-
leetcode每日一题复盘(10.23~10.29)
leetcode 450 删除二叉搜索树中的节点
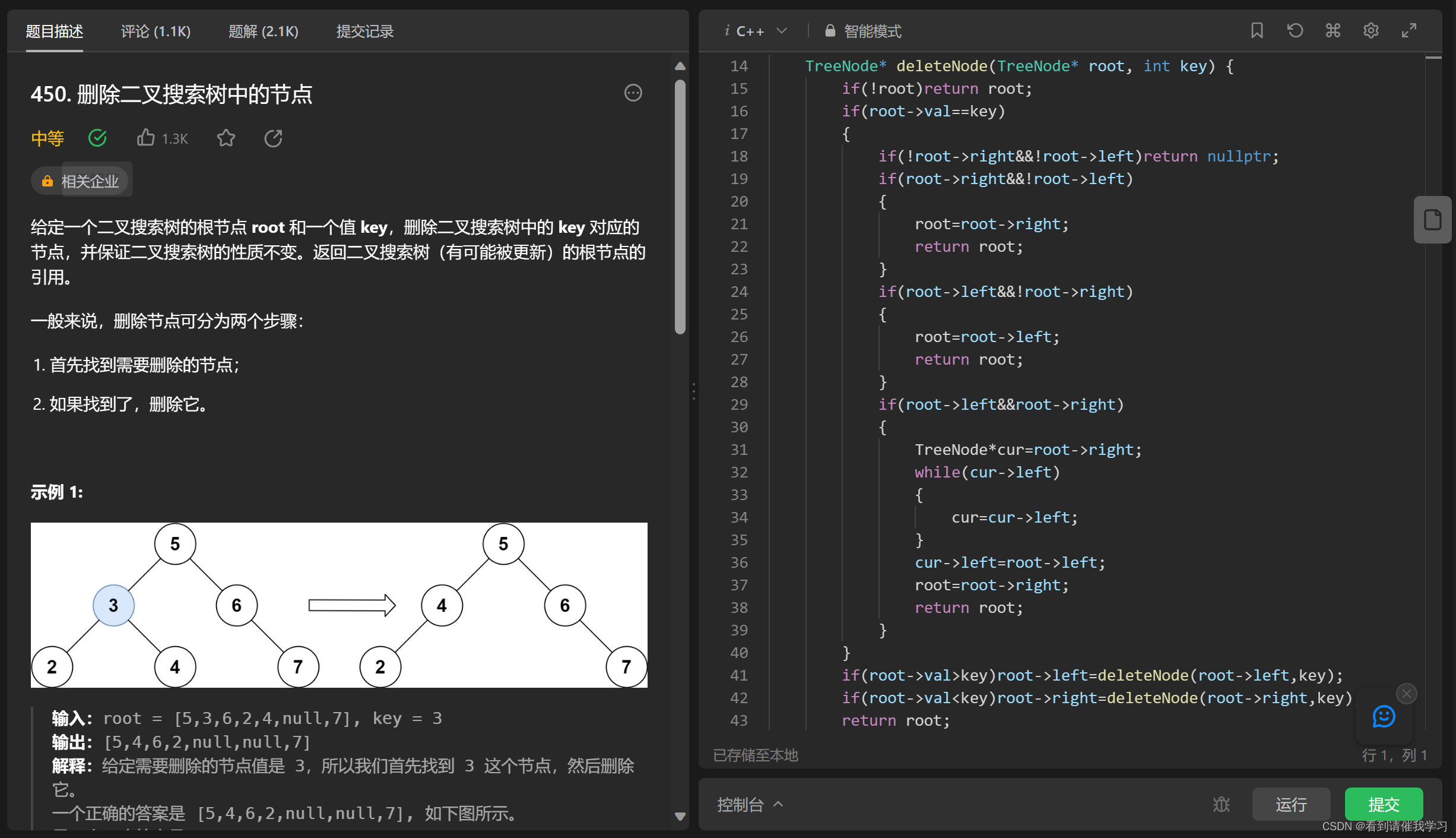
见到二叉搜索树第一时间就应该想起用中序遍历(本题用哪种遍历都可以,因为本质上是查找),知道用什么遍历之后接下来想如何删除节点了(左右遍历根据节点大小决定向左向右移动)
遍历找不到目标节点,就不用进行操作直接返回根节点就好了
当遍历找到要删除的节点(root)时,根据子树情况进行分类处理:
1.左右子树都为空:
这种情况直接返回nullptr就可以了,因为删除节点相当于把节点变为空
2.左子树空右子树不为空
这种情况把要删除节点直接赋值成他的右子树即可,相当于删除了root节点,也可以直接返回右子树
3.右子树空左子树不为空
这种情况同上一种一样,本质是返回新节点
4.左右子树都存在
这种情况需要把右子树的第一个节点的位置顶上到原来节点root的位置,而左子树应该接在右子树的最左边,返回右子树的第一个节点
再一次讲回有返回值的递归:
如果递归是有返回值的(非bool型),那么在递归的时候必然是有变量来承接递归的返回值的
因此设计递归的时候用变量来接返回值
如果是返回bool型的递归,可以用if条件来判断,这种情况一般是查找一条符合条件的路径
leetcode 699 修剪二叉搜索树
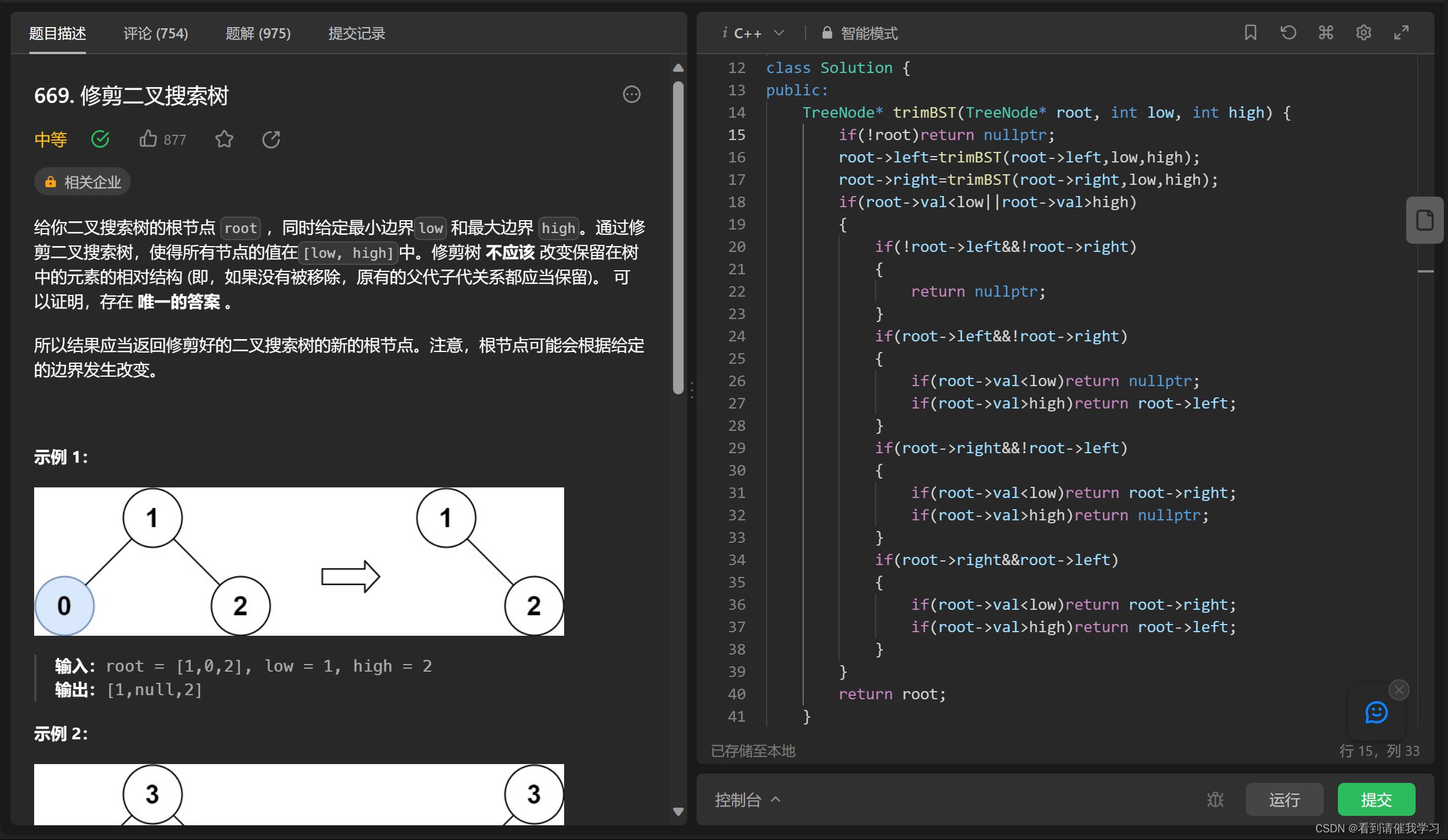
类似于上一题的删除操作,但是有些地方不同,同样是删除操作,为什么一个是前序遍历一个是后序遍历呢?这确实让人迷惑,一开始我就写错了
原因是上一题的删除操作只涉及到一个节点(因为节点的值唯一),所以可以自顶向下进行操作,找到该节点就可以直接删除了;而本题涉及到n多个节点,如果使用前序遍历会导致剪掉一个节点后,接上去的那个节点无法继续剪枝!因此需要自底向上进行操作,符合条件的就不改变,不符合操作的进行对应剪枝,从底开始重构二叉搜索树,最后返回顶上的根
因此需要根据题目实际情况选择哪种遍历方式
leetcode 17 电话号码的字母组合

开始涉及到了回溯算法,说到回溯算法就应该知道backtrack是纵向遍历,for是横向遍历(把数据排成一个N叉树)
