-
【LLM工程篇】deepspeed | Megatron-LM | fasttransformer
note
- 当前比较主流的一些分布式计算框架 DeepSpeed、Megatron 等,都在降低显存方面做了很多优化工作,比如:量化、模型切分、混合精度计算、Memory Offload 等
大模型参数计算
1. 模型参数单位
“10b”、“13b”、"70b"等术语通常指的是大型神经网络模型的参数数量。其中的 “b” 代表 “billion”,也就是十亿。表示模型中的参数量,每个参数用来存储模型的权重和偏差等信息。例如:
“10b” 意味着模型有大约 100 亿个参数。
“13b” 意味着模型有大约 130 亿个参数。
“70b” 意味着模型有大约 700 亿个参数。
例如:Meta 开发并公开发布的 Llama 2 系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参数规模从 70 亿(7b)到 700 亿(70b)不等。经过微调的LLMs(称为 Llama-2-Chat)针对对话场景进行了优化。meta-llama/Llama-2-7b-hf
meta-llama/Llama-2-13b-hf
meta-llama/Llama-2-70b-hf
输入:仅输入文本
输出:仅生成文本
模型架构:Llama 2 是一种使用优化的 Transformer 架构的自回归语言模型。调整后的版本使用监督微调(SFT)和带有人类反馈的强化学习(RLHF)来适应人类对有用性和安全性的偏好。2. 训练显存计算
1.模型权重
模型权重是模型参数中的一部分,通常是指神经网络中连接权重(weights)。这些权重决定了输入特征与网络层之间的连接强度,以及在前向传播过程中特征的传递方式。所以模型2.梯度
