-
嵌入式分享合集90
带着废品zhang看中医~~ 现在这中医骗子太多 太忽悠 就是卖药的 就和xinguan一样 告诉你多严重吓唬你 好了言归正传
一、电容的作用
电容是电路设计中最为普通常用的器件,是无源元件之一,有源器件简单地说就是需能(电)源的器件叫有源器件,无需能(电)源的器件就是无源器件。
电容的作用和用途一般都有好多种,如:在旁路、去耦、滤波、储能方面的作用;在完成振荡、同步以及时间常数的作用。
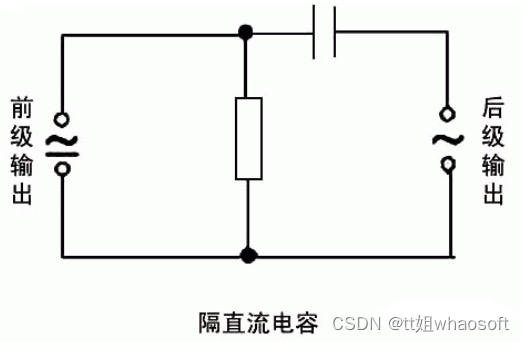
隔直流:作用是阻止直流通过而让交流通过。
旁路(去耦):为交流电路中某些并联的元件提供低阻抗通路。

旁路电容:旁路电容,又称为退耦电容,是为某个器件提供能量的储能器件。它利用了电容的频率阻抗特性,理想电容的频率特性随频率的升高,阻抗降低,就像一个水塘,它能使输出电压输出均匀,降低负载电压波动。旁路电容要尽量靠近负载器件的供电电源管脚和地管脚,这是阻抗要求。
在画PCB时候特别要注意,只有靠近某个元器件时候才能抑制电压或其他输信号因过大而导致的地电位抬高和噪声。说白了就是把直流电源中的交流分量,通过电容耦合到电源地中,起到了净化直流电源的作用。如下图C1为旁路电容,画图时候要尽量靠近IC1。
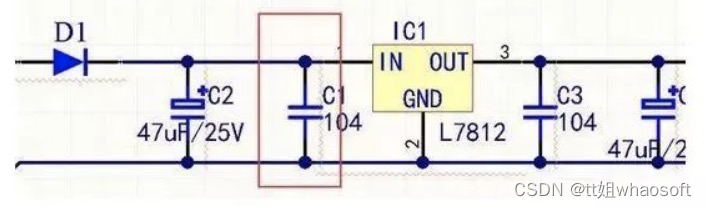 去耦电容:去耦电容,是把输出信号的干扰作为滤除对象,去耦电容相当于电池,利用其充放电,使得放大后的信号不会因电流的突变而受干扰。它的容量根据信号的频率、抑制波纹程度而定,去耦电容就是起到一个“电池”的作用,满足驱动电路电流的变化,避免相互间的耦合干扰。
去耦电容:去耦电容,是把输出信号的干扰作为滤除对象,去耦电容相当于电池,利用其充放电,使得放大后的信号不会因电流的突变而受干扰。它的容量根据信号的频率、抑制波纹程度而定,去耦电容就是起到一个“电池”的作用,满足驱动电路电流的变化,避免相互间的耦合干扰。旁路电容实际也是去耦合的,只是旁路电容一般是指高频旁路,也就是给高频的开关噪声提高一条低阻抗泄放途径。高频旁路电容一般比较小,根据谐振频率一般取 0.1F、0.01F 等。而去耦合电容的容量一般较大,可能是 10F 或者更大,依据电路中分布参数、以及驱动电流的变化大小来确定。

它们的区别:旁路是把输入信号中的干扰作为滤除对象,而去耦是把输出信号的干扰作为滤除对象,防止干扰信号返回电源。
耦合:作为两个电路之间的连接,允许交流信号通过并传输到下一级电路 。

用电容做耦合的元件,是为了将前级信号传递到后一级,并且隔断前一级的直流对后一级的影响,使电路调试简单,性能稳定。如果不加电容交流信号放大不会改变,只是各级工作点需重新设计,由于前后级影响,调试工作点非常困难,在多级时几乎无法实现。
滤波:这个对电路而言很重要,CPU背后的电容基本都是这个作用。
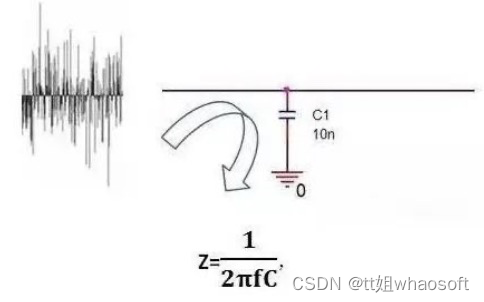
即频率f越大,电容的阻抗Z越小。当低频时,电容C由于阻抗Z比较大,有用信号可以顺利通过;当高频时,电容C由于阻抗Z已经很小了,相当于把高频噪声短路到GND上去了。
滤波作用:理想电容,电容越大,阻抗越小,通过的频率也越高。
电解电容一般都是超过 1uF ,其中的电感成分很大,因此频率高后反而阻抗会大。我们经常看见有时会看到有一个电容量较大电解电容并联了一个小电容,其实大的电容通低频,小电容通高频,这样才能充分滤除高低频。电容频率越高时候则衰减越大,电容像一个水塘,几滴水不足以引起它的很大变化,也就是说电压波动不是你很大时候电压可以缓冲。
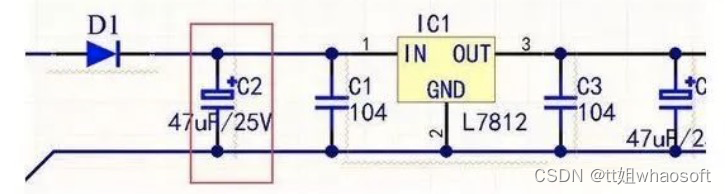
图C2温度补偿:针对其它元件对温度的适应性不够带来的影响,而进行补偿,改善电路的稳定性。
