-
Performance of the Dell PowerEdge R750xa Server for MLPerf™ Inference v2.0
Abstract
Dell Technologies recently submitted results to the MLPerf Inference v2.0 benchmark suite. The results provide information about the performance of Dell servers. This blog takes a closer look at the Dell PowerEdge R750xa server and its performance for MLPerf Inference v1.1 and v2.0.We compare the v1.1 results with the v2.0 results. We show the performance difference between the software stack versions. We also use the PowerEdge R750xa server to demonstrate that the v1.1 results from all systems can be referenced for planning an ML workload on systems that are not available for MLPerf Inference v2.0.
PowerEdge R750xa server
Built with state-of-the-art components, the PowerEdge R750xa server is ideal for artificial intelligence (AI), machine learning (ML), and deep learning (DL) workloads. The PowerEdge R750xa server is the GPU-optimized version of the PowerEdge R750 server. It supports accelerators as 4 x 300 W DW or 6 x 75 W SW. The GPUs are placed in the front of the PowerEdge R750xa server allowing for better airflow management. It has up to eight available PCIe Gen4 slots and supports up to eight NVMe SSDs.The following figures show the PowerEdge R750xa server (source):

Figure 1: Front view of the PowerEdge R750xa server

Figure 2: Rear view of the PowerEdge R750xa server

Figure 3: Top view of the PowerEdge R750xa server
Configuration comparison
The following table describes the software stack configurations from the two rounds of submission for the closed data center division:Table 1: MLPerf Inference v1.1 and v2.0 software stacks
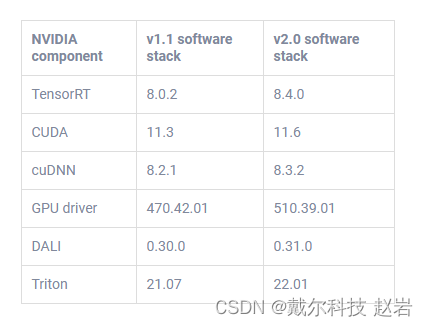
Although the software has been updated across the two rounds of submission, performance is consistent, if not better, for the v2.0 submission. For MLPerf Inference v2.0, Triton performance results can be extrapolated from MLPerf Inference v1.1 except for the 3D U-Net benchmark, which is due to a v2.0 dataset change.The following table describes the System Under Test (SUT) configurations from MLPerf Inference v1.1 and v2.0 of data center inference submissions:
Table 2: MLPerf Inference v1.1 and v2.0 system configuration of the PowerEdge R750xa server

In the v1.1 round of submission, Dell Technologies submitted four different configurations on the PowerEdge R750xa server. Although the GPU count of four was maintained, Dell Technologies submitted the 40 GB and the 80 GB versions of the NVIDIA A100 GPU. Additionally, Dell Technologies submitted Multi-Instance GPU (MIG) numbers using 28 instances of the one compute instance of the 10gb memory profile on the 80 GB A100 GPU. Furthermore, Dell Technologies submitted power numbers (MaxQ is a performance and power submission) for the 40 GB version of the A100 GPU and submitted with the Triton server on the 80 GB version of the A100 GPU. A discussion about the v1.1 submission by Dell Technologies can be found in this blog.Performance comparison of the PowerEdge R70xa server for MLPerf Inference v2.0 and v1.1
ResNet 50
ReNet50 is a 50-layer deep convolution neural network that is made up of 48 convolution layers along with a single max pool and average pool layer. This model is used for computer vision applications including image classification, object detection, and object classification. For the ResNet 50 benchmark, the performance numbers from the v2.0 submission match and outperform in the server and offline scenarios respectively when compared to the v1.1 round of submission. As shown in the following figure, the v2.0 submission results are within 0.02 percent in the server scenario and outperform the previous round by 1 percent in the offline scenario:

Figure 4: MLPerf Inference v2.0 compared to v1.1 ResNet 50 per card results on the PowerEdge R750xa serverBERT
Bidirectional Encoder Representation from Transformers (BERT) is a state-of-the-art language representational model for Natural Language Processing applications. This benchmark performs the SQuAD question answering task. The BERT benchmark consists of default and high accuracy modes for the offline and server scenarios. In the v2.0 round of submission, the PowerEdge R750xa server matched and slightly outperformed its performance from the previous round. In the default BERT server and offline scenarios, the extracted performance is within 0.06 and 2.33 percent respectively. In the high accuracy BERT server and offline scenarios, the extracted performance is within 0.14 and 1.25 percent respectively.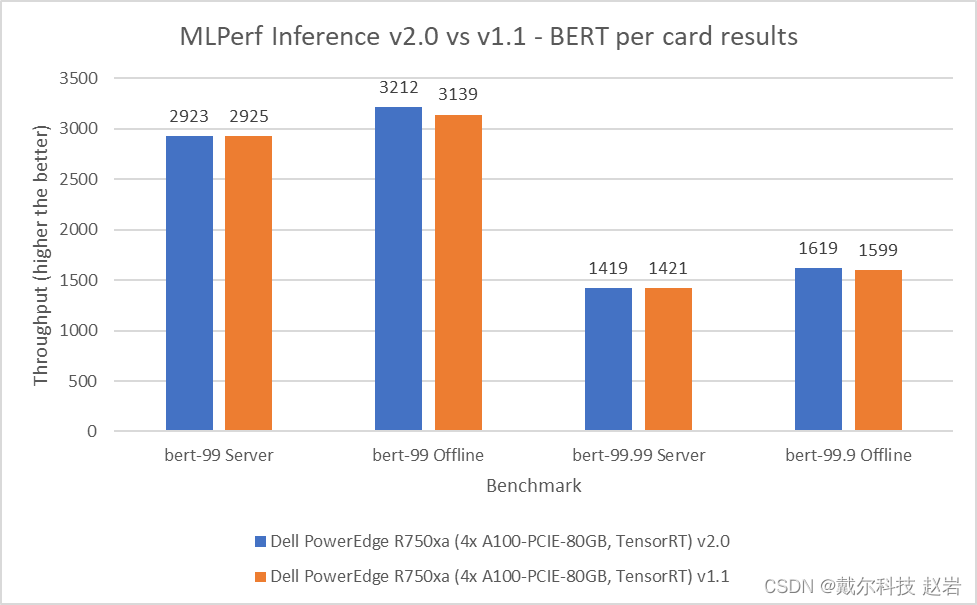
Figure 5: MLPerf Inference v2.0 compared to v1.1 BERT per card results on the PowerEdge R750xa serverSSD-ResNet 34
The SSD-ResNet 34 model falls under the computer vision category. This benchmark performs object detection. For the SSD-ResNet 34 benchmark, the results produced in the v2.0 round of submission are within 0.14 percent for the server scenario and show a 1 percent improvement in the offline scenario.

Figure 6: MLPerf Inference v2.0 compared to v1.1 SSD-ResNet 34 per card results on the PowerEdge R750xa serverDLRM
Deep Learning Recommendation Model (DLRM) is an effective benchmark for understanding workload requirements for building recommender systems. This model uses collaborative filtering and predicative analysis-based approaches to process large amounts of data. The DLRM benchmark consists of default and high accuracy modes, both containing the server and offline scenarios. For the server scenario in both the default and high accuracy modes, the v2.0 submissions results are within 0.003 percent. For the offline scenario across both modes, the PowerEdge R750xa server showed a 2.62 percent performance gain.

Figure 7: MLPerf Inference v2.0 compared to v1.1 DLRM per card results on the PowerEdge R750xa serverRNNT
The Recurrent Neural Network Transducers (RNNT) model falls under the speech recognition category. This benchmark accepts raw audio samples and produces the corresponding character transcription. For the RNNT benchmark, the PowerEdge R750xa server maintained similar performance behavior within 0.04 percent in the server mode and showing 1.46 percent performance gains in the offline mode.

