-
C++11的学习
目录
1. 列表初始化
1.1 { } 初始化
在C++98中 { } 的作用是用来对数组或者结构体的初始化而设定的
比如:
- struct Point
- {
- int _x;
- int _y;
- };
- int main()
- {
- int array1[] = { 1, 2, 3, 4, 5 };
- int array2[5] = { 0 };
- Point p = { 1, 2 };
- return 0;
- }
在C++11中扩大了用大括号括起的列表使用的范围,不再仅仅是用来初始化数组和结构体,使其可以使用在所有的内置类型和自定义类型中,而实现这个功能就离不开一个容器 --- std:: initializer_list
1.2 initilizer_list

一般{ }内的元素,会被编译器识别成为initializer_list的参数,而initialize_list在C++11中一般是作为构造函数的新参数:

我们可以发现在C++11中就多了initializer_list作为新参数来构造函数
2. 声明
2.1 auto
在C++98中 auto只是作为一个存储类型的说明符,表示变量是局部自动存储类型,而在C++11中将auto 之前的用法舍弃,将其用于实现自动类型的推导。
- #include
- using namespace std;
- int main()
- {
- int a = 10;
- auto b = 20;
- auto* p = &a;
- cout << typeid(b).name() << endl;
- cout << typeid(p).name() << endl;
- return 0;
- }
2.2 decltype
我们可以使用typeid.name()来帮助我们推出变量的类型,那么我们可以使用这个来实现变量的声明吗?

发现是不可以的,因为typeid.name()的返回值是一个string类型,那么我们就需要使用decltyp来帮助我们
decltype是一个关键字,作用是将变量的类型声明作为指定的类型

2.3 nullptr
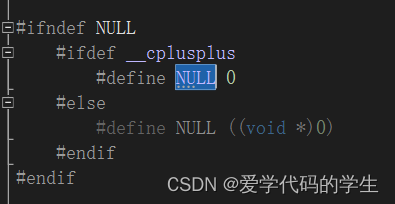
在C++11之前NULL被定义成字面值0,这样可能会带来一些问题,因为0既可以指为指针,又可以指为常量,出于安全的角度,C++11出台了nullptr,表示空指针。
3. 范围for循环
- #include
- #include
- using namespace std;
- int main()
- {
- vector<int> array = {1,2,3,4,5};
- for(auto &e : array)
- {
- cout<
- }
- return 0;
- }
范围for循环的底层结构其实也是迭代器来进行的实现。
4. STL容器的改变
4.1 新增容器
在C++11中引入了两个新的容器分别是:1. unordered_map,2. unordered_set
那么他们和map和set又有什么不同呢?
1. 通过名称我们可以发现这两个容器都是无序的,也就是在遍历容器时,他们是不会进行排序2
2. 实现方式不同,map、set的实现底层都是红黑树,而unordered_map、unordered_set的底层都是哈希函数
4.2 接口的变量