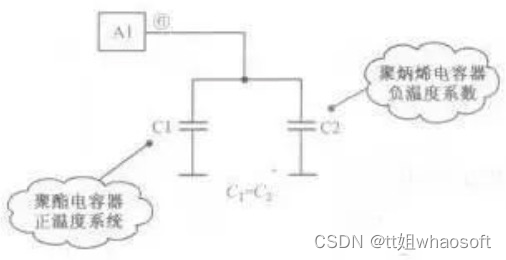
分析:由于定时电容的容量决定了行振荡器的振荡频率,所以要求定时电容的容量非常稳定,不随环境湿度变化而变化,这样才能使行振荡器的振荡频率稳定。因此采用正、负温度系数的电容并联,进行温度互补。当工作温度升高时,C1的容量在增大,而C2的容量在减小,两只电容并联后的总容量为两只电容容量之和,由于一个容量在增大而另一个在减小,所以总容量基本不变。同理,在温度降低时,一个电容的容量在减小而另一个在增大,总的容量基本不变,稳定了振荡频率,实现温度补偿目的。
计时:电容器与电阻器配合使用,确定电路的时间常数。
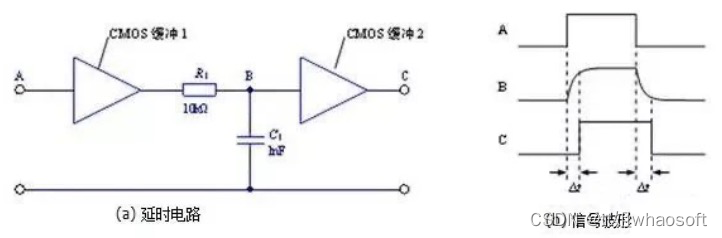
输入信号由低向高跳变时,经过缓冲1后输入RC电路。电容充电的特性使B点的信号并不会跟随输入信号立即跳变,而是有一个逐渐变大的过程。当变大到一定程度时,缓冲2翻转,在输出端得到了一个延迟的由低向高的跳变。时间常数:以常见的 RC 串联构成积分电路为例,当输入信号电压加在输入端时,电容上的电压逐渐上升。而其充电电流则随着电压的上升而减小,电阻R和电容C串联接入输入信号VI,由电容C输出信号V0,当RC (τ)数值与输入方波宽度tW之间满足:τ》》tW,这种电路称为积分电路。
调谐:对与频率相关的电路进行系统调谐,比如手机、收音机、电视机。
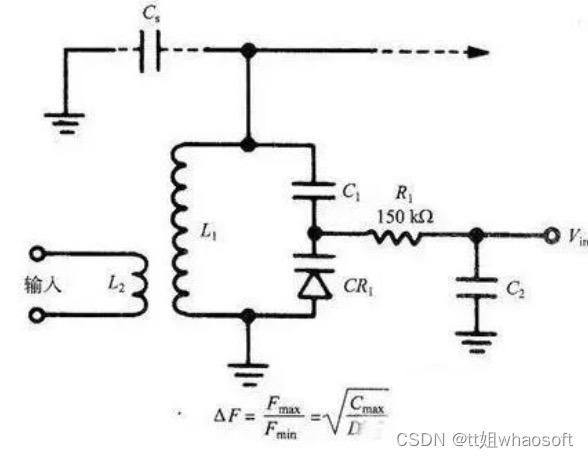
上图,变容二极管的调谐电路。
因为IC调谐的振荡电路的谐振频率是IC的函数,我们发现振荡电路的最大与最小谐振频率之比随着电容比的平方根变化。此处电容比是指反偏电压最小时的电容与反偏电压最大时的电容之比。因而,电路的调谐特征曲线(偏压一谐振频率)基本上是一条抛物线。
整流:在预定的时间开或者关半闭导体开关元件。
 储能:储存电能,用于必要的时候释放。例如相机闪光灯,加热设备等等。
储能:储存电能,用于必要的时候释放。例如相机闪光灯,加热设备等等。
一般地,电解电容都会有储能的作用,对于专门的储能作用的电容,电容储能的机理为双电层电容以及法拉第电容。其主要形式为超级电容储能,其中超级电容器是利用双电层原理的电容器。
当外加电压加到超级电容器的两个极板上时,与普通电容器一样,极板的正电极存储正电荷,负极板存储负电荷。在超级电容器的两极板上电荷产生的电场作用下,在电解液与电极间的界面上形成相反的电荷,以平衡电解液的内电场。
这种正电荷与负电荷在两个不同相之间的接触面上,以正负电荷之间极短间隙排列在相反的位置上,这个电荷分布层叫做双电层,因此电容量非常大。 whaosoft aiot http://143ai.com
二、嵌入式硬件经验提升

理解“嵌入式”的概念
1 从硬件上
将基于CPU的处围器件,整合到CPU芯片内部,比如早期基于X86体系结构下的计算机,CPU只是有运算器和累加器的功能,一切芯片要造外部桥路来扩展实现,象串口之类的都是靠外部的16C550/2的串口控制器芯片实现,而目前的这种串口控制器芯片早已集成到CPU内部,还有PC机有显卡,而多数嵌入式处理器都带有LCD控制器,但其种意义上就相当于显卡。
比较高端的ARM类Intel Xscale架构下的IXP网络处理器CPU内部集成PCI控制器(可配成支持4个PCI从设备或配成自身为CPI从设备);还集成3个NPE网络处理器引擎,其中两个对应于两个MAC地址,可用于网关交换用,而另外一个NPE网络处理器引擎支持DSL,只要外面再加个PHY芯片即可以实现DSL上网功能。IXP系列最高主频可以达到 1.8G,支持2G内存,1G×10或10G×1的以太网口或Febre channel的光通道。IXP系列应该是目标基于ARM体系统结构下由intel进行整合后成Xscale内核的最高的处理器了。
