-
python字典与集合还有数据类型转换
字典——使用大括号{},是可变数据类型
使用 键查找数据,不支持下标,数据以键值对出现,和数据顺序没有关系- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct['age'])
新增数据- disct = {'name':'gyq','age':18,'Gender':'boy'}
- disct['id'] = 110 #默认添加到尾部
- print(disct)
修改字典数据——通过已有的键修改数据,不然就成了添加数据- disct = {'name':'gyq','age':18,'Gender':'boy'}
- disct['name'] = 'Tom'
- print(disct)
删除指定数据——通过指定key实现- disct = {'name':'gyq','age':18,'Gender':'boy'}
- del disct['name']
- print(disct)
清空字典——clear()- disct = {'name':'gyq','age':18,'Gender':'boy'}
- disct.clear()
- print(disct) #{}
查找1.key值查找- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct['name'])
2.get()语法:字典序列.get(key, 默认值)- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.get('age'))
注意:当查找的key不存在则返回第二个参数(默认值),如果省略的第二个参数,则返回None。如:- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.get('id')) #None
- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.get('id',0)) #0
key——查找字典中所有的key,返回可迭代对象- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.keys()) #dict_keys(['name', 'age', 'Gender'])
values——查找字典中所有的values,返回可迭代对象- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.values()) #dict_values(['gyq', 18, 'boy'])
items—— 查找字典中所有的键值对,返回可迭代对象里面的数据是元组,元组数据1是字典key,元组数据2是key对应的值- disct = {'name':'gyq','age':18,'Gender':'boy'}
- print(disct.items()) #dict_items([('name', 'gyq'), ('age', 18), ('Gender', 'boy')])
for循环遍历字典的key- disct = {'name':'gyq','age':18,'Gender':'boy'}
- for key in disct.keys():
- print(key)
for循环遍历字典的values- disct = {'name':'gyq','age':18,'Gender':'boy'}
- for values in disct.values():
- print(values)
for循环遍历字典的元素- disct = {'name':'gyq','age':18,'Gender':'boy'}
- for items in disct.items():
- print(items)
for循环遍历字典的键值对(拆包)- disct = {'name':'gyq','age':18,'Gender':'boy'}
- for key,value in disct.items():
- print(f'{key} = {value}')
集合
可变类型的数据,无序创建集合使用{}或set(),但是如果要创建 空集合只能使用set(),因为{} 用来创建空字典。- s1 = {10,20,30,40}
- print(s1) #{40, 10, 20, 30}
注意:这是无序显示,所以 集合没有顺序集合具有 去重功能- s2 = {10,10,20,30,40}
- print(s2) #{40, 10, 20, 30}
使用 set()创建集合- s3 = set('gyq1234')
- print(s3) #{'4', '3', '2', '1', 'y', 'q', 'g'}
创建 空集合- s4 = set()
- print(s4) #set()
add() 增加单个数据- s1 = {10}
- s1.add(20)
- print(s1)
注意:如果追加的数据是 集合已有数据,则什么都不做。update() 是增加序列时使用- s1 = {10}
- s1.update([100,20,30])
- print(s1)
删除数据remove() , 删除集合中的指定数据,如果数据不存在则报错- s1 = {10,20}
- s1.remove(10)
- print(s1)