在训练过程中,计算梯度用于更新模型参数。梯度与模型参数的维度相同。
3.优化器参数
一些优化算法(如带有动量的优化器)需要保存一些状态信息,以便在每次更新时进行调整。这些状态信息也会占用一定的显存。比如:- 采用 AdamW 优化器:每个参数占用8个字节,需要维护两个状态。意味着优化器所使用的显存量是模型权重的 2 倍;
- 采用 经过 bitsandbytes 优化的 AdamW 优化器:每个参数占用2个字节,相当于权重的一半;
- 采用 SGD 优化器:占用显存和模型权重一样。
4.输入数据和标签
训练模型需要将输入数据和相应的标签加载到显存中。这些数据的大小取决于每个批次的样本数量以及每个样本的维度。5.中间计算
在前向传播和反向传播过程中,可能需要存储一些中间计算结果,例如激活函数的输出、损失值等。6.临时缓冲区
在计算过程中,可能需要一些临时缓冲区来存储临时数据,例如中间梯度计算结果等。减少中间变量也可以节省显存,这就体现出函数式编程语言的优势了。7.硬件和依赖库的开销
显卡或其他硬件设备以及使用的深度学习框架在进行计算时也会占用一些显存。【以 Llama-2-7b-hf 为例】
数据类型:Int8
模型参数: 7B * 1 bytes = 7GB
梯度:同上7GB
优化器参数: AdamW 2倍模型参数 7GB * 2 = 14GB
LLaMA的架构(hidden_size= 4096, intermediate_size=11008, num_hidden_lavers= 32, context.length = 2048),所以每个样本大小:(4096 + 11008) * 2048 * 32 * 1byte = 990MB
