-
【MySQL查缺补漏学习】六、MySQL中使用JOIN小结

说明:【
MySQL查缺补漏学习】系列是在工作之余,梳理的一些关于MySQL的一些容易忽略的知识点,通过回顾和补充也可以更加系统的学习MySQL,以便在工作中更加游刃有余。前几节已初步性的进行简单整理,本次文章主要整理一些关于对数据库JOIN使用的知识。
MySQL中使用JOIN小结
在实际生产中,关于 join 语句使用的问题,一般会集中在以下两类:
-
我们 DBA 不让使用 join,使用 join 有什么问题呢?
-
如果有两个大小不同的表做 join,应该用哪个表做驱动表呢?
首先,我们应该先了解 join 语句到底是怎么执行的,然后再来解答上面这两个问题。
为了便于量化分析,我还是使用前面的表
my_user、my_order来分析说明。-- my_user表 CREATE TABLE `my_user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(20) NOT NULL DEFAULT '' COMMENT '名字', `sex` enum('0','1') NOT NULL COMMENT '性别', `tag_ids` varchar(255) NOT NULL COMMENT '标签', `score` decimal(5,2) NOT NULL DEFAULT '0.00' COMMENT '分数', `class_rome` tinyint(2) NOT NULL DEFAULT '0' COMMENT '班级号', PRIMARY KEY (`id`), KEY `score` (`score`) USING BTREE COMMENT '分数索引', KEY `class_rome` (`class_rome`) USING BTREE COMMENT '班级索引' ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- my_order表 CREATE TABLE `my_order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `oid` varchar(20) NOT NULL, `uid` int(11) NOT NULL, `price` decimal(6,2) NOT NULL DEFAULT '0.00', `uid2` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) USING BTREE, KEY `uid` (`uid`) USING BTREE, KEY `oid` (`oid`) USING BTREE, KEY `un_key` (`uid`,`price`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- 通过存储过程向my_order表插入100w测试数据 CREATE DEFINER=`root`@`localhost` PROCEDURE `test_loop`( ) BEGIN DECLARE i INT DEFAULT 1; WHILE i <= 1000000 DO INSERT INTO my_order ( oid, uid ,price) VALUES ( CONCAT( 'o_', DATE_FORMAT( now( ), '%Y%m%d%h%i%s' ), FLOOR(1000 + RAND( )*(9999-1000) )), FLOOR( 1 + RAND( ) * 10 ), 10 + RAND( ) * 99 ); SET i = i + 1; END WHILE; END通过上面可以看到,这两个表都有一个主键索引 id,my_order 表有一个uid 索引和my_user id 进行关联。
my_user表 测试数据:
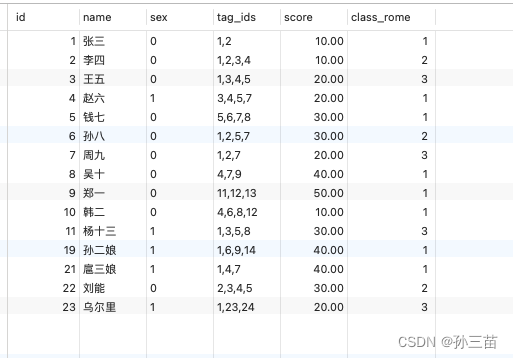
my_order表 的uid范围为 1-10;Index Nested-Loop Join
我们先来看下这个语句:
SELECT * FROM my_user STRAIGHT_JOIN my_order ON my_user.id = my_order.uid;如果直接使用 join 语句,MySQL 优化器可能会选择表 my_user 或 my_order 作为驱动表,这样会影响我们分析 SQL 语句的执行过程。所以,为了便于分析执行过程中的性能问题,改用 straight_join 让 MySQL 使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去 join。在这个语句里,my_user 是驱动表,my_order 是被驱动表。
现在,我们来看一下这条语句的 explain 结果:

在这条语句里,被驱动表 my_order 的字段 uid 上有索引,join 过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表 my_user 中读入一行数据 R;
- 从数据行 R 中,取出 id 字段到表 my_order 里去查找;
- 取出表 my_order 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 my_user 的末尾循环结束。