discard() 删除集合中的指定数据,如果数据 不存在也不会报错- s1 = {10,20}
- s1.remove(10)
- print(s1)
pop() 随机删除集合中的某个数据, 并返回这个数据- s1 = {10,20,30,40}
- del_num = s1.pop()
- print(del_num)
查找数据in : 判断数据在集合序列not in : 判断数据不在集合序列- s1 = {10,20,30,40}
- print(10 in s1 ) #True
- print(200 not in s1 ) #True
公共操作
运算符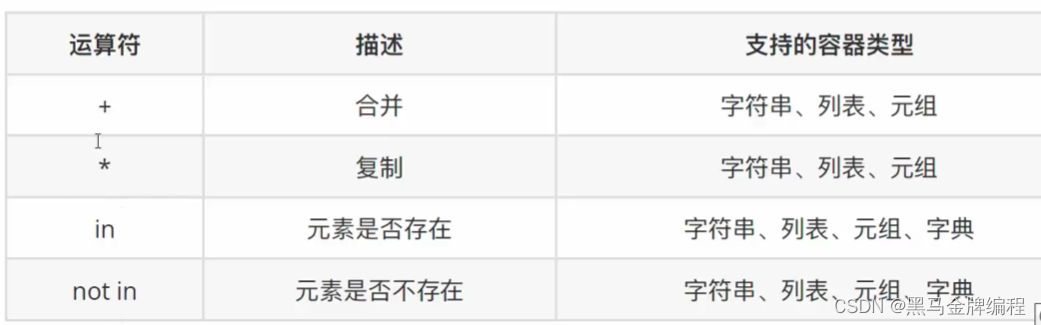 print(变量1 + 变量2)print ( 变量 * 想要复制的数量 )print(元素 in 变量名)print(元素 not in 变量名)公共方法
print(变量1 + 变量2)print ( 变量 * 想要复制的数量 )print(元素 in 变量名)print(元素 not in 变量名)公共方法 range(start,end,step) ——配for循环使用
range(start,end,step) ——配for循环使用- for sum in range(1,6,2):
- print(sum)
enumerate (可遍历对象,tart=0)——start参数用来设置遍历数据的下标的起始值,默认为0- list1 = ['a','b','c','d','e']
- for i in enumerate(list1):
- print(i)
注意: enumerate ()返回的结果是元组,元组第一个数据是原迭代对象的数据对应的下标,元组第二个数据是元迭代对象对象的数据
数据类型转换
tuple()——转换成元组set()——转换成集合,集合没有顺序,不支持下标,有自动去重功能list()——转换成列表- list1 = [10,20,30]
- s1 = {10,20,30}
- t1 = (10,20,30)
- print("这是列表转元组:", tuple(list1))
- print("这是集合转列表:",list(s1))
- print("这是元组转集合:",set(t1))
列表推导式
作用:用一个表达式创建一个有规律的列表或控制一个有规律列表优点:简化代码- list3 =[i for i in range(10)] #第一个i作为返回值,将生成的序列存储到i中,返回给变量。
- print(list3)
#第一个i作为返回值,将生成的序列存储到i中,返回给变量。带if的列表推导式- list5 = [i for i in range(10) if i % 2 == 0]
- print(list5)
多个for循环实现列表推导式- list6 = [(i,j) for i in range(1,3) for j in range(3)]
- print(list6) #[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
字典推导式
创建一个字典:字典key是1-5数字,value是这个数字的2次方- dict1 = {i:i**2 for i in range(1,5)}
- print(dict1)
将两个列表合并为·1一个字典- list1 = ['name','age','gender']
- list2 = ['gyq',20,'man']
- dict1 = {list1[i]: list2[i] for i in range(len(list1))}
- print(dict1)
注意:如果两个列表数据个数相同,len统计任何一个列表的长度都可以如果两个列表数据个数不同,len统计数据多的列表数据个数会报错;len统计数据少的列表数据个数不会报错。提取字典中目标数据——大于等于200- counts = {'MBP':268,'HP':125,'DELL':201,'Lenovo':99,'acer':99}
- dict1 = {key:value for key, value in counts.items() if value >= 200}
- print(dict1)
集合推导式
需求:创建一个集合,数据为下方列表的2次方- list1 = [1,1,2]
- list1 = [1,1,2]
- set1 = {i ** 2 for i in list1}
- print(set1) #{1,4}
注意集合有去重功能,所以只显示{1,4} -
相关阅读:
大数据开发是做什么的?怎样入门?
Redis系列学习文章分享---第三篇(Redis快速入门之Java客户端--短信登录+session+验证码+拦截器+登录刷新)
如何进行pyhon的虚拟环境创建及管理
AI落地制造业:智能机器人应具备这4种能力
Postman API测试工具的使用
C++ Reference: Standard C++ Library reference: C Library: cerrno
docker 映射端口穿透内置防火墙
JAVA代码审计-json web token 安全分析
你安全吗?丨虎云系统“后门”
《Java8实战》读书笔记09:用 Optional 处理值为 null 的情况
- 原文地址:https://blog.csdn.net/gyqailxj/article/details/127129055