A100 (80GB RAM)大概可以在int8精度下BatchSize设置为50
综上总现存大小:7GB + 7GB + 14GB + 990M * 50 ~= 77GB
Llama-2-7b-hf模型Int8推理由上个章节可得出现存大小6.5GB, 由此可见,模型训练需要的显存是至少推理的十几倍。3. 推理显存计算
- 模型结构: 模型的结构包括层数、每层的神经元数量、卷积核大小等。较深的模型通常需要更多的显存,因为每一层都会产生中间计算结果。
- 输入数据: 推理时所需的显存与输入数据的尺寸有关。更大尺寸的输入数据会占用更多的显存。
- 批处理大小BatchSize: 批处理大小是指一次推理中处理的样本数量。较大的批处理大小可能会增加显存使用,因为需要同时存储多个样本的计算结果。
- 数据类型DType: 使用的数据类型(如单精度浮点数、半精度浮点数)也会影响显存需求。较低精度的数据类型通常会减少显存需求。
- 中间计算: 在模型的推理过程中,可能会产生一些中间计算结果,这些中间结果也会占用一定的显存。
大模型的分布式训练
【背景】假设神经网络中某一层是做矩阵乘法, 其中的输入 x x x 的形状为 4 × 5 4 \times 5 4×5, 模型参数 w w w 的形状为 5 × 8 5 \times 8 5×8, 那么, 矩阵乘法输出形状为 4 × 8 4 \times 8 4×8 。如下:
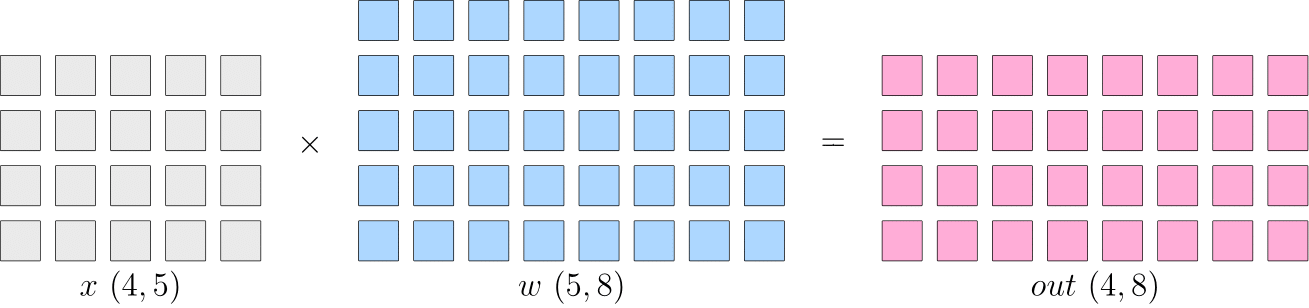
1. 数据并行
- 数据并行:切分数据
x
x
x到不同设备上,在反向传播过程中,需要对各个设备上的梯度进行 AllReduce,以确保各个设备上的模型始终保持一致。适合数据较大,模型较小的情况,如resnet50
