-
mindspore如何处理网络训练过程中loss异常的问题
现象描述
在Ascend上单卡训练alexnet网络,使用的数据集为imagenet,开始的几个step出现loss为0的情况,又经过几个step之后,loss在一个值附近浮动,没有下降趋势。下面是训练时的log信息。
- epoch: 1 step: 1, loss is 175.412841796875
- epoch: 1 step: 2, loss is 8.265993118286133
- epoch: 1 step: 3, loss is 0.0
- epoch: 1 step: 4, loss is 0.0
- epoch: 1 step: 5, loss is 0.0
- epoch: 1 step: 6, loss is 986.4647827148438
- epoch: 1 step: 7, loss is 168.6614990234375
- epoch: 1 step: 8, loss is 17.382360458374023
- epoch: 1 step: 9, loss is 0.0
- epoch: 1 step: 10, loss is 0.0
- epoch: 1 step: 11, loss is 500.17535400390625
- epoch: 1 step: 12, loss is 117.48480224609375
- epoch: 1 step: 13, loss is 65.71255493164062
- epoch: 1 step: 14, loss is 22.631694793701172
- epoch: 1 step: 15, loss is 10.495172500610352
- epoch: 1 step: 16, loss is 8.155228614807129
- epoch: 1 step: 17, loss is 6.926827907562256
- epoch: 1 step: 18, loss is 6.922276973724365
- epoch: 1 step: 19, loss is 6.915751934051514
- ...
- epoch: 2 step: 1, loss is 7.522680282592773
