-
【Mysql】Mysql获取排班时间段中的休息时间段方法
在MySQL中,可以使用自连接(self-join)来获取上一条记录的结束时间和下一条记录的开始时间,并将它们组合成一条记录。首先,需要为表创建一个包含记录ID和时间信息的临时表,然后使用自连接获取相邻记录的时间信息。
数据准备:
-- demo.schedule definition CREATE TABLE `schedule` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id', `start_time` datetime NOT NULL, `end_time` datetime NOT NULL, `employee_id` int(10) unsigned DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=latin1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
INSERT INTO demo.schedule (start_time, end_time, employee_id) VALUES('2023-09-08 07:50:00', '2023-09-08 12:00:00', 1); INSERT INTO demo.schedule (start_time, end_time, employee_id) VALUES('2023-09-08 12:40:00', '2023-09-08 17:20:00', 1); INSERT INTO demo.schedule (start_time, end_time, employee_id) VALUES('2023-09-08 18:10:00', '2023-09-08 20:30:00', 1);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
以下是一个示例查询,假设你的表名为schedule,其中包含id和start_time、end_time字段:
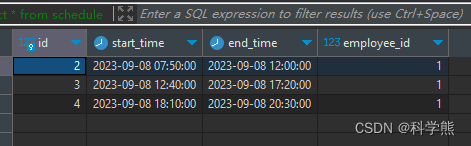
select * from schedule;- 1
输出:
-- 创建临时表并插入数据 CREATE TEMPORARY TABLE temp_schedule ( prev_id INT, curr_id INT, prev_end_time DATETIME, curr_start_time DATETIME ); INSERT INTO temp_schedule (prev_id, curr_id, prev_end_time, curr_start_time) SELECT t1.id AS prev_id, t2.id AS curr_id, t1.end_time AS prev_end_time, t2.start_time AS curr_start_time FROM schedule t1 JOIN schedule t2 ON t1.id = t2.id - 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
select * from temp_schedule- 1
输出:

这个查询将创建一个名为temp_schedule的临时表,其中包含相邻记录的ID、上一条记录的结束时间和下一条记录的开始时间。最后,通过在临时表上执行查询,选择上一条记录的结束时间和下一条记录的开始时间的结果。
注意:这个查询假设记录按时间顺序排列,并且每个记录的ID是唯一的。如果你的表结构或数据不符合这些要求,你需要根据实际情况进行调整。
-
相关阅读:
CommonsCollection1反序列化链学习
关于缓存一致性协议、MESI、StoreBuffer、InvalidateQueue、内存屏障、Lock指令和JMM的那点事
瞬态抑制二极管TVS的核心参数?|深圳比创达电子EMC(下)
设计模式学习(七):适配器模式
前端面试题日常练-day45 【面试题】
ZooKeeper-API基础
【Mybatis源码分析】插件机制和Pagehelper插件源码分析
Spark性能调优
special net 出Lef
2.2数据的表示和运算--原码、反码、补码、移码
- 原文地址:https://blog.csdn.net/qq_22744093/article/details/132753317
