-
c++初始之二
七.auto关键字
1.auto不能作为函数参数。
因为函数栈帧创建时需要知道明确具体的空间的大小。如果auto作为函数参数,就没有办法知道函数创建时的具体空间的大小了。
2.auto不能直接用来声明数组
3.关键字typeid的介绍
a.介绍:typeid 是 C++ 的 关键字 之一,等同于sizeof这类的操作符。typeid (a).name ()可以返回变量a的类型。
b.使用: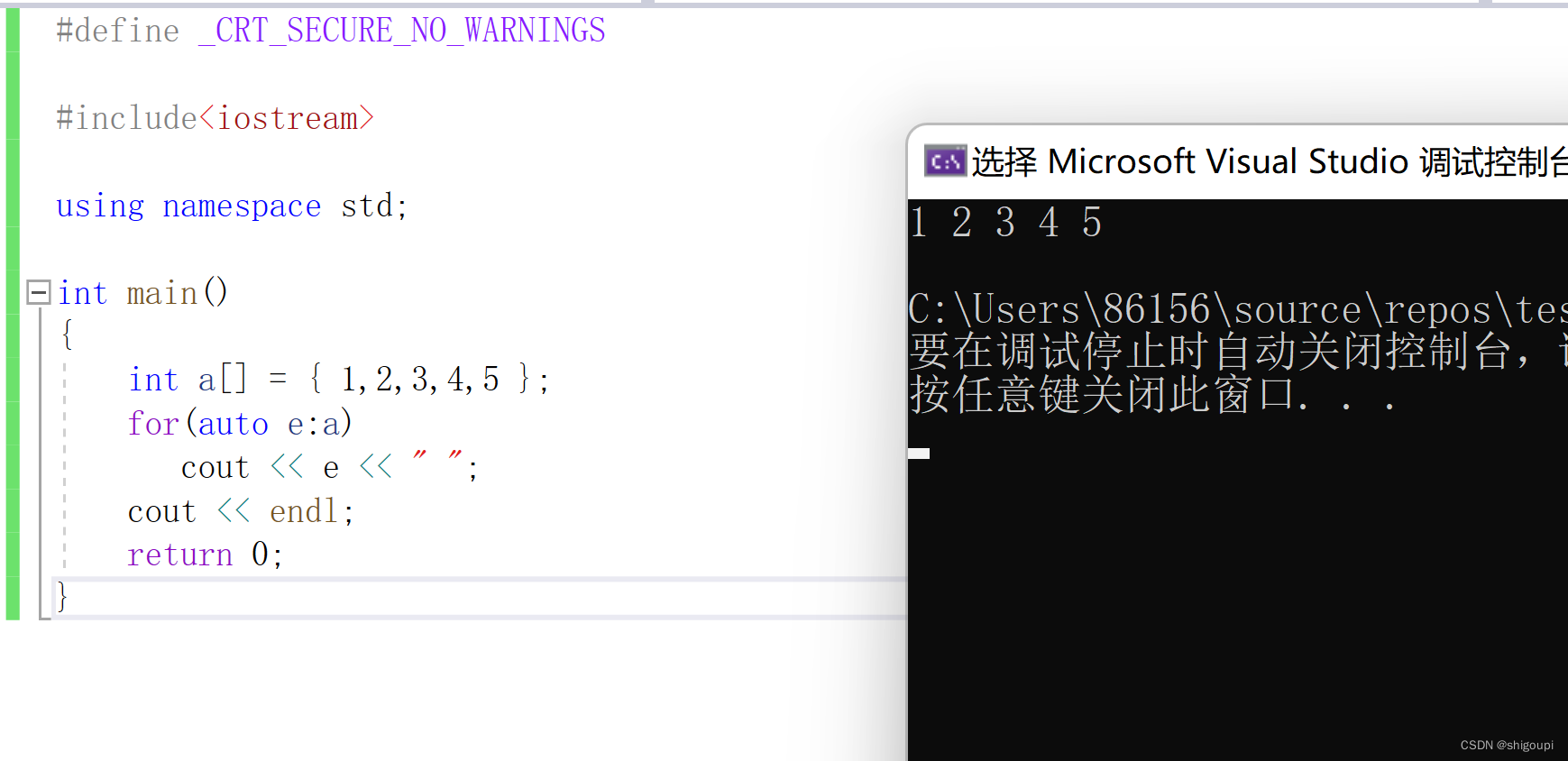
八.范围for遍历
1.使用:
2.和auto、引用的混合使用
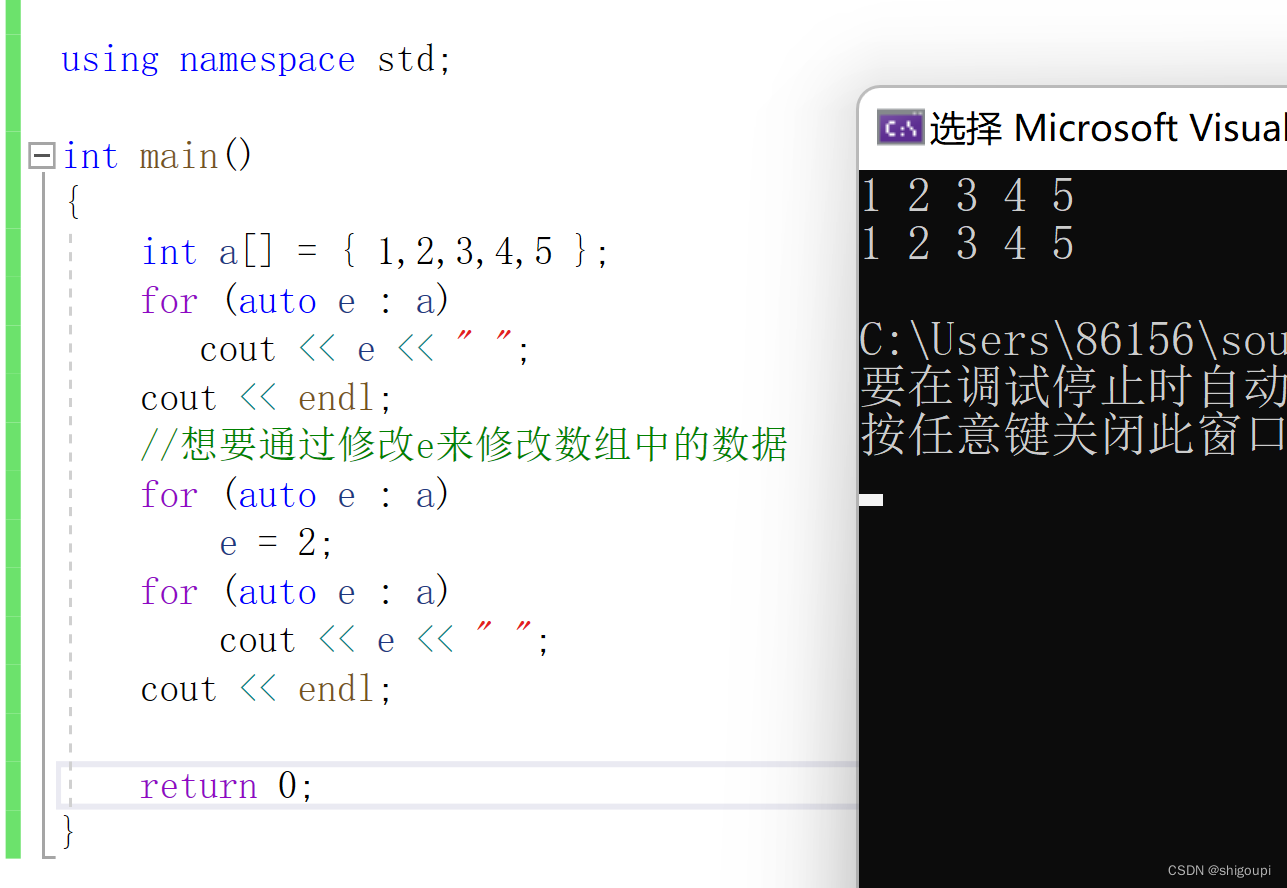
想要通过直接修改e的值修改数组a的数据是不可得的,因为e只是a数组数据的一个拷贝,当第二次范围for循环遍历,修改了e的值也没有修改数组a的值,且等到第三次范围for循环遍历的时候,e又重新被赋予a数组的数据。