这个过程是先遍历表 my_user,然后根据从表 my_user 中取出的每行数据中的 id 值,去表 my_order 中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“
Index Nested-Loop Join”,简称NLJ。在上面这个过程里:
- 对驱动表 my_user 做了全表扫描,这个过程需要扫描 15 行;
- 而对于每一行 R,根据 id 字段去表 my_order 查找,走的是树搜索过程。由于我的测试数据是一对多的,每次的搜索过程都不只扫描一行,但总共扫描 1000000 行;
所以,整个执行流程,总扫描行数是 1000015。
假设我们不使用 join,那就只能用单表查询。我们看看上面这条语句的需求,用单表查询怎么实现。
执行select * from my_user,查出表 my_user 的所有数据,这里有 15 行;
循环遍历这 15 行数据:
从每一行 R 取出字段 id 的值 $R.id;
执行
select * from my_order where uid=$R.id;把返回的结果和 R 构成结果集的一行。
可以看到,在这个查询过程,也是扫描了 1000015 行,但是总共执行了 16 条语句,比直接 join 多了 15 次交互。除此之外,客户端还要自己拼接 SQL 语句和结果。
显然,这么做还不如直接 join 好。
在这个 join 语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
假设被驱动表的行数是 M。每次在被驱动表查一行数据,要先搜索索引 uid,再搜索主键索引。每次搜索一棵树近似复杂度是以 2 为底的 M 的对数,记为 log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是
N + N*2*log2M。显然,N 对扫描行数的影响更大,因此应该让小表来做驱动表。
通过上面的分析,我们得到了两个结论:
- 使用 join 语句,性能比强行拆成多个单表执行 SQL 语句的性能要好;
- 如果使用 join 语句的话,需要让小表做驱动表。
但是,我们需要注意的是,这个结论的前提是“
可以使用被驱动表的索引”。接下来,我们再看看被驱动表用不上索引的情况。
Simple Nested-Loop Join
先在
my_order上新加一个字段`uid2,所存数据和uid一样。ALTER TABLE `test`.`my_order` ADD COLUMN `uid2` int(11) NOT NULL DEFAULT 0 AFTER `price`; UPDATE my_order SET uid2 = uid;然后我们把SQL改成这样:
SELECT * FROM my_user STRAIGHT_JOIN my_order ON my_user.id = my_order.uid2;由于表
my_order的字段 uid2 上没有索引,因此再用上面提到的执行流程时,每次到 my_order 去匹配的时候,就要做一次全表扫描。你可以先设想一下这个问题,继续使用上面的算法,是不是可以得到正确的结果呢?如果只看结果的话,这个算法是正确的,而且这个算法也有一个名字,叫做“
Simple Nested-Loop Join”。但是,这样算来,这个 SQL 请求就要扫描表 my_order 多达 15 次,总共扫描 15*1000000=1500 万行。
这还只是一个大表,这个算法看上去太“笨重”了。
当然,MySQL 也没有使用这个
Simple Nested-Loop Join算法,而是使用了另一个叫作“Block Nested-Loop Join”的算法,简称BNL。Block Nested-Loop Join
这时候,被驱动表上没有可用的索引,算法的流程是这样的:
- 把表 my_user 的数据读入线程内存 join_buffer 中,由于我们语句中写的是
select *,因此是把整个表 my_user 放入了内存; - 扫描表 my_order,把表 my_order 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
这条 SQL 语句的 explain 结果如下:

可以看到,在这个过程中,对表 my_user 和 my_order 都做了一次全表扫描,因此总的扫描行数是 1000015。由于 join_buffer 是以无序数组的方式组织的,因此对表 my_order 中的每一行,都要做 15 次判断,总共需要在内存中做的判断次数是:15*1000000=1500 万次。
前面我们说过,如果使用
Simple Nested-Loop Join算法进行查询,扫描行数也是 1500 万行。因此,从时间复杂度上来说,这两个算法是一样的。但是,Block Nested-Loop Join 算法的这 10 万次判断是内存操作,速度上会快很多,性能也更好。接下来看一下,在这种情况下,应该选择哪个表做驱动表。
假设小表的行数是 N,大表的行数是 M,那么在这个算法里:
- 两个表都做一次全表扫描,所以总的扫描行数是 M+N;
- 内存中的判断次数是 M*N。
可以看到,调换这两个算式中的 M 和 N 没差别,因此这时候选择大表还是小表做驱动表,执行耗时是一样的。
然后,你可能马上就会问了,这个例子里表 my_user 才 15 行,要是表 my_user 是一个大表,join_buffer 放不下怎么办呢?