- allReduce: 先将所有device上的模型的梯度reduce归约,然后将结果广播到所有设备上
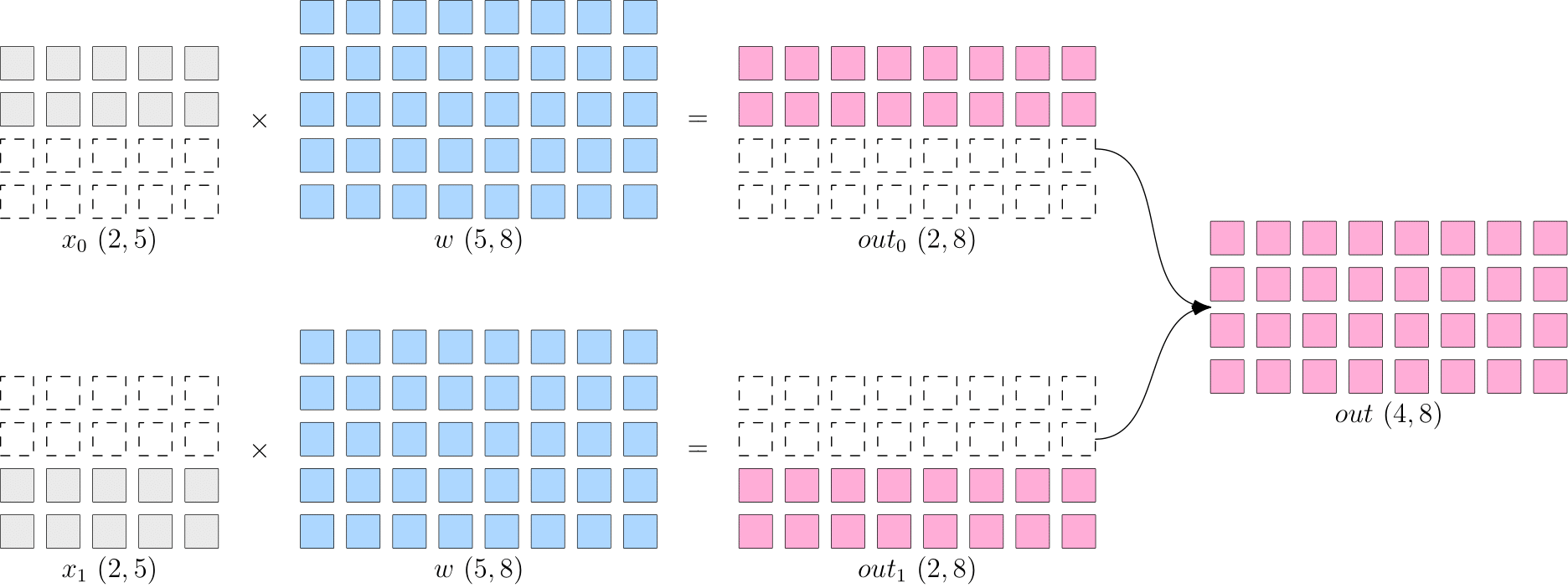
- allReduce: 先将所有device上的模型的梯度reduce归约,然后将结果广播到所有设备上
2. 模型并行
- 模型并行:省去了多个设备之间的梯度 AllReduce;但是, 由于每个设备都需要完整的数据输入,因此,数据会在多个设备之间进行广播,产生通信代价。比如,上图中的最终得到的 out
(
4
×
8
)
(4 \times 8)
(4×8) ,如果它作为下一层网络的输入,那么它就需要被广播发送到两个设备上。如bert
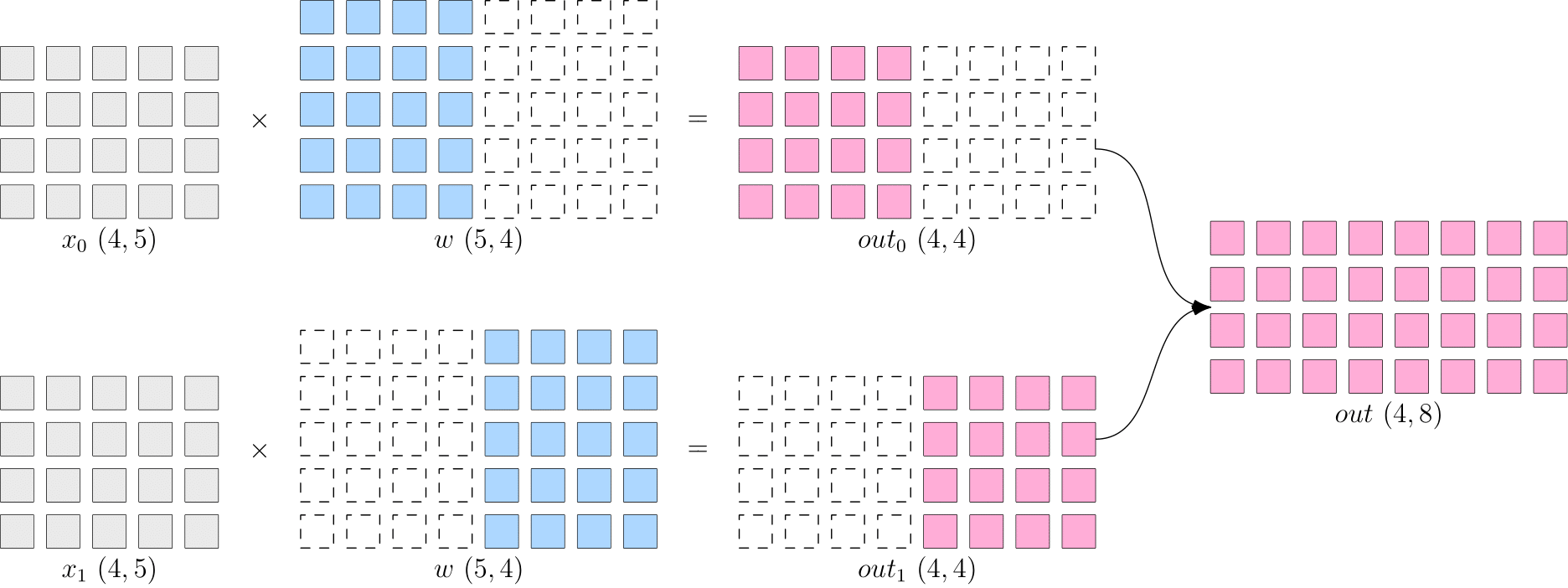
3. 流水并行
- 流水并行:模型网络过大,除了用模型并行,还能用流水并行(如下的网络有4层,T1-T4)
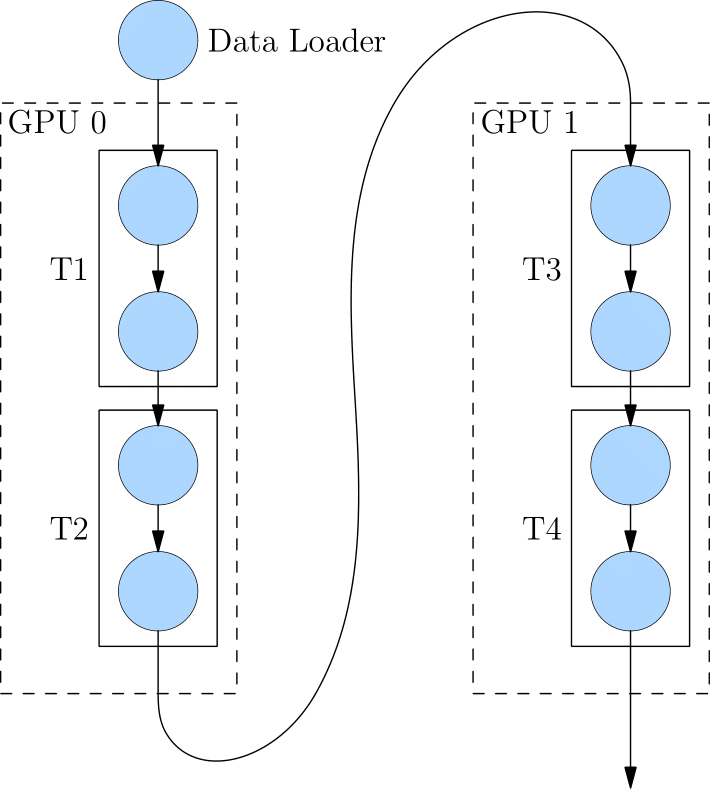
4. 混合并行
- 混合并行:综合上面的多种策略一起训练,如GPT3:
- 首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台 DGX-A100 主机上。
- 在6台主机之间,进行的是数据并行训练;
- 每台主机有 8 张 GPU 显卡,同一台机器上的8张 GPU 显卡之间是进行模型并行训练。
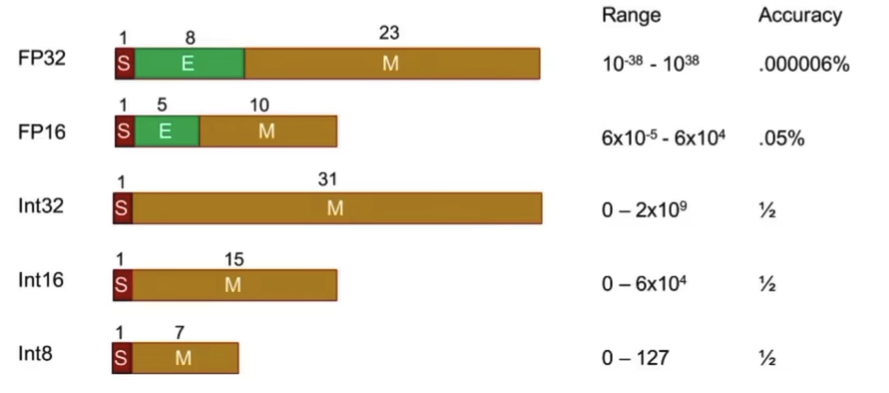
模型量化
W4/8A16量化方案,显著节省显存:存储时int4/8,计算时FP16
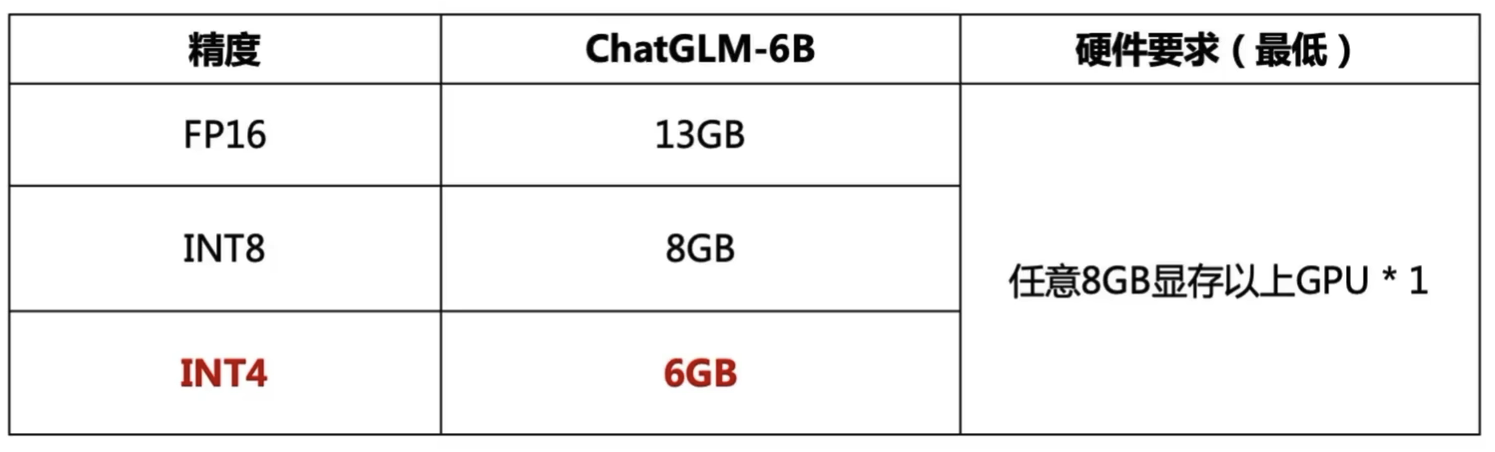
