-
【教学类-12-02】20221105《连连看12*4-不重复24个)(小班主题《白天与黑夜》)
效果展示:

两列两列连连看

背景需求:
在前一篇【教学类-12-01】20221105《连连看8*4》(小班主题《白天与黑夜》)中已经说明背景需求,本篇考虑到幼儿的能力特点(能力强的画的太快了),特地修改图形的大小和间距,增加画线的次数,提升难度。
本文核心代码与前一篇相同,只是修改了word里的字号和间距
链接位置:
1、生成的PDF保存在这里——C:\Users\jg2yXRZ\OneDrive\桌面\连连看\
(没有“打印”文件夹也不影响)
2、py文件的位置( 放在电脑任意位置都不影响运行,我这里为了便于查找,放在D:/test下

代码设计
- '''
- 作者:阿夏
- 时间:2022年11月4日连连看12*4)
- (A4竖排12*4张,纵向中间剪切))
- '''
- import os
- num=int(input('生成多少份\n'))
- Number=int(input('每页制作多少个(24个)\n'))
- print('----------第1步:提取所有图案------------')
- list=['✿','☸','✪','☁','➹','✈','☂','☃','◐','☼','☯','◎','❤','♨','☋','♘','★','♫','❀','〼','✉','☏','♕','♖']
- print(len(list))# 一共24个图案
- print('----------第2步:新建一个临时文件夹------------')
- # 新建一个”装N份word和PDF“的文件夹
- os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\零时Word')
- print('----------第3步:随机抽取12个不重复的图案 ------------')
- import random
- from win32com.client import constants,gencache
- from win32com.client.gencache import EnsureDispatch
- from win32com.client import constants # 导入枚举常数模块
- import os,time
- import docx
- from docx import Document
- from docx.shared import Pt
- from docx.shared import RGBColor
- from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
- from docx.oxml.ns import qn
- for nn in range( 1,num+1): #多少份
- # word = gencache.EnsureDispatch('Word.Application')
- doc =Document()
- # doc = docx.Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\连连看Python模板.docx')# 打开带docx模板(这个模板有页脚的页码,阿夏认为页码是必须的)
- # 先随机抽取12个一列
- all=[]
- n1=[]
- n2=[]
- n = random.sample(list, Number) # 24个里面随机抽取24个放入一个组nn
- print(n)
- for b1 in n[0:int(Number/2)]: # 24个里面的1-12个,提取单独数
- n1.append(b1) # 做第2列的乱序用
- all.append(b1) # 第1轮12个添入总列表 (插入Word第1列)
- # print(n1)
- # print(all)
- o1 = random.sample(n1, int(Number/2)) # 第1轮12个再随机打乱一次,不重复抽取
- for b in o1:
- all.append(b)#第1轮12个乱序排列不重复(插入Word第2列)
- # print(all)
- # # 以下代码用作第1列1-12图案,第2列12-1倒序排列
- # for bb in range(int(Number/2)-1,-1,-1):
- # print(bb)
- # all.append(n1[bb])#第1轮12个倒序排列不重复(插入Word第2列)
- # print(all)
- for b2 in n[int(Number/2):Number]: #24个里面的13-24个,提取单独数
- n2.append(b2) # 做第4列的乱序用
- all.append(b2) # 第2轮12个添入总列表 (插入Word第3列)
- # print(all)
- o2 = random.sample(n2, int(Number/2)) # 第2轮12个再随机打乱一次,不重复抽取
- for b in o2:
- all.append(b)#第2轮12个乱序排列不重复(插入Word第4列)
- # print(all)
- # # 以下代码用作第3列13-24图案,第4列24-13倒序排列
- # for bb in range(int(Number/2)-1,-1,-1):
- # print(bb)
- # all.append(n2[bb])#第2轮12个倒序排列不重复(插入Word第4列)
- # print(all)
- # 把all里面的所有元素输入到Word里
- for c in all: # 单个取值
- print(c)
- doc.add_paragraph(c)
- # 把内容按段落输入到doc这个docx文件内
- # 字体这一段一定要再写一次
- for paragraph in doc.paragraphs:
- for run in paragraph.runs:
- run.font.size = Pt(56) # 数字题目字体大小
- run.font.bold = False #数字题目字体是否加粗 不加粗,5*8再加粗比较满,压抑了
- run.font.name = 'Arial' # 控制是英文时的字体
- run.element.rPr.rFonts.set(qn('w:eastAsia'), '宋体') # 控制数字是中文时的字体
- # paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.LEFT # 设置数字页眉居中对齐
- paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 设置数字页眉居中对齐
- # paragraph.paragraph_format.line_spacing=1 #数字中文字的段行距
- paragraph.paragraph_format.line_spacing = Pt(56) #数字段间距
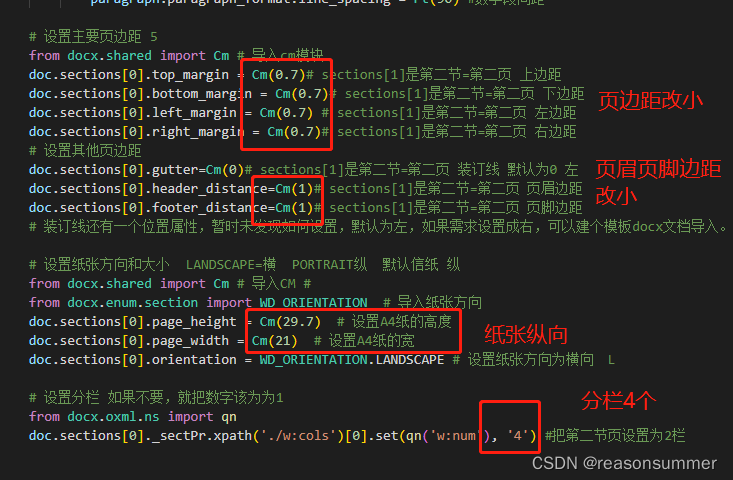
- # 设置主要页边距 5
- from docx.shared import Cm # 导入cm模块
- doc.sections[0].top_margin = Cm(0.7)# sections[1]是第二节=第二页 上边距
- doc.sections[0].bottom_margin = Cm(0.7)# sections[1]是第二节=第二页 下边距
- doc.sections[0].left_margin = Cm(0.7) # sections[1]是第二节=第二页 左边距
- doc.sections[0].right_margin = Cm(0.7)# sections[1]是第二节=第二页 右边距
- # 设置其他页边距
- doc.sections[0].gutter=Cm(0)# sections[1]是第二节=第二页 装订线 默认为0 左
- doc.sections[0].header_distance=Cm(1)# sections[1]是第二节=第二页 页眉边距
- doc.sections[0].footer_distance=Cm(1)# sections[1]是第二节=第二页 页脚边距
- # 装订线还有一个位置属性,暂时未发现如何设置,默认为左,如果需求设置成右,可以建个模板docx文档导入。
- # 设置纸张方向和大小 LANDSCAPE=横 PORTRAIT纵 默认信纸 纵
- from docx.shared import Cm # 导入CM #
- from docx.enum.section import WD_ORIENTATION # 导入纸张方向
- doc.sections[0].page_height = Cm(29.7) # 设置A4纸的高度
- doc.sections[0].page_width = Cm(21) # 设置A4纸的宽
- doc.sections[0].orientation = WD_ORIENTATION.LANDSCAPE # 设置纸张方向为横向 L
- # 设置分栏 如果不要,就把数字该为为1
- from docx.oxml.ns import qn
- doc.sections[0]._sectPr.xpath('./w:cols')[0].set(qn('w:num'), '4') #把第二节页设置为2栏
- # doc.Save()# 把有空格的1.docx保存
- doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\连连看\零时Word\{}.docx'.format('%02d'%nn))
- from docx2pdf import convert
- # docx 文件另存为PDF文件
- inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
- outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
- # 先创建 不存在的 文件
- f1 = open(outputFile, 'w')
- f1.close()
- # 再转换往PDF中写入内容
- convert(inputFile, outputFile)
- print('----------第4步:把都有PDF合并为一个打印用PDF------------')
- # 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
- import os
- from PyPDF2 import PdfFileMerger
- target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word'
- pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
- pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
- pdf_lst.sort()
- file_merger = PdfFileMerger()
- for pdf in pdf_lst:
- print(pdf)
- file_merger.append(pdf)
- file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/连连看/(打印合集)连连看{}乘4({}份).pdf".format(int(Number/2),num))
- file_merger.close()
- # doc.Close()
- # print('----------第5步:删除临时文件夹------------')
- import shutil
- shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/连连看/零时Word') #递归删除文件夹,即:删除非空文件夹
运行说明:
1、运行代码需要输入的信息