2 从软件上
就是在定制操作系统内核里将应用一并选入,编译后将内核下载到ROM中。而在定制操作系统内核时所选择的应用程序组 件就是完成了软件的“嵌入”,比如WinCE在内核定制时,会有相应选择,其中就是wordpad,PDF,MediaPlay等等选择,如果我们选择 了,在CE启动后,就可以在界面中找到这些东西,如果是以前PC上将的windows操作系统,多半的东西都需要我们得新再装。
3 理解“嵌入”
把软件内核或应用文件系统等东西烧到嵌入式系统硬件平台中的ROM中就实现了一个真正的“嵌入”。
以上的定义是重于理解型的定义,书上的定义也有很多,但在这个领域范围内,谁都不敢说自己的定义是十分确切的,包括那些专家学者们,历为毕竟嵌入式系统是计算机范畴下的一门综合性学科
嵌入式系统的分层
嵌入式系统分为4层,硬件层、驱动层、操作系统层和应用层。
1 硬件层
是整个嵌入式系统的根本,如果现在单片机及接口这块很熟悉,并且能用C和汇编语言来编程的话,从嵌入式系统的硬件层走起来相对容易,硬件层也是驱动层的基础,一个优秀的驱动工程师是要能够看懂硬件的电路图和自行完成CPLD的逻辑设计的,同时还要对操作系统内核及其调度性相当的熟悉的。但硬件平台是基础,增值还要靠软件。
硬件层比较适合于,电子、通信、自动化、机电一体、信息工程类专业的人来搞,需要掌握的专业基础知识有,单片机原理及接口技术、微机原理及接口技术、C语言。
2 驱动层
这部分比较难,驱动工程师不仅要能看懂电路图还要能对操作系统内核十分的精通,以便其所写的驱动程序在系统调用时,不会独占操作系统时间片,而导 至其它任务不能动行,不懂操作系统内核架构和实时调度性,没有良好的驱动编写风格,按大多数书上所说添加的驱动的方式,很多人都能做到,但可能连个初级的 驱动工程师的水平都达不到,这样所写的驱动在应用调用时就如同windows下我们打开一个程序运行后,再打开一个程序时,要不就是中断以前的程序,要不 就是等上一会才能运行后来打开的程序。想做个好的驱动人员没有三、四年功底,操作系统内核不研究上几编,不是太容易成功的,但其工资在嵌入式系统四层中可是最高的。
驱动层比较适合于电子、通信、自动化、机电一体、信息工程类专业尤其是计算机偏体系结构类专业的人来搞,除硬件层所具备的基础学科外,还要对数据结构与算法、操作系统原理、编译原理都要十分精通了解。
3 操作系统层
对于操作系统层目前可能只能说是简单的移植,而很少有人来自已写操作系统,或者写出缺胳膊少腿的操作系统来,这部分工作大都由驱动工程师来完成。操作系统是负责系统任务的调试、磁盘和文件的管理,而嵌入式系统的实时性十分重要。据说,XP操作系统是微软投入300人用两年时间才搞定的,总时工时是600人年,中科院软件所自己的女娲Hopen操作系统估计也得花遇几百人年才能搞定。因此这部分工作相对来讲没有太大意义。
4 应用层
相对来讲较为容易的,如果会在windows下如何进行编程接口函数调用,到操作系统下只是编译和开发环 境有相应的变化而已。如果涉及Java方面的编程也是如此的。嵌入式系统中涉及算法的由专业算法的人来处理的,不必归结到嵌入式系统范畴内。但如果涉及嵌 入式系统下面嵌入式数据库、基于嵌入式系统的网络编程和基于某此应用层面的协议应用开发(比如基于SIP、H.323、Astrisk)方面又较为复杂, 并且有难度了。
目标与定位
先有目标,再去定位。
学STM32等单片机,从硬件上讲,一方面就是学习接口电路设计,另一方面就是学习汇编和C语言的板级编程。