- epoch: 2 step: 2, loss is 7.474167823791504
- epoch: 2 step: 3, loss is 7.39562463760376
- epoch: 2 step: 4, loss is 7.276236534118652
- epoch: 2 step: 5, loss is 7.129960060119629
- epoch: 2 step: 6, loss is 7.30611515045166
- epoch: 2 step: 7, loss is 7.276240825653076
- epoch: 2 step: 8, loss is 7.190131187438965
- epoch: 2 step: 9, loss is 7.061898231506348
- epoch: 2 step: 10, loss is 6.9132795333862305
- ...
原因分析
网络训练时loss不下降,可能的原因有很多。常见原因有超参问题、数据问题、算法问题等,或者多个原因共同导致。 1)超参问题:包括学习率设置不合理、loss_scale参数不合理、权重初始化参数不合理、epoch过大或过小、batch size过大等。 2)数据问题:数据质量不好或者数据预处理方式不好。 3)算法问题:包括API使用不当、计算图结构不合理、权重初始化不合理等。
解决办法
步骤1. 启动调试器
用MindInsight调试器可以结合计算图,查看图节点的输出结果。还可以设置监测点来监测训练异常情况。调试器有在线和离线两种模式。由于alexnet网络规模很小,这里使用在线调试器来分析。 1)首先,需要安装和MindSpore同一版本号的MindInsight; 2)然后,启动MindInsight, 注意启动时通过--enable-debugger为True来开启在线调试器,并通过--debugger-port来指定调试器端口,例如“mindinsight start --enable-debugger True --debugger-port 1234”。更多mindinsight的启动选项,请参考MindInsight相关命令。 启动之后,会看到终端显示启动的web address和启动状态,如果看到"service start state: success"说明启动成功了,这时在浏览器中打开web address中显示的地址,点击页面上方的
