-
pdf生成:puppeteer
一、Puppeteer
Puppeteer是Google Chrome团队出品的一款无界面Chrome工具,它提供了丰富的API,让开发者像鼠标一样控制浏览器的各种行为。Puppeteer是一个Node库,提供发了一个高级API来通过DevTools协议控制Chromium或Chrome。Puppeteer默认以 headless模式( 以命令行接口的方式 )运行,但是可以通过修改配置文件运行 non-headless 模式。Puppeteer本身依赖 6.4 以上的node,但是为了异步超级好用的 async/await,推荐使用7.6版本以上的Node。另外headless Chrome本身对服务器依赖的库的版本要求比较高。所以 尽量安装最新版本的node 。用途:1) 生成网页截图或者 PDF2) 高级爬虫,可以爬取大量异步渲染内容的网页3) 模拟键盘输入、表单自动提交、登录网页等,实现 UI 自动化测试4) 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题二、安装
2.1、npm安装
1、安装chrome依赖apt install -y libglib2.0-dev libnss3 libatk1.0-0 libatk-bridge2.0-0 libcups2 libdrm2 libxcomposite1 libxdamage1 libxfixes3 libxrandr2 libgbm-dev libpango1.0-0 libasound2 libxshmfence1 libxkbcommon0 libcairo22、安装 nodejs 与 npmapt-get install nodejs npm但这种方法安装的版本可能偏低,影响后续的包安装。按照下面的链接里的步骤安装https://linuxize.com/post/how-to-install-node-js-on-ubuntu-18.04/#1-installing-nvm-node-version-manager-script
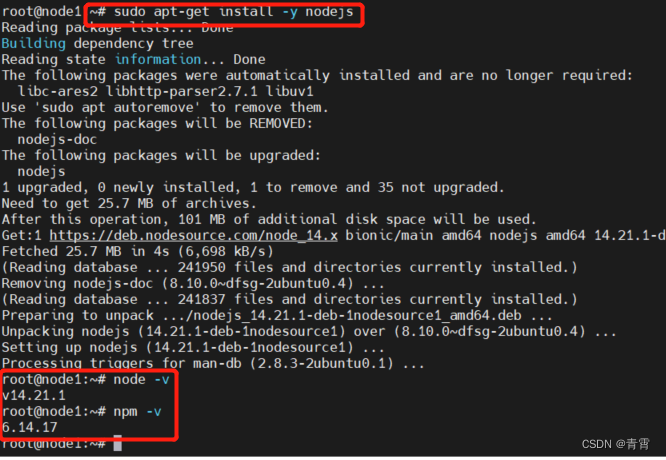
- 1、curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash - # -s参数将不输出错误和进度信息;-L参数会让 HTTP 请求跟随服务器的重定向。curl 默认不跟随重定向。
- 2、sudo apt-get install -y nodejs
- 3、node --version # v14.21.1
- 4、npm --version # 6.14.17
 3 、安装 puppeteernpm install -g puppeteer --unsafe-perm=true # 要加--unsafe-perm=true否则会提示权限不足
3 、安装 puppeteernpm install -g puppeteer --unsafe-perm=true # 要加--unsafe-perm=true否则会提示权限不足 安装路径:/usr/lib/node_modules/puppeteer当您安装Puppeter时,它会自动下载最新版本的Chromium(~170MB的macOS、~282MB的Linux、~280MB的Windows),保证可以与Puppeter一起使用。
安装路径:/usr/lib/node_modules/puppeteer当您安装Puppeter时,它会自动下载最新版本的Chromium(~170MB的macOS、~282MB的Linux、~280MB的Windows),保证可以与Puppeter一起使用。2.2、docker安装 Docker | Puppeteer
- docker pull ghcr.io/puppeteer/puppeteer:latest # pulls the latest
- docker pull ghcr.io/puppeteer/puppeteer:16.1.0 # pulls the image that contains Puppeteer v16.1.0
该映像用于在sandbox模式下运行浏览器,因此,运行该映像需要SYS_ADMIN功能。
使用:docker run -i --init --cap-add=SYS_ADMIN --rm ghcr.io/puppeteer/puppeteer:latest node -e "$(cat path/to/script.js)" #path/to/script.js是相对于工作目录的路径三、使用Puppeteer Request Interception | Puppeteer
Puppeteer 使用起来和其他测试框架类似。创建一个 Browser 示例,打开页面,然后使用 Puppeteer API。Puppeteer 初始化的屏幕大小默认为 800px x 600px。但是这个尺寸可以通过 Page.setViewport() 设置。3.1、示例 - 跳转到https://www.baidu.com/,保存截图至 example.png,同时保存为pdf
-