回溯算法本质上仍是递归,我们就可以用递归三部曲去设计回溯算法
1.设计回溯所需要的参数
除了需要遍历的数据外,还有其他在遍历时需要用到的参数(在这一题中就是num,用来记录递归的层数)
2.递归结束的条件
当递归层数达到要求的时候就可以return了
3.单层递归
当返回的数据是k位时,需要k层递归,相当于树的深度是k;遍历数据的长度是n,相当于树的宽度是n,n个数据就有n个子树
先回溯递归,进行纵向遍历(选择层数),然后再进行横向遍历,因此是backtrack里包含for
在for中进行数据处理以及递归,回溯等操作
这题第一个点是字符串的转换,要根据字符串里面的数字转换到对应的集合(借助哈希表),再在集合里面进行遍历操作,而且每一次遍历的集合都不一样,属于是不同数据之间的组合
根据传入的字符串和层数,获取对于的字符,将其转换为整数,作为哈希表的索引,来获取需要遍历的数据;for循环遍历对应数据,同时进行回溯递归
leetcode 39 组合总和

39题和40题是一对姐妹题,在这里我一起讲一下,更好地理解回溯算法
39题:遍历数据不重复,同一个数字可以重复选取,但不能是同一种组合(数量相同,顺序不同)
40题:遍历数据可重复,同一个数字不可以重复选取,不能是同一种组合
了解两题就不同就可以根据需求更好地设计算法啦
回溯算法的模板大概就是下面这段伪代码这样,每次根据需求填空即可
- backtracking(参数)
- {
- 终止条件;
- for循环
- {
- backtracking(参数);
- }
- }
39题因为允许重复选取同一个值,因此在for循环中的回溯的参数可以包含自身(i),而不是寻常的i+1
相当于进行纵向遍历的时候仍是从第一个数开始遍历,同时用剪枝操作代替了sum>target,提高了运行效率

40题感觉比39题难一点,如果是刚学习回溯算法的新手还真不好做,主要是对模型的抽象树不够了解,对题目需求没明白
复制一下刚才的需求:遍历数据可重复,同一个数字不可以重复选取,不能是同一种组合
同一个数字不能重复选取,因此我们for循环里面的回溯参数就需要是i+1,而遍历的数据可能会导致重复,这就是这一题的难点:如何避免重复数据出现