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 my_user 的所有数据话,策略很简单,就是分段放。我把 join_buffer_size 改成 1000,再执行:
SELECT * FROM my_user STRAIGHT_JOIN my_order ON my_user.id = my_order.uid2;执行过程:
- 扫描表 my_user,顺序读取数据行放入 join_buffer 中,放完第 10 行 join_buffer 满了,继续第 2 步;
- 扫描表 my_order,把 my_order 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join条件的,作为结果集的一部分返回;
- 清空 join_buffer;
- 继续扫描表 my_user,顺序读取最后的 5 行数据放入 join_buffer 中,继续执行第 2 步。
这个流程才体现出了这个算法名字中“Block”的由来,表示“分块去 join”。
可以看到,这时候由于表 my_user 被分成了两次放入 join_buffer 中,导致表 my_order 会被扫描两次。虽然分成两次放入 join_buffer,但是判断等值条件的次数还是不变的,依然是 (10+5)*1000000=1500 万次。
我们再来看下,在这种情况下驱动表的选择问题。
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。
注意,这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。
所以,在这个算法的执行过程中:
- 扫描行数是 N+λNM;
- 内存判断 N*M 次。
显然,内存判断次数是不受选择哪个表作为驱动表影响的。而考虑到扫描行数,在 M 和 N 大小确定的情况下,N 小一些,整个算式的结果会更小。
所以结论是,应该让小表当驱动表。
当然,在 N+λNM 这个式子里,λ才是影响扫描行数的关键因素,这个值越小越好。
刚刚我们说了 N 越大,分段数 K 越大。那么,N 固定的时候,什么参数会影响 K 的大小呢?(也就是λ的大小)答案是 join_buffer_size。join_buffer_size 越大,一次可以放入的行越多,分成的段数也就越少,对被驱动表的全表扫描次数就越少。
这就是为什么,你可能会看到一些建议告诉你,如果你的 join 语句很慢,就把 join_buffer_size 改大。
理解了 MySQL 执行 join 的两种算法,现在我们再来试着回答文章开头的两个问题。
- 第一个问题:能不能使用 join 语句?
如果可以使用 Index Nested-Loop Join 算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
如果使用 Block Nested-Loop Join 算法,扫描行数就会过多。尤其是在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。
所以你在判断要不要使用 join 语句时,就是看 explain 结果里面,Extra 字段里面有没有出现“Block Nested Loop”字样。
- 第二个问题是:如果要使用 join,应该选择大表做驱动表还是选择小表做驱动表?
如果是 Index Nested-Loop Join 算法,应该选择小表做驱动表;
如果是 Block Nested-Loop Join 算法:
在 join_buffer_size 足够大的时候,是一样的;
在 join_buffer_size 不够大的时候(这种情况更常见),应该选择小表做驱动表。
所以,这个问题的结论就是,总是应该使用小表做驱动表。当然,这里也会说明下,什么叫作“小表”。
我们前面的例子是没有加条件的。如果我在语句的 where 条件加上 my_order.id<=5 这个限定条件,再来看下这两条语句:
SELECT * FROM my_user STRAIGHT_JOIN my_order ON my_user.id = my_order.uid2 WHERE my_order.id <= 5; SELECT * FROM my_order STRAIGHT_JOIN my_user ON my_user.id = my_order.uid2 WHERE my_order.id <= 5;注意,为了让两条语句的被驱动表都用不上索引,所以 join 字段都使用了没有索引的字段 uid2。
但如果是用第二个语句的话,join_buffer 只需要放入 my_order 的前 5 行,显然是更好的。所以这里,“my_order 的前 5 行”是那个相对小的表,也就是“小表”。
我们再来看另外一组例子:
SELECT my_user.id,my_order.* FROM my_user STRAIGHT_JOIN my_order ON my_user.id = my_order.uid2 WHERE my_order.id <= 15; SELECT my_user.id,my_order.* FROM my_order STRAIGHT_JOIN my_user ON my_user.id = my_order.uid2 WHERE my_order.id <= 15;这个例子里,表 my_user 和 my_order 都是只有 15 行参加 join。但是,这两条语句每次查询放入 join_buffer 中的数据是不一样的:
表 my_user 只查字段 id,因此如果把 my_user 放到 join_buffer 中,则 join_buffer 中只需要放入 id 的值;
表 my_order 需要查所有的字段,因此如果把表 my_order 放到 join_buffer 中的话,就需要放入五个字段 id、oid、uid、price 和 uid2。
这里,我们应该选择表 my_user 作为驱动表。也就是说在这个例子里,“只需要一列参与 join 的表 my_user”是那个相对小的表。所以,更准确地说,在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
END
如有问题请在下方留言。
或关注我的公众号“孙三苗”,输入“联系方式”。获得进一步帮助。
-
-
相关阅读:
PHY强制模式下的协商能力
YOLOV8部署Android Studio安卓平台NCNN
虚幻引擎:代理
uniapp使用技巧及例子
“比特币技术与链上分析:解析市场机会,掌握暴利投资策略!“
GB/T 10707 橡胶燃烧性能
使用C#窗体绘制动态曲线图
闭包学习记录-iOS开发
从《职业分类大典》看人才需求,优秀的程序员应该具备哪些能力?
11.22二叉树相关OJ
- 原文地址:https://blog.csdn.net/u010377516/article/details/127085131