-
自定义类型--结构体(C语言)
快速导航
👍【前言】👍在日常写代码的过程中,结构体可谓是见怪不怪,那么你是否真的理解结构体的内存对齐,结构体自引用,以及结构体的一些特殊声明,接下来就由博主带你们一起在知识的海洋中遨游吧!✈️
1.什么情况会使用到结构体?
C语言中的内置类型int,char,double等类型描述变量是有一定限制的,像学生,老师,书本等对象是无法使用内置类型进行描述的,所以我们需要用到结构体来对这些对象进行描述。
结构体是一些值的集合,这些值称之为成员变量。结构体的每个成员可以是不同类型的变量。
- struct Stu //描述一个学生对象
- {
- char name[20];//姓名
- int age; //年龄
- char id[12]; //学号
- };
当使用内置类型无法描述一个对象时,就需要考虑使用自定义类型-结构体。
2.结构体的声明🛰
- struct tag
- {
- member-list;//成员列表
- }variable-list; //变量列表
下面以struct Book为例:
- struct Book
- {
- char name[20];//书名
- float price;//价格
- char id[20];//书号
- }; //一定能够要注意 ;不能丢
3.特殊的声明🍺
在声明结构体时,可以不完全声明。举个栗子:
- struct
- {
- int a;
- char b;
- float c;
- }x;//定义了一个匿名的变量x
这种声明结构只能在声明的时候才能定义变量,之后无法再定义变量,适用于只定义一次的情况。
这时候就会出现一个问题:如果两个匿名结构体中的成员相同,那么这两个匿名结构体是不是同一种类型?
- struct
- {
- int a;
- char b;
- float c;
- }*p; //相当于定义了一个结构体的指针
- //在上面代码的基础上,下面的代码合法吗?
