-
JVM(Java虚拟机)
JVM
- 本文讲解的名词有,JVM,程序计数器,栈,堆,方法区,幸存区,元空间,永久代,老年代,新生代,伊甸园区,常量池等等。
- 什么是JVM?
- JRE、JDK和JVM的关系
- JVM的主要组成部分
- JVM执行程序
- JVM 内存划分(重点来了)
