-
设计模型之六大原则(有的地方称之为七大原则)
其实模型前面一篇说了,但是在聊23模型之前,还是要说一下设计模型需要遵守的六大原则。
原则 描述 单一职责原则(SRP) 单一职责原则规定一个类应该有且仅有一个引起它变化的原因,同时不会影响其它类。 接口隔离原则(ISP) 一个类对领域给类的依赖应该建立在最小的接口,也就是不应该有多余不需要的方法 依赖倒置原则(DIP) 就是要面向接口编程,而不是面向实现类编程 里氏替换原则(lSP) 子类可以扩展父类的功能,但不能改变父类原有的功能 迪米特原则也被称之为最少知识原则(LOD) 直接进行使用对象方法,直接通过暴露接口使用,而不用过多的了解其内部如何实现 开闭原则(OCP) 框架应该对其扩展进行开发,但是对其修改进行关闭 但是也有说有七个原则:合成复用原则。
原则 描述 合成复用原则 尽量使用合成或聚合的方式,而不是使用继承。 上面就是所说的需要遵守的六个或者说是七个原则,需要遵循的。而现在依次进行简单演示以及再次阐述回更加容易明白这些原则的真正含义。
单一职责原则
单一职责原则规定一个类应该有且仅有一个引起它变化的原因,同时不会影响其它类。
简单的说就是一类应该只负责一项职责,这个就用例子来演示:
public class test { public static void main(String[] args) { Animal animalObj=new Animal(); animalObj.run("羊"); animalObj.run("鱼"); } } class Animal{ public void run(String animalName){ System.out.println(animalName+"在草地上自由的奔跑"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以看出一点,这个鱼不会再草地上奔跑,而这个如果修改为在水底自由的游来游去,又会影响羊的行为,所以需要将其拆解出来。当然拆解有两种方法,从类上拆解或者从方法上拆解,现在依次演示。
从类上拆解
public class test { public static void main(String[] args) { LandAnimal landAnimalObj=new LandAnimal(); landAnimalObj.run("羊"); WaterAnimal waterAnimal=new WaterAnimal(); waterAnimal.run("鱼"); } } class LandAnimal{ public void run(String animalName){ System.out.println(animalName+"在草地上自由的奔跑"); } } class WaterAnimal{ public void run(String animalName){ System.out.println(animalName+"在水底自由的游来游去"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
两种动物的行为,彼此修改不会影响彼此的行为,但是这种是从类上进行分离的,实现了单一职责原理。
从类上进行拆解,满足单一职责的原则,会有一个问题,有时候类中的方法很简单,也就是不多,这个时候从类上进行拆解会引起浪费运行内存,毕竟重新创建了对象,而这个时候可以从方法层次进行拆解而实现单一职责原则。
从方法层次拆解
从方法层次进程拆解的话,如果方法数量简单的,为了减少性能浪费,也可以从方法层次进行拆解,例子如下:
public class test { public static void main(String[] args) { Animal animal=new Animal(); animal.landRun("羊"); animal.waterRun("鱼"); } } class Animal{ public void landRun(String animalName){ System.out.println(animalName+"在草地上自由的奔跑"); } public void waterRun(String animalName){ System.out.println(animalName+"在水底自由的游来游去"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
总结
- 降低类的复杂性,一个类负责单一职责,提高了类的可读性和可维护性也降低了和其它类的耦合性,不会引起其它业务异常风险。
- 当然单一准则应该遵守,但是如果逻辑足够简单,也可以再代码级违法单一职责原则,但是有一个前提类的方法数量足够上,这样可以通过方法级别来满足单一职责原则。
接口隔离原则
实现类不应该依赖它不需要的接口,其实最常见的一个类再引用另一个类的时候,应该建立再最小的接口上。下面用代码进行演示:
一个接口有的三个方法,但是其三个实现类实现其接口下的方法要求如下:
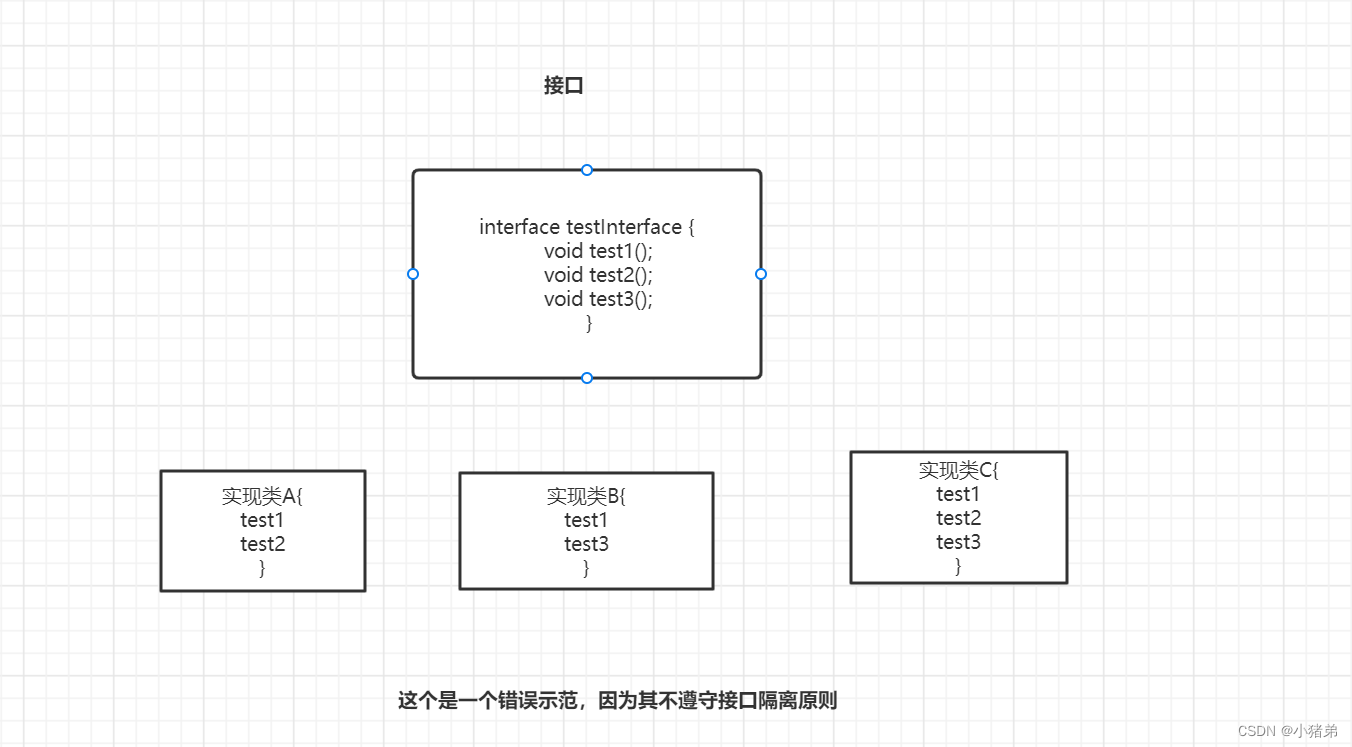
public class test { public static void main(String[] args) { A a=new A(); a.test1(); a.test2(); B b=new B(); b.test1(); b.test3(); // 因为代码太重复不再写C类的方法 } } interface testInterface { void test1(); void test2(); void test3(); } class A implements TestInterface{ @Override public void test1() { } @Override public void test2() { } @Override public void test3() { } } class B implements TestInterface{ @Override public void test1() { } @Override public void test2() { } @Override public void test3() { } } class C implements testInterface{ @Override public void test1() { } @Override public void test2() { } @Override public void test3() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
这样的错误示范,似乎可以满足我们的需求,但是发现实现类其中的实现方法,有些是无效的。造成代码看着很冗余,维护起来也有麻烦,同时也会浪费一些性能,毕竟再创建代码的时候也会再jvm中生成的字节占据jvm虚拟机的存储(这个后面聊jvm的时候再补充)。
如果遵守接口隔离原则的话,那么上面的接口应该拆成三个:
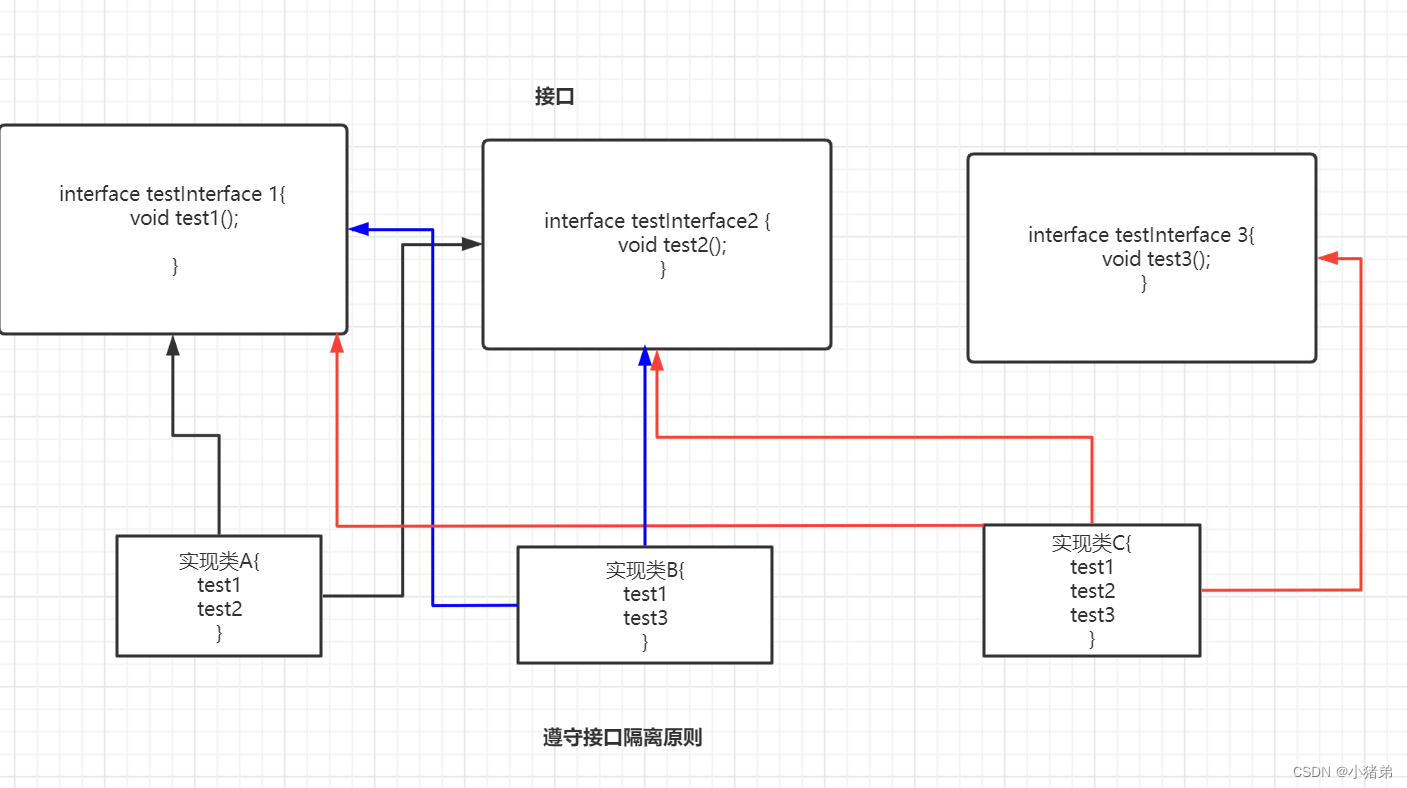
现在代码演示:
public class test { public static void main(String[] args) { A a = new A(); a.test1(); a.test2(); B b = new B(); b.test1(); b.test3(); // 因为代码太重复不再写C类的方法 } } interface TestInterface1 { void test1(); } interface TestInterface2 { void test2(); } interface TestInterface3 { void test3(); } class A implements TestInterface1, TestInterface2 { @Override public void test1() { } @Override public void test2() { } } class B implements TestInterface1, TestInterface3 { @Override public void test1() { } @Override public void test3() { } } class C implements TestInterface1, TestInterface2, TestInterface3 { @Override public void test1() { } @Override public void test2() { } @Override public void test3() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
总结
再次重复一遍,其实现类实现的接口,不要使用不需要方法的接口,而接口尽可能的小。
在操作的时候,可以将接口拆分出多个,当然也可以通过即可的继承(这个实例中没有演示,但是要记住还可以这样操作)而减少接口中重新的代码。
依赖倒置原则
依赖倒置原则是程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
面向过程的开发,上层调用下层,上层依赖于下层,当下层剧烈变动时上层也要跟着变动,这就会导致模块的复用性降低而且大大提高了开发的成本。
面向对象的开发很好的解决了这个问题,一般情况下抽象的变化概率很小,让用户程序依赖于抽象,实现的细节也依赖于抽象。即使实现细节不断变动,只要抽象不变,客户程序就不需要变化。这大大降低了客户程序与实现细节的耦合度。还是代码演示:
// public class test { public static void main(String[] args) { EldenRing eldenRing=new EldenRing(); new PS5().play(eldenRing); } } class PS5{ public void play(Object obj){ // 如果这里有无限个游戏,是否需要重新创建无限个if判断语句, if(obj instanceof EldenRing){ new EldenRing().play(); } else if (obj instanceof GodofWar) { new GodofWar().play(); } } } class EldenRing{ public void play(){ System.out.println("玩的可以艾尔登法环啊"); } } class GodofWar{ public void play(){ System.out.println("玩的可以战神奎爷"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这样写,似乎没有问题,但是如果PS5上游戏太多了,比如一千个,需要些一千给if语句判断,而且ps5上的游戏也是每时每刻都在增加的,所以就需要一个接口进行调用而不是通过实现类。
而这样的通过接口实现也有三种方式:
通过接口传递实现依赖
public class test { public static void main(String[] args) { // 这里接口作为参数实现 Game game=new EldenRing(); new PS5().play(game); } } class PS5{ public static void play(Game game) { game.play(); } } interface Game{ public void play(); } class EldenRing implements Game{ public void play(){ System.out.println("玩的可以艾尔登法环啊"); } } class GodofWar implements Game{ public void play(){ System.out.println("玩的可以战神奎爷"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这样无论你添加多少游戏,和PS5没有关系,只要你遵守我的接口,你想添加多少游戏也不会引起我的方法修改或者代码修改。
接口通过构造方法实现依赖
这个说白了就是将被依赖的接口作为一个需要依赖类的一个构成参数。
public class test { public static void main(String[] args) { new PS5(new EldenRing()).play(); } } class PS5 { Game game; public PS5(Game game) { this.game = game; } public void play() { this.game.play(); } } interface Game { public void play(); } class EldenRing implements Game { public void play() { System.out.println("玩的可以艾尔登法环啊"); } } class GodofWar implements Game { public void play() { System.out.println("玩的可以战神奎爷"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
通过setter方法实现依赖
这个通过setter设置属性值罢了。
public class test { public static void main(String[] args) { PS5 ps5=new PS5(); ps5.setGame(new EldenRing()); if(ps5!=null){ ps5.play(); } } } class PS5 { Game game; public void setGame(Game game) { this.game = game; } public void play() { this.game.play(); } } interface Game { public void play(); } class EldenRing implements Game { public void play() { System.out.println("玩的可以艾尔登法环啊"); } } class GodofWar implements Game { public void play() { System.out.println("玩的可以战神奎爷"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
