1.优缺点#
优点:-
在数据较少的情况下仍然有效,
-
可以处理多类别问题。
缺点:
-
对于输入数据的准备方式较为敏感。
-
适用数据类型:标称型数据
2.朴素贝叶斯的一般过程#
(1) 收集数据:可以使用任何方法。本章使用RSS源。
(2) 准备数据:需要数值型或者布尔型数据。
(3) 分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
(4) 训练算法:计算不同的独立特征的条件概率。
(5) 测试算法:计算错误率。
(6) 使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴
素贝叶斯分类器,不一定非要是文本。
3.概率论知识补充#
3.1条件概率#
下图公式表示在事件A发生的条件下,B发生的概率
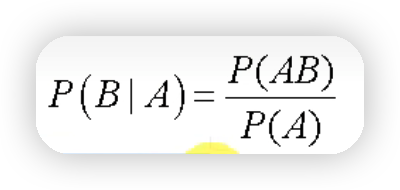
3.2全概率公式#
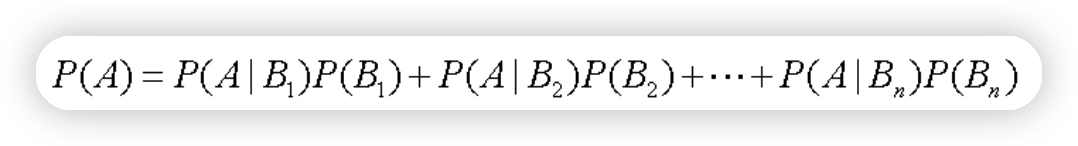
3.3贝叶斯公式#
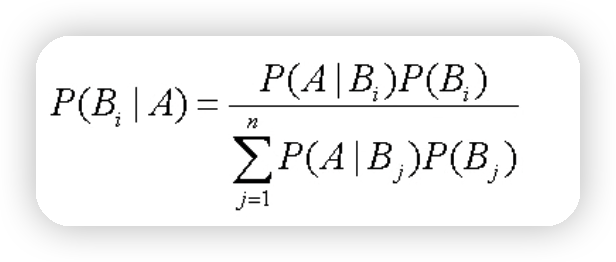
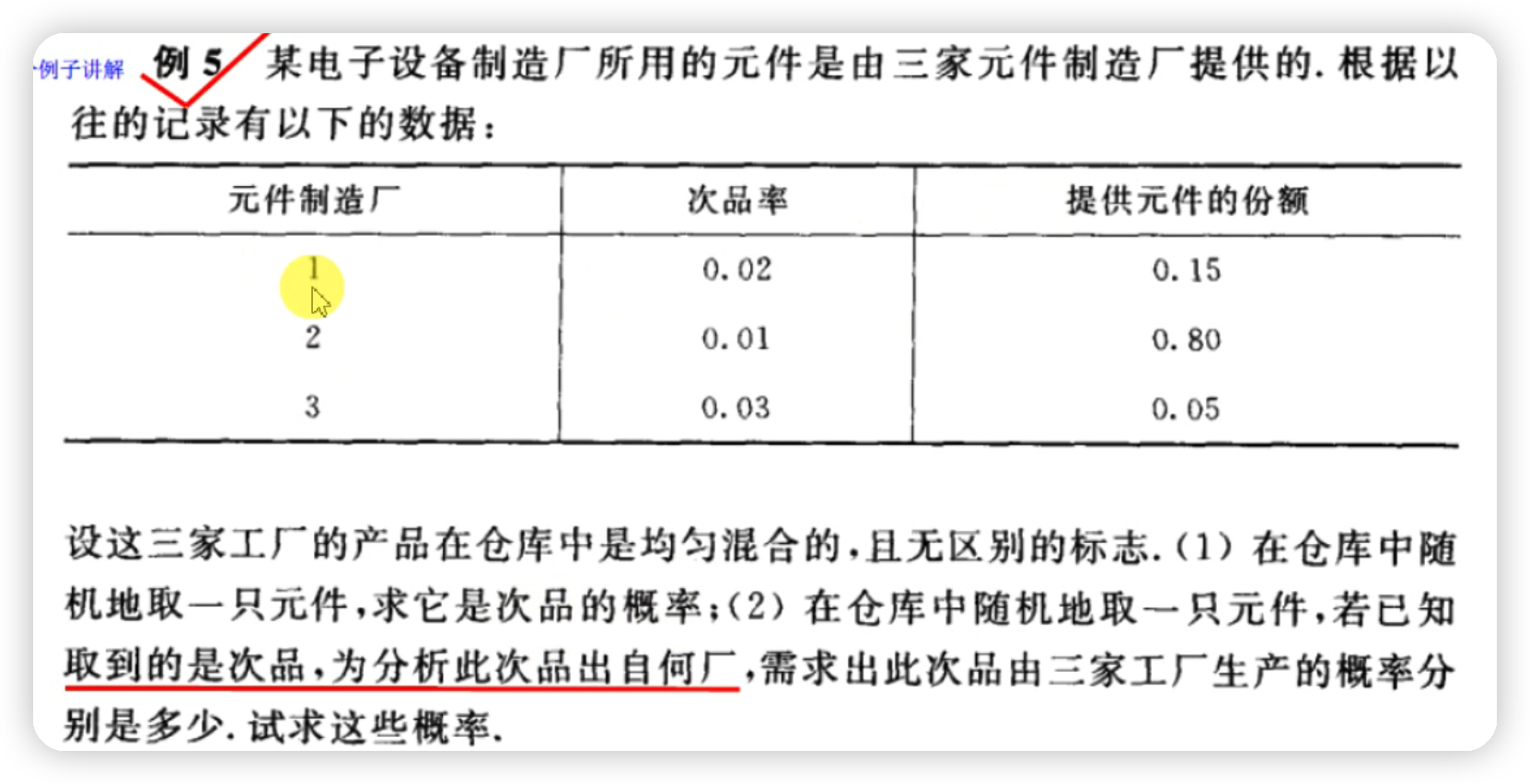

4.使用 Python 进行文本分类#
4.1准备数据:从文本中构建词向量#
我们将把文本看成单词向量或者词条向量,也就是说将句子转换为向量
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性词汇,0代表不是
return postingList,classVec
#创建词汇表-文档向量化的第一步,将所有单词放入set集合中(去除重复的单词)
#原数据集中去掉重复的单词之后,一共有32个单词
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) #取并集
return list(vocabSet)
#词集法-文档向量化的第二步
#inputSet - 切分的词条列表(最初的postingList的每一行)
# vocabList - createVocabList返回的列表
#思想,遍历inputSet中的每一个单词,若在vocabList中存在,则将出现的位置的值设置为1即可
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) #创建一个其中所含元素都为0的向量
for word in inputSet: #遍历每个词条
if word in vocabList: #如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec #返回文档向量
得到的向量集为:

4.2从词向量计算概率#
#朴素贝叶斯分类器训练函数
# trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
# trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)#计算训练的文档数目 6
numWords = len(trainMatrix[0]) #计算每篇文档的词条数 32
pAbusive = sum(trainCategory)/float(numTrainDocs)#文档属于侮辱类的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords)#创建numpy.zeros数组,词条出现数初始化为0
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]#计算侮辱性单词所在行每个单词出现的频数
p1Denom += sum(trainMatrix[i])#侮辱性单词所在行的总共单词的个数
else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]#计算非侮辱性单词所在行每个单词出现的频数
p0Denom += sum(trainMatrix[i])#非侮辱性单词所在行单词的总个数
p1Vect = np.log(p1Num/p1Denom)#计算侮辱性单词所在行的每个单词是侮辱性单词的概率
