLocal key: key * i:可能发生hash冲突的位置 * e:可能发生hash冲突的位置上的元素 */ private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { // 保存hash表引用 Entry[] tab = table; // 保存hash表长度 int len = tab.length; // 当桶位上的元素不是null的时候,就循环下去,继续查找 while (e != null) { // entry继承了弱引用,get()方法就是获取内部的ThreadLocal对象 ThreadLocal<?> k = e.get(); // 查找成功,返回entry if (k == key) return e; // 如果key是null,说明entry关联的ThreadLocal被回收了,但是entry还存在, // 这时就需要将当前位置的entry处理掉 if (k == null) // 删除过期的entry expungeStaleEntry(i); //k不为NULL,但是当前entry不是目标entry,继续向后查找 else i = nextIndex(i, len); e = tab[i]; } return null; } /** * 通过重新哈希位于staleSlot和下一个空槽之间的任何可能发生碰撞的条目来删除过期条目。 * 这还会删除尾随空符之前遇到的任何其他过期条目。 * 返回: 在staleSlot之后的下一个空槽的索引(所有在staleSlot和这个槽之间的索引将被检查以清除)。 */ private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; // 将key过期元素上的value置为null,以便gc回收 tab[staleSlot].value = null; // 槽位上的元素也置为null tab[staleSlot] = null; // 元素个数-1 size--; // REHASH, 直到遇到null // 当前遍历的entry Entry e; // 当前位置索引 int i; // 循环遍历数组,从传入的那个位置的下一个位置开始,遇到entry为null时结束 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { // 获取槽位上对应的entry中的key ThreadLocal<?> k = e.get(); // 如果key为null, 说明此槽位上的数据过期(无效)了 if (k == null) { // e.value置为null方便gc e.value = null; // 槽位上的entry也置为null,方便gc tab[i] = null; // 元素个数-1 size--; } else { /* 执行到这里,说明当前位置的entry不为null。 此时需要执行的事就是判断当前位置上的entry是否在经过哈希寻址后应该在的位置,(因为有可能发生过冲突), 如果不在该在的位置,就去寻找距离寻址位置最近的位置(也可能找到寻址的位置)。 */ // 计算索引位置 int h = k.threadLocalHashCode & (len - 1); // 条件成立 表示当前entry在存放是确实发生过冲突,需要尝试重新找位置存放。 if (h != i) { tab[i] = null; // 我们必须扫描到entry为空,因为多个条目可能已经过时。 // 循环查找空位存放 while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
5.4 set(ThreadLocal key, Object value) 方法
/** * 设置与键相关联的值。 * * @param key 线程本地对象 * @param value 需要设置的值 */ private void set(ThreadLocal<?> key, Object value) { Entry[] tab = table; // hash表引用 int len = tab.length; // 表长 // 当前key对应的槽位索引 int i = key.threadLocalHashCode & (len-1); /* for循环做的事就是,循环寻找key相同的entry。 1.找到相同key并且正常的entry,做value替换 2.找到某一位置(entry != null && entry.key == null),将entry替换。 */ for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { // 获取key值 ThreadLocal<?> k = e.get(); //找到了相同的key,直接替换value。 if (k == key) { e.value = value; return; } // 当前key为null,表示当前entry为过期数据 if (k == null) { // 替换过期的entry。 replaceStaleEntry(key, value, i); return; } } // 执行到这里,说明for循环找到了一个当前slot为null的情况, // 此时直接在这个slot位置上创建一个Entry对象. tab[i] = new Entry(key, value); int sz = ++size; // 这里做一次清理工作,cleanSomeSlots()返回true表示内部没有清理过数据 // 这时在判断元素数量是否达到了扩容阈值,大于等于阈值就进行rehash()操作 if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); } /** * 用指定键的项替换设置操作期间遇到的过期项。 * 在value参数中传递的值存储在条目中,无论指定键的条目是否已经存在。 * 作为一个副作用,该方法会删除包含过期条目的“运行”中的所有过期条目。(run是两个空槽之间的条目序列。) * * 参数: * key—键值—与键相关联的值 * staleSlot—搜索键时遇到的第一个过期条目的索引。 */ private void replaceStaleEntry(ThreadLocal<?> key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; // 将过期entry的位置赋值给slotToExpunge int slotToExpunge = staleSlot; //--------------------循环1开始------------------------- // 以当前staleSlot位置的前一个位置开始,向前迭代查找,(结束条件entry = null) // 更新slotToExpunge先出现的(entry != null && entry.key == null)的过期entry的位置。 for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) if (e.get() == null) slotToExpunge = i; //--------------------循环1结束-------------------------- //--------------------循环2开始-------------------------- // 从过期的entry所在位置向后遍历,找到第一个为 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { // 当前遍历到的entry的key值 ThreadLocal<?