-
Apache Sqoop_2
Apache Sqoop系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Sqoop系列
#博学谷IT学习技术支持
前言

sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的HDFS、HIVE中导出数据到关系数据库mysql等。

一、Sqoop数据导入至Hive–HCatalog API
使用HCatalog API的原因主要是为了压缩,这里指定了表的文件存储格式为ORC。
-- 手动在hive中建一张表 create table test.emp_hive ( id int, name string, deg string, salary int, dept string ) row format delimited fields terminated by '\t' stored as orc; -- 将mysql表的数据导入到HIVE ORC格式,用HCatalog,原生态的方式不支持 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table emp \ --fields-terminated-by '\t' \ --hcatalog-database test \ --hcatalog-table emp_hive \ -m 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
二、Sqoop数据导入–条件部分导入
在实际开发中,有时候我们从RDBMS(MySQL)中导入数据时,不需要将数据全部导入,而只需要导入满足条件的数据,则需要进行条件导入。
使用sql query语句来进行查找时,不能加参数–table;并且必须要添加where条件;
并且where条件后面必须带一个$CONDITIONS这个字符串;
并且这个sql语句必须用单引号,不能用双引号
sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --target-dir /sqoop/result5 \ --query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \ --delete-target-dir \ --fields-terminated-by '\001' \ --m 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
三、Sqoop数据导入–增量导入
增量导入,之前已经导入过一次,下一次只导入新增加或者修改的数据
# 首先我们要在mysql中创建一个customer表,指定一个时间戳字段 create table userdb.customertest( id int,name varchar(20), last_mod timestamp default current_timestamp on update current_timestamp ); #此处的时间戳设置为在数据的产生和更新时都会发生改变. #插入如下记录: insert into userdb.customertest(id,name) values(1,'neil'); insert into userdb.customertest(id,name) values(2,'jack'); insert into userdb.customertest(id,name) values(3,'martin'); insert into userdb.customertest(id,name) values(4,'tony'); insert into userdb.customertest(id,name) values(5,'eric'); #第一次全量导入:此时执行sqoop指令将数据导入hdfs: sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --table customertest \ --username root \ --password 123456 \ --target-dir /sqoop/lastmodifiedresult \ --m 1 #再次插入一条数据进入customertest表 insert into userdb.customertest(id,name) values(6,'james'); #更新一条已有的数据,这条数据的时间戳会更新为我们更新数据时的系统时间. update userdb.customertest set name = 'NEIL' where id = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
#第二次增量导入:将新插入的两条数据导入到HIVE 先创建HIVE表 create table test.customertest ( id int, name string, last_mod string ) row format delimited fields terminated by '\t' stored as orc; #导入增量数据 sqoop import \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --query "select * from customertest where last_mod >'2022-10-30 19:50:00' and \$CONDITIONS" \ --fields-terminated-by '\001' \ --hcatalog-database test \ --hcatalog-table customertest \ -m 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
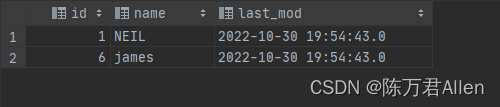
四、Sqoop数据导出–全量导出
1.将HDFS数据导出的MySql
sqoop导出操作最大的特点是,目标表需要自己手动提前创建。
1、在大数据中,数据的导出一般发生在大数据分析的最后一个阶段
2、将分析后的指标导入一些通用的数据库系统中,用于进一步使用
3、导入到MySQL时,需要在MySQL中提前创建表#step1:MySQL中建表 create table employee ( id int primary key, name varchar(20), deg varchar(20), salary int, dept varchar(10));- 1
- 2
- 3
- 4
- 5
- 6
- 7
解释:将HDFS/sqoop/result1/目录下的文件内容,导出到mysql中userdb数据库下的employee表
#step2:从HDFS导出数据到MySQL sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table employee \ --export-dir /sqoop/result1/- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.将Hive数据导出的MySql
将Hive中test数据库下的emp_hive表导出到MySQL的userdb数据库中employee表
#step3:从Hive导出数据到MySQL #首先清空MySQL表数据 truncate table employee; sqoop export \ --connect "jdbc:mysql://192.168.88.80:3306/userdb? useUnicode=true&characterEncoding=utf-8" \ --username root \ --password 123456 \ --table employee \ --hcatalog-database test \ --hcatalog-table emp_hive \ --input-fields-terminated-by '\t' \ -m 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

五、Sqoop数据导出–增量导出(比较少用,了解)
- updateonly:只增量导出更新的数据
- allowerinsert:既导出更新的数据,也导出新增的数据
1.updateonly模式
#在HDFS文件系统中/sqoop/updateonly/目录的下创建一个文件updateonly_1.txt hadoop fs -mkdir -p /sqoop/updateonly/ hadoop fs -put updateonly_1.txt /sqoop/updateonly/ 1201,gopal,manager,50000 1202,manisha,preader,50000 1203,kalil,php dev,30000 #手动创建mysql中的目标表 CREATE TABLE userdb.updateonly ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT ); #先执行全部导出操作: sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table updateonly \ --export-dir /sqoop/updateonly/updateonly_1.txt #新增一个文件updateonly_2.txt:修改了前三条数据并且新增了一条记录 1201,gopal,manager,1212 1202,manisha,preader,1313 1203,kalil,php dev,1414 1204,allen,java,1515 hadoop fs -put updateonly_2.txt /sqoop/updateonly/ #执行更新导出: sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table updateonly \ --export-dir /sqoop/updateonly/updateonly_2.txt \ --update-key id \ --update-mode updateonly #解释: --update-key id 根据id这列来判断id两次导出的数据是否是同一条数据,如果是则更新 --update-mode updateonly 导出时,只导出第一次和第二次的id都有的数据,进行更新,不会导出HDFS中新增加的数据- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46

2.allowinsert模式
#手动创建mysql中的目标表 CREATE TABLE userdb.allowinsert ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT); #先执行全部导出操作 sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root \ --password 123456 \ --table allowinsert \ --export-dir /sqoop/updateonly/updateonly_1.txt #执行更新导出 sqoop export \ --connect jdbc:mysql://192.168.88.80:3306/userdb \ --username root --password 123456 \ --table allowinsert \ --export-dir /sqoop/updateonly/updateonly_2.txt \ --update-key id \ --update-mode allowinsert- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
多增加了一条数据

总结
今天继续和大家分享一下Sqoop系列2,常用的导入和导出方法。
-
相关阅读:
Linux操作系统学习:day05
Visual Studio C++工程——包含目录、库目录、附加依赖项、附加包含目录、附加库目录配置与静态库、动态库的调用
VALSE2022天津线下参会个人总结8月23日-2
为什么科技型企业需要“贯标”?
基础算法训练(五)折半插入排序
牛客前端刷题(四)——微信小程序篇
批次大小对ES写入性能影响初探
Spirngboot中文乱码解决方案
创建MyBatis的核心配置文件、创建mapper接口和映射文件
【HCIA-Datacom】华为VRP系统
- 原文地址:https://blog.csdn.net/weixin_53280379/article/details/127602234