我们可以发现每个容器的构造函数都新增加了几个API,其中就包括我们之前所说的initializer_list和接下来我们要提到的右值引用
5. 右值引用
5.1 左值引用和右值引用
传统的C++写法中就包括引用这个语法,在C++11中又新增加了右值引用这种写法,那么从C++11开始我们之前学过的引用都被称为左值引用,但是无论是之前学过的左值引用,还是新添加了右值引用都是对变量起别名。
1. 什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名或解引用的指针),我们可以获取它的地址+可以对它赋
值,左值可以出现赋值符号的左边,右值不能出现在赋值符号左边。定义时const修饰符后的左
值,不能给他赋值,但是可以取它的地址。左值引用就是给左值的引用,给左值取别名。
我们可以发现左值的最大特点就是: 可以取地址
- int main()
- {
- // 以下的p、b、c、*p都是左值
- int* p = new int(0);
- int b = 1;
- const int c = 2;
- // 以下几个是对上面左值的左值引用
- int*& rp = p;
- int& rb = b;
- const int& rc = c;
- int& pvalue = *p;
- return 0;
- }
2. 什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引
用返回)等等,右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能
取地址。右值引用就是对右值的引用,给右值取别名。- int main()
- {
- double x = 1.1, y = 2.2;
- // 以下几个都是常见的右值
- 10;
- x + y;
- fmin(x, y);
- // 以下几个都是对右值的右值引用
- int&& rr1 = 10;
- double&& rr2 = x + y;
- double&& rr3 = fmin(x, y);
- // 这里编译会报错:error C2106: “=”: 左操作数必须为左值
- 10 = 1;
- x + y = 1;
- fmin(x, y) = 1;
- return 0;
- }
由此我们可以发现左右引用的最大区别就是:是否能取地址
5.2 右值引用的使用场景和意义
那么我们既然已经有了左值引用,为什么还要设置一个右值引用?
首先我们来思考一下,使用左值引用作为参数的特点:提高效率,不用进行临时拷贝
那么左值引用有什么缺点呢?
但是当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回,
只能传值返回。例如:bit::string to_string(int value)函数中可以看到,这里只能使用传值返回,
传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷贝构造)。如果返回值类型是内置类型,那么消耗还小,那如果是自定义类型呢?如果是vector
什么是移动构造?
移动构造的本质就是将参数右值的资源窃取过来,占位己有,以完成资源转移,那么如果之前进行的是深拷贝,则在移动构造下只需要将传入的参数资源占位己有即可,无序进行拷贝,移动构造就是窃取别人的资源。
那么不仅仅有移动构造,还有移动赋值,其原理也和移动构造一样,将他人的资源窃取。
5.3 右值引用和左值引用的转换
那么右值引用只能引用右值,但右值引用不能引用左值吗?在某些特点的场景下我们需要右值引用左值,那么应该怎么做? 如果需要用右值引用一个左值,可以通过move来将一个左值转换称为右值,在C++11中实现了std::move这个函数,其作用仅仅是将左值转换成右值。
6. lambda表达式
在C++98中如果想对一个数组集合进行排序的话,可以使用std::sort的方法
- #include
- #include
- #include
- #include
- using namespace std;
- int main()
- {
- vector<int>a{ 1,2,3,7,6,4,3,2 };
- sort(a.begin(), a.end());
- //sort默认升序
- for (auto e : a) cout << e << ' ';
- cout<//如果要实现降序,则需要改变比较规则sort(a.begin(), a.end(),greater<int>());for (auto e : a) cout << e << ' ';return 0;}

如果待排列的是自定义类型,那么我们如果需要排序的话,需要自己制定排序规则:
- #include
- #include
- #include
- using namespace std;
- struct Goods
- {
- string _name;
- double _price;
- int _evaluate;
- };
- struct lessname
- {
- bool operator()(const Goods a,const Goods b)
- {
- return a._name < b._name;
- }
- };
- struct lessprice
- {
- bool operator()(const Goods a,const Goods b)
- {
- return a._price < b._price;
- }
- };
- int main()
- {
- vector
arr = {{"苹果",5,4},{"香蕉",6,3},{"桃子",3,2}}; - //如果我们按照名称来排序
- sort(arr.begin(),arr.end(),lessname());
- for(auto e:arr)
- {
- cout<<"名称"<
- cout<<"价钱"<
- cout<<"评价"<}cout<//按照价钱来排序sort(arr.begin(),arr.end(),lessprice());for(auto e:arr){cout<<"名称"<cout<<"价钱"<cout<<"评价"<}return 0;}
那么当我们在实现自定义类型,并需要对它进行各方面的排序时,我们都需要自己去实现一个仿函数,并且这种写法是复杂的且多余的。
那么在C++11中,出现了lambda表达式来解决了这类问题。
6.1 lambda表达式
lambda表达式书写格式:[capture-list] (parameters) mutable -> return-type { statement
}- capture-list:也称作捕捉列表,该列表总是出现在lamdba表达式的起始位置,编译器会根据[ ]来判断该表达式是否是lamdba表达式,捕捉列表可以捕捉上下变量以供lamdba表达式的使用
- (parameters):也称作参数列表,与普通函数的参数一致,也可以不用传参。
- mutable :在默认情况下,传入lamdba表达式的参数都是const属性,那么mutable的作用就是将参数的const属性取消
- -> return-type:返回值类型,一般情况下,我们可以省略
- {statement}:函数体,在函数体内部可以使用捕捉列表中的所有变量
那么对于数组集合的升序排序使用lamdba是怎么完成的呢?
- #include
- #include
- #include
- using namespace std;
- int main()
- {
- vector<int> arr{1,4,2,5,3,4,1};
- //升序排列
- sort(arr.begin(),arr.end(),[](int x,int y){return xfor(auto e:arr) cout<return 0;}
- 相关阅读:
Docker镜像的制作(容器转镜像和DockerFile)
rk3568 buildroot
MyBatis-Plus快速入门
Android音视频开发:AudioRecord录制音频
内存函数(memcpy、memmove、memset、memcmp)你真的懂了吗?
关于Git的入门教程(附GitHub和Gitee的使用方法)
keras归一化与反归一化
项目管理之财务基础
《从0开始写一个微内核操作系统》4-关于mmu
这五个bug,论文绘图时千万别碰!
- 原文地址:https://blog.csdn.net/Rinki123456/article/details/127058819