p0Vect = np.log(p0Num/p0Denom)#计算非侮辱性单词所在行的每个单词是非侮辱性单词的概率
return p0Vect,p1Vect,pAbusive
4.3根据现实情况修改分类器#
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概 率,即计算p(w0|1)p(w1|1)p(w2|1)。如果其中一个概率值为0,那么最后的乘积也为0。为降低 这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。p0Num = np.ones(numWords); p1Num = np.ones(numWords)#创建numpy.zeros数组,词条出现数初始化为0
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为0
另一个遇到的问题是下溢出,这是由于太多很小的数相乘造成的。当计算乘积 p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)时,由于大部分因子都非常小,所以程序会下溢出或者 得到不正确的答案。(读者可以用Python尝试相乘许多很小的数,最后四舍五入后会得到0。)一 种解决办法是对乘积取自然对数。在代数中有ln(a*b) = ln(a)+ln(b),于是通过求对数可以 避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。
p1Vect = np.log(p1Num/p1Denom)#计算侮辱性单词所在行的每个单词是侮辱性单词的概率
p0Vect = np.log(p0Num/p0Denom)#计算非侮辱性单词所在行的每个单词是非侮辱性单词的概率
朴素贝叶斯分类函数
#朴素贝叶斯分类器分类函数
# vec2Classify - 待分类的词条数组
# p0Vec - 侮辱类的条件概率数组
# p1Vec -非侮辱类的条件概率数组
# pClass1 - 文档属于侮辱类的概率
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify*p1Vec)+np.log(pClass1) #计算测试集对应每个单词是侮辱性的概率
p0 = sum(vec2Classify*p0Vec)+np.log(1.0-pClass1)#计算测试集中对应每个单词是非侮辱性单词的概率
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
#测试朴素贝叶斯分类器
def testingNB():
listOPosts,listClasses = loadDataSet() #创建实验样本
myVocabList = createVocabList(listOPosts) #创建词汇表
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #将实验样本向量化
p0V,p1V,pAb = trainNB0(trainMat,listClasses)#训练朴素贝叶斯分类器
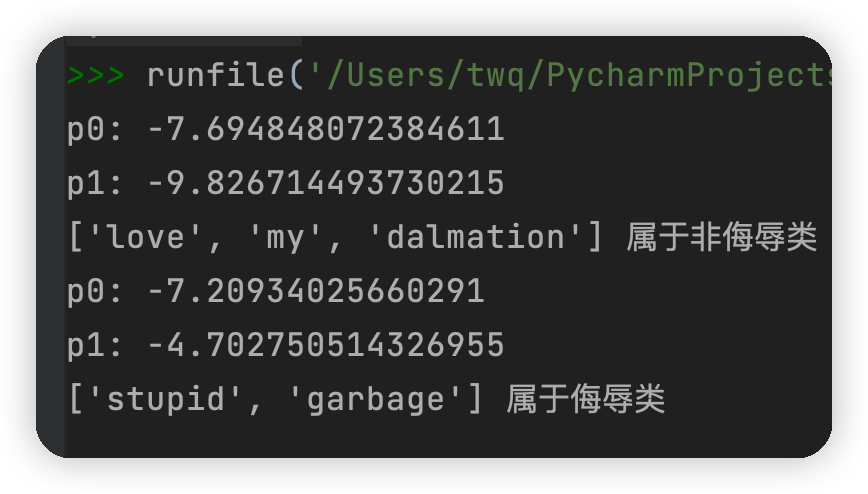
testEntry = ['love', 'my', 'dalmation'] #测试样本1
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry))#测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类')#执行分类并打印分类结果
testEntry = ['stupid', 'garbage']#测试样本2
thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类')
测试结果:
总结:整个代码完成的步骤如下:
-
由原始数据得到分类列表,将原始数据存入set集合中去除重复数据
-
由set集合和原始数据得到向量集
- 循环遍历原始数据的每一行,并判断该行中每个元素在set集合中是否存在,若存在,则将set集合中对应位置设为1,最后得到一个一行set集合中元素个数这么多列的一个向量组,依次类推,原始数据每一行都得到一个向量组,最终组成原始数据的向量集