> k = e.get(); // If we find key, then we need to swap it // with the stale entry to maintain hash table order. // The newly stale slot, or any other stale slot // encountered above it, can then be sent to expungeStaleEntry // to remove or rehash all of the other entries in run. // 找到了key,做value的替换操作 if (k == key) { e.value = value; // 将过期的entry放到当前位置i,因为下面要从i这个位置开始清理 tab[i] = tab[staleSlot]; // 将替换完毕的entry放到过期数据的位置 tab[staleSlot] = e; // 条件成立:说明replaceStaleEntry一开始时向前查找过期数据时,并未找到过期的entry. if (slotToExpunge == staleSlot) // 因为上面做了交换,所以当前位置i就是过期数据,赋值给slotToExpunge slotToExpunge = i; // 清理过期的entry。 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } // 如果我们在向后扫描时没有发现过期 entry, // 那么在扫描键时看到的第一个过期 entry 就是过期 entry if (k == null && slotToExpunge == staleSlot) // 因为向后查询过程中查找到了一个过期数据, // 更新slotToExpunge为当前位置,前提条件是前驱扫描时未发现过期数据 slotToExpunge = i; } //--------------------循环2结束-------------------------- // 什么时候执行到这里? // 向后查找过程中,并未发现 key = null 也就是过期的entry, // 说明当前set操作是一个添加逻辑,直接将新数据添加到过期entry的位置上。 tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); // 条件成立:说明除了当前staleSlot过期entry位置以外,还发现其他的过期slot了 if (slotToExpunge != staleSlot) // 开始数据清理 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); } /* * @param i 表示清理工作的起始位置,这个位置一定是NULL。 * @param n 表示table.length */ private boolean cleanSomeSlots(int i, int n) { boolean removed = false; Entry[] tab = table; int len = tab.length; do { //获取当前i位置的下一个位置 i = nextIndex(i, len); //获取位置上的entry。 Entry e = tab[i]; // 条件成立表示当前位置的entry是过期数据, 需要清理 if (e != null && e.get() == null) { n = len; //清理表示置为true,表示清理过 removed = true; //以当前过期的slot位置开始,做一次探测式清理工作。 i = expungeStaleEntry(i); } // 表示循环次数。 } while ( (n >>>= 1) != 0); return removed; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
流程总结:
- 先遍历hash表查找元素
- 找到相同的key就做value的替换操作
- 未找到,可能发生hash冲突,继续向后寻找
- 找到了过期entry,进行清理和替换操作
- 遇到了空位,说明是第一次添加元素,新建一个Entry对象
5.5 rehash() 方法
//--------------------ThreadLocalMap.rehash()--------------------------------- private void rehash() { //这个方法执行完毕后,当前散列表内部所有过期的数据,都会被干掉。 expungeStaleEntries(); //条件成立,说明清理完所有的过期entry后,size数量仍然达到了扩容阈值的 3/4 //才会去做一次resize()扩容。 if (size >= threshold - threshold / 4) resize(); } //------------------------ThreadLocalMap.resize()----------------------------- private void resize() { //扩容,变为原长度的2倍 Entry[] oldTab = table; int oldLen = oldTab.length; int newLen = oldLen * 2; // 新长度 = 原长度 * 2; //创建一个新的table, Entry[] newTab = new Entry[newLen]; //表示新表中的元素个数 int count = 0; //遍历原表中的每一个slot,将原表中的数据迁移到新表。 for (int j = 0; j < oldLen; ++j) { Entry e = oldTab[j]; if (e != null) { ThreadLocal<?> k = e.get(); if (k == null) { e.value = null; // Help the GC } else { //计算新位置 int h = k.threadLocalHashCode & (newLen - 1); //遍历找空位置(找到距离目标位置最近的一个slot) while (newTab[h] != null) h = nextIndex(h, newLen); //放到新位置 newTab[h] = e; count++; } } } setThreshold(newLen); //设置新的扩容阈值 size = count; // 将count赋值给size table = newTab; //将新表赋值给table。 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
5.6 remove() 方法
private void remove(ThreadLocal<?> key) { Entry[] tab = table; int len = tab.length; //根据key获取索引位置 int i = key.threadLocalHashCode & (len - 1); //遍历 for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { //找到指定key if (e.get() == key) { /* * entry是弱引用,调用clear()方法会将内部关联的threadLocal置为null */ e.clear(); //清理当前位置 将entry内部的value以及entry干掉。 expungeStaleEntry(i); return; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
最后总结一下,那些方法会触发清理操作?