上面三种其实就是实现依赖倒置的三种方式,
总结
简单的说就是通过接口或者抽象来来指定好规范,而不涉及任何具体操作,把展现细节的任务交给他们的实现类去完成。通俗的说就是行为具体的方法应该是具体的实现类来调用,但是为了统一方便调用这个方法我就去找它的接口,而这种思想就是依赖倒置。
- 而底层模块(被依赖类)尽量都要有抽象类或者接口,或者两者都有,这样程序会更加稳定。
- 同时这样些也就将两个类耦合降低,比如例子中在PS5中如何写和游戏如何写相互不影响,只要满足接口就行,至于后面是否有新游戏只要实现接口,PS5也不用调整自己的内容,直接通过接口或者抽象类的标准定义即可。
- 通过三种方式实现可以看出变量声明的时候尽量也使用抽象类或者接口,这样变量在引用或者实际对象间就存在一个缓冲区,利于程序扩展和优化。
里氏替换原则
在聊这个原则的时候,需要理解继承。因为这个原则和继承关系很密切。然后既然和继承有关系,但是为什么叫做里氏替换而不是叫做带有继承有关的名字,其实这个命名时因为1988年麻省理工的一位姓里的女士提出了的。
继承中需要常见的两个问题:
- 其实在父类中已实现好的方法,实际上时在设定规范和契约,与接口不同的地方是其已经实现了一个完整的方法。虽然它不强制要求所有的子类必须遵守这些七月,但是如果子类对这些已实现的方法任意修改,就会对整个继承体系造成破环。
- 继承在给程序设计带来的便利同时也会带来另一个弊端,如果上面写的是子类修改会影响父类,当然父类修改也会引起子类出现问题。毕竟有时候子类的某个方法实现依靠的是父类,如果父类修改了子类原本的需求就等于无法正确体现了。
因为继承的父类和子类的方法修改都会让继承的优势会带来一些不好的体验,但是继承的优势还是很明显的,那为什么不通过一个标准来体现这个优势的同时还会避免带来的问题呢?所以就有了里氏替换原则。
**里氏替换规定子类中尽量不要重写父类的方法。**其实这个也有了一个神奇的效果,那就是如果用父类的地方,其实可以使用子类也不会产生问题。
还是老规矩来一个错误的案例。
public class test { public static void main(String[] args) { Grandson grandson=new Grandson(); // 打算求和 ,但是却为积 grandson.fun1(8,2); grandson.fun2(8,2); } } class Father{ //求和 public void fun1(int a,int b){ System.out.println(a+b); } // 求差 public void fun2(int a,int b){ System.out.println(a-b); } } class Son extends Father{ // 求积 public void fun1(int a,int b ){ System.out.println(a*b); } } class Grandson extends Son{ }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
其实可以看出son方法修改了father中fun1的运算,这样Grandson中方法第一个是求和,发现求积,难道在Grandson再写一遍求和方法吗?这样有些浪费代码,同时继承优势也就没有了,其影响了整个继承的体系,也可以看出继承中的约束是不是强制性的。所以如下操作:
public class test { public static void main(String[] args) { Grandson grandson=new Grandson(); // 打算求和 ,但是却为积 grandson.fun1(8,2); grandson.fun2(8,2); } } class Father{ //求和 public void fun1(int a,int b){ System.out.println(a+b); } // 求差 public void fun2(int a,int b){ System.out.println(a-b); } } class Son extends Father{ // 求积 public void fun2(int a,int b ){ System.out.println(a*b); } } class Grandson extends Son{ }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这样遵守里氏原则,子类只会新增功能,而不修改原有的父类功能,这样让完整的继承体系体现其优势。
但是里氏原则也会有一个问题,继承实际上让两个类的耦合性增加了,就是父类和子类会相互影响,所以在适当情况下,可以通过聚合,组合,依赖来解决问题,减少耦合性