要想实现这一效果就要使用引用作为参数类型。
be like:
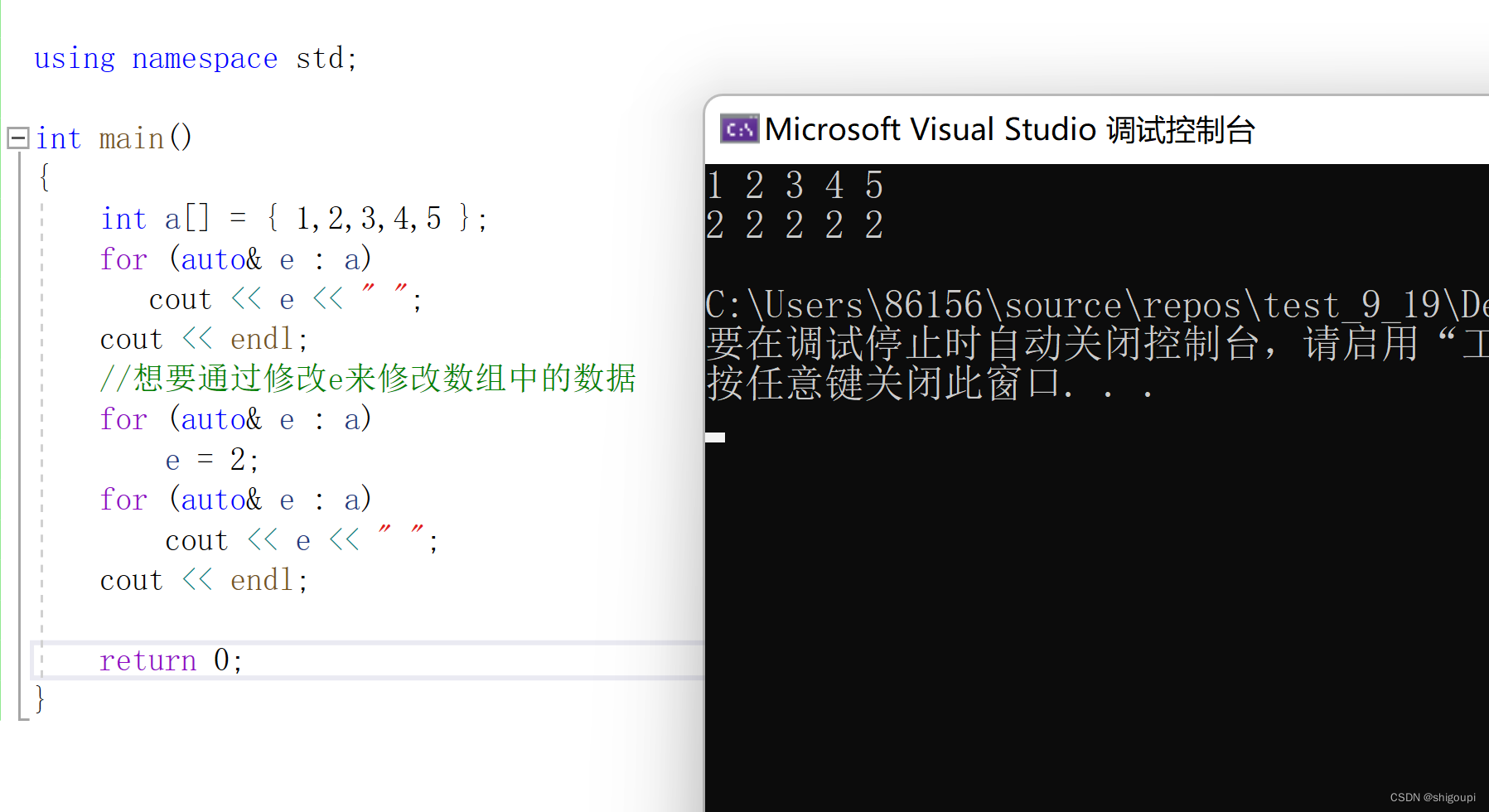
上图表示的效果中,e是数组a每个元素的别名,该变量与数组a每个元素赋值过去的地址相同,所以在第二个范围for循环遍历的时候,修改e的值就修改相应的数组a的元素的值。第三个范围for循环遍历打印的数组a的数据是修改后的结果。
九.指针空值 nullptr
1.为什么要在c++再定义指针空值nullptr?
