-
基于BERT模型的舆情分类应用研究-笔记
基于BERT模型的舆情分类应用研究-笔记
一、模型介绍
本文工作:在预训练的BERT模型基础上进行结构的微调,将其适应于文本分类任务。
1.Transformer编码器
2013年Word2Vec通过连续词袋模型CBOW和连续Skip-gram模型进行训练。
CBOW:将一个句子中的一个词进行掩盖,通过神经网络介绍上下文词去预测被掩盖的词,通过神经网络计算出该词的词向量表征。原理类似于(人们阅读文本时发现某个词不认识,但可以通过上下文的语境含义去推测出该词的大致意思)
但后来人们发现了Word2Vec的缺点:无法解决多义词。针对该缺点,有学者提出新的表示词嵌入方法—ELMO,该模型利用预训练的词嵌入模型的基础上利用长短期记忆网络编码单词的上下文,调整单词的Embedding编码表示动态的具备了上下文语义。
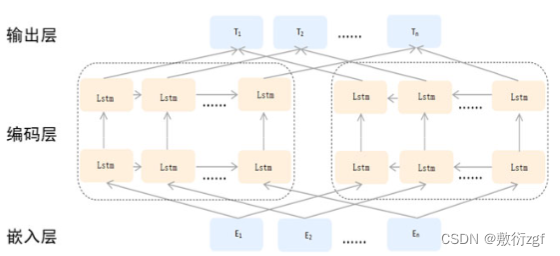 ELMO模型,句子中的每一个单词经过三层编码:嵌入层为单词原始的词向量表示,之后是第一层正向LSTM中对应的词汇编码,主要蕴含句法信息;最后是第二层反向LSTM中对应词汇编码,这层主要蕴含语义信息。通过给予三层各一个权重,将编码结果乘以各自权重累加求和,得到ELMO的输出。
ELMO模型,句子中的每一个单词经过三层编码:嵌入层为单词原始的词向量表示,之后是第一层正向LSTM中对应的词汇编码,主要蕴含句法信息;最后是第二层反向LSTM中对应词汇编码,这层主要蕴含语义信息。通过给予三层各一个权重,将编码结果乘以各自权重累加求和,得到ELMO的输出。BERT模型在ELMO模型之后提出,它与ELMO并无二致,根本的改变在于BERT使用的Transformer编码器代替了原先的LSTM。
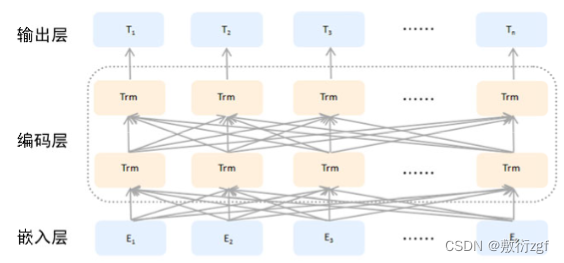
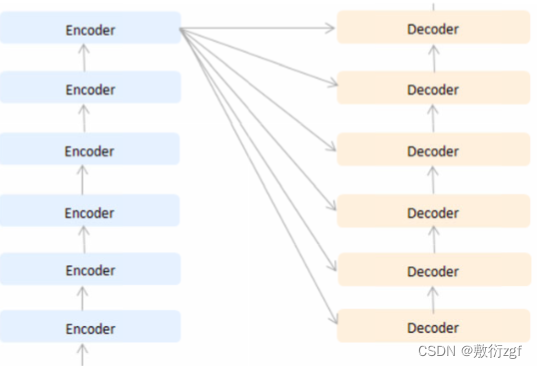
Transformer外部结构,由6个编码器和6个解码器堆叠而成,它接收序列数据,并且输出序列数据,经过6个编码器处理后的数据会分别输入6个解码器进行解码。
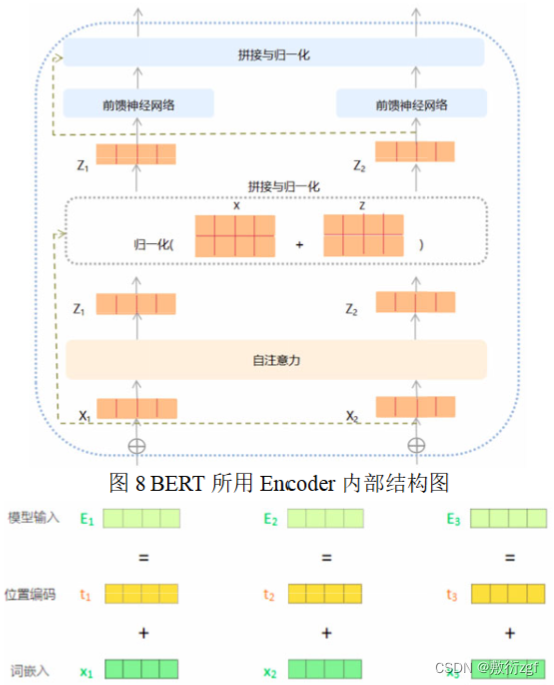
每一个Encoder的内部构造完全相同,但参数不会共享,主要由两部分组成:自注意力层(self-attention)和前馈神经网络层(Feed Forward Neural Network)
每一个Decoder也有类似的内部结构,比Encoder多一个编码-解码注意力层,目的是帮助Decoder重点关注句子中某个关键词语,而忽略其他相关程度较低的词。