比如如下修改:
public class test { public static void main(String[] args) { Grandson grandson=new Grandson(); grandson.fun1(8,2); // 打算求和 ,这样也可以使用Father的方法,打破了继承的耦合性 grandson.fun2(8,2); } } // 提出一个新的基类 class base{ } class Father extends base{ //求和 public void fun1(int a,int b){ System.out.println(a+b); } // 求差 public void fun2(int a,int b){ System.out.println(a-b); } } class Son extends base{ // 作为一个属性 private Father father=new Father(); // 求积 public void fun1(int a,int b ){ System.out.println(a*b); } public void fun2(int a,int b ){ this.father.fun1(a,b); } } class Grandson extends Son{ }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
这种情况只是为了基础耦合性而解决的方式之一,有点像是依赖倒置中的三种实现依赖了,不过似乎有没有完美的体现继承的优势。
总结
- 子类可以实现父类的抽象方法,但是不能覆父类的非抽象方法,当然子类也可以增加自己特有的方法。
- 当然继承也是有其带来的问题那就是耦合性很高,有时候通过聚合,依赖,组合来基金问题。
迪米特原则
迪米特法则(Law of Demeter, LoD)是1987年秋天由lan holland在美国东北大学一个叫做迪米特的项目设计提出的,它要求一个对象应该对其他对象有最少的了解,所以迪米特法则又叫做最少知识原则 。
一个对象应该对其它对象保持最少的了解,因为类与类的关系越密切,耦合度越多大。
简单的说就是被依赖的类不管多米复杂,都尽量将逻辑封装在类的内部,对除了提供public方法,不对外泄露任何信息。
举个例子:
比如小红租房的时候,直接连接中介,而中介直接根据小红的需求提供房源即可。 但是如果小红不需中介,而直接在城市将所有房子的资源整理,然后依次排除不需要的房屋,然后再联系房主,如果房东的房子被出租了还要不停的剔除这个资源。如果小红只是一个租客只为了租房而已,不从事中介工作,那么做这样多事情有没有意义呢?浪费了世间和精力。 所以小红之与中介有关系,其它的毫不在意,因为老子至少租房而已,房子满意即可,其它的内容小红不需要知道。- 1
- 2
- 3
来一个代码来体验:
public class test { public static void main(String[] args) { ZhongJie zhongJie=new ZhongJie(new City("北京")); System.out.println("满足需求的房屋有多少套:"+zhongJie.getHouseCount()); } } // 其要做的事情太多了,就是简单的演示 class ZhongJie{ static Map mapBase=new HashMap<City,List<House>>(); static { City c1=new City("北京"); List<House> list1=new ArrayList<>(); list1.add(new House("北京花园1号21-1-4")); list1.add(new House("北京花园1号11-2-4")); list1.add(new House("北京同意 3-4-3")); City c2=new City("上海"); List<House> list2=new ArrayList<>(); list2.add(new House("上海花园1号21-1-4")); list2.add(new House("上海花园1号11-2-4")); list2.add(new House("上海同意 3-4-3")); mapBase.put(c1.getCityName(),list1); mapBase.put(c2.getCityName(),list2); } City city; public ZhongJie(City city) { this.city = city; } // 其中这个就是中介维护房屋数据库的方法,其中包含了很多信息比如添加房屋信息,以及修改房屋状态,价格等等。