-
基于强化学习的机组组合问题求解方法研究
目 录
第 1 章 引言 1
1.1研究背景 1
1.2研究现状 1
1.3研究意义 2
1.4研究目标与主要工作 3
1.4.1研究目标 3
1.4.2主要工作 3
第 2 章 机组组合的马尔可夫决策过程建模 5
2.1概述 5
2.2主要符号对照表 5
2.3直流潮流模型 6
2.4考虑安全约束的电力系统机组组合优化模型 7
2.4.1决策变量 7
2.4.2目标函数 8
2.4.3约束条件 8
2.5考虑安全约束的电力系统 MDP 建模 9
2.5.1状态空间 10
2.5.2动作空间 12
2.5.3转换概率 12
2.5.4 奖励 13
2.6本章小结 13
第 3 章 机组组合模仿学习 14
3.1 概述 14
3.2主要符号对照表 14
3.3模仿学习 14
3.4网络设计 16
3.4.1问题结构 16
3.4.2智能体网络 17
3.5算例分析 19
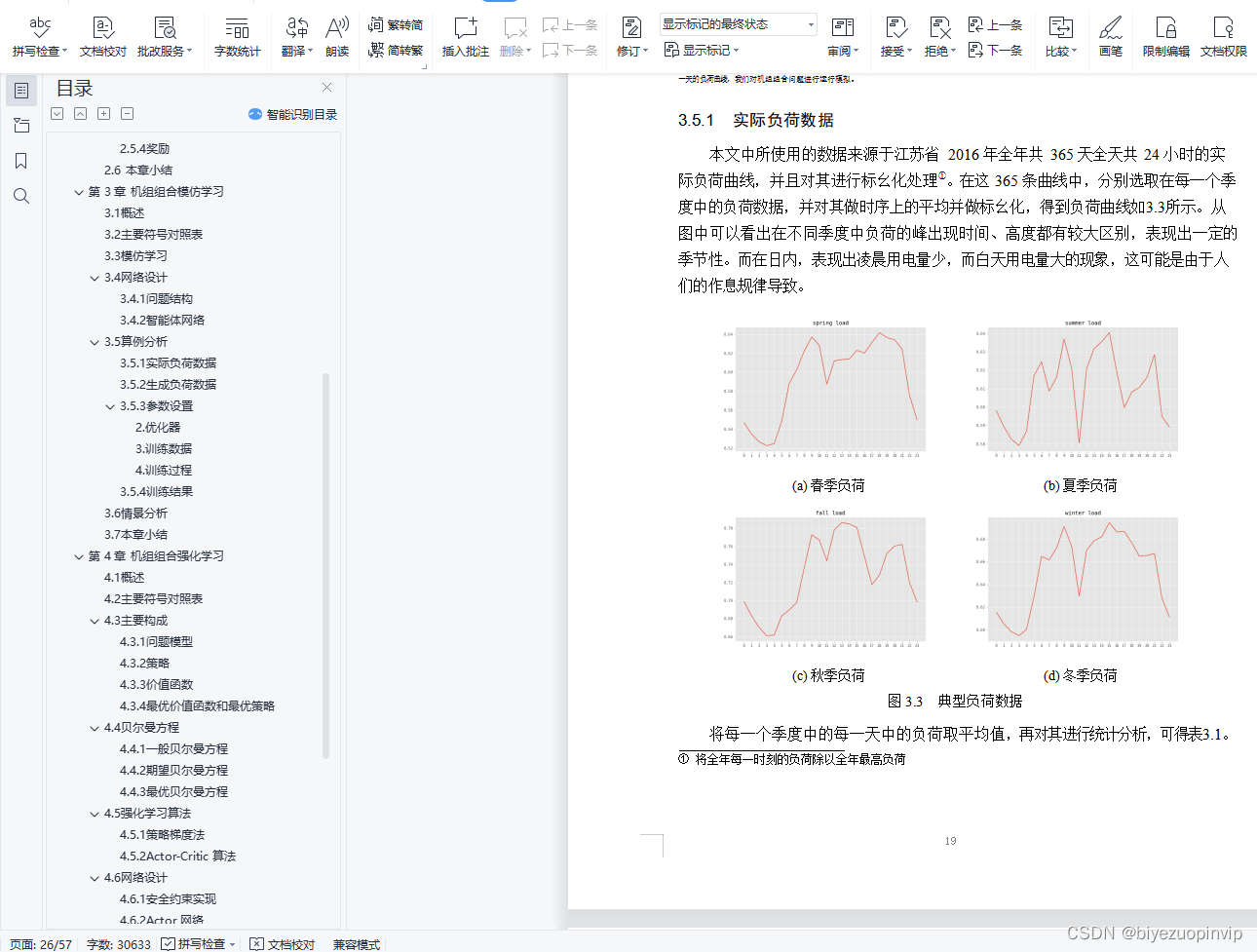
3.5.1实际负荷数据 19
3.5.2生成负荷数据 20
3.5.3参数设置 20
3.5.4训练结果 21
3.6情景分析 22
3.7本章小结 23
第 4 章 机组组合强化学习 24
4.1 概述 24
4.2主要符号对照表 24
4.3主要构成 25
4.3.1 问题模型 25
4.3.2 策略 26
4.3.3价值函数 26
4.3.4最优价值函数和最优策略 27
4.4贝尔曼方程 27
4.4.1一般贝尔曼方程 27
4.4.2期望贝尔曼方程 28
4.4.3最优贝尔曼方程 28
4.5强化学习算法 28
4.5.1策略梯度法 29
4.5.2ActorCritic 算法 29
4.6网络设计 31
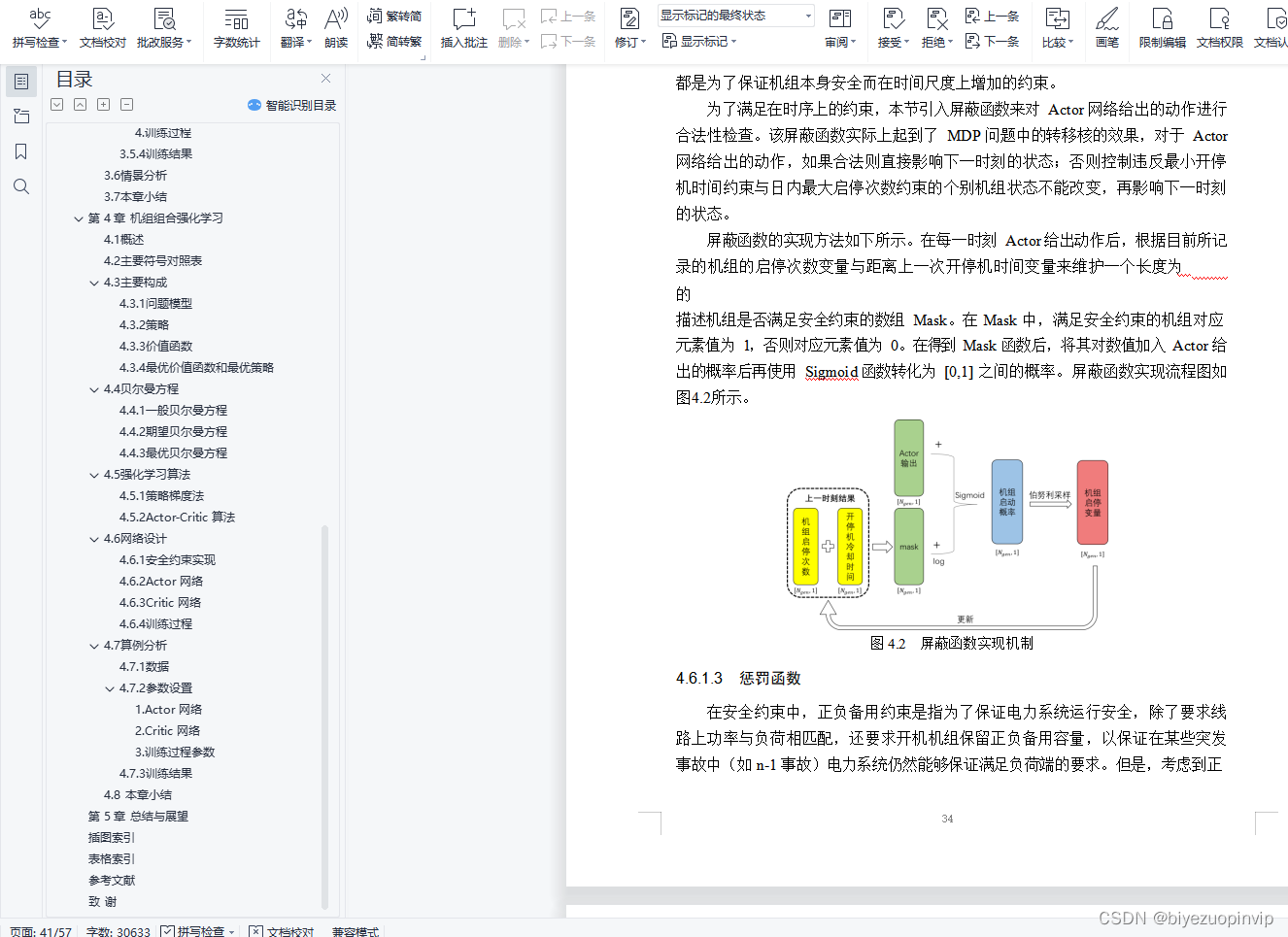
4.6.1安全约束实现 31
4.6.2Actor 网络 33
4.6.3Critic 网络 34
4.6.4训练过程 35
4.7算例分析 35
4.7.1 数据 35
4.7.2参数设置 36
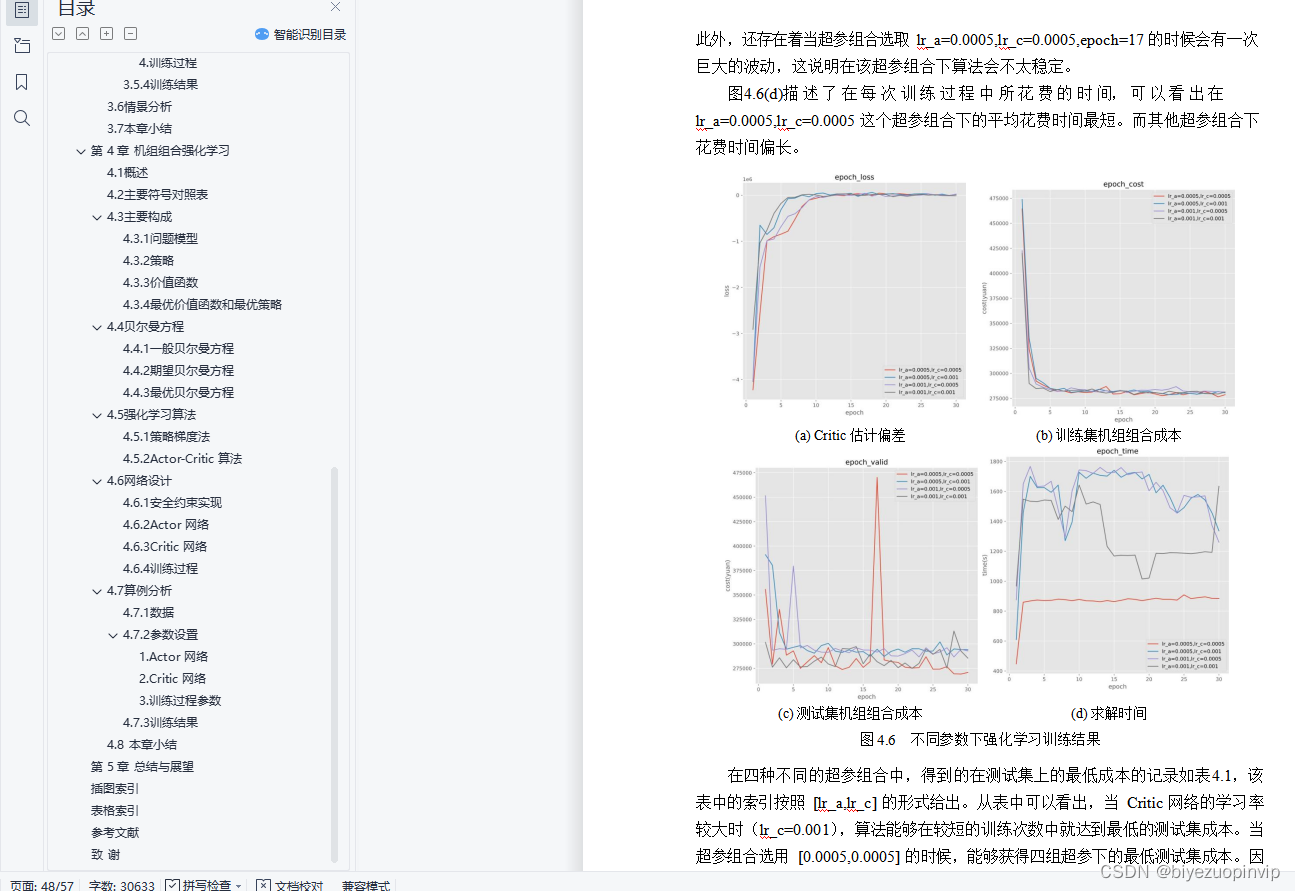
4.7.3训练结果 37
4.8本章小结 39
第 5 章 总结与展望 40
插图索引 42
表格索引 43
参考文献 44
致 谢 471.3研究意义
目前为止,对机组组合问题使用基于数据驱动的人工智能方法的研究还比较少。而随着数据科学的快速方法,使用大数据与数据分析的方法对问题进行研究已经成为十分重要的研究方法。本文基于对机组组合问题的优化问题建模与 MDP 建模,设计并训练得到机组组合问题的决策模型。借由此模型,经过前期训练后便可快速求解新的机组组合问题,从而适应电力市场背景下的快速出清、快速计算的要求。
本文主要的研究意义如下:
(1)完成对机组组合问题的马尔可夫决策过程(MDP)建模。MDP 是强化学习中的基础,所有的强化学习方法都是基于 MDP 的。本文中将从机组组合问题中提取出包含状态空间、动作空间、转移函数以及奖励函数的四元元组,使用 MDP 描述了机组组合的全过程,并且保证了电力系统安全约束能够得到满足。基于该 MDP,可以使用多种不同的强化学习方法对该问题进行求解。
(2)通过强化学习的方法,使用 ActorCritic 网络给出了机组组合的策略模型和价值函数,从而提升了机组组合问题的求解速度。基于对机组组合问题的优化问题建模与 MDP 建模,本文通过模仿学习和强化学习的方法给出了一个能够求解序贯决策的机组组合问题的算法模型。该算法模型能够在短时间内给出决策结果,从而提升机组组合问题求解的效率。1.4研究目标与主要工作