Figure 8: MLPerf Inference v2.0 compared to v1.1 RNNT per card results on the PowerEdge R750xa server3D U-Net
The 3D U-Net performance numbers have changed in terms of scale and are not comparable in a bar graph because of a change to the dataset. The new dataset for this model is the Kitts 2019 Kidney Tumor Segmentation set. However, the PowerEdge R750xa server yielded Number One results among the PCIe form factor systems that were submitted. This model falls under the computer vision category, but it specifically deals with medical image data.Results summary
Figure 1 through Figure 8 show the consistent performance of the PowerEdge R750xa server across both rounds of submission.The following figure shows that in the offline scenarios for the benchmarks there is a small but noticeable performance improvement:
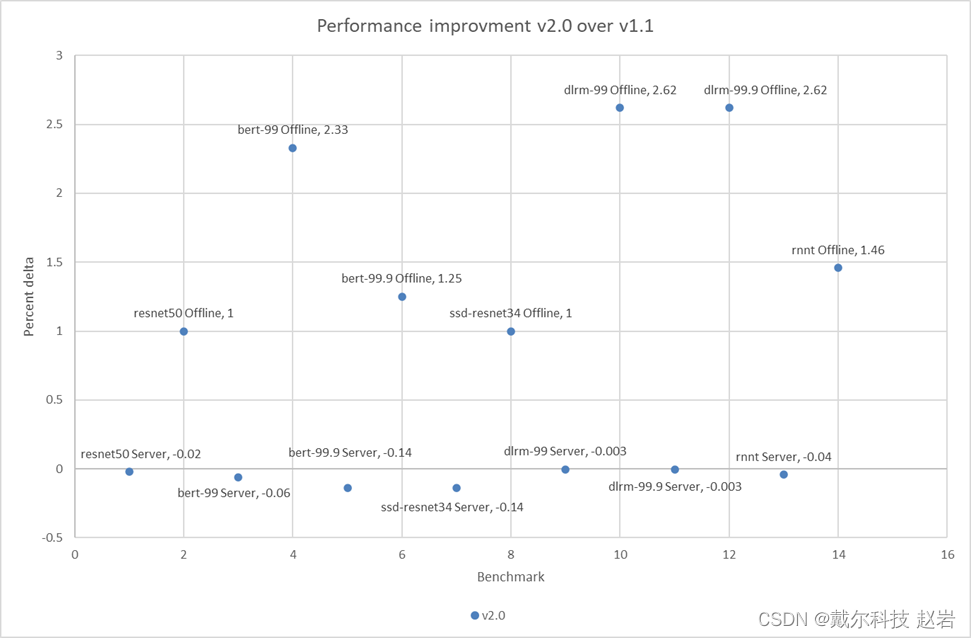
Figure 9: Performance improvement in percentage of the PowerEdge R750xa server across MLPerf Inference v2.0 and v1.1The small percentage delta in the server scenarios can be a result of noise and are consistent with the previous round of submission.
Conclusion
This blog confirms the consistent performance of the Dell PowerEdge R750xa server across the MLPerf Inference v1.1 and MLPerf Inference v2.0 submissions. Because an identical system from round v1.1 performed at a consistent level for MLPerf Inference v2.0, we see that the software stack upgrades had minimal impact on performance. Therefore, the optimal results from the v1.1 round of submission can be used for making informed decisions about server performance for a specific ML workload. Because Dell Technologies submitted a diverse set of configurations in the v1.1 round of submission, customers can take advantage of many results. -
相关阅读:
一次数据库主键莫名其妙的变得非常大排查记录
ADSP-21489的开发详解:Norflash的编程和烧写
手把手教你随机合并全部视频添加同一个文案的方法
20231024后端研发面经整理
网络——多区域OSPF配置(OSPF系列第1篇)
spring-cloud-starter-alibaba-nacos-discovery 依赖不下来的解决办法
山东省技能兴鲁网络安全大赛 web方向
实现mnist手写数字识别
Spring Cloud 运维篇1——Jenkins CI/CD 持续集成部署
一文看懂拉格朗日乘子法、KKT条件和对偶问题
- 原文地址:https://blog.csdn.net/lxbjjszy/article/details/127123651