这个就不再通过实现了 private void updataBase(){ } // 知道满足需求的有多少套房 public int getHouseCount(){ // 其实一个城市的信息太多了,比如还有区街道等,单这里至是为了演示,所以只写一个名字。 List<House> list2= (List<House>) mapBase.get(this.city.getCityName()); return list2.size(); } } class City{ String cityName; public City(String cityName) { this.cityName = cityName; } public String getCityName() { return cityName; } } class House{ String houseName; public House(String houseName) { this.houseName = houseName; } public String getHouseName() { return houseName; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
总结
迪米特原则初衷是为了降低类之间的耦合,让每个类都减少不必要的依赖,依次降低了耦合关系,但是其避免了非必要直接的耦合,但是其自己会通过一个”中介“来发生联系。但是过分只用迪米特原则会产生大量的的中介或传递类,倒置系统的复杂度变大。比如本身就与一个类进行依赖,而这个类方法很简单,难道还需与再创建一个中介类来满足吗?所以要反复权衡,做到结构侵袭又要高内聚低耦合。
开闭原则
开闭原则其实编程中最基础,最重要的设计原则。其本质是定义了模块和函数应该对扩展开放,但是关闭修改。简单的说就是通过抽象构建框架,用实现来扩展细节。
也就是当软件需求变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有代码来实现。
其实整个是一个很虚的概念,它只是简单说了一整个准则:扩展开放,修改关闭。但是如何实现其没有提出任何的一个行使的方式,其实说前面聊的原则而设计的模型,都会遵循这个开闭原则的。
先来一个错误示范:
public class test { public static void main(String[] args) { PS5 ps5=new PS5(); ps5.play(new EldenRing()); ps5.play(new GodofWar()); } } class PS5 { public void play(Game game) { if(game.gameID==1){ playEldenRing(); } else if (game.gameID==2) { playGodofWar(); } } public void playEldenRing() { System.out.println("老子用PS5玩的是老头环啊"); } public void playGodofWar() { System.out.println("老子用PS5玩的是战神奎爷啊"); } } class Game { int gameID; } class EldenRing extends Game { EldenRing() { super.gameID = 1; } } class GodofWar extends Game { GodofWar() { super.gameID = 2; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
上面是面对类开放的,如果有新的游戏增加的话,需要对ps5类添加新的方法,其扩展就会修改ps5,所以没扩展依次都需要修改,这样是很麻烦的。
如果修改为面对抽象类(或接口)如下:
public class test { public static void main(String[] args) { PS5 ps5=new PS5(); ps5.play(new EldenRing()); ps5.play(new GodofWar()); } } class PS5 { public void play(Game game) { game.play(); } } abstract class Game { int gameID; abstract void play(); } class EldenRing extends Game { EldenRing() { super.gameID = 1; } @Override void play() { System.out.println("老子用PS5玩的是老头环啊"); } } class GodofWar extends Game { GodofWar() { super.gameID = 2; } @Override void play() { System.out.println("老子用PS5玩的是战神奎爷啊"); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