答:由于c++支持函数重载,所以会出现下图这样的情况。
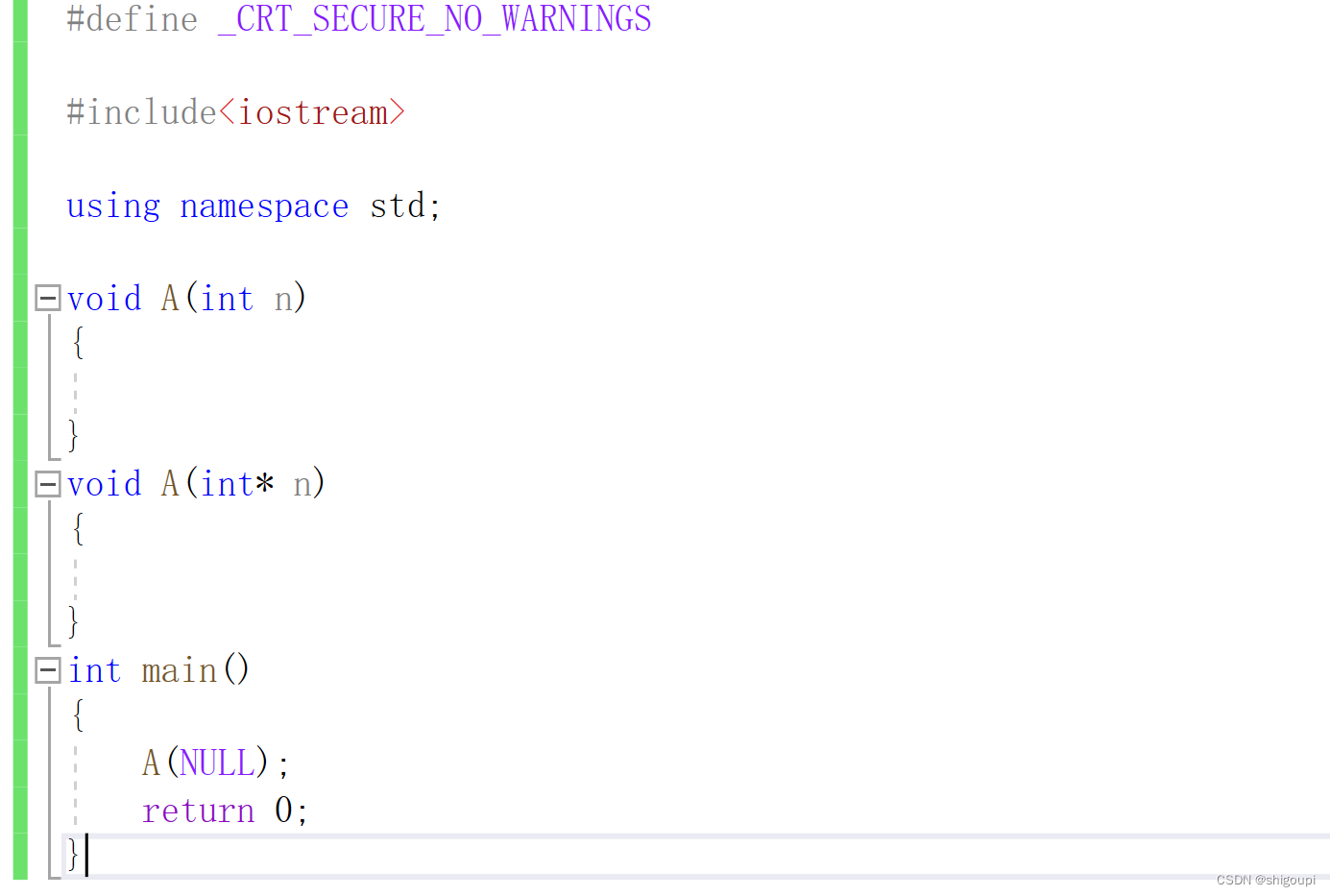
又

在宏中NULL被定义为0,当NULL当作参数传入时,是作为整型0传入呢,还是作为整型指针NULL传入呢,这就出现了二义性。所以c++的创始人就发现了这个问题,创建了nullptr来表示c++中的指针空值。十.内联函数
1.复习宏
在介绍这部分知识前,请允许我带领大家先复习宏的定义。好久没有接触到宏,以至于当再次看到宏的定义的时候,脑中竟然没有有价值的知识浮现。c++是在c的基础生长的,要想学好c++就必然要学好c。
a.定义一个宏
比如定义一个ADD宏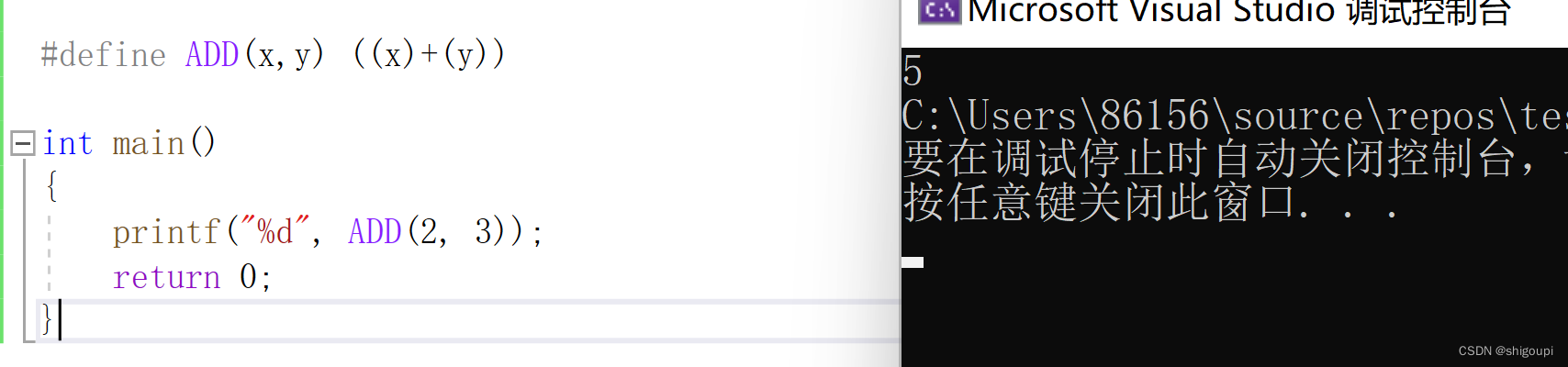
b.宏定义时的一些注意事项:
不加外层括号无法判断优先级,比如:
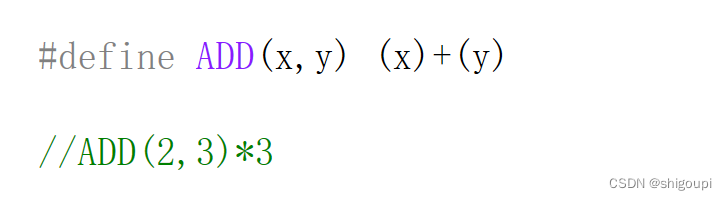
不加内层括号,若是传复杂参数出现,运算出现歧义,比如: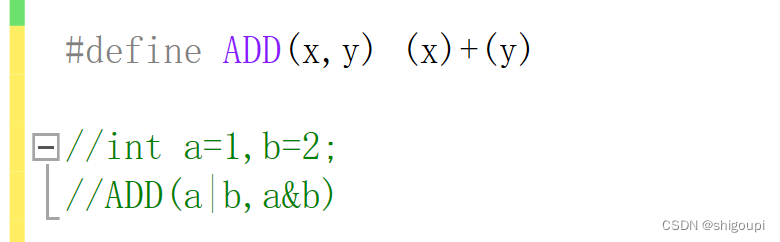
不可以加分号,宏在预处理阶段会直接替换,分号也会随之替换过去,比如:#define ADD(x,y) ((x)+(y));
//ADD(2,3)
//((2)+(3));c.宏的缺点:
不能调试;没有类型安全检查;容易写错。2.定义:
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调
用建立栈帧的开销,内联函数提升程序运行的效率。3.特点:
没有栈帧的开销,调用地方进行展开
4.判断内联函数是否成立
- 在release模式下,查看编译器生成的汇编代码中是否存在call Add
- 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不
会对代码进行优化)
//不存在call Add的表示展开,存在表示不展开。
//在汇编语言中,call表示调用一个子程序。
比如:
在Debug版本下

在Release版本下

5.缺点
a.递归不适用
b.长函数不适用6.为什么函数长了以后不展开?