- p = &x;
注意:上面这种是不合法的;编译器会把两个匿名的结构体声明当成不同的两个类型,造成指针的非法访问。
4.结构体自引用😊
以数据结构中的单链表为例:
链表:物理空间上不一定连续,逻辑上一定连续,通过指针来链接。

4.1在结构体中包含一个类型为该结构本身的成员是否可以?
- struct Node
- {
- int data;
- struct Node next;
- };
Node结构体之中包含Node结构体……,就相当于无穷的递归下去,那么sizeof(Node)是多少呢?
很显然,这种结构体自引用是不正确的。
4.2正确的结构体自引用
链表中数据域用来存储数据,指针域用来存储结构体指针。
- struct Node
- {
- int data;
- struct Node* next;
- };
如果觉得结构体类型复杂,可以对结构体类型进行重命名,这也是数据结构书籍中普遍的一种用法:
- typedef struct Node
- {
- int data;
- struct Node* next;
- }Node;
4.3 typedef对结构体重命名时的两种情况
1.不存在结构体自引用
- typedef struct
- {
- int a;
- char b;
- float c;
- }St; //无论是匿名还是非匿名可以进行typedef
2.存在结构体自引用
- typedef struct Node
- {
- int data;
- struct Node* next;
- }Node;
typedef:只有在非匿名的时候才能对结构体自引用的结构体进行重命名。
- typedef struct
- {
- int data;
- struct Node* next;//无法进行声明
- }Node;
5.结构体变量的定义、初始化
既然对结构体变量进行了声明,那么就要对变量进行定义和初始化:
5.1结构体变量的定义