调试器标签,可以看到调试器处于等待训练连接的状态。 3)启动MindInsight以后,在训练脚本的窗口设置环境变量“export ENABLE_MS_DEBUGGER=1”,并设置调试器端口MS_DEBUGGER_PORT与启动MindInsight时相同,例如“export MS_DEBUGGER_PORT=1234”,还要设置MS_DEBUGGER_HOST与MindInsight host一致,例如“export MS_DEBUGGER_HOST=127.0.0.1”。 设置好环境变量以后,就可以启动训练脚本了。步骤2. 检查异常现象
- 启动训练脚本以后,等待片刻,从调试器页面可以看到接收到了计算图,并出现一个弹窗询问
是否检查常见异常现象?,我选的是使用。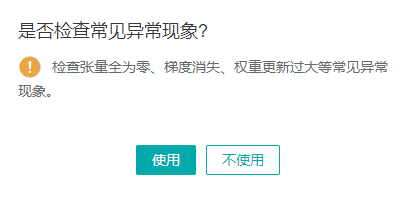
这时,会监测点列表看到一些常见异常现象监测点,包括检查权重初始值、检查权重变化过大、检查梯度消失、检查计算过程溢出、检查张量溢出、检查张量是否全为0等。然后点击页面左下方的
继续按钮,就会在执行脚本时检查异常现象。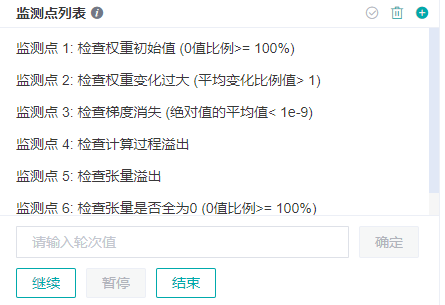
-
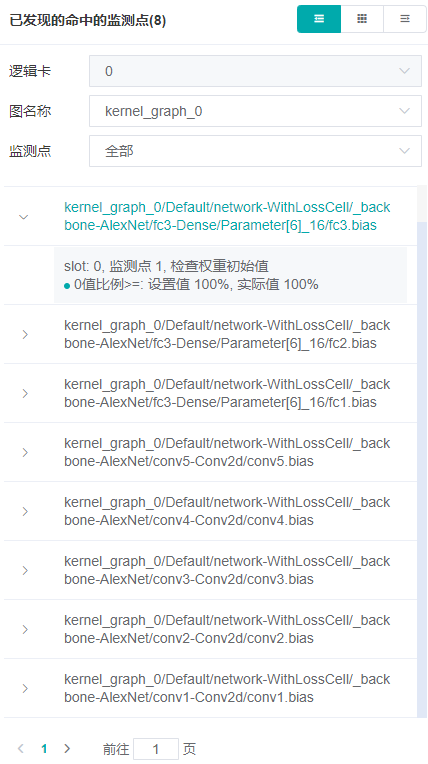
发现异常现象以后,页面会跳转到已发现的命中的监测点,如下图所示。点击列表中某一项最左边的
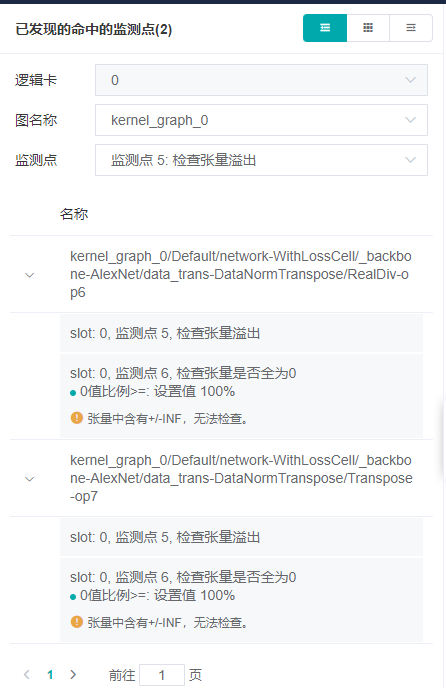
>符号,会显示该异常点的详细信息。这里发现了权重初始值全为0的异常,检查训练脚本中权重初始化的方式,发现并没有异常,暂且先不理会这个监测点。点击继续,直到命中一些别的监测点。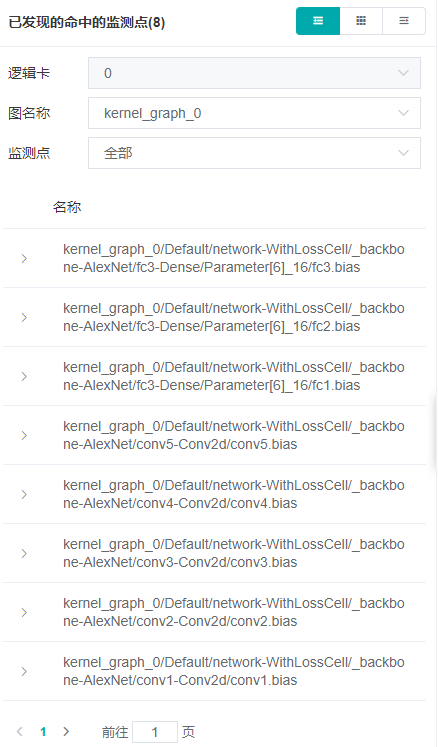
-
在已发现的命中的监测点列表中,可以有选择的查看监测点。在监测点的下拉列表中,选择一个监测点,就可以只显示选中监测点的命中情况。如下图是检查张量溢出的结果。可以看到有两个节点中出现了INF值。