1.4.1研究目标
本文主要对机组组合问题在全天二十四小时内的调度计划进行求解。本文的研究目标分为以下两点。
1.对机组组合问题进行建模,分别建模为 MILP 问题和 MDP 过程,使之可以分别使用优化算法和强化学习算法进行求解。
2.使用强化学习方法求解机组组合问题的 MDP 问题,在保证电力系统安全约束满足的前提下给出高效的机组组合求解模型。
强化学习是机器学习中的一个分支,其通过智能体与环境的交互过程使得智能体能够在该交互过程中逐步学习环境的特性,最终实现理解环境动态的效果。通过引入强化学习,可以充分利用曾经解过的机组组合问题的经验,本文转载自http://www.biyezuopin.vip/onews.asp?id=14880使得在面对新问题的时候能够实现快速求解。而强化学习的第一步是将机组组合问题建模为马尔可夫决策过程(Markov Decision Process,简称为 MDP)。
综上所述,对机组组合问题的建模有混合整数先行优化建模以及 MDP 建模两种方法,本章分别采用两种模型进行建模。import warnings import numpy as np import torch import os from torch.utils.data import Dataset import pandas as pd import pandapower as pp import pandapower.networks as pn import time # device = torch.device('cpu') device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # * define net net = pn.case24_ieee_rts() num_unit = len(net.poly_cost) # * define hyperparameters changeTimesLimit = 4 stillLimit = 2 RESERVE = .05 RAMPING_LIMIT = .4 RESERVE_PENALTY = 50000 FOWARD_REWARD = 200000 def get_data(name, power=False): # can directly get the answer if power == False: if name in net['poly_cost'].columns: return net['poly_cost'][name] else: ans = [] for i in range(len(net['poly_cost'])): try: point = net['poly_cost'].iloc[i] et, element = point['et'], point['element'] ans.append(net[et][name][element]) except: ans.append(0) # r1aise warnings.warn('Something went wrong when retrieving %s data. ' % (name) + # 'Check poly_cost %d for more details' % (i)) return torch.tensor(ans, device=device) else: ans = [] for i in range(len(net['poly_cost'])): try: point = net['poly_cost'].iloc[i] et, element = point['et'], point['element'] ans.append(net['res_'+et]['p_mw'][element]) except: ans.append(0) return torch.tensor(ans, device=device) def save_data(name, data): for i in range(len(net['poly_cost'])): try: point = net.poly_cost.iloc[i] et, element = point.et, int(point.element) net[et][name][element] = data[i].item() except: raise Exception('Something went wrong when saving %s data. ' % (name) + 'Check poly_cost %d for more details' % (i)) # * define hyperparameters power_load_ratio = .9 load_multiplier = get_data('max_p_mw').sum().item()/power_load_ratio/net.load['p_mw'].sum() total_load = get_data('max_p_mw').sum().item()/power_load_ratio RAMPING = get_data('max_p_mw') * RAMPING_LIMIT INIT_MAX = get_data('max_p_mw') INIT_MIN = get_data('min_p_mw') # * define dataset class UCDataset(Dataset): def __init__(self, file_name, seed=None, num_ft_load=6, name=None): super(UCDataset, self).__init__() if name is None: raise Exception('Please specify a name for the dataset') self.num_ft_load = num_ft_load self.name = name # reading load curve data file data = pd.read_csv(file_name, index_col=0) data = data.div(data.max().max()) # exclude the unsucessful case by matlab if file_name == 'imitate_load_power.csv': available = sorted( list(map(lambda x: x.split('.')[0], os.listdir('data/onoff/')))) data = data.iloc[available] self.orig_index = data.index self.data = data.reset_index(drop=True) self.idx = self.data.index # num_samples represents the number of the total training data self.num_samples = num_samples = len(self.data) # set the random seed if seed is None: seed = np.random.randint(1, 1234) np.random.seed(seed) torch.manual_seed(seed) cross_section_shape = (num_unit,) # * generate static features self.num_static = 5 # ! require that all data in the sequence of poly_cost # define the power cost of each unit cost2 = get_data('cp2_eur_per_mw2') cost1 = get_data('cp1_eur_per_mw') cost0 = get_data('cp0_eur') # define the minimum on/off time limit before changing states of each unit minTimeLimit = torch.full(cross_section_shape, 2, dtype=torch.int) # define reserve rate of the unit reserveRate = torch.full(cross_section_shape, 1+RESERVE) # compose the above static data static = torch.tensor( np.stack([cost2, cost1, cost0, minTimeLimit, reserveRate]) ).expand(num_samples, -1, -1) self.static = static # * generate dynamic features self.num_dynamic = 3 + num_ft_load # define the states of the unit state = torch.ones(cross_section_shape) # define the realized on/off time time = torch.full(cross_section_shape, 12, dtype=torch.int) # define the last period power power = get_data('p_mw').cpu() # compose the above dynamic data dynamic = torch.tensor( np.stack([state, time, power]) ).expand(num_samples, -1, -1) # * define the load curve load = torch.tensor([self.data.iloc[:, k] for k in range( num_ft_load)]).expand(33, -1, -1).permute(2, 1, 0) dynamic = torch.cat([dynamic, load], dim=1) self.dynamic = dynamic def __len__(self) -> int: return len(self.data) def __getitem__(self, idx: int): return self.static[idx], self.dynamic[idx], self.idx[idx] def