如果从软件上讲,就是要学习基于ARM处理器的操作系统层面的驱动、移植了。这些对于初学都来说必须明确,要么从硬件着手开始学,要么从操作系统的熟悉到应用开始学,但不管学什么,只要不是纯的操作系统级以上基于API的应用层的编程,硬件的寄存器类的东西还是要能看懂的,基于板级的汇编和C编程还是要会的。因此针对于嵌入式系统的硬件层和驱动程的人,ARM的接口电路设计、ARM的C语言和汇编语言编程及调试开发环境还是需要掌握的。
因此对于初学者必然要把握住方向,自己的目标是什么,自己要在那一层面上走。然后再着手学习较好,与ARM相关的嵌入式系统的较为实际的两个层面硬件层和驱动层,不管学好了那一层都会很有前途的。
学 ARM,从硬件上讲,一方面就是学习接口电路设计,另一方面就是学习汇编和C语言的板级编程。
如果想从嵌入式系统的应用层面的走的话,可能与ARM及其它体系相去较远,要着重研究基嵌入式操作系统的环境应用与相应开发工具链,比如WinCe操作系统下的EVC应用开发(与windows下的VC相类似),如果想再有突破就往某些音视频类的协议上靠,比如VOIP领域的基于SIP或H.323协议的应用层开发,或是基于嵌入式网络数据库的开发等等。
对于初学者来讲,要量力而行,不要认为驱动层工资高就把它当成方向了,要结合自身特点,嵌入式系统四个层面上那个层面上来讲都是有高人存在,当然高人也对应 的高工资,我是做硬件层的,以前每月工资中个人所得税要被扣上近3千大元,当然我一方面充当工程师的角色,一方面充当主管级人物的角色,两个职位我一个人 干,但上班时间就那些。硬件这方面上可能与我PK的人很少了,才让我拿到那么多的工资。
开发系统选择
很多ARM初学者都希望有一套自己能用的系统,但他们住住会产生一种错误认识就是认为处理器版本越高、性能越高越好,就象很多人认为ARM9与 ARM7好,我想对于初学者在此方面以此入门还应该理智,开发系统的选择最终要看自己往嵌入式系统的那个方向上走,是做驱动开发还是应用,还是做嵌入式系统硬件层设计与板级测试。
在某种意义上请,ARM7与9的差别就是在某些功能指令集上丰富了些,主频提高一些而已,就比如286和386。对于用户来讲可能觉查不到什么,只能是感觉速度有些快而已。
ARM7比较适合于那些想从硬件层面上走的人,因为ARM7系列处理器内部带MMU的很少,而且比较好控制,就比如S3C44B0来讲,可以很容易将 Cache关了,而且内部接口寄存器很容易看明白,各种接口对于用硬件程序控制或AXD单步命令行指令都可以控制起来,基于51单片机的思想很容易能把他 搞懂,就当成个32位的单片机,从而消除很多51工程师想转为嵌入式系统硬件ARM开发工程师的困惑,从而不会被业界某此不是真正懂嵌入式烂公司带到操作 系统层面上去,让他们望而失畏,让业界更加缺少这方面的人才。
而嵌入式系统不管硬件设计还是软件驱动方面都是十分注重接口这部分的,选择平台还要考察一个处理器的外部资源,你接触外部资源越多,越熟悉他们那你以后就业成功的机率就越高,这就是招聘时 所说的有无“相关技能”,因为一个人不可能在短短几年内把所有的处理器都接触一遍,而招聘单位所用的处理器就可能是我们完全没有见过的,就拿台湾数十家小 公司(市价几千万)的公司生产的ARM类处理器,也很好用,但这些东西通用性太差,用这些处理器的公司就只能招有相关工作经验的人了,那什么是相关工作经 验,在硬件上讲的是外围接口设计,在软件上讲是操作系统方面相关接口驱动及应用开发经验。我从业近十年,2000年ARM出现,我一天始做ARM7,然后 直接跑到了Xscale(这个板本在ARM10-11之间),一做就是五年,招人面试都不下数百人,在这些方面还是深有体会的。
我个人认为三星的 S3C44b0对初学者来说比较合适,为什么这么说哪?因为接口资源比较丰富,技术成熟,资料较多,应该十分适合于初学者,有问题可能很容易找人帮且解决,因为大多数人都很熟悉,就如同51类的单片机,有N多位专家级的人物可以给你帮忙,相关问题得以很快解答,所然业界认为这款ARM都做用得烂了,但对于初学者来,就却是件好事。