DeepSpeed ZeRO:零冗余优化
DP: Data Parallel
MP: Model Parallel
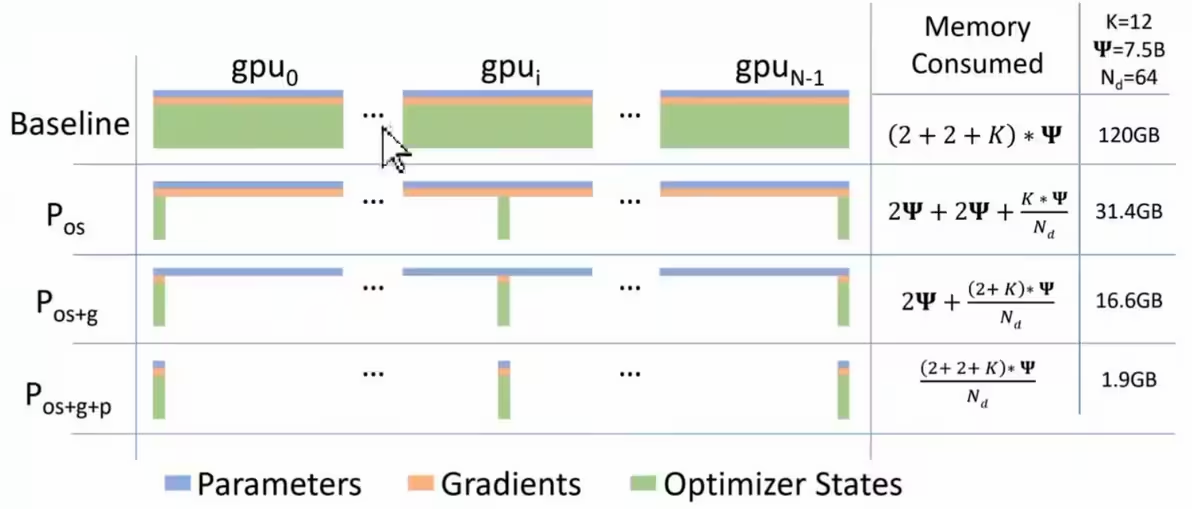
- deepspeed是微软大规模分布式训练框架,其中3D并行解决两大问题:显存效率+计算效率
- DeepSpeed+Zero可以实现全参数微调
- DeepSpeed ZeRO-2主要用于训练
deepspeed 的参数配置可参考:
- https://www.deepspeed.ai/docs/config-json/
- https://huggingface.co/docs/accelerate/usage_guides/deepspeed
- https://github.com/huggingface/transformers/blob/main/tests/deepspeed
DeepSpeed Chat
项目:https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat
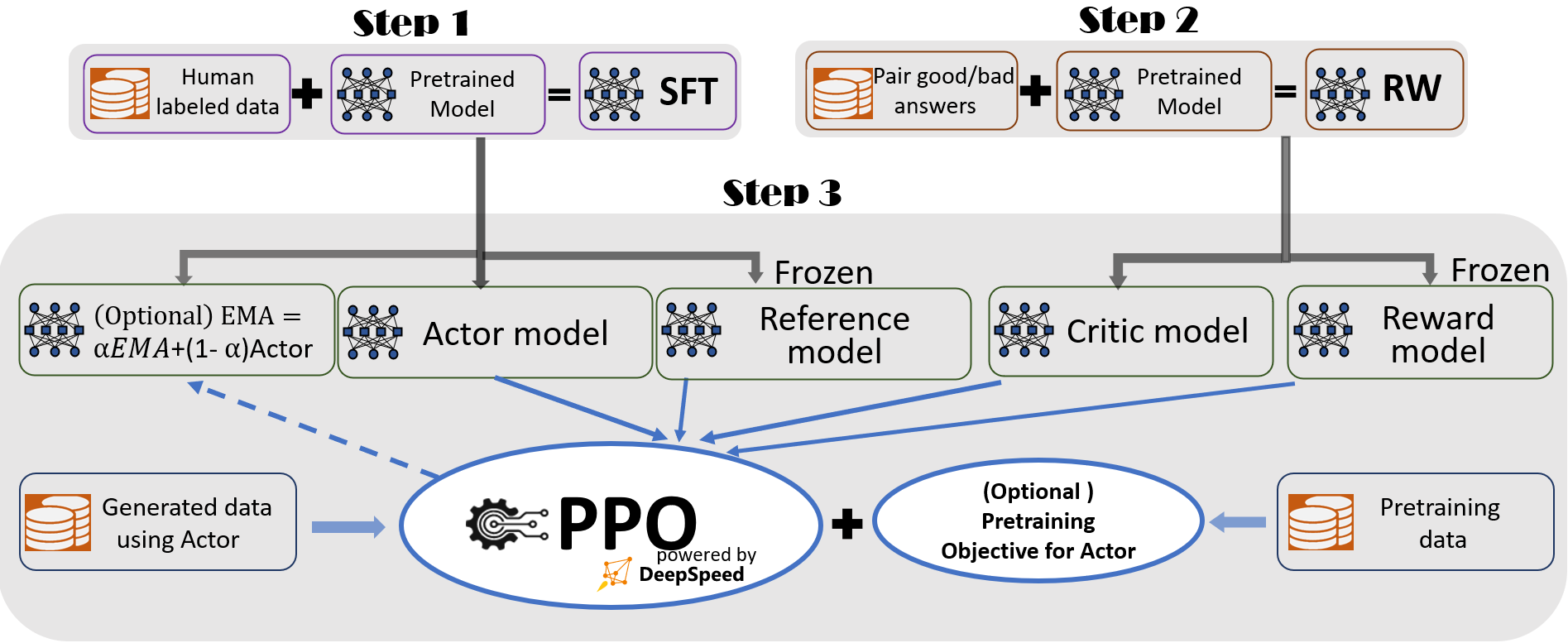
deepspeed最近推出的RLHF pipeline如下图,和之前很多LLM类似使用三部曲:sft、reward model、PPO,亮点是在第三步使用奖励模型对sft微调模型进行ppo时:
- 基于指数移动平均计算的checkpoint:Exponential Moving Average (EMA) collection, where an EMA based checkpoint can be chosen for the final evaluation.