1.在声明的时候定义变量
- struct Stu
- {
- char name[20];//姓名
- int age; //年龄
- char id[12]; //学号
- }s1, s2, s3;
2.声明之后再定义
- struct Stu
- {
- char name[20];//姓名
- int age; //年龄
- char id[12]; //学号
- };
- int main()
- {
- struct Stu s1;
- struct Stu s2;
- return 0;
- }
5.2结构体变量的初始化
1.在声明的时候定义变量并且进行初始化
- struct Stu
- {
- char name[20];//姓名
- int age; //年龄
- char id[12]; //学号
- }s1 = {"阿飞", 19, "66666666"};
2.定义时进行初始化
- struct Stu
- {
- char name[20];//姓名
- int age; //年龄
- char id[12]; //学号
- };
- int main()
- {
- struct Stu s1 = { "阿飞", 19, "66666666" };
- return 0;
- }
6.两种结构体成员访问方式的对比
1.传结构体
- void Print1(struct Stu s)
- {
- printf("%s, %d, %s\n", s.name, s.age, s.id);
- }
- int main()
- {
- struct Stu s = { "阿飞", 19, "66666666" };
- Print1(s);
- return 0;
- }
2.传结构体指针
- void Print2(struct Stu* ps)
- {
- printf("%s, %d, %s\n", ps->name, ps->age, ps->id);