set()getEntry()remove()
6. ThreadLocal的内存泄漏问题
看了上文的讲解,我们知道ThreadLocalMap内部维护了一个Entry数组,而内存泄漏与这个Entry数组有很大的关系。
Entry对象的key是ThreadLocal对象,是一个弱引用,而value是强引用。如果外部的ThreadLocal被置为null,也就是key的强引用消失了, 此时只有一个弱引用还在,而这时又发生了GC,key就被回收掉了,此时Entry对象还在强引用value,导致value无法被回收,我们也无法获取到这个value,此时就造成了内存泄漏。
但是要注意一个误区,ThreadLocal造成内存泄漏的可能性 很低 ,而且不是将ThreadLocalMap中Entry的key设计为弱引用容易导致内存泄漏问题,相反地,将key设置为弱引用反而防止了内存泄漏的发生。
Entry的key设计为弱引用是JDK在尽量避免程序出现内存泄漏,通过上文的分析可以看出ThreadLocal做了保护措施,在操作ThreadLocal时,如果发现key为null也就代表这些节点已经是过期节点,就会将其自发的清理掉。
所以,如果在线程池(线程复用)环境下,如果还会调用ThreadLocal的
set/get/remove方法,就不会发生长期的内存泄漏问题。同时我们想想,如果key设计成强引用而不是弱引用会怎么样?
如果key设计为强引用,外部的ThreadLocal引用被置为null了,此时Entry中的key所引用ThreadLocal对象就没有了存在的意义,无法获取到,还没法被回收,造成了内存泄漏。
达成ThreadLocal长期性内存泄漏的条件有哪些?
- ThreadLocal被外部回收
- 线程被复用
- 没有再调用
set、get、和remove方法
那些操作会清理过期的key呢?
- 调用set()方法时,采样清理、全量清理,扩容时还会继续检查。
- 调用get()方法,没有直接命中,向后环形查找时。
- 调用remove()时,除了清理当前Entry,还会向后继续清理。
7. ThreadLocal的最佳实践
虽然ThreadLocal有避免内存泄漏发生的机制,但并不是万无一失的,所以在我们使用时也要注意一些。
使用ThreadLocal的最佳实践 :
- 一般建议将其声明为
static final或者static的,避免频繁创建ThreadLocal实例。 - 每次使用完ThreadLocal,都尽量调用它的
remove()方法,清理数据。 - 尽量避免存储大对象,如果非要存,那么尽量在访问完成后及时调用
remove()删除掉。
8. ThreadLocal 应用场景
8.1 用于保存登录用户信息
在ThreadLocal中保存登录用户的信息,这样方便在业务层中就能方便的获取到用户信息。
这里实现的例子是在拦截器(刷新用户登录token的拦截器,用于防止用户登录过期)中保存登录用户的信息到ThreadLocal中,在Controller层方法执行完毕后,页面渲染完成后再清除ThreadLocal中保存的用户信息,防止内存泄漏。
使用Session也可以实现响应的功能,但是不建议使用Session,原因有两点:
- 登陆不一定用session实现,后期就会用Redis代替session。
- 在业务层获取session需要调用servlet相关的API,或者把session传递到service层。用起来不太方便,而且session是web层的技术,尽量不要进业务层。
拦截器实现:
/** * token 刷新拦截器 */ public class RefreshTokenInterceptor implements HandlerInterceptor { private StringRedisTemplate stringRedisTemplate; public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) { this.stringRedisTemplate = stringRedisTemplate; } @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { // 获取token String token = request.getHeader("authorization"); String userToken = LOGIN_USER_KEY + token; // 根据token从redis中获取 user 信息 Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(userToken); if (userMap.isEmpty()) { return true; } // 获取 user 信息 UserDTO user = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false); // 刷新redis缓存过期时间 stringRedisTemplate.expire(userToken, LOGIN_USER_TTL, TimeUnit.MINUTES); // 用户已经登录将,用户信息保存到ThreadLocal中 UserHolder.saveUser(user); return true; } @Override public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { // 移除User,避免内存泄漏 UserHolder.removeUser(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
操作ThreadLocal的工具类:
public class UserHolder { private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>(); public static void saveUser(UserDTO user){ tl.set(user); } public static UserDTO getUser(){ return tl.get(); } public static void removeUser(){ tl.remove(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
整理本文时参考的文章:
-
相关阅读:
FRED应用:激光二极管的模拟
Java笔试题总结
有哪些免费的数据恢复软件?EasyRecovery免费版下载
郑州灵活用工平台的市场价值大吗?
我发布了一款基于RBAC权限模型实现的通用后台管理系统
BUUCTF reverse wp 76 - 80
JAVA中的static 关键字
SQL学习路径
力扣刷题记录141.1-----34. 在排序数组中查找元素的第一个和最后一个位置
225. 用队列实现栈、232. 用栈实现队列、622. 设计循环队列
- 原文地址:https://blog.csdn.net/qq_51628741/article/details/127714393