- 混合训练(将pretrain和ppo混合训练):Mixture Training, which mixes the pretraining objective (i.e., the next word prediction) with the PPO objective to prevent regression performance on public benchmarks like SQuAD2.0.
fastertransformer:LLM推理加速引擎
项目链接:https://github.com/NVIDIA/FasterTransformer
将张量并行 (TP) 和流水线并行 (PP) 应用于transformer模型。
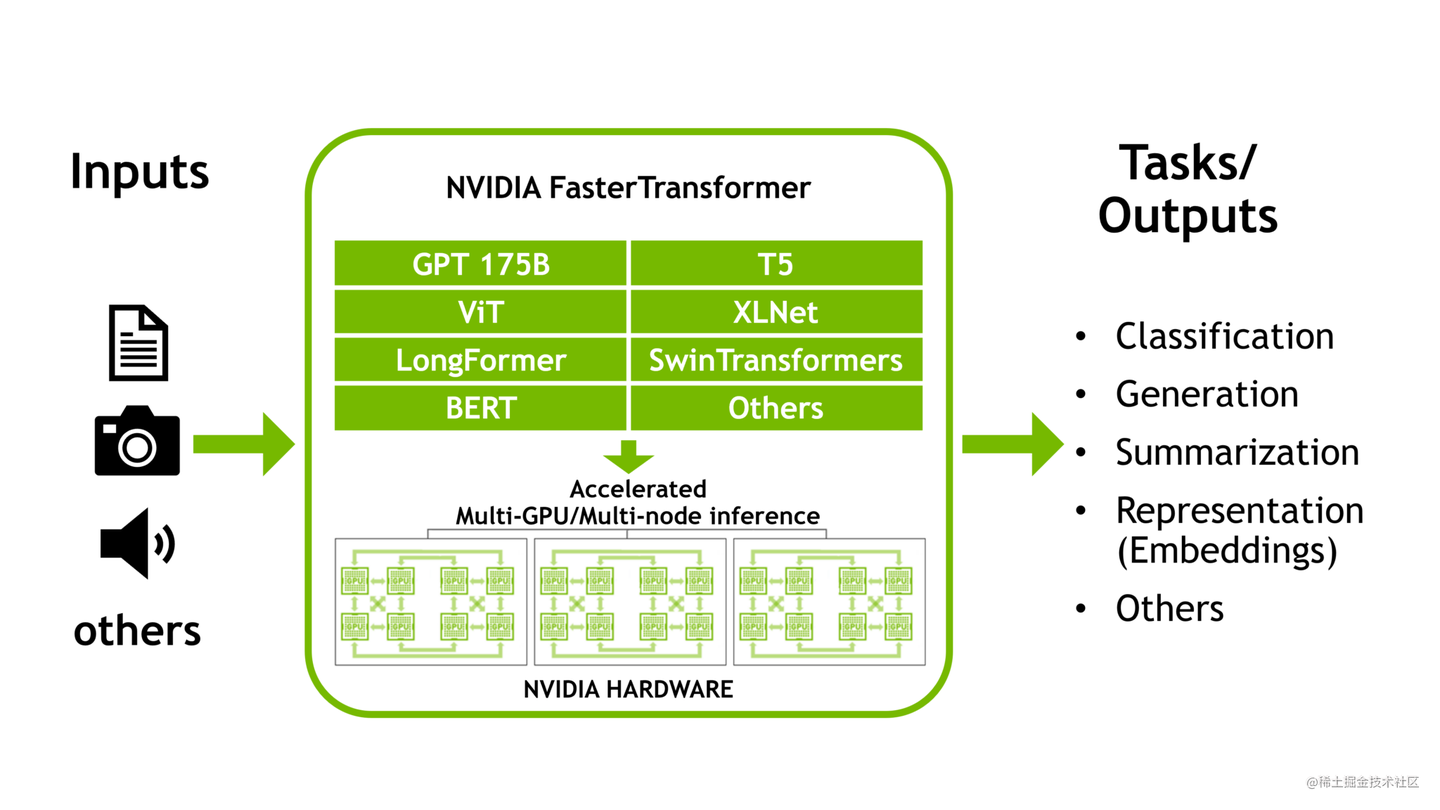
使用fastertransformer运行 GPT 模型的工作流程是:- 通过 MPI 或线程初始化 NCCL 通信并设置张量并行和流水线并行的ranks
- 按张量并行、流水线并行和其他模型超参数的ranks加载权重。
- 通过张量并行、流水线并行和其他模型超参数的ranks创建ParalelGpt实例。
- 接收来自客户端的请求并将请求转换为 ParallelGpt 的输入张量格式。
- 运行forward
- 将 ParallelGpt 的输出张量转换为客户端的响应并返回响应。
tgi加速推理:Text Generation Inference
tgi项目:https://github.com/huggingface/text-generation-inference
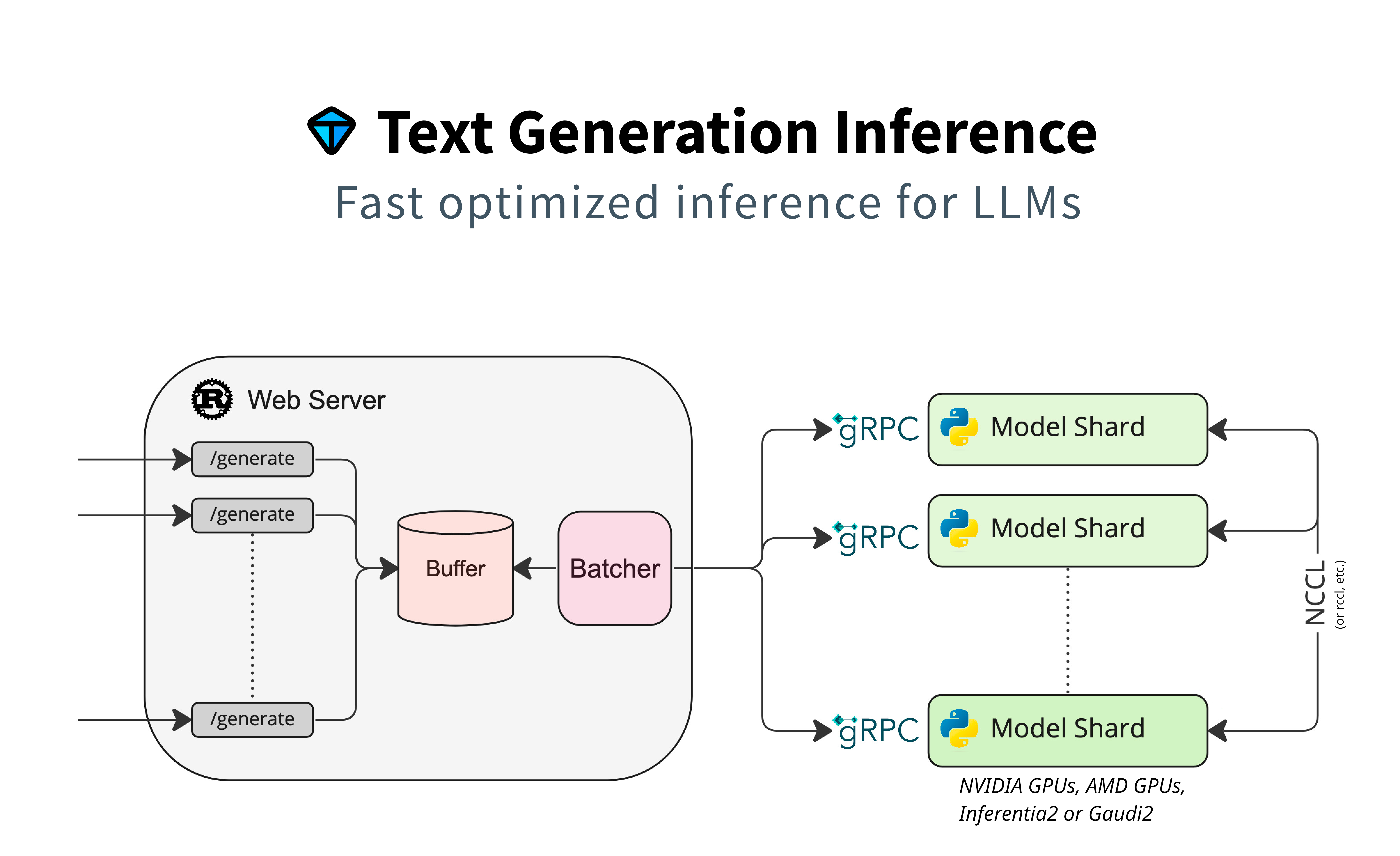
注:text-generation-inference 这个项目里Fused qkv 以及 Fused gate and up projs的好处:可以并行计算。
注:tgi不支持量化后的模型,但是Tensort-LLM(也是微软提出的)支持。Megatron-LM训练框架
项目:https://github.com/NVIDIA/Megatron-LM
论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using