总结
看上面的例子是否有点像是前面演示的依赖倒置,这就是前面一直说开闭原则是前面几个原则的集大成者,都是遵循开闭原则,而上面的例子其实也体现出来了。
合成复用原则
其实这个原则本身就是为了解决继承带来的耦合度过高的原则,而通过聚合等方式冉让松解耦合度。
而这地方就是简单的说一下几个概念(对于概念就直接赋值了,毕竟概念大体一直也懒得自己写了):
依赖
什么是依赖,当一个类使用另一个类中的方法,自然会先创建这个类,那么类和类一个类有了依赖关系。
class A{ public static void main(String[] args) { // A依赖B这个对象才能实现方法,所以两者是依赖关系 new B().play(); } } class B{ public void play() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
而依赖关系不单单是上面例子那样,其依赖关系在Java语言中体现为局域变量、方法的形参,或者对静态方法的调用。
关联
关系是类与类之间的联接,它使一个类知道另一个类的属性和方法。关联可以是双向的,也可以是单向的。在Java语言中,关联关系一般使用成员变量来实现。
聚合
关系是关联关系的一种,是强的关联关系。聚合是整体和个体之间的关系。例如,汽车类与引擎类、轮胎类,以及其它的零件类之间的关系便整体和个体的关系。与关联关系一样,聚合关系也是通过实例变量实现的。但是关联关系所涉及的两个类是处在同一层次上的,而在聚合关系中,两个类是处在不平等层次上的,一个代表整体,另一个代表部分。
简单的说激素再new调用构造方法时候,需要将这个局部的对象new出来作为构造参数。
其实这个再聊依赖倒置的时候说过,其一般是通过构造方法实现依赖:
class Car{ String color; String Wheel; // 这里举例还是少的,毕竟出来轮子,还有装饰,以及发动机等零部件组合在一起才说一辆车 public Car(String color, String wheel) { this.color = color; Wheel = wheel; } } //轮子也有自己的属性,比如尺寸,材质等 class Wheel{ int size; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
组合
关系是关联关系的一种,是比聚合关系强的关系。它要求普通的聚合关系中代表整体的对象负责代表部分对象的生命周期,组合关系是不能共享的。代表整体的对象需要负责保持部分对象和存活,在一些情况下将负责代表部分的对象湮灭掉。代表整体的对象可以将代表部分的对象传递给另一个对象,由后者负责此对象的生命周期。换言之,代表部分的对象在每一个时刻只能与一个对象发生组合关系,由后者排他地负责生命周期。部分和整体的生命周期一样。
class Person{ String name; String Apple; // 毕竟人有没有苹果都是一个人,所以其不是聚合关系 public Person1(String name) { this.name = name; } // 但是无论如何,都需给这个人一个苹果,人才能操作这个苹果 public void setApple(String apple) { Apple = apple; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
以上关系的耦合度依次增强(关于耦合度的概念将在以后具体讨论,这里可以暂时理解为当一个类发生变更时,对其他类造成的影响程度,影响越小则耦合度越弱,影响越大耦合度越强)。由定义我们已经知道,依赖关系实际上是一种比较弱的关联,聚合是一种比较强的关联,而组合则是一种更强的关联,所以笼统的来区分的话,实际上这四种关系、都是关联关系。
当然集中耦合度还是低于继承的,毕竟是为了基金继承带来的耦合度过高而相到解决方式
其实说实话后面聊的23中设计模型,无论如何设计这个模型,都遵守上面的原则,只有如此才会让模型适合或者说提高我们编码的效率,以及提高可读性,维护性。
-
相关阅读:
数据挖掘可视化+机器学习初探
【Redis】主从复制
springmvc:设置后端响应给前端的json数据转换成String格式
程序环境和预处理
c++文件解析之换行(CRLF、LF、CR)
分享Bitmap加载Drawable资源失败的解决方法
多人协作代码管理工具 gitlab 实战演练
使用 React Router 的 withRouter
学习亚马逊云科技AWS云计算技术的三款官方免费3A游戏大作
tmux随笔
- 原文地址:https://blog.csdn.net/u011863822/article/details/127428804