- }
- int main()
- {
- struct Stu s = { "阿飞", 19, "66666666" };
- Print1(s);
- Print2(&s);
- return 0;
- }
这两种访问方式都能访问结构体成员:
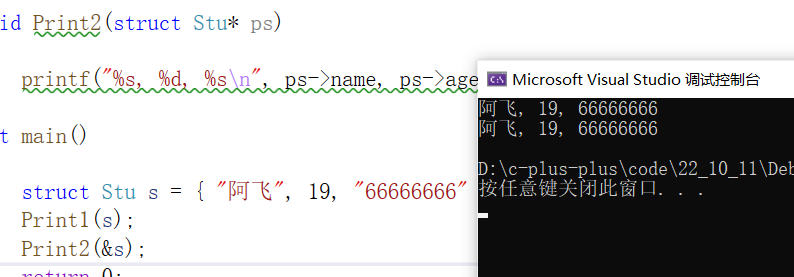
但是传值的时候形参是实参的一份拷贝,如果结构体很大的话,会造成大量的内存消耗;
首选使用传址来进行访问,因为没有额外的内存消耗。
7.结构体内存对齐🤡
- struct S1
- {
- char c1;
- int i;
- char c2;
- };
- int main()
- {
- printf("%d\n", sizeof(s1));
- return 0;
- }
VS下的运行结果:
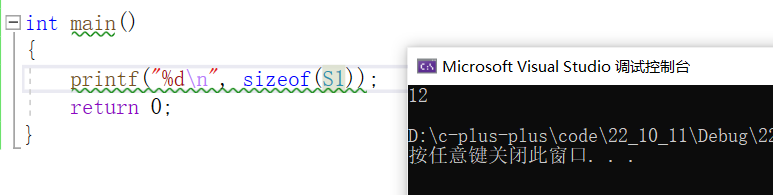
char类型1个字节,int类型4个字节,那么结果为什么不是6而是12呢?
那是因为结构体内存对齐的缘故。具体在7.3中会详解;
7.1为什么要有结构体内存对齐?
1. 硬件原因:
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
7.2结构体内存对齐规则
1.第一个成员在与结构体变量偏移量为0的地址处。
2.其他成员变量要对齐到对齐数的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数与该成员大小的较小值。(VS中默认对齐数为8)
3.结构体总大小为最大对齐数的整数倍处。
4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的大小是最大对齐数(含嵌套结构体的对齐数)的整数倍。
7.3 4个练习(画图理解)
7.3.1 练习1
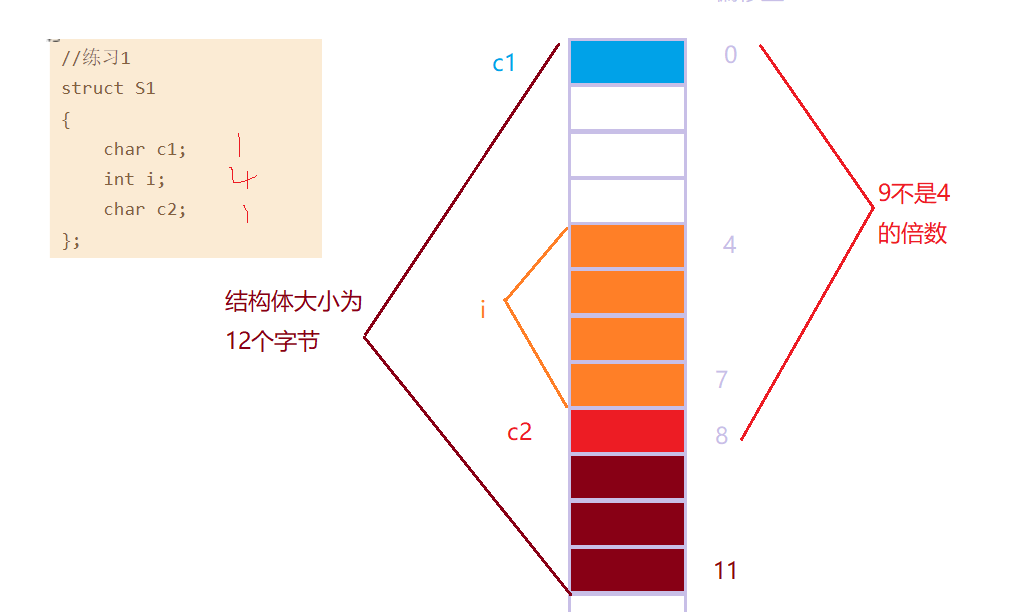