-
计算概率
-
循环遍历分类数据集中每一个元素,根据该元素找到其在向量集中所在的行,然后统计该行每个元素出现的频次和改行总元素的个数,依次类推,找到每个类别所在行元素出现的频次,以及该类别对应元素的总个数
-
最后根据每个类别的元素出现的频次除以该类别下元素的总数,得到每个元素是该类别的概率
-
-
测试数据集
-
首先计算出测试数据集对应的向量集(也就是测试集中的元素出现在set集合中的位置设为1)
-
然后根据该向量集和之前得到的每个元素是每一类别的概率的数据集相乘,就可以得到测试集中每个元素是某一类别的概率
-
然后取算出来的是每个类别的概率的最大值,即测试集就是该类别
-
5.过滤垃圾邮件#
Mac电脑的朋友在导入邮件数据的时候如果出现编码错误,可以使用如下命令修改文件的编码格式
enconv -L zh_CN -x UTF-8 filename
#2.垃圾邮件分类
def textParse(bigString):#将字符串转换为字符列表
import re
#机器学习与实战课本上的这种正则表达式的写法切分会将每一个单词的每一个字母都单独切分开,可以自己调试看看
#listOfTokens = re.split(r'\W*', bigString)
listOfTokens =re.split(r'\W+', bigString)#将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母(因为在判断一个邮件是否是垃圾邮件的时候,仅凭一个字母还不能判断出来)例如大写的I,其它单词变成小写
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26): #遍历25个txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) #读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1)#标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())#读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0)#标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) #创建词汇表,不重复
trainingSet = list(range(50)); testSet = []#创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10): #从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) #随机选取索索引值
testSet.append(trainingSet[randIndex])#添加测试集的索引值
del(trainingSet[randIndex]) #在训练集列表中删除添加到测试集的索引值
trainMat = []; trainClasses = [] #创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: #遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) #将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) #训练朴素贝叶斯模型
errorCount = 0 #错误分类计数
for docIndex in testSet: #遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) #测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: #如果分类错误
errorCount += 1 #错误计数加1
print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
测试结果
