-
【机器学习】李宏毅——Domain Adaptation(领域自适应)
在前面介绍的模型中,一般我们都会假设训练资料和测试资料符合相同的分布,这样模型才能够有较好的效果。而如果训练资料和测试资料是来自于不同的分布,这样就会让模型在测试集上的效果很差,这种问题称为Domain shift。那么对于这种两者分布不一致的情况,称训练的资料来自于Source Domain,测试的资料来自于Target Domain。
那么对于领域转变的问题,具体的做法随着我们对于目标领域的了解程度不同而不同,主要有以下几种情况:
- 我们当前拥有少量目标领域的样本且含有标注:具体做法是取其中的一小部分去“微调”训练好的模型,但要注意不能够训练太多次迭代否则可能会对小部分的样本产生过拟合
- 我们拥有目标领域的大量资料但是没有标注
- 我们拥有很少量的目标领域的资料且没有标注
- 我们根据对于目标领域没有认识与了解
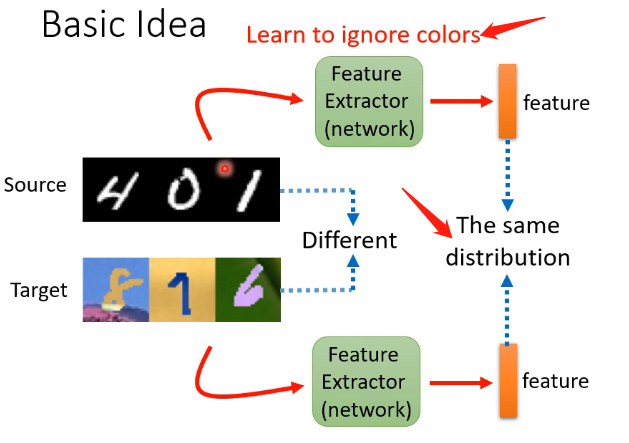
那我们关注的主要是第二种情况,它是我们现实生活中的常见情况。那么最基本的想法是我们能不能训练一个特征提取器,它可以接受训练集和测试集的样本,然后输出是对这些样本的关键特征进行提取,例如下图的例子中就是去除掉颜色的影响,提取它作为数字最关键的特征。
Domain Adversarial Training
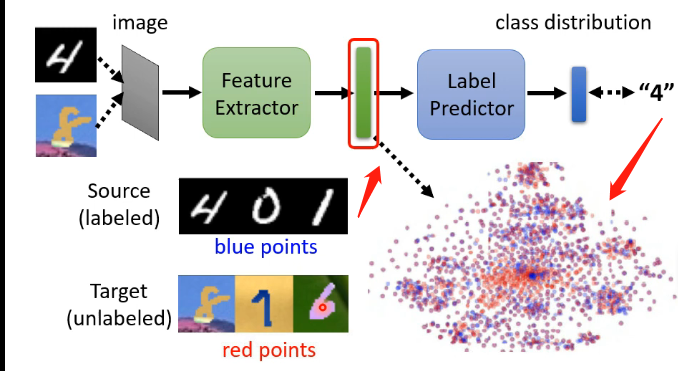
这个想法是基于上面说的基本想法之上,但是它没有专门地去训练一个特征提取器,它只是在原来的模型上,划分一部分为特征提取器,另一部分为标签预测器,如下图:

那么在这个模型中,如果输入的是训练集的图片,我们可以通过其输出结果与真实结果之间的交叉熵来进行训练,但是如果输入是测试集的图片,由于没有标签就无法来调整参数,但这时就要想到我们的特征提取器。
经过特征提取器处理之后得到的向量,我们是希望训练集得到的向量分布,和测试集得到的向量分布是没有差异的,如下图:
那么怎么让这两个分布之间越接近越好呢?这时候就想到了对抗的思想,我们可以加入一个领域分辨器,它的输入就是特征提取器的这个输出向量,而输出就是该向量是来自于训练集还是测试集,因此我们可以将特征提取器看成是生成器,将领域分辨器看成是辨认器,特征提取器是不断调整参数来骗过领域分辨器,而领域分辨器则不断学会来区分,如下图:
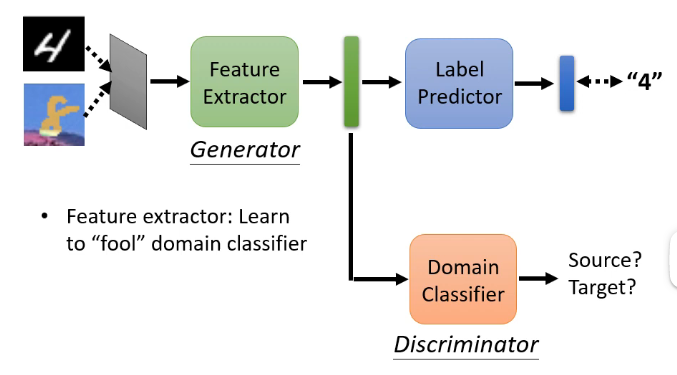
但是我们要考虑到一个问题:有没有可能这样会使得特征提取器学习到不管我得到什么样的输入,我都输出一模一样的向量(例如零向量)这样你肯定无法分辨?可能会存在这个问题,但是如果真的只生成一模一样的向量,那么后面的标签预测器也就无法做出预测了!因此我们可以通过标签预测器的输出来防止这种情况的发生!