Model Parallelism
论文链接:https://arxiv.org/pdf/1909.08053.pdfPS:codegeex就是采用的是8头TP,192头DP,共1536块GPU进行训练
采用的训练框架:Megatron + DeepSpeed ZeRO2。
项目:https://github.com/THUDM/CodeGeeX/tree/7365d9df242d87a5583d3f203e4b6c547dc6240e
codegeex paper: https://arxiv.org/abs/2303.17568
codegeex模型结构:

训练LLM需要的硬件
拿llama为例子:
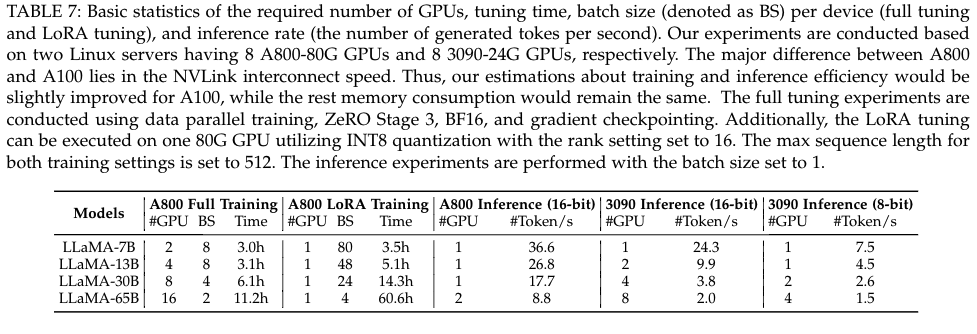
上表源自《A Survey of Large Language Models》大模型的ToB部署
目前企业应用大模型面临诸多难点:模型体积大,训练难度高;算力规模大,性能要求高;数据规模大,数据质量参差不齐。大模型产业化需要云计算厂商将模型开发、训练、调优、运营等复杂过程封装起来,通过低门槛、高效率的企业级服务平台深入产业,为千行百业提供服务。
【举例】(非guanggao)文心千帆大模型平台提供公有云服务、私有化部署两大交付模式。
- 在公有云服务方面,将提供:推理(直接调用大模型的推理能力)、微调(通过高质量精标业务数据,高效训练出特定行业的大模型)、托管(将模型发布在百度智能云,以实现更加稳定高效的运行)三种服务,大幅降低企业部署大模型的门槛。
- 在私有化部署方面,文心千帆大模型平台支持
- 软件授权(提供在企业环境中运行的大模型服务)、
- 软硬一体(提供整套大模型服务及对应的硬件基础设施),
- 租赁服务(提供机器和平台的租赁满足客户低频需求)三种方式。私有化部属能够满足对数据监管有严格要求的企业客户需求。
Reference
[1] 大语言模型(LLM)分布式训练框架总结
[2] 【论文阅读】Megatron-LM要点
[3] Megatron LM 论文精读【论文精读】.李沐论文解读.b站
[4] 详谈大模型训练和推理优化技术.华师王嘉宁