inline关键字只是向编辑器提出建议,有不实现的可能性。编译器当辨识inline定义的内联函数过长,展开后会出现代码膨胀,也就是编译指令的大量增加的情况导致可执行程序(即安装包)的大小变大,便不会展开。
7.不支持声明和定义分离
还是在讲解这部分内容,要补充一方面的知识。我们要充分了解程序环境和处理的一些内容。
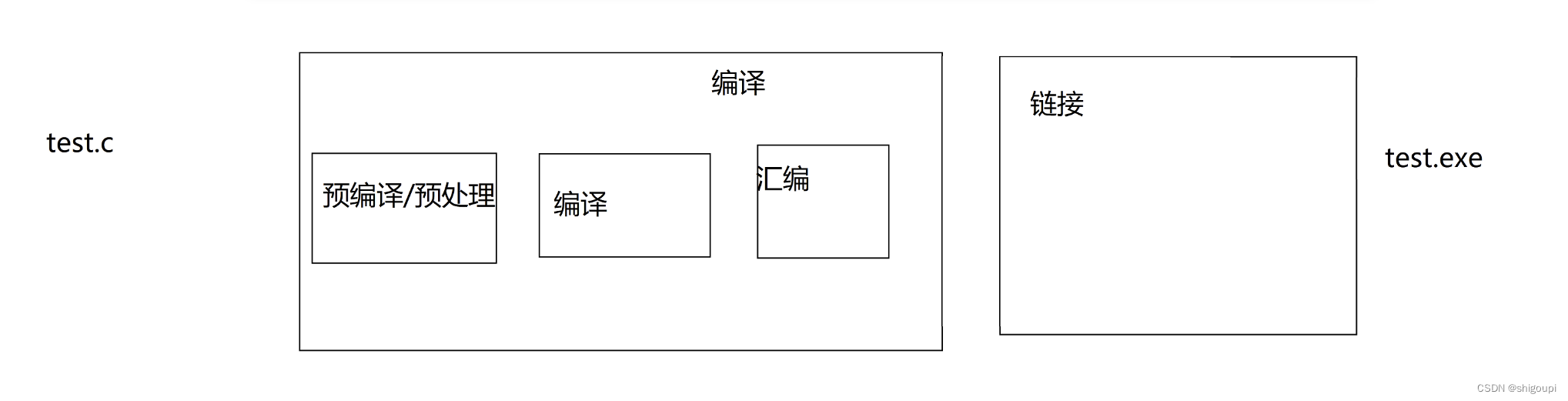
//定义需要创建存储空间,声明不需要创建空间
//链接的前提是有声明,无定义。(声明、定义在同一文件,或者定义在头文件,声明所在文件引用此头文件都不需要链接)为什么,为什么内联函数不支持声明和定义呢?为什么?
普通函数的声明和定义分离,仍然可以使用。是因为在函数调用的时候,通过函数的声明可以找到函数地址。
