-
Redis字符串占用偏高
前言
直接上测试结果, 向
redis中写入值(KV相同)为5000001..5100000共10万个字符串类型KV数据.先自以为是的单计算一下需要多少内存: K/V相同, 均为整形, 各占用8字节, 那么一条数据会占用16字节. 10万数据大概占用155kb. 但事实真的是这样么? (如果是这样我也不用写这篇文章了)
实际测试一下, 这是一个刚刚启动的
redis状态, 还没有写入任何数据: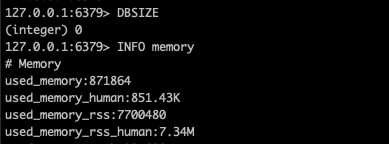
使用脚本向其中
set这10万条数据后: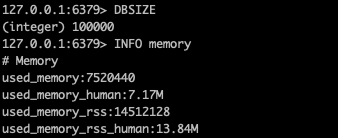
怎么说? 是不是发现比之前计算的数据要大的多? 算一下每条数据占用的内存大小:
(7520440-871864)/100000≈66也就是说, 只是简单的整形
KV,redis写入内存后也会占用66字节. 啊, 这?为了解释这个问题, 我研究了字符串类型在
redis中的实现.字符串实现
源码
为了搞懂这个问题, 我去翻了
Redis的源码. 以下源码基于Redis5.0首先,
Redis在内存中使用一个map来记录所有的K/V映射关系. 其实现就是比较常见的数组加链表. 每一个元素使用结构体dictEntry保存, 源码如下:typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中三个字段各占用8字节, 用于保存元素的结构体占用16字节.
next字段用于链表指向下个元素,k/v均是指向redisObject类型的指针(value 的整形先跳过, 后面会提到), 其源码如下:#define LRU_BITS 24 typedef struct redisObject { unsigned type:4; // 4bit unsigned encoding:4; // 4bit unsigned lru:LRU_BITS; // 3字节 int refcount; // 4字节 void *ptr; // 8字节 } robj;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
RedisObject类型共占用16字节. 很明显, 对应的数据就保存在ptr指针中.Redis中保存字符串有几种情况, 我用一张小图简单说明不同情况下redisObject的数据存放.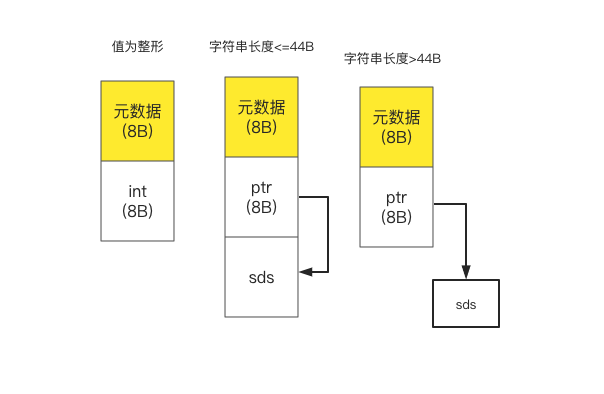
为了减少内存占用,
Redis在存储的时候根据不同的值使用了不同的存储方式. 为什么是44B 呢? 在注释中给出了解释, 是为了令连续内存占用为64B. 至于sds结构, 这里不展开了.再次计算
至此, 我们可以重新计算内存占用了, 每个元素的内存占用大致如下:
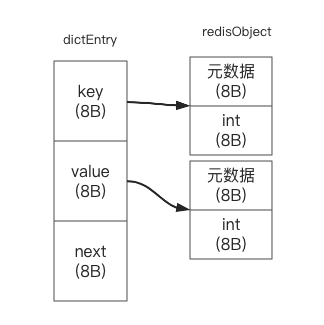
加起来就是
8*7=56B. 但是这跟我们实际测量的66B还是有些差距的呀? 经过查找,Redis使用的内存分配库为jemalloc, 而jemalloc在内存分配的时候申请的内存为2的n 次方. 因此, 虽然dictEntry只需要24B 的内存, 但还是会分配32B.这样一来, 每个元素的内存占用就是:
32+8*4=64B, 与我们之前分析的几乎没差.value union
在刚刚看
dictEntry的时候, 还有个疑惑, 就是value是一个union, 整形可以直接保存在value变量中, 不需要额外的redisObject, 这样的话, 不就可以节省16B 么?是的, 没有错. 如果使用
incr key命令将值放进去, 你就会发现内存占用减少了, 每个元素占用大概48B思考
至此, 经过查找, 我们发现, 在向
Redis中使用字符串类型保存整形的时候, 虽然我们以为每个元素只需要16B, 但最终还是会占用64B, 这意味着如果需要存储10G 的数据, 需要至少40G 的内存才能放得下, 这着实有些夸张了. 当存储的元素本身不大的时候, 元素所带的额外信息就会是内存占用的大头了.那么对于我们遇到的这种情况, 有没有什么办法能够减少内存占用呢?
通过查找, 发现了压缩列表这个结构, 在
Redis的注释中对其进行了详细的解释.在元素不多的时候,
hash/set/list等均使用ziplist, 其优势是可以减少内存占用, 但缺点是时间复杂度较高. 可以使用命令object encoding key查看元素内部类型于是, 我尝试着将
k=5012345 v=5012345的数据, 改为k=5012 field=345 v=5012345的形式以hash的方式进行存储, 这里为了使用ziplist, 修改了配置文件hash-max-ziplist-entries=1024.当我将这10万条数据以hash的方式放进去后, 浅看结果: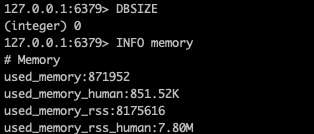
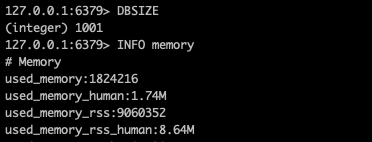
我想到内存占用会降低一些, 但没想到低了这么多, 每个元素占用内存大概:
(1824216-871952)/100000≈10B.其中必然是存在这一些共享内容的, 比如元素
5012345/5112345的field均为345.但是, 这个内存占用着实有些令我震惊了, 回头抽时间好好研究研究压缩列表这玩意.
注意,
hash-max-ziplist-entries配置不要盲目的调高, 压缩列表虽然会降低内存占用, 但是会将时间复杂度降低到 O(n). -
相关阅读:
Linux·【ftp】【nfs】【ssh】服务器搭建
程序员的土味情话
Java面向对象(基础)-- 属性赋值过程、JavaBean和UML类图
【RPC】RPC的序列化方式
python代码实现生成二维码
MindSponge分子动力学模拟——Constraint约束(2023.09)
AI加持,商业智能与分析软件市场释放更大潜能
一元多项式
[solidity]合约调用合约
【计算机网络 - 基础问题】每日 3 题(八)
- 原文地址:https://blog.csdn.net/qq_31725391/article/details/127597783