[5] Finding the cause of RuntimeError: Expected to mark a variable ready only once
[6] 百度工程师首次现场演示:“文心千帆”如何可视化微调大模型
[7] 开源大模型部署及推理所需显卡成本必读:也看大模型参数与显卡大小的大致映射策略
[8] 也看大模型训练中的显存占用分析及优化方法:解析问题思路与策略的一些总结
[9] 大模型的好伙伴,浅析推理加速引擎FasterTransformer
[10] [NLP]深入理解 Megatron-LM(详解并行策略)
[11] 图解大模型训练之:Megatron源码解读2,模型并行
[12] https://github.com/NVIDIA/FasterTransformer/blob/main/docs/gpt_guide.md
[13] 一步一步理解大模型:零冗余优化器技术
[14] 阿里云. Llama2-7B基于PAI-DSW的全参数微调训练,训练参数
[15] DeepSpeed结合Megatron-LM训练GPT2模型笔记
[16] 大模型时代,是 Infra 的春天还是冬天?昆仑万维 AI-Infra 负责人
[17] https://github.com/microsoft/DeepSpeed、
[18] LLM(十八):LLM 的推理优化技术纵览 -
相关阅读:
逆向分析:还原 App protobuf 协议加密
Idea克隆Gitee项目完整步骤(Mac)
(C++) this_thread 函数介绍
5--OpenCV:图形绘制与文字输出
uniapp自定义国际化语言uni.chooseImage、picker组件文本错误问题
vue2+element医院安全(不良)事件报告管理系统源代码
【遥控器开发基础教程1】疯壳·开源编队无人机-GPIO(遥控器指示灯控制)
Spring beans
14 SpringMVC执行流程
Spring Data Redis + RabbitMQ - 基于 string 实现缓存、计数功能(同步数据)
- 原文地址:https://blog.csdn.net/qq_35812205/article/details/131971176