因此开发系统的选择,要看自己的未来从来目标方向、要看开发板接口资源、还要看业界的通用性。
如何成为优秀的嵌入式硬件工程师
对于硬件来讲有几个方向,就单纯信号来分为数字和模拟,模拟比较难搞,一般需要很长的经验积累,单单一个阻值或容值的精度不够就可能使信号偏差很大。因此年轻人搞的较少,随着技术的发展,出现了模拟电路数字化,比如手机的Modem射频模块,都采用成熟的套片,而当年国际上只有两家公司有此技术,自我感觉模拟功能不太强的人,不太适合搞这个。
如果真能搞定到手机的射频模块,只要达到一般程度可能月薪都在15K以上。另一类就是数字部分了,在大方向上又可分为51/ARM的单片机类,DSP类,FPGA类,国内FPGA的工程师大多是在IC设计公司从事IP核的前端验证,这部分不搞到门级,前途不太明朗,即使做个IC前端验证工程师,也要搞上几年才能胜任。DSP硬件接口比较定型,如果不向驱动或是算法上靠拢,前途也不会太大。
而ARM单片机类的内容就较多,业界产品占用量大,应用人群广,因此就业空间极大,而硬件设计最体现水平和水准的就是接口设计这块,这是各个高级硬件工程师相互PK,判定水平高低的依据。
而接口设计这块最关键的是看时序,而不是简单 的连接,比如PXA255处理器I2C要求速度在100Kbps,如果把一个I2C外围器件,最高还达不到100kbps的与它相接,必然要导致设计的失 败。这样的情况有很多,比如51单片机可以在总线接 LCD,但为什么这种LCD就不能挂在ARM的总线上,还有ARM7总线上可以外接个Winband的SD卡控制器,但为什么这种控制器接不到ARM9或 是Xscale处理器上,这些都是问题。因此接口并不是一种简单的连接,要看时序,要看参数。
一个优秀的硬件工程师应该能够在没有参考方案的前提下设计出一个在成本和性能上更加优秀的产品,靠现有的方案,也要进行适当的可行性裁剪,但不是胡乱的来,我遇到一个工程师把方案中的5V变1.8V的DC芯片, 直接更换成LDO,有时就会把CPU烧上几个。
前几天还有人希望我帮忙把他们以前基于PXA255平台的手持GPS设备做下程序优化,我问了一下情况,地 图是存在SD卡中的,而SD卡与PXA255的MMC控制器间采用的SPI接口,因此导致地图读取速度十分的慢,这种情况是设计中严重的缺陷,而不是程序 的问题,因此我提了几条建议,让他们更新试下再说。
因此想成为一个优秀的工程师,需要对系统整体性的把握和对已有电路的理解,换句话说,给你一套电路图你 终究能看明白多少,看不明白80%以上的话,说明你离优秀的工程师还差得远哪。其次是电路的调试能力和审图能力,但最最基本的能力还是原理图设计PCB绘 制,逻辑设计这块。这是指的硬件设计工程师,从上面的硬件设计工程师中还可以分出ECAD工程师,就是专业的画PCB板的工程师,和EMC设计工程师,帮 人家解决EMC的问题。
硬件工程师再往上就是板级测试工程师,就是C语功底很好的硬件工程师,在电路板调试过程中能通过自已编写的测试程序对硬件功能进行验证。然后再交给基于操作系统级的驱动开发人员。
总之,硬件的内容很多很杂,硬件那方面练成了都会成为一个高手,我时常会给人家做下方案评估,很多高级硬件工程师设计的东西,经常被我一句话否定,因此工程师做到我这种地步,也会得罪些人,但硬件的确会有很多不为人知的东西,让很多高级硬件工程师也摸不到头脑。
三、芯片指令集架构重要吗
whaosoft aiot http://143ai.com
在过去的十年中,ARM CPU厂商多次尝试打入高性能 CPU 市场,因此我们看到大量关于 ARM 努力的文章、视频和讨论也就不足为奇了,其中许多文章关注的是两种指令集架构(ISA)的差异。