7.3.2 练习2
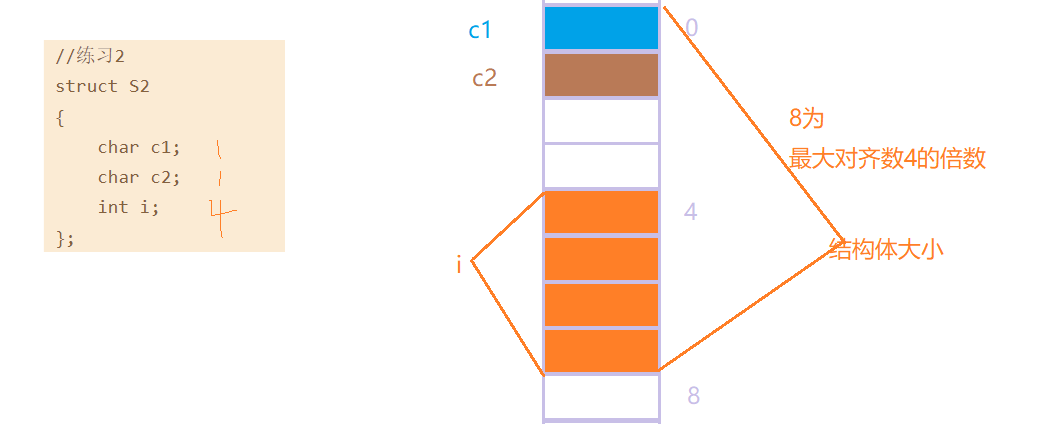
7.3.3 练习3
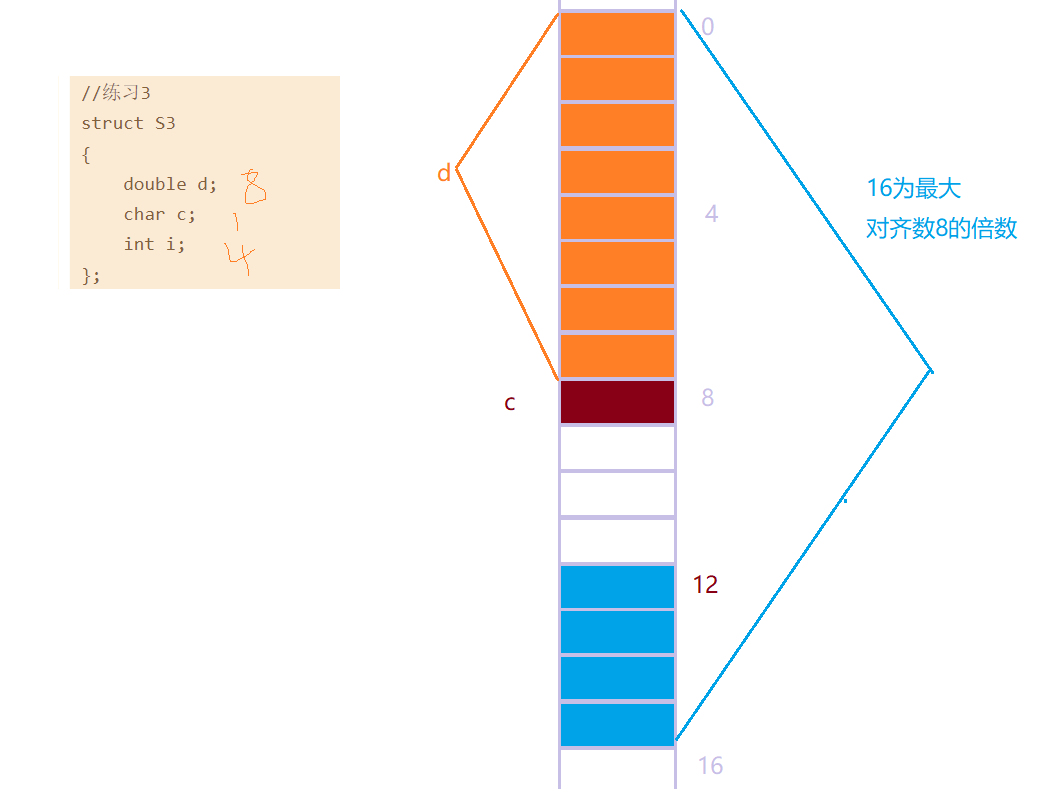
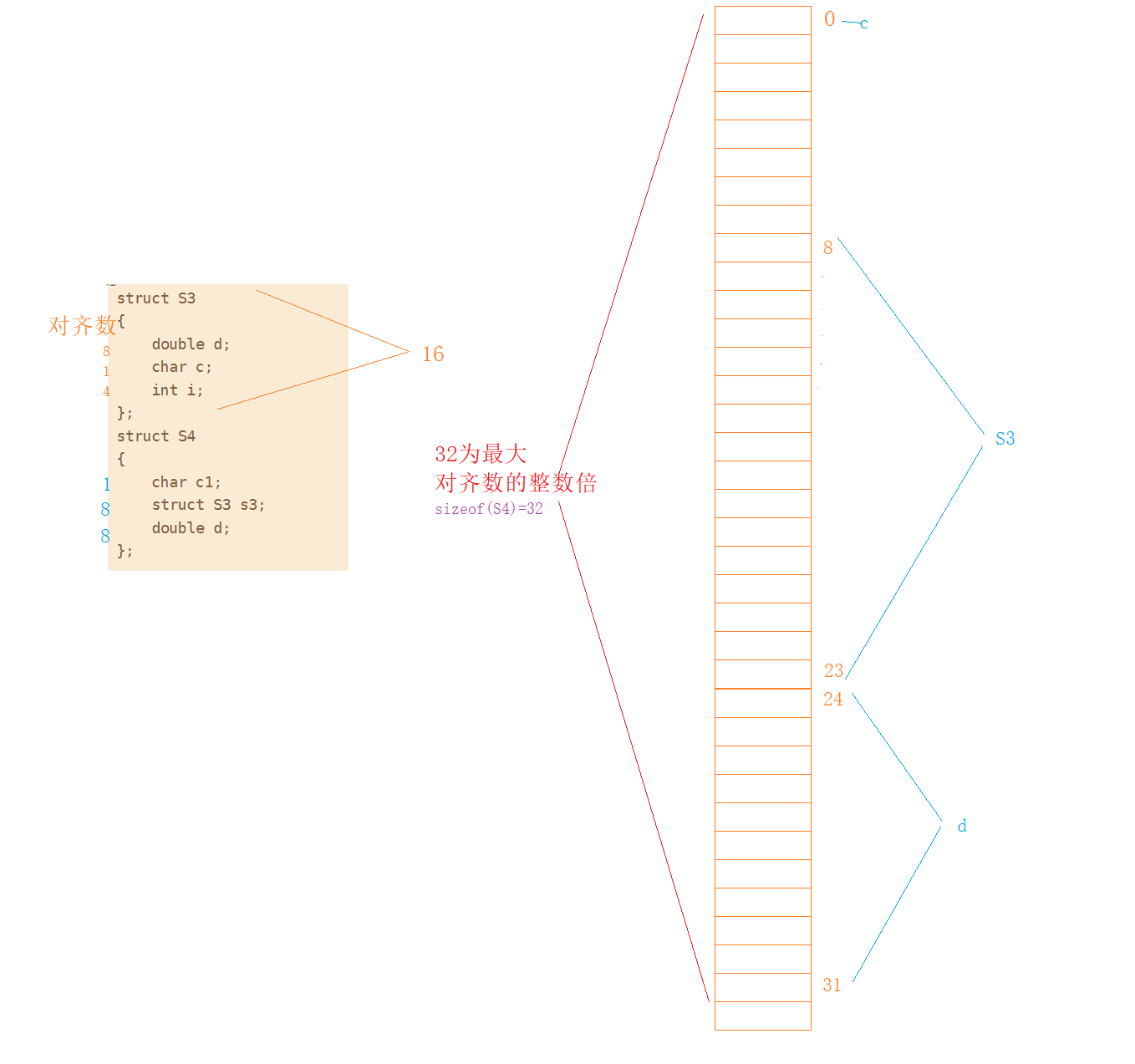
7.3.4 练习4(嵌套结构体)
- struct S3
- {
- double d;
- char c;
- int i;
- };
- struct S4
- {
- char c1;
- struct S3 s3;
- double d;
- };
7.4修改默认对齐数
- #pragma pack(8) //设置默认对齐数为8
- #pragma pack(4) //设置默认对齐数为4
VS的默认对齐数为8,那接下来验证一下默认对齐数为4的时候结果是否正确。
- struct S
- {
- char c;
- double d;
- int i;
- };
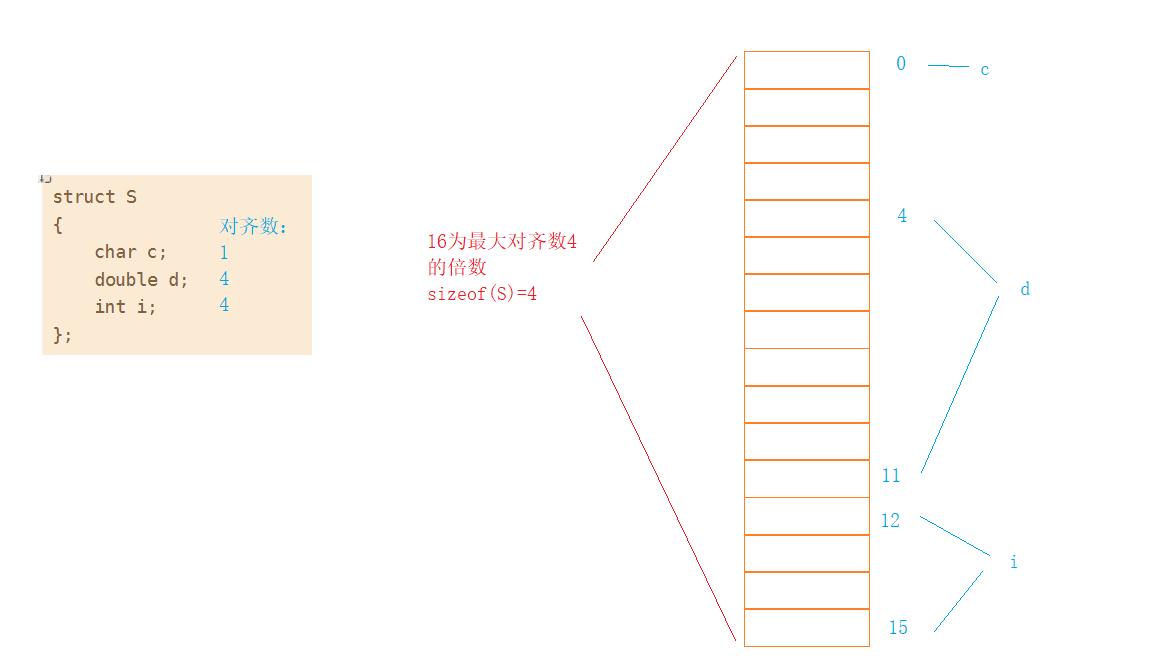
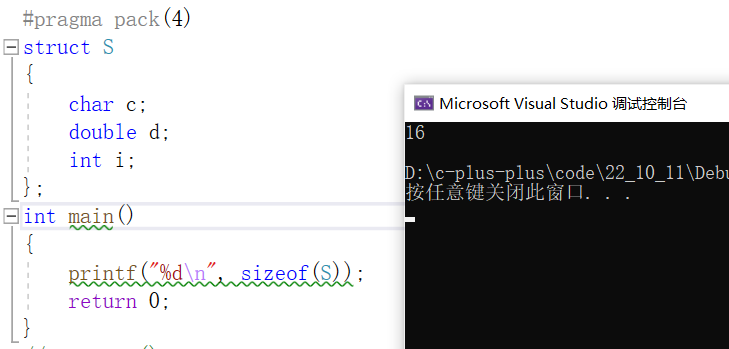
我们计算的结果和编译器打印的结果是相同的,说明默认对齐数确实修改了。
-
相关阅读:
吉他谱制作软件哪个好 吉他弹唱谱制作软件推荐
星际争霸之小霸王之小蜜蜂(十一)--杀杀杀
pdf生成:puppeteer
【Linux初阶】信号入门 | 信号基本概念+信号产生+核心转储
LPQ(局部相位量化)学习笔记
WorkManager的使用篇_batch
Java面向对象编程
python读文件如何不换行,以及python写文件后怎么换行
第二十章《Java Swing》第8节:选择器
LeetCode 1159.市场分析2
- 原文地址:https://blog.csdn.net/qq_63179783/article/details/123772869