点击已发现的命中监测点中的第一项RealDiv-op6节点。计算图就会定位到这个节点上,下面的张量信息展示了该节点的基本信息,包括节点的输入节点和它们的类型、形状、数值。点击数值栏中的
查看可以看到张量的具体数值。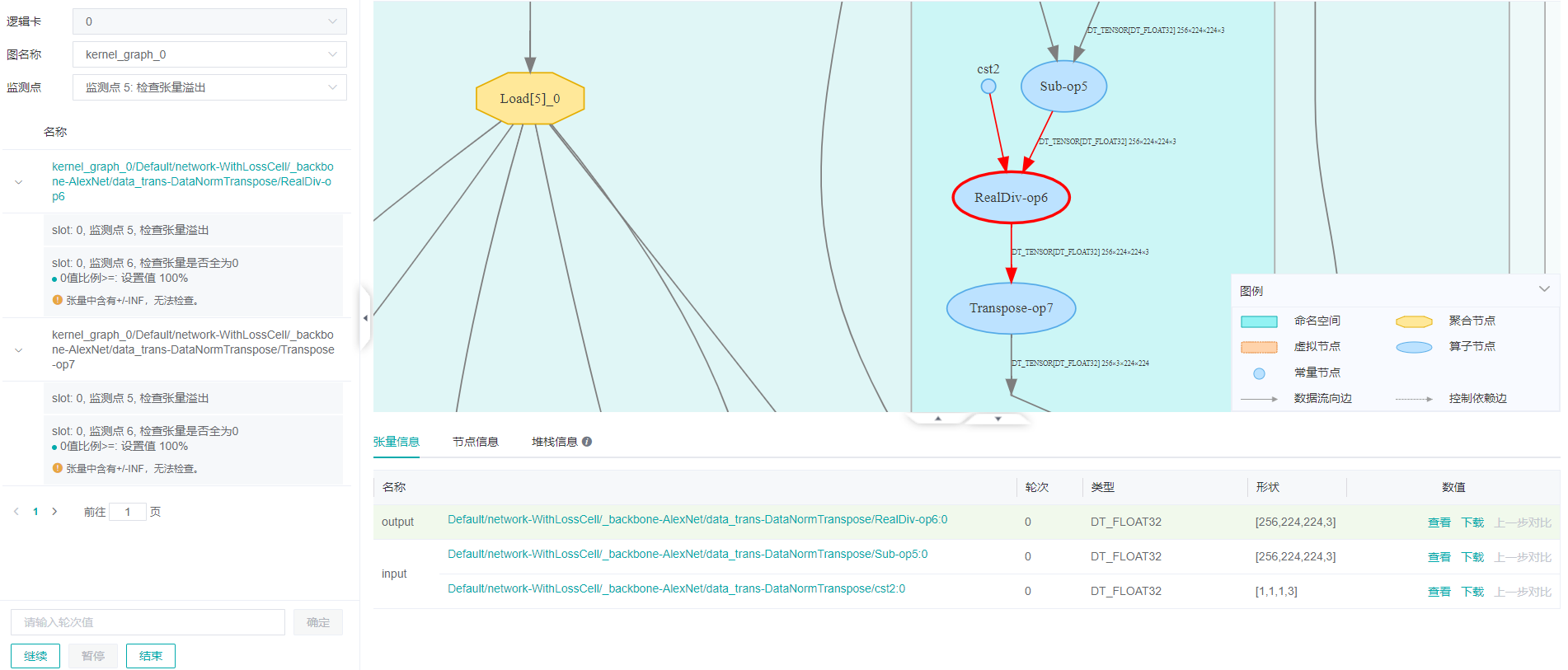
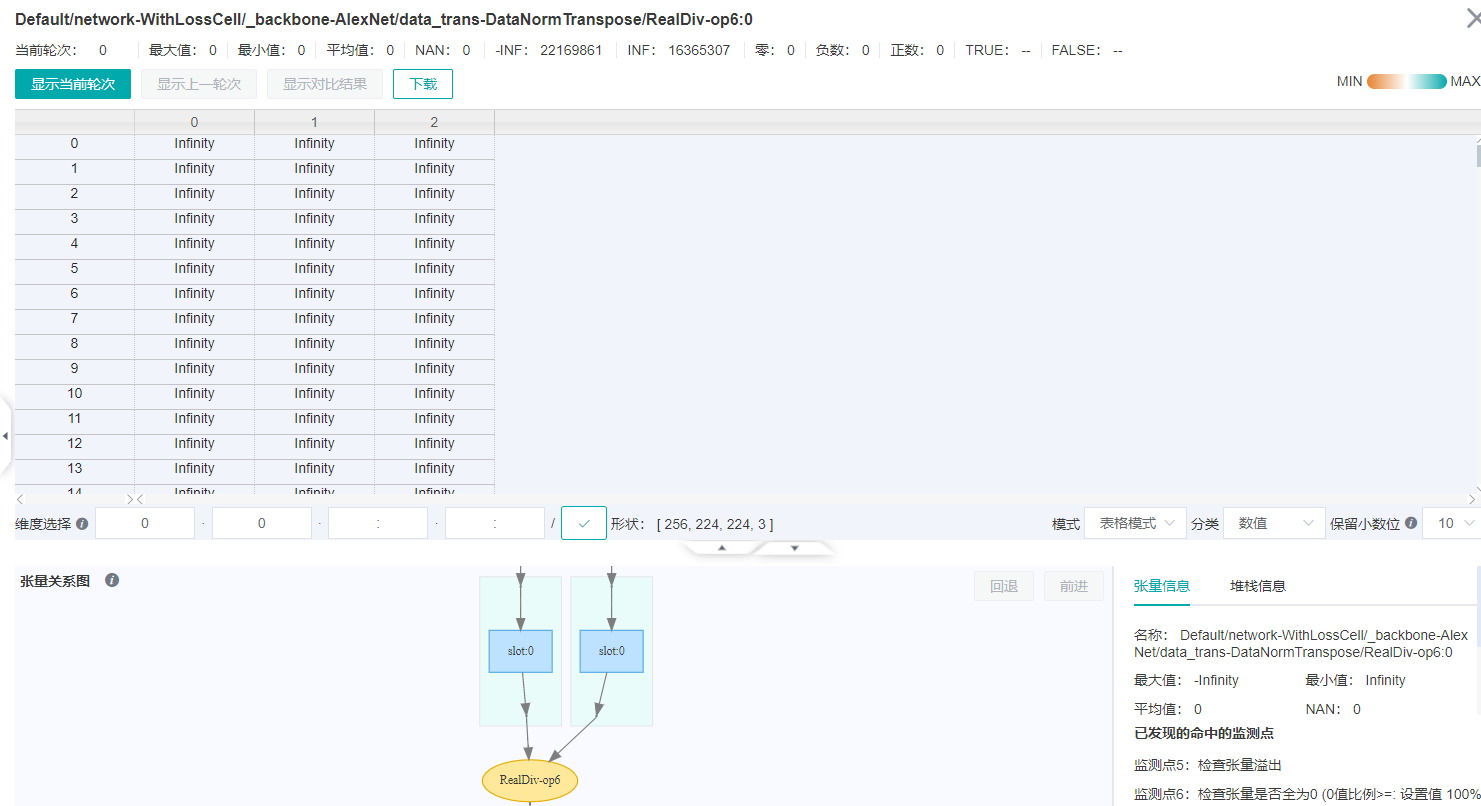
查看RealDiv-op6节点的具体数值,在张量展示区域的右下方的模式下拉框中选择表格模式,如下图,可以看到这个节点中,全是INF或-INF值。
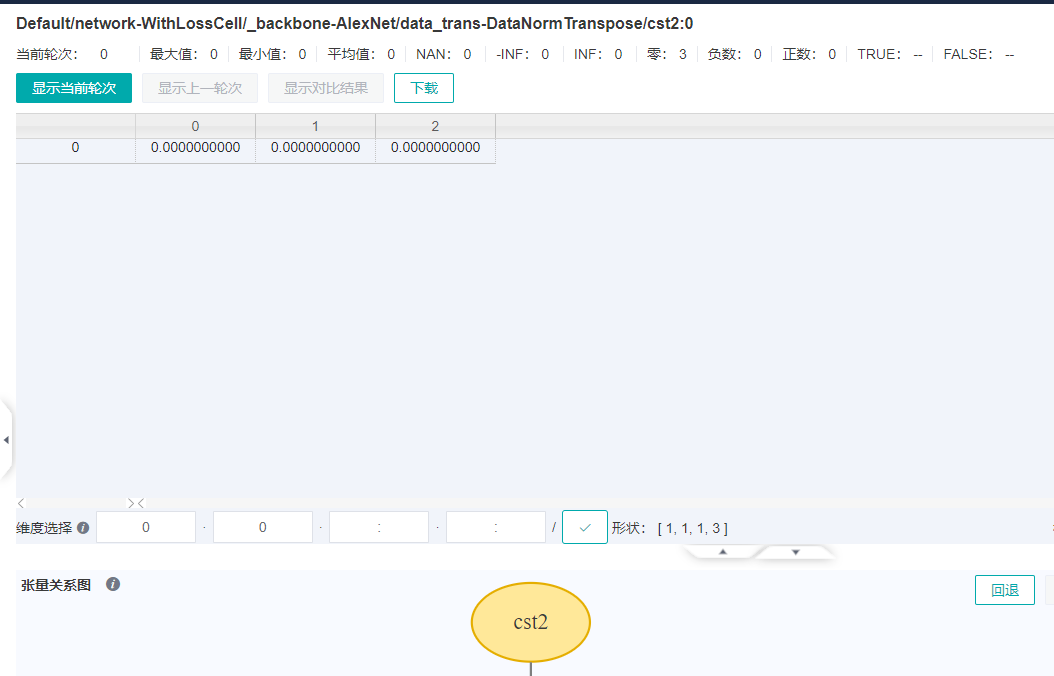
再查看RealDiv-op6节点的输入,在张量关系图上,双击RealDiv-op6上方用箭头连接的‘slot:0’,就可以切换展示的张量。切换到cst节点后,发现cst2节点中有0值,而0是不能作为除数的,至此就找到了异常的根源。
那么是哪里造成了0作为除数的后果呢,我们点击张量展示页的右上方的
×,关闭张量展示页,回到计算图展示页。在计算图展示页,再定位到RealDiv-op6节点,点击图下方的堆栈信息,就可以看到当前节点相关的代码。可以看到除法运算的除数是alexnet.py文件的59行代码中的self.std。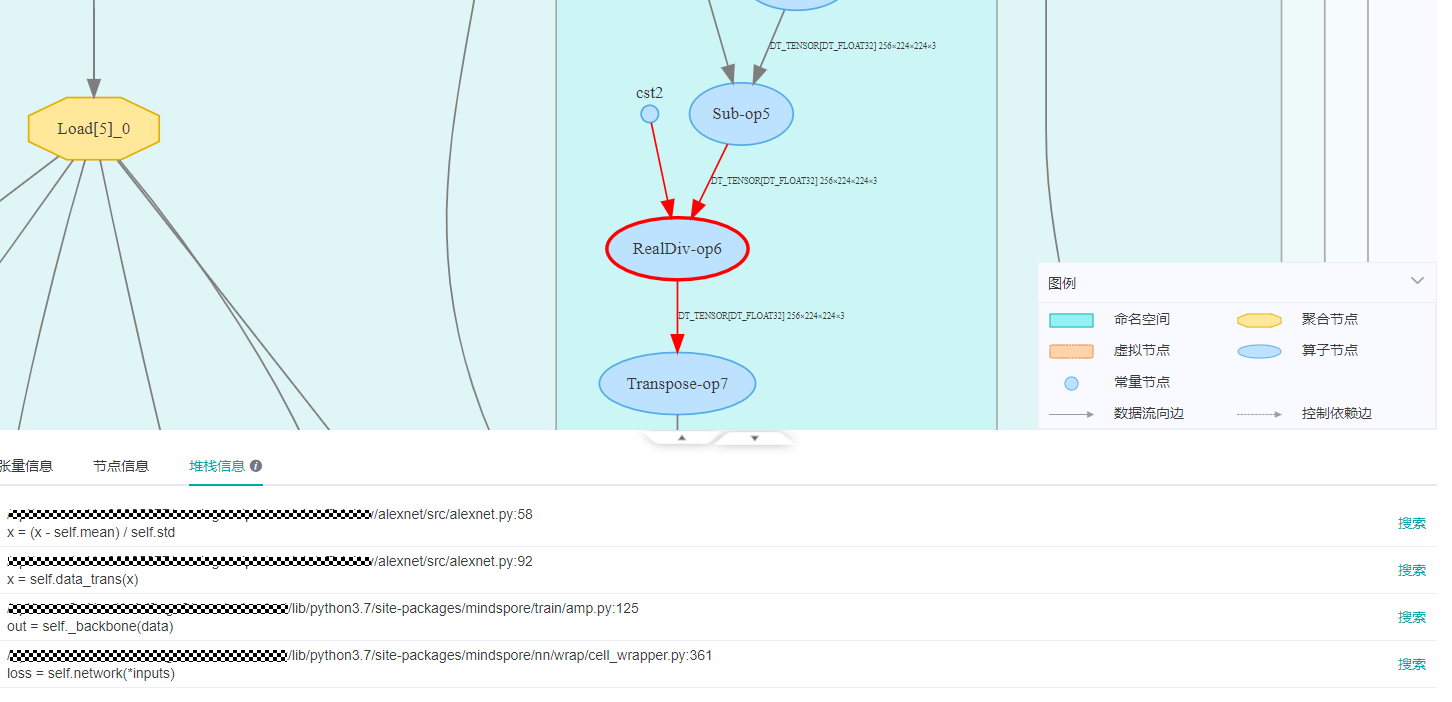
检查alexnet.py文件代码,发现上下文代码如下:
- class DataNormTranspose(nn.Cell):
- """Normalize an tensor image with mean and standard deviation.
- Given mean: (R, G, B) and std: (R, G, B),
- will normalize each channel of the torch.*Tensor, i.e.
- channel = (channel - mean) / std
- Args:
- mean (sequence): Sequence of means for R, G, B channels respectively.
- std (sequence): Sequence of standard deviations for R, G, B channels