update_mask(self, dynamic, unit_state, nOchg): mask = torch.ones_like(unit_state) zero = torch.zeros_like(mask) # changing times limit mask = torch.where(nOchg >= changeTimesLimit, zero, mask) # still limit stillTime = torch.abs(dynamic[:, 1, :]) mask = torch.where(stillTime <= stillLimit, zero, mask) return mask def update_dynamic(self, dynamic, idx, unit_state, power, moment, nOchg): # dynamic [256,9,33] ## state, time, power, future_load num_ft_load = self.num_ft_load stateChg = torch.ne(unit_state, dynamic[:, 0, :]) nOchg = nOchg + stateChg # state dynamic[:, 0, :] = unit_state # time if moment == 0: ones = torch.ones_like(dynamic[:, 1, :]) dynamic[:, 1, :] = torch.where(unit_state == 1, ones, -ones) else: unchanged = dynamic[:, 1, :] + torch.sign(unit_state-0.5) changed = torch.sign(unit_state-0.5).double() dynamic[:, 1, :] = torch.where(stateChg, changed, unchanged) # power dynamic[:, 2, :] = power # future_load load_range = torch.clamp(torch.arange( moment+1, moment+num_ft_load+1), 0, 23) new_load = torch.tensor(self.data.iloc[idx, load_range].values).expand( 33, -1, -1).permute(1, 2, 0) dynamic[:, 3:, :] = new_load return dynamic, nOchg def reward(unit_state, last_power, load, last_success): # ramping limit and calculate penalty for reserve limit cost, true_cost, power, success = [], [], [], [] for case_idx in range(unit_state.shape[0]): if last_success[case_idx]==False: cost.append(0) true_cost.append(500000.) power.append(torch.zeros((33,),device=device)) success.append(False) continue max_power = last_power[case_idx] + RAMPING