- const puppeteer = require('/usr/lib/node_modules/puppeteer');
- (async() => {
- const browser = await puppeteer.launch({
- headless: true,
- args: [
- '--no-sandbox', // 沙盒模式
- '--disable-dev-shm-usage', // 创建临时文件共享内存
- '--disable-setuid-sandbox', // uid沙盒
- '--disable-gpu', // GPU硬件加速
- '--disable-web-security', // 关闭chrome的同源策略
- '--no-first-run', // 没有设置首页。在启动的时候,就会打开一个空白页面
- '--single-process' // 单进程运行
- ]
- });
- const page = await browser.newPage();
- await page.goto('百度一下,你就知道', { waitUntil: 'networkidle0'}); //设置 waitUntil: 'networkidle0'选项表示Puppeteer已经导航到页面并结束
- await page.screenshot({path: 'example.png'});
- await page.pdf({
- path: 'example.pdf',
- format: 'A4',
- });
- await browser.close();
- })().catch(error => {
- console.error(error);
- process.exit(1);
- });
执行命令node example.js:

3.2、示例 - 通过html字符串生成pdf
- const html = `
- ·
Document - 页面Dom
- `
- const puppeteer = require('/usr/lib/node_modules/puppeteer')
- async function printPDF() {
- const browser = await puppeteer.launch({
- headless: true,
- args: [
- '--no-sandbox', // 沙盒模式
- '--disable-dev-shm-usage', // 创建临时文件共享内存
- '--disable-setuid-sandbox', // uid沙盒
- '--disable-gpu', // GPU硬件加速
- '--disable-web-security', // 关闭chrome的同源策略
- '--no-first-run', // 没有设置首页。在启动的时候,就会打开一个空白页面
- '--single-process' // 单进程运行
- ]
- });
- const page = await browser.newPage()
- await page.setContent(html, {waitUntil: 'networkidle0'})
- await page.pdf({ path: 'test.pdf', format: 'A4'})
- await browser.close()
- }
- printPDF()
执行js,生成test.pdf文件:
3.3、示例 - html动态加载json文件,生成pdf
tree `pwd` -a --dirsfirst查看目录结构: json数据:input.json: 403行,19.3kb
json数据:input.json: 403行,19.3kb html文件:html/content.html加载js文件:
html文件:html/content.html加载js文件: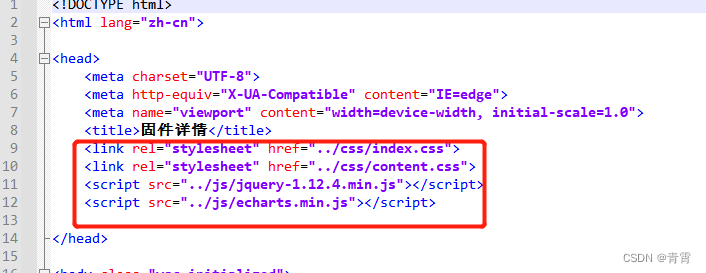 加载json数据:
加载json数据: json_html_2_pdf.js
json_html_2_pdf.js- const puppeteer = require('/usr/lib/node_modules/puppeteer');
- (async() => {
- const browser = await puppeteer.launch({headless: true,args: ['--no-sandbox', '--disable-dev-shm-usage', '--disable-gpu', ' --test-type', '--disable-web-security']});
- const page = await browser.newPage();
- await page.goto('file:///home/zhang/Desktop/puppeteer_zq/firmware/html/content.html', { waitUntil: 'networkidle0'}); //设置 waitUntil: 'networkidle0'选项表示Puppeteer已经导航到页面并结束