假设特征提取器的参数为 θ f \theta_f θf,标签预测器的参数为 θ p \theta_p θp,领域辨别器的参数为 θ d \theta_d θd,而L为标签预测器预测结果与真实结果之间交叉熵算出来的损失函数, L d L_d Ld为领域辨别器分辨的时候的损失函数,那么各自的训练目标为:
θ p ∗ = m i n θ p L θ d ∗ = m i n θ d L d θ f ∗ = m i n θ f L − L d \theta^*_p=min_{\theta_p}L\\\theta^*_d=min_{\theta_d}L_d\\\theta^*_f=min_{\theta_f}L-L_d θp∗=minθpLθd∗=minθdLdθf∗=minθfL−Ld
第三个公式表明特征提取器一方面是希望能够降低后面预测的误差,另一方面是为了让领域辨别器无法分辨,从而来使得两个分布更加接近。Limitation
假设我们当前样本的类别有两类,那么对于有标签的训练集我们可以明显地划分为两类,那么对于没有标签的测试我们希望它的分布能够和训练集的分布越接近越好,如下图的右图:
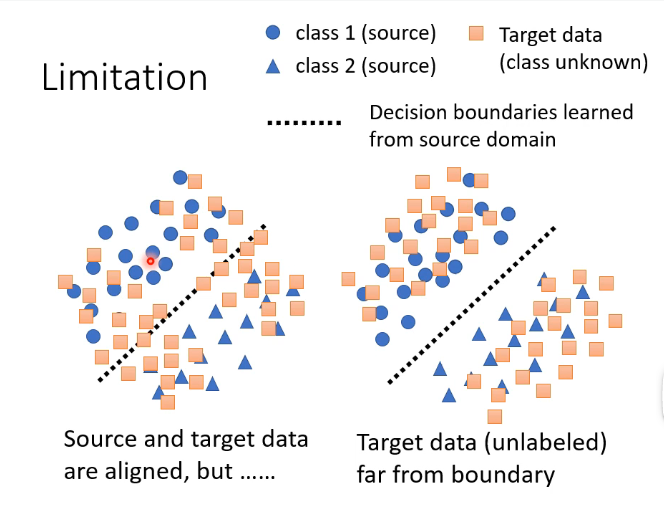
那么在这个思路上进行拓展的话,对于我们刚才手写识别的例子,我们输入一张图片得到的是一个向量,其中含有属于每一个分类的概率,那我们希望的是这个测试集的样本离分界线越远越好,那就代表它得到的输出向量要更加集中于某一类的概率,不能够各个分类的可能性都差不多,即:
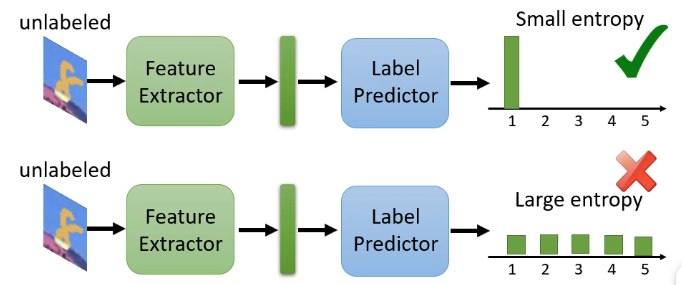
那么上述想法的问题在于,有没有可能训练集和测试集的分类根据就是不同的呢?例如训练集中可以分为老虎和狮子两类,而测试集还有另外的狼呢?如下图:
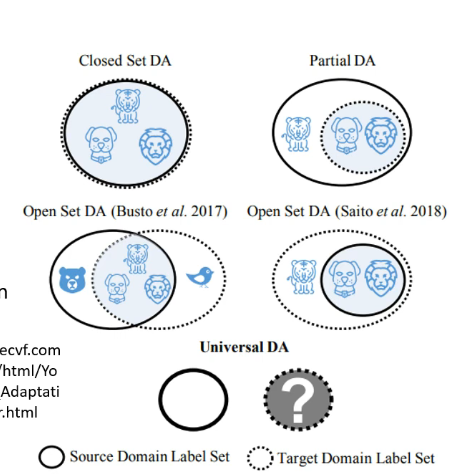
那么这也是一个值得研究的问题。
其他情况
除了上述介绍的情况,我们对于测试集的了解程度还有其他的情况,例如我们只拥有很少量的测试集并且还没有标签,甚至于说我们对于测试集什么都不知道。这些情形会更加的复杂,目前也仍然处于研究之中
-
相关阅读:
什么是微控制器?
算法通关村第十八关——回溯
Android开发的Handler消息机制解释
关于Kali部署OneForAll,不能运行问题
你是如何做好Unity项目性能优化的
什么是高敏感型人格,高敏型人格如何改变自己
技术策划学习 —— 引擎工具链高级概念与应用
艾泊宇产品战略:华为手机品牌是如何从低端到高端的
Windows系统设置mysql主从模式
计算机操作系统学习(五)文件管理
- 原文地址:https://blog.csdn.net/StarandTiAmo/article/details/126978723