在本文中,我们将汇集研究、来自非常熟悉 CPU 的人的评论以及我们的一些内部数据,以说明为什么专注于 ISA 是浪费时间,并让我们开始在我们的小冒险中,让我们参考 Anandtech 对 Jim Keller 的采访,Jim Keller 是一位工程师,他曾参与过多种成功的 CPU 设计,包括 AMD 的 Zen 和 Apple 的 A4/A5。
CISC vs RISC:过时的辩论
x86 历史上被归类为 CISC(复杂指令集计算)ISA,而 ARM 被归类为 RISC(精简指令集计算)。最初,CISC 机器旨在执行更少、更复杂的指令,并为每条指令做更多的工作。RISC 使用更简单的指令,执行起来更容易、更快。今天,这种区别已不复存在。用Jim keller的话来说:
“RISC 刚问世时,x86 是半微码(half microcode)。所以如果你看一下die,一半的芯片是 ROM,或者可能是三分之一。从事RISC 人可以说 RISC 芯片上没有 ROM,因此我们获得了更高的性能。但是现在ROM太小了,找不到了。其实加法器这么小,你很难找到吗?今天限制计算机性能的是可预测性,两个大的是指令/分支可预测性和数据局部性。”
简而言之,就性能而言,RISC/ARM 和 CISC/x86 之间没有有意义的区别。重要的是保持内核的供给,并提供正确的数据,这些数据专注于缓存设计、分支预测、预取以及各种很酷的技巧,比如预测加载是否可以在存储到未知地址之前执行。
在2013 年,Blem 等研究人员发现了一种方法。研究了 ISA 对各种 x86 和 ARM CPU [1]的影响,发现 RISC/ARM 和 CISC/x86 在很大程度上已经收敛。
Blem等人得出的结论是,ARM 和 x86 CPU 在功耗和性能方面存在差异,主要是因为它们针对不同的目标进行了优化。指令集在这里并不重要,重要的是实现指令集的 CPU 的设计:
他们研究的主要发现是:
-
尽管平均周期计数差距 <= 2.5 倍,但实现之间存在很大的性能差距。
-
指令计数和混合与一阶 ISA 无关。
-
性能差异是由独立于 ISA 的微架构差异产生的。
-
能耗再次与 ISA 无关。
-
ISA 差异具有实施意义,但现代微架构技术使它们没有实际意义;一个 ISA 从根本上说并不是更有效。
-
ARM 和 x86 实现只是针对不同性能级别优化的设计点
以上观点来自论文《Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures》
换句话说,ARM ISA 与低功耗没有任何关系。同样,x86 ISA 与高性能无关。我们今天熟悉的基于 ARM 的 CPU 恰好是低功耗的,因为 ARM CPU 的制造商将他们的设计定位于手机和平板电脑。英特尔和 AMD 的 x86 CPU 以更高的性能为目标,具有更高的功率。
为了给 ISA 发挥重要作用的想法泼冷水,英特尔以基于 x86 的 Atom 内核为目标。Federal University of Rio Grande do Sul [6] 进行的一项研究得出结论:“对于所有测试用例,基于 Atom 的集群被证明是在低功耗处理器上使用多级并行性的最佳选择。”
正在测试的两种内核设计是 ARM 的 Cortex-A9 和英特尔的 Bonnell 内核。有趣的是,Bonnell 是一种有序设计,而 Cortex-A9 是一种无序设计,应该为 Cortex-A9 带来性能和能源效率的胜利,但在研究中使用的测试中,Bonnell 出现了在这两个类别中都领先。
解码器差异:杯水车薪
另一个经常重复的真理是 x86 有一个显著的“ecode tax”障碍。ARM 使用固定长度的指令,而 x86 的指令长度不同。因为您必须在知道下一条指令从哪里开始之前确定一条指令的长度,所以并行解码 x86 指令更加困难。这对于 x86 来说是一个缺点,但对于高性能 CPU 来说,这并不重要,用 Jim Keller 的话来说:
“有一段时间我们认为可变长度指令真的很难解码。但我们一直在想办法做到这一点。.所以当你在建造小型电脑时,固定长度的指令看起来真的很好,但如果你正在建造一台非常大的电脑,预测或找出所有指令的位置,它并没有支配die。所以没那么重要。”
我们深入并亲自对此进行了检查。
通过未记录的 MSR 禁用 op 缓存后,我们发现 Zen 2 的 fetch 和 decode 路径比 op cache 路径消耗大约 4-10% 的核心功率,或 0.5-6% 的封装功率。在实践中,解码器将消耗更少的核心或封装功率。Zen 2 并非设计为在禁用微操作缓存的情况下运行,并且我们使用的基准 (CPU-Z) 适合 L1 缓存,这意味着它不会对内存层次结构的其他部分造成压力。对于其他工作负载,来自 L2 和 L3 高速缓存以及内存控制器的功耗将使解码器的功耗变得不那么重要。
事实上,在禁用 op 缓存的情况下,一些工作负载的功耗降低了。解码器的功耗被其他核心组件的功耗所淹没,特别是如果操作缓存让它们得到更好的馈送。这与Jim Keller的评论一致。
研究人员也同意这个观点。
2016 年,Helsinki Institute of Physics[2]支持的一项研究着眼于英特尔的 Haswell 微架构。在那里,Hiriki 等人估计,Haswell 的解码器消耗了 3-10% 的封装功率。该研究得出的结论是,“x86-64 指令集并不是生产节能处理器架构的主要障碍。”
在另一项研究中,Oboril 等人 [5] 在 Intel Ivy Bridge CPU 上测量获取和解码能力。虽然那篇论文专注于为核心组件开发一个准确的功率模型,并没有直接得出关于 x86 的结论,但它的数据再次表明解码器的功率是沧海一粟。
但显然解码器功率不是零,这意味着它是一个潜在改进的领域。毕竟,当您受到功率限制时,每一瓦特都很重要。即使在台式机上,多线程性能也常常受到功率的限制。我们已经看到 x86 CPU 架构师使用 op 缓存来提供每瓦性能,所以让我们从 ARM 方面看一下。
ARM 解码也很贵
Hirki 等人还得出结论:“切换到不同的指令集只会节省少量功率,因为在现代处理器中无法消除指令解码器。”
ARM Ltd 自己的设计就是证明。高性能 ARM 芯片采用微操作缓存来跳过指令解码,就像 x86 CPU 一样。2019 年,Cortex-A77 引入了 1.5k 条目操作缓存[3]。设计运算缓存并非易事——ARM 的团队在至少六个月的时间里调试了他们的运算缓存设计。显然,ARM 解码的难度足以证明花费大量工程资源尽可能跳过解码是合理的。Cortex-A78、A710、X1 和 X2 还具有运算缓存,表明该方法在蛮力解码方面取得了成功。
三星还在其 M5 上引入了运算缓存。在一篇详细介绍三星 Exynos CPU [4]的论文中,解码能力被称为实现操作缓存的动机:
“随着设计从 M1 中的每个周期提供 4 条指令/微指令变为 M3 中的每个周期 6 条(未来的目标是增长到每个周期 8 条),获取和解码能力是一个重要的问题。M5 实现添加了一个微操作缓存作为替代 uop 供应路径,主要是为了节省可重复内核的获取和解码能力。”——《Evolution of the Samsung Exynos CPU Microarchitecture》
就像 x86 CPU 一样,ARM 内核使用 op 缓存来降低解码成本。ARM 的“解码优势”并不足以让 ARM 避免操作缓存。并且操作缓存将减少解码器的使用,使解码功率变得更不重要。
ARM指令解码成微操作?
