-
HTTP协议
一、HTTP协议的具体格式。
深度好文,值得一看:深入了解HTTP(已完结)
1、HTTP 请求报文
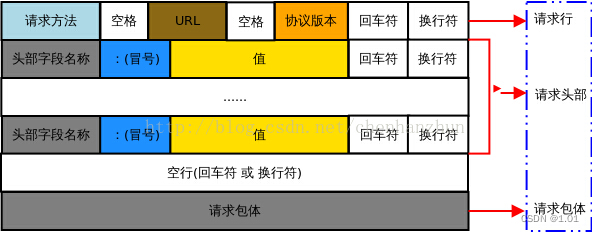
HTTP 请求报文由请求行、请求头部、空行 和 请求包体 4 个部分组成请求头部字段(常用)
Host字段 host字段可以是域名,也可以是ip地址。host字段域名/ip后可以跟端口号,如Host: www.6san.com:8080
Connection: keep-alive
用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用Accept: / //表示啥都可以
声明自己可以接受哪些数据格式Accept-Encoding: gzip, deflate
说明自己可以接受哪些压缩方法2、HTTP 响应报文

HTTP 响应报文由状态行、响应头部、空行 和 响应包体 4 个部分组成
响应头部字段(常用)Content-Length:1000
服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据长度。Content-Type: text/html; charset=utf-8
用于服务器回应时,告诉客户端,本次数据是什么格式。Content-Encoding: gzip
说明数据的压缩方法,表示服务器返回的数据使用了什么压缩格式注意:
1、http协议明文传输,没有针对内容加密的措施,所以,使用抓包工具看到的内容(加密或未加密)的都是明文内容。
2、base64编码
(URI中编码知识)(有空得研究研究)为什么需要URL编码
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc& ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和= 符号进行转义,也就是对其进行编码。
又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。
Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。
URL中对非法字符进行编码
Url编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的 十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就 是%61,我们在地址栏上输入Google,实际上就等同于在google上搜索abc了。又如@符号 在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。 对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如“中文”使用UTF-8字符集得到 的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到“%E4%B8%AD%E6%96%87”。
如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。 例如“Url编码”,使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符“Url”,因此这三个字节可以用非保留字符“Url”表示。最终的Url编码可以简化成 “Url%E7%BC%96%E7%A0%81” ,当然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81”也是可以的。
来自:https://zhuanlan.zhihu.com/p/22169525
HTTP1.1的优点:
1、长连接
2、管道传输
举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求,但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。 -
相关阅读:
java面向对象(上)
使用p2p实现Linux内网快速分发文件
C++学习第八课--迭代器精彩演绎、失效分析及弥补、实战笔记
C进阶-自定义类型:结构体,枚举,联合
c++ | json库的使用 | josn静态库生成
GTK进行rgb绘图
JVM 程序计数器
基于JAVA天津城建大学校友录管理系统计算机毕业设计源码+系统+mysql数据库+lw文档+部署
并发修改异常
EMQX Newsletter 2022-08|企业版 5.0 开发进行中、EMQX Kubernetes Operator 2.0 即将发布
- 原文地址:https://blog.csdn.net/weixin_43743711/article/details/127098388