self-attention具体的执行流程,可以参考博客

计算公式

Bert模型执行流程:
Bert模型采用多头注意力机制(Multi-headed Attention),相较于self-attention,它为attention层提供了多个表示子空间(Representation Subspaces),拓展了模型关注不同位置的能力。每个注意力头(header)都分配了一个Query、Key、Value权重矩阵。这些权重矩阵在训练开始时随机生成,通过训练来自较低层的Encoder/Decoder的矢量投影到不同的表示子空间。对于每一个注意力头,通过上述公式,计算得到相应的关照程序向量Z0,Z1,…,Z7,将8个向量拼接之后乘以矩阵W0,得到最终的注意力矩阵Z。


二、实验介绍
采用微博舆情数据共14大类:民生、文化、娱乐、体育、财经、房产、汽车、教育、科技、军事、旅游、国际、农业、电竞。
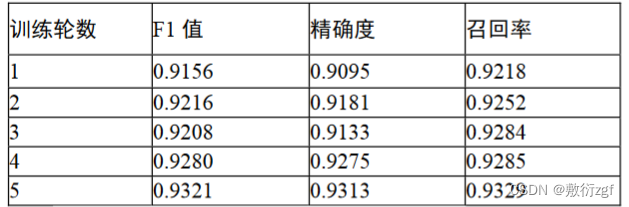
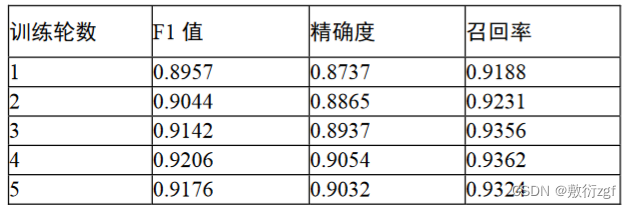
作者将他提出的Bert的fine-turning训练记录与双向LSTM链接的CNN模型训练记录进行对比,作者的改进在训练数据集上表现出较好的F1值、精确度和召回率。 -
相关阅读:
Spring MVC
【课程笔记】编译原理
AI:141-利用自然语言处理改进医疗信息提取与分类
前端面经整理
ThreeJS-3D教学二基础形状展示
详解 Java 19 中的记录类型的模式匹配
C#计算不规则多边形关系
FreeRTOS 简单内核实现8 时间片轮询
鸿蒙HarmonyO实战-ArkUI动画(组件内转场动画)
OFDM 十六讲 2- OFDM and the DFT
- 原文地址:https://blog.csdn.net/qq_45556665/article/details/127412965