Gary Explains 在标题为“ RISC vs CISC– Is it Still a Thing ? “,他在随后的视频中重复了这一说法。
Gary 是不正确的,因为现代 ARM CPU 还将 ARM 指令解码为多个微操作。事实上,“减少微操作扩展”使 ThunderX3 的性能比 ThunderX2 提高了 6%(Marvell 的 ThunderX 芯片都是基于 ARM 的),这比故障中的任何其他原因都要多。
我们还快速浏览了富士通 A64FX 的架构手册,这是为日本 Fugaku 超级计算机提供动力的基于 ARM 的 CPU。A64FX 还将 ARM 指令解码为多个微操作。
如果我们深入看,一些 ARM SVE 指令会解码为数十个微操作。例如,FADDA(“浮点加法严格有序归约,以标量累加”)解码为 63 个微操作。其中一些微操作单独具有 9 个周期的延迟。对于在单个周期中执行的 ARM/RISC 指令来说,就这么多了……
另外需要注意的是,ARM 并不是一个纯粹的加载存储架构。例如,LDADD 指令从内存中加载一个值,添加到它,然后将结果存储回内存。A64FX 将其解码为 4 个微操作。
x86 和 ARM:都因遗留问题而臃肿
这对他们中的任何一个都没有关系。
在 Anandtech 的采访中,Jim Keller 指出,随着软件需求的发展,x86 和 ARM 都随着时间的推移增加了功能。当它们进入 64 位时,两者都得到了一些清理,但仍然是经过多年迭代的旧指令集,迭代不可避免地会带来臃肿。
Keller 好奇地指出,RISC-V 没有任何历史遗留文呢提,因为它“处于复杂性生命周期的早期”。他继续:
“如果我今天想真正快速地构建一台计算机,并且我希望它能够快速运行,那么 RISC-V 是最容易选择的。它是最简单的一个,它具有所有正确的功能,它具有您实际需要优化的正确的前八条指令,而且它没有太多的垃圾。”
如果遗留膨胀起重要作用,我们可以期待很快会出现 RISC-V 的猛攻,但我认为这不太可能。旧版支持并不意味着旧版支持必须快速;它可以进行微编码,从而最大限度地减少芯片面积的使用。就像可变长度指令解码一样,这种开销在现代高性能 CPU 中不太重要,因为芯片区域由缓存、宽执行单元、大型乱序调度程序和大型分支预测器主导。
结论:实施很重要,而不是ISA
我很高兴看到来自 ARM 的竞争,因为高端 CPU 空间需要更多玩家,但由于指令集差异,ARM 玩家并没有超越 Intel 和 AMD。要赢得胜利,ARM 制造商将不得不依靠其设计团队的技能。或者,他们可以通过针对特定的功率和性能目标进行优化来超越英特尔和 AMD。AMD 在这里尤其容易受到攻击,因为它们使用单核设计来涵盖从笔记本电脑和台式机到服务器和超级计算机的所有内容。
-
-
相关阅读:
【web前端特效源码】使用HTML5+CSS3+JavaScript制作一个响应式网站登陆页面|使用全屏可拖动图像滑块~手把手一步一步教学 ~快来收藏吧!
【localStorage的理解与使用】
java-php-python-ssm药房药品采购集中管理系统计算机毕业设计
C++中float和double的比较
环境保护监测系统
【JavaSE】注释\标识符\关键字\字面常量\数据类型与变量
使用VMware安装linux虚拟机
Layui快速入门之第十节 表单
基于微信美食菜谱小程序系统设计与实现 开题报告
Android逆向入门、进阶、工具大全
- 原文地址:https://blog.csdn.net/qq_29788741/article/details/127603191