生成Word和PDF过程中,会有一个“零时Word”文件夹“暂时出现。
“零时Word”文件夹里面的内容(30份)

30份全部生成后,“零时Word”文件夹会被删除,留下最后需要的打印合并PDf(30份随机的连连看)


重点代码:
1、图案的选择 :从24个不同的文字符号图案

2、确认4列中12个图案的排位,导入ALL列表

3、all里面的图案按预定计划写入Word的列,设置字体大小和段间距(这里是重点)

4、页边距与分栏
视频时长
运行时长:连连看12*4,30份,运行时长1分0秒
连连看12乘4_30份
最后的效果图
(1)高难度:一列12个图,连线时间长一点,
这一套每个图案都有了,所以幼儿不需要交换。
(2)《统计》有几个爱心,几个王冠(都是2个)

感悟:
千变万化的随机抽取,实现多种难度的学具设计。
-
相关阅读:
centos服务器a.sh内如何 在指令中自动加入当前时间?
Maven中的小学问(版本问题、打包问题等)
java-net-php-python-ssm出版社管理系统计算机毕业设计程序
SpringBoot集成Prometheus实现监控
java计算机毕业设计高校共享机房管理系统的设计与实现源码+系统+lw文档+mysql数据库+部署
不一样的网络协议-------KCP协议
MapStruct代码生成器使用
Real-Time Rendering——7.8 Volumetric Shadow Techniques体积阴影技术
制作web3d动态产品展示的优点
设计模式学习笔记 - 装饰者模式
- 原文地址:https://blog.csdn.net/reasonsummer/article/details/127705111