- await page.pdf({
- path: 'firmware.pdf',
- format: 'A4',
- printBackground: true // 加这行pdf文件的背景才会显示
- });
- await browser.close();
- })().catch(error => {
- console.error(error);
- process.exit(1);
- });
执行node json_html_2_pdf.js生成pdf文件。ok》》 更换json文件:32123行,1.40MB运行出错: TimeoutError: waiting for Page.printToPDF failed: timeout 30000ms exceeded 默认超时时间30000ms ,设置不超时 timeout: 0 :
默认超时时间30000ms ,设置不超时 timeout: 0 :- const puppeteer = require('/usr/lib/node_modules/puppeteer');
- (async() => {
- const browser = await puppeteer.launch({
- headless: true,
- args: [
- '--no-sandbox', // 沙盒模式
- '--disable-dev-shm-usage', // 创建临时文件共享内存
- '--disable-gpu', // GPU硬件加速
- '--test-type',
- '--disable-web-security' // 关闭chrome的同源策略
- ]
- });
- const page = await browser.newPage();
- await page.goto('file:///home/zhang/Desktop/puppeteer_zq/firmware/html/content.html', { waitUntil: 'networkidle0'}); //设置 waitUntil: 'networkidle0'选项表示Puppeteer已经导航到页面并结束
- await page.pdf({
- path: 'firmware.pdf',
- format: 'A4',
- printBackground: true, // 加这行pdf文件的背景才会显示
- displayHeaderFooter: false, // 显示页眉和页脚。默认为False
- timeout: 0, // 无穷大,不超时
- });
- await browser.close();
- })().catch(error => {
- console.error(error);
- process.exit(1);
- });
执行node json_html_2_pdf.js生成pdf文件。ok
》》 但在容器中运行又报错:UnhandledPromiseRejectionWarning: ProtocolError: Protocol error (Page.printToPDF): Printing failed容器内node版本:v14.20.0 相关参考:解决:升级nodejs版本至v14.21.1,重新安装puppeteer后,设置不超时(timeout : 0)再次执行ok
相关参考:解决:升级nodejs版本至v14.21.1,重新安装puppeteer后,设置不超时(timeout : 0)再次执行ok 制作成镜像使用:1、制作镜像docker build -t puppeteer_pdf:1.0 .
制作成镜像使用:1、制作镜像docker build -t puppeteer_pdf:1.0 . 2、运行容器docker run -it -v /firmware/:/home/firmware/ puppeteer_pdf:1.0 /bin/bashtree `pwd` -a --dirsfirst查看目录结构:
2、运行容器docker run -it -v /firmware/:/home/firmware/ puppeteer_pdf:1.0 /bin/bashtree `pwd` -a --dirsfirst查看目录结构: 制作好的镜像已上传至dockerhub,可直接通过 docker push 1162886013/puppeteer_pdf:1.0下载。
制作好的镜像已上传至dockerhub,可直接通过 docker push 1162886013/puppeteer_pdf:1.0下载。四、参考
-
相关阅读:
Shader入门精要笔记-屏幕后处理(2)
类 —— 友元、常/静态成员函数
Redis知识-实战篇(1)
跨平台密码管理器KeePassX停止开发,你用过吗?
【音视频】C语言基础快速复习
资深大牛纯手写RabbitMQ 核心笔记,还有谁?
Kubernets Pod概念浅析
高效管理和盘点固定资产的办法
conda配置完整的pytorch虚拟环境
react:swr接口缓存
- 原文地址:https://blog.csdn.net/leiwuhen92/article/details/128031642