一开始我想用unordered_set结果是超时,candidate[i]==candidate[i-1]虽然想过但是条件没写全,错过正确答案
一种方法是排序+前后数据对比,也就是图片中的那种解法,比较好理解
另一种方法是排序+vector
记录每一次遍历的bool值,true表示可以纵向遍历(没有同一个数字重复选取),false表示横向遍历(存在重复数字因此横向遍历) - vector
- vector<int> path;
- void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) {
- if (sum == target) {
- result.push_back(path);
- return;
- }
- for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) {
- // used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- // used[i - 1] == false,说明同一树层candidates[i - 1]使用过
- // 要对同一树层使用过的元素进行跳过
- if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) {
- continue;
- }//横向遍历时遇到前一个与当前相等的情况
- sum += candidates[i];
- path.push_back(candidates[i]);
- used[i] = true;
- backtracking(candidates, target, sum, i + 1, used); // 和39.组合总和的区别1,这里是i+1,每个数字在每个组合中只能使用一次
- used[i] = false;
- sum -= candidates[i];
- path.pop_back();
- }
- }
- public:
- vector
- vector<bool> used(candidates.size(), false);
- path.clear();
- result.clear();
- // 首先把给candidates排序,让其相同的元素都挨在一起。
- sort(candidates.begin(), candidates.end());
- backtracking(candidates, target, 0, 0, used);
- return result;
- }
- };
leetcode 131 分割回文串

又是一道没做出来的题,卡在不知道怎么切割还有如何存放每一次需要检查的字符串,总的来说是对模型不够了解,不清楚每一步是怎么出来的,还有就是对模板方法产生依赖,总想着把字符加到tmp后面回溯的时候再吐出来,没有根据题目设计算法
首先是要清楚如何分割的,我们可以想象有一条线,这条线从第一个字符后开始移动一直直到末尾,线前面的元素就是我们需要判断的字符串,a,aa,aab,分割三次就完成了我们的横向遍历;那纵向遍历怎么搞,这时候就容易晕了又是i又是startindex的,所以我们需要了解他们代表着什么,i可以看作工作指针,在for循环横向遍历数据的时候移动,而startindex可以看作数据的开头啦
我们都知道纵向遍历是回溯那么当前工作指针后面的元素就是我们下一次回溯需要遍历的元素,即工作指针指向a,那么剩余元素ab即下一次需要遍历的数据(backtrack),因此i+1
怎么存放每一次检查的字符串呢,这就用到了substr方法复制子字符串,就不用在字符串s本身进行操作了,而且破坏了s后面怎么遍历呢
之后就是判断回文串了,这个比较简单,但是有更好的方法可以提高运行效率
for循环是获取线前面的元素,当作字符串拿来判断是否是回文;
backtracking递归是移动startindex指针,将原来线后面的元素拿来作为新的数据进行切割;
-
相关阅读:
Redis集群操作-----主从互换
电脑重装系统后内存占用高怎么解决?
5款好用的工具软件推荐给你
leetcode T31:下一排列
MAC 安装miniconda
[Linux]文件系统
深入理解多线程(第一篇)
Join and meet
【Django】Django4.1.2使用xadmin避坑指南
32 数据分析(下)pandas介绍
- 原文地址:https://blog.csdn.net/vh_127/article/details/133992118