//这是声明
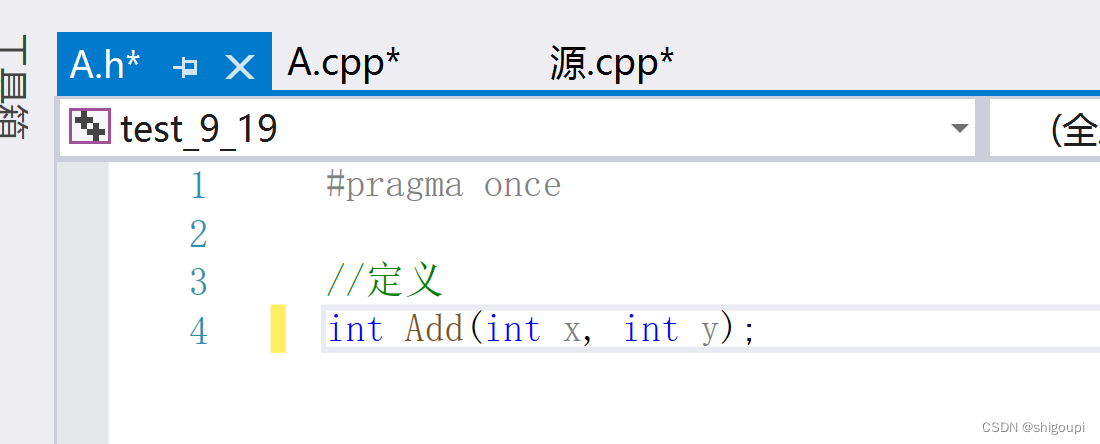
//这是定义
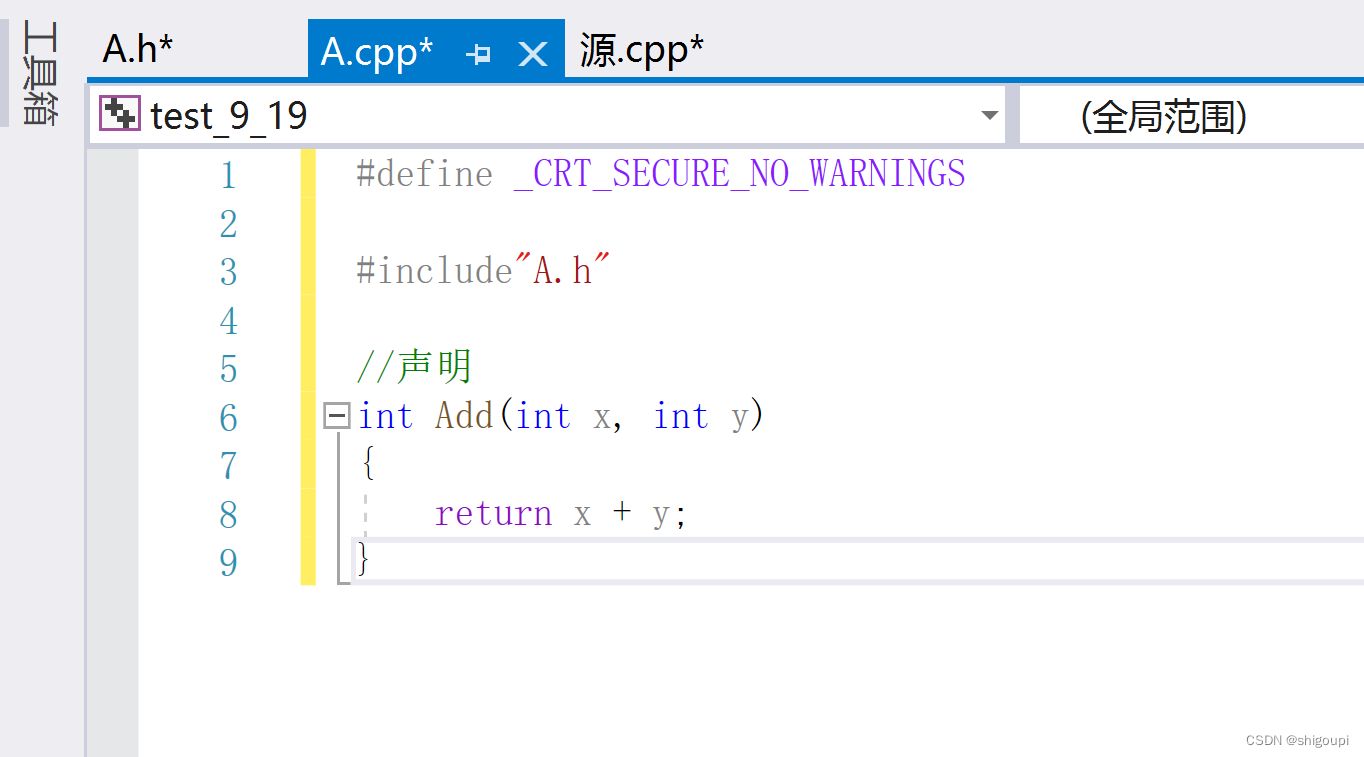
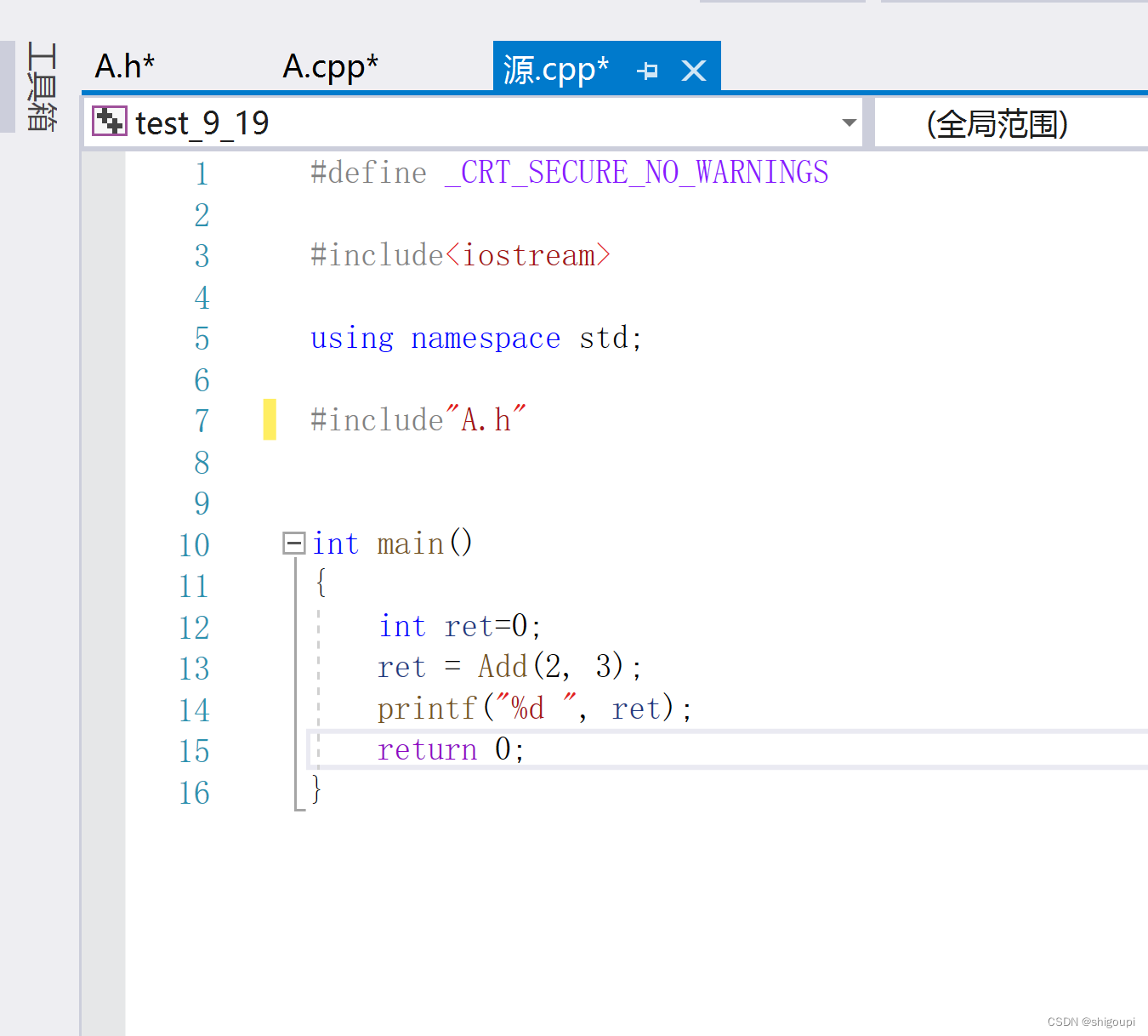
而内联函数的声明和定义不可以分离,是因为内联函数在文件预处理阶段就已经展开,并不并入到符号表中去,编辑器没有给函数开辟空间,所以内联函数是没有地址的。在函数调用时,即使函数声明展开也是无法找到函数的。
出错报告:

8.总结
inline关键字修饰的内联函数是以空间换取时间的行为,即使inline修饰的函数也有在预处理阶段不展开的情况。如果inline
修饰的函数编译器支持其在预处理阶段展开,那该函数在汇编过程不会被加入符号表中,因此也就无法调试该函数。 -
相关阅读:
Java无锁并发
Selenium 3和JUnit 5中的显示等待与隐式等待
解决 edge 浏览器开发者工具出不来的问题
Java Double valueOf(double d)方法具有什么功能呢?
默默无闻之随机练习题
gitee使用教程
iEnglish全国ETP大赛:教育游戏助力英语习得
跨时钟域握手信号的实现(Verilog)
springboot+shiro中自定义session过期时间
从 12K 到 60K, 这 2023Java 研发必问高级面试题,过关斩将拿 offer
- 原文地址:https://blog.csdn.net/shizhongruyi0606/article/details/126972939