min_power = last_power[case_idx] - RAMPING max_power = np.array([x.item() if x < y else y.item() for x, y in zip(max_power, INIT_MAX)]) min_power = np.array([y.item() if x < y else x.item() for x, y in zip(min_power, INIT_MIN)]) penalty = 0 cond1=max_power[unit_state[case_idx].bool().cpu()].sum() < load[case_idx]*(1+RESERVE)*total_load cond2=min_power[unit_state[case_idx].bool().cpu()].sum() > load[case_idx]*(1-RESERVE)*total_load if cond1: penalty += RESERVE_PENALTY if cond2: penalty += RESERVE_PENALTY save_data('max_p_mw', max_power) save_data('min_p_mw', min_power) net.load['scaling'] = load[case_idx].item() * load_multiplier save_data('in_service',unit_state[case_idx].bool()) try: pp.rundcopp(net, delta=1e-16) cost.append(-net.res_cost - penalty + FOWARD_REWARD) true_cost.append(net.res_cost) power.append(get_data('p_mw', power=True)) success.append(True) except: cost.append(0) true_cost.append(500000.) # * how to deal with unsuccessful scenario power.append(torch.zeros((33,), device=device)) success.append(False) return torch.tensor(cost,dtype=float,device=device), torch.stack(power).to(device), torch.tensor(success,device=device), torch.tensor(true_cost,device=device)

-
相关阅读:
Real-Time Rendering——9.9.4 Rough-Surface Subsurface Models粗糙表面地下模型
微服务中「组件」集成
(二)库存计划-经济订货量(EOQ)
Prompt-Tuning源码分析
【数学建模】单、多因素试验的方差分析(Matlab代码实现)
Go 以小端字节序修改文件
nodejs+vue电影在线预定与管理系统的设计与实现-微信小程序-安卓-python-PHP-计算机毕业设计
动态渲染 echarts 饼图(vue 2 + axios + Springboot)
Java使用Redis实现分页功能
maven依赖管理
- 原文地址:https://blog.csdn.net/newlw/article/details/127046997