- respectively.
- """
- def __init__(self):
- super(DataNormTranspose, self).__init__()
- self.mean = Tensor(np.array([0.485 * 255, 0.456 * 255, 0.406 * 255]).reshape((1, 1, 1, 3)), mstype.float32)
- self.std = Tensor(np.array([0. * 255, 0. * 255, 0. * 255]).reshape((1, 1, 1, 3)), mstype.float32)
- def construct(self, x):
- x = (x - self.mean) / self.std
- x = F.transpose(x, (0, 3, 1, 2))
- return x
从以上代码可以看出,在DataNormTranspose 类的__init__方法中self.std = Tensor(np.array([0. * 255, 0. * 255, 0. * 255]).reshape((1, 1, 1, 3)), mstype.float32) 将std初始化为全零的张量,这里的错误导致了x = (x - self.mean) / self.std 中将0作为除数。
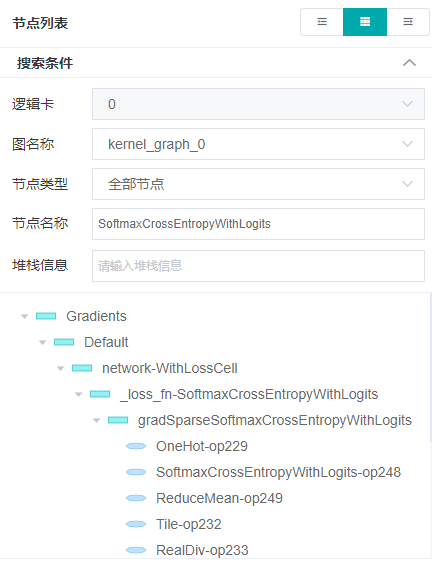
- 这里还没有到loss为0的step,我们点击页面上的继续按钮,直到看到训练的log中出现loss is 0.0,然后在调试器上查看loss为0的具体原因。由于网络loss使用的是SoftmaxCrossEntropyWithLogits,在调试器页面的搜索条件一栏输入SoftmaxCrossEntropyWithLogits,按回车键,就可以找到SoftmaxCrossEntropyWithLogits节点,如下图所示。
在节点列表点击SoftmaxCrossEntropyWithLogits-op248,计算图就会定位到这个节点。如下图所示,可以看到SoftmaxCrossEntropyWithLogits-op248有两个输入,一个是OneHot-op229,它是训练数据的真实的OneHot编码,还有一个是前向网络的输出。
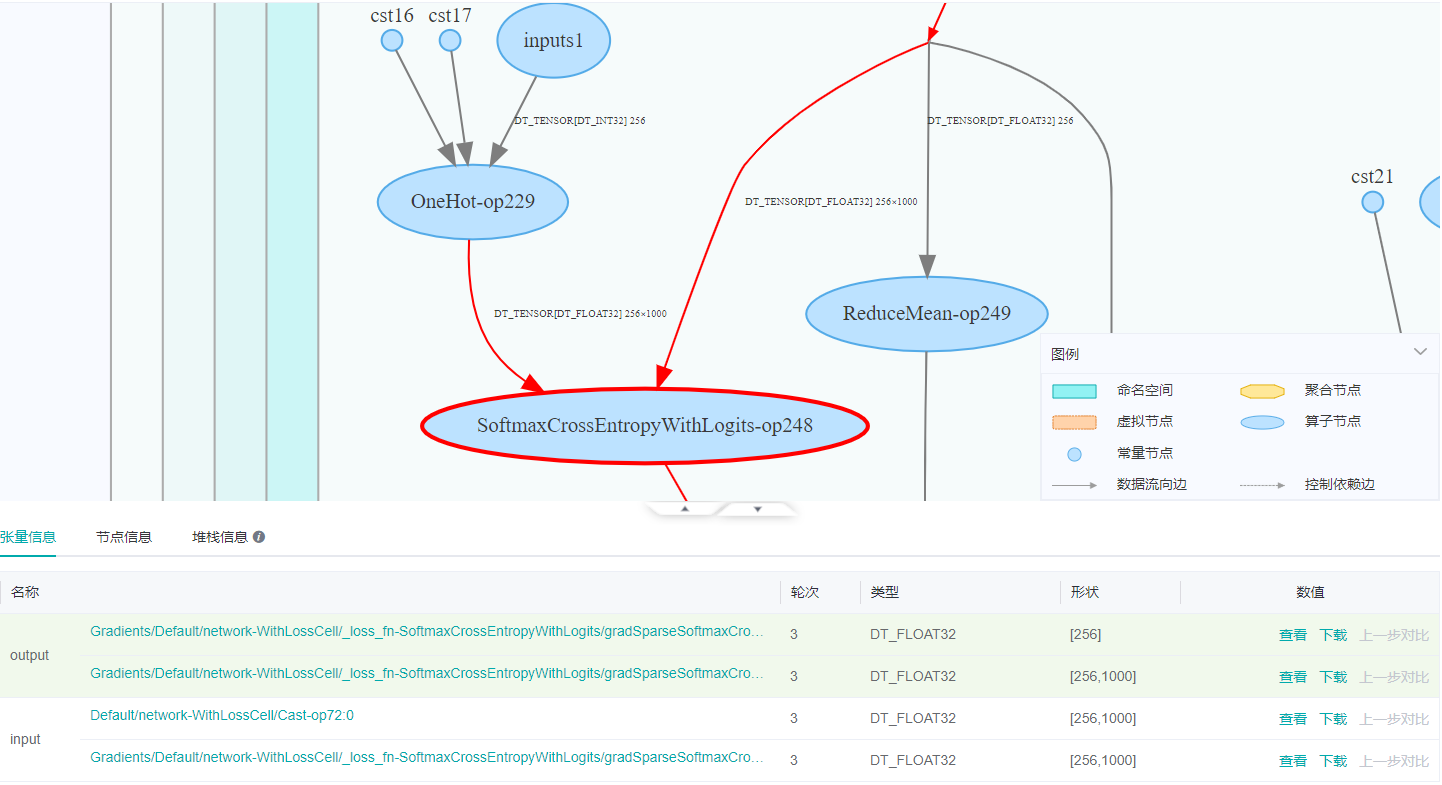
点击张量信息中数值列的第一行的
查看,进入张量展示页面,模式改成表格模式,可以看到张量值全为0,如下图所示。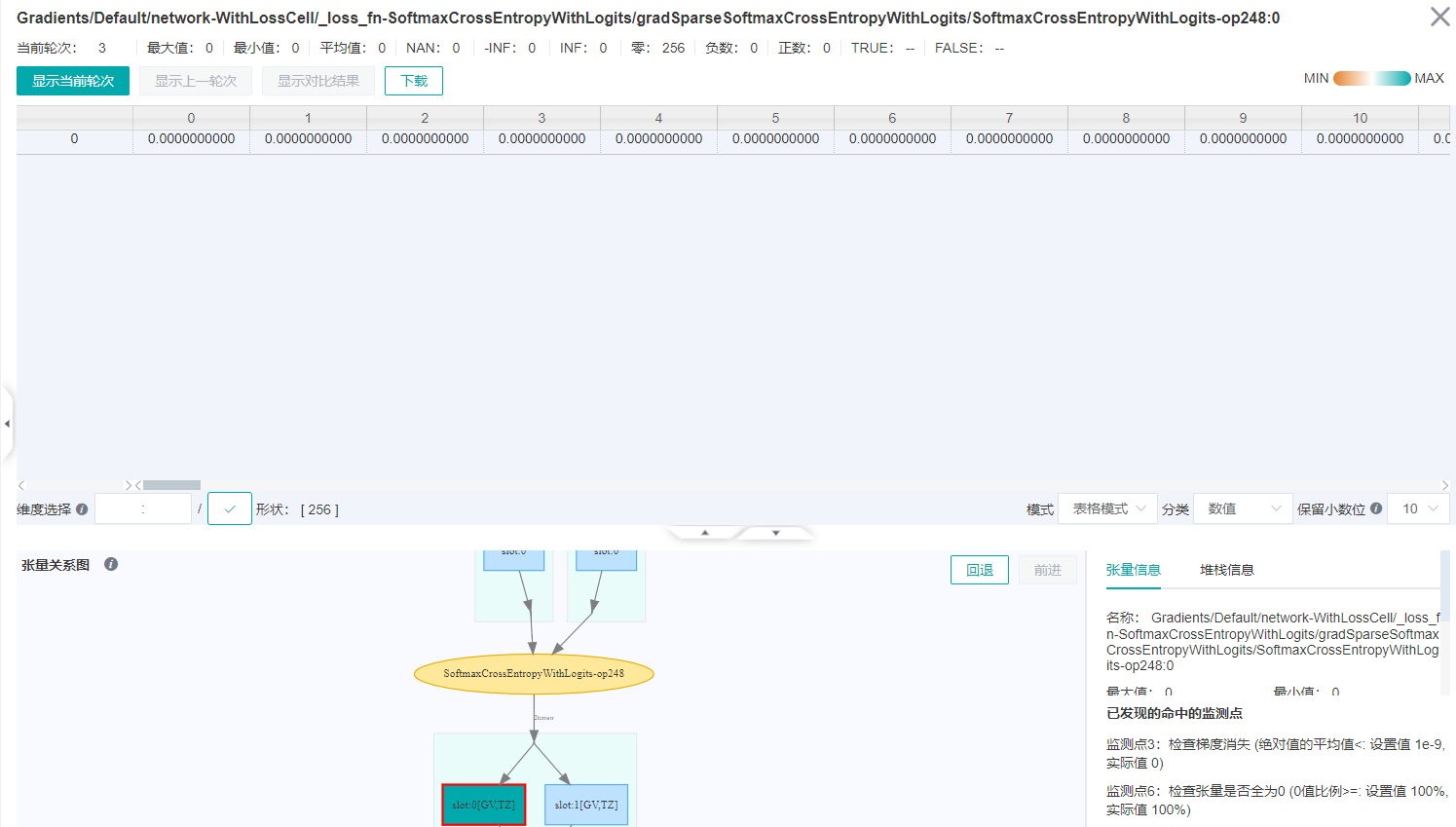
然后在张量关系图上双击SoftmaxCrossEntropyWithLogits-op248的第一个输入,切换到Cast-op72节点。开始会显示“请求数据超过上限10万,请尝试切片或查询其他维度。”,需要在维度选择后面的输入框中,第一个维度改成“:100”,表示只显示前100行的数据,然后点击后面的“√”确定。
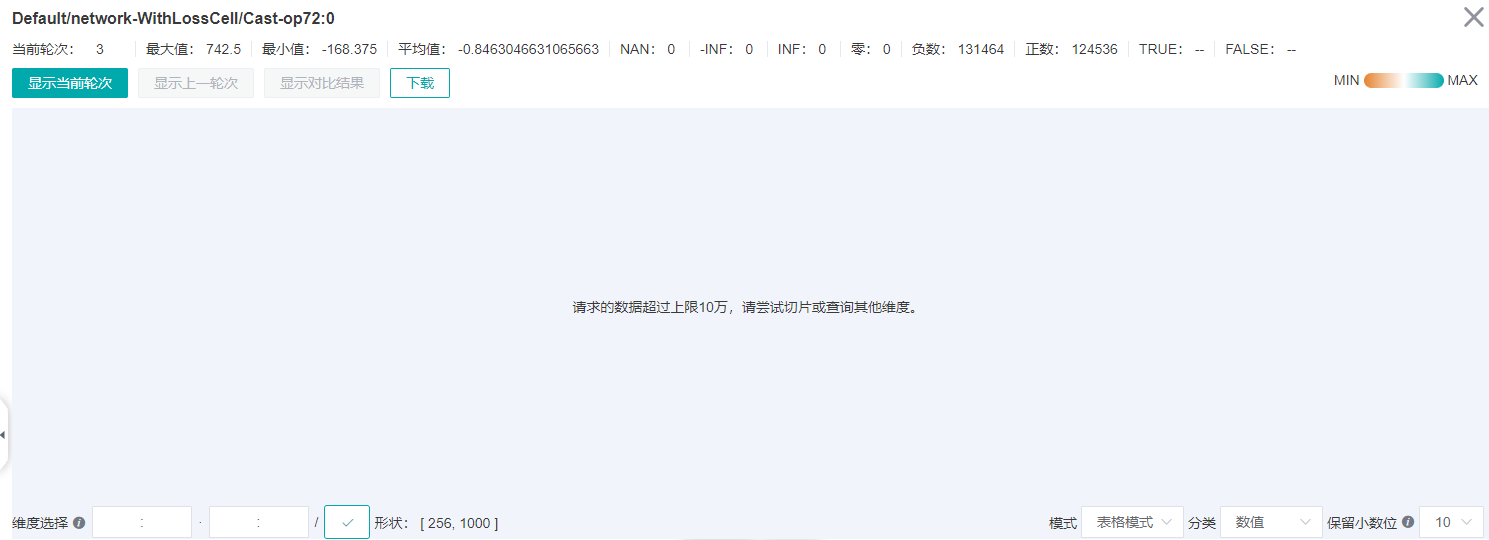
选择维度之后的张量展示如下图,可以看到第一列数值远大于其它列的数值。在维度选择的第一个输入框改成“100:200”或者“200:”,同样是第一列数值远大于其它列的数值。这与之前的除0的操作是相关的,因为对输入数据除0之后都变成了INF,导致本来有差异的输入数据变得没有差异,所以最终的网络输出也差异不大。
点击张量关系图右上角的回退,我们再回退到SoftmaxCrossEntropyWithLogits-op248,然后在张量关系图上双击SoftmaxCrossEntropyWithLogits-op248的第二个输入,查看OneHot-op229节点,同样在维度选择的第一个输入框输入“:100”,点击“√”之后如下图所示,第一列数值为1,其它列数值都是0。在维度选择的第一个输入框改成“100:200”或者“200:”,同样是第一列数值为1,其它列数值都是0。OneHot-op229的形状是[256, 1000],其中256是batch_size,1000是数据集的种类。也就是说,这一批的输入的样本数是256,每个样本的类别都是第一类,数据集的类别没有打乱。

检查代码的数据集生成部分。确定没有打乱数据集顺序,ds_train = create_dataset_imagenet(config, config.data_path, config.batch_size, shuffle=False)语句中将shuffle设置成了False,如下所示。
- if config.dataset_name == "cifar10":
- ds_train = create_dataset_cifar10(config, config.data_path, config.batch_size, target=config.device_target)
- elif config.dataset_name == "imagenet":
- # Imagenet dataset normalize and transpose will work on device
- _off_load = True
- ds_train = create_dataset_imagenet(config, config.data_path, config.batch_size, shuffle=False)
- else:
- raise ValueError("Unsupported dataset.")
- 通过以上检查步骤,可以判断是除0的操作和数据集没有打乱这两个原因共同造成了loss异常。除0使网络接收的数据是相同的,没有打乱数据集使loss计算接收的label是相同的,相同的数据和label导致总是以相同的数据更新权重,严重限制了梯度优化方向的可选择性,导致过拟合。
步骤3. 修复异常代码
修改代码的以上两个地方 alexnet.py中self.std = Tensor(np.array([0. * 255, 0. * 255, 0. * 255]).reshape((1, 1, 1, 3)), mstype.float32)self.std = Tensor(np.array([0.229 * 255, 0.224 * 255, 0.225 * 255]).reshape((1, 1, 1, 3)), mstype.float32)ds_train = create_dataset_imagenet(config, config.data_path, config.batch_size, shuffle=False)ds_train = create_dataset_imagenet(config, config.data_path, config.batch_size)- epoch: 1 step: 1, loss is 6.907746315002441
- epoch: 1 step: 2, loss is 6.907710552215576
- epoch: 1 step: 3, loss is 6.90772819519043
- epoch: 1 step: 4, loss is 6.907771110534668
- epoch: 1 step: 5, loss is 6.907710075378418
- …
- epoch: 2 step: 1, loss is 6.339262008666992
- epoch: 2 step: 2, loss is 6.275265693664551
- epoch: 2 step: 3, loss is 6.352719306945801
- epoch: 2 step: 4, loss is 6.288741111755371
- epoch: 2 step: 5, loss is 6.236105442047119
- epoch: 2 step: 6, loss is 6.177802085876465
- …
建议与总结
MindInsight调试器是为MindSpore图模式训练提供的调试工具,对于图模式训练过程中遇到的loss异常问题,可以用调试器查看计算过程中的中间节点值。调试器还提供了一些常见的异常现象检查规则,可以自动发现计算过程中的异常节点。在训练时遇到loss为0,nan,inf等异常值的问题,不妨尝试用调试器来定位问题。
相关参考文档
1)关于精度问题定位的思路,可以参见精度问题初步定位指南和精度问题详细定位和调优指南。
-
相关阅读:
python web服务器部署
Ubuntu编辑.bashrc
全球南方《乡村振兴战略下传统村落文化旅游设计》八一新枝——2023学生开学季许少辉瑞博士生辉少许
Echarts的配置修改
elementui日期时间选择框自定义组件
2020年计算机能力挑战赛C/C++初赛题解
SkyWalking安装部署
dbeaver怎么批量执行sql
【21天学习挑战赛】冒泡排序与插入排序
微信新功能,图片直接一键生成Excel表格
- 原文地址:https://blog.csdn.net/Kenji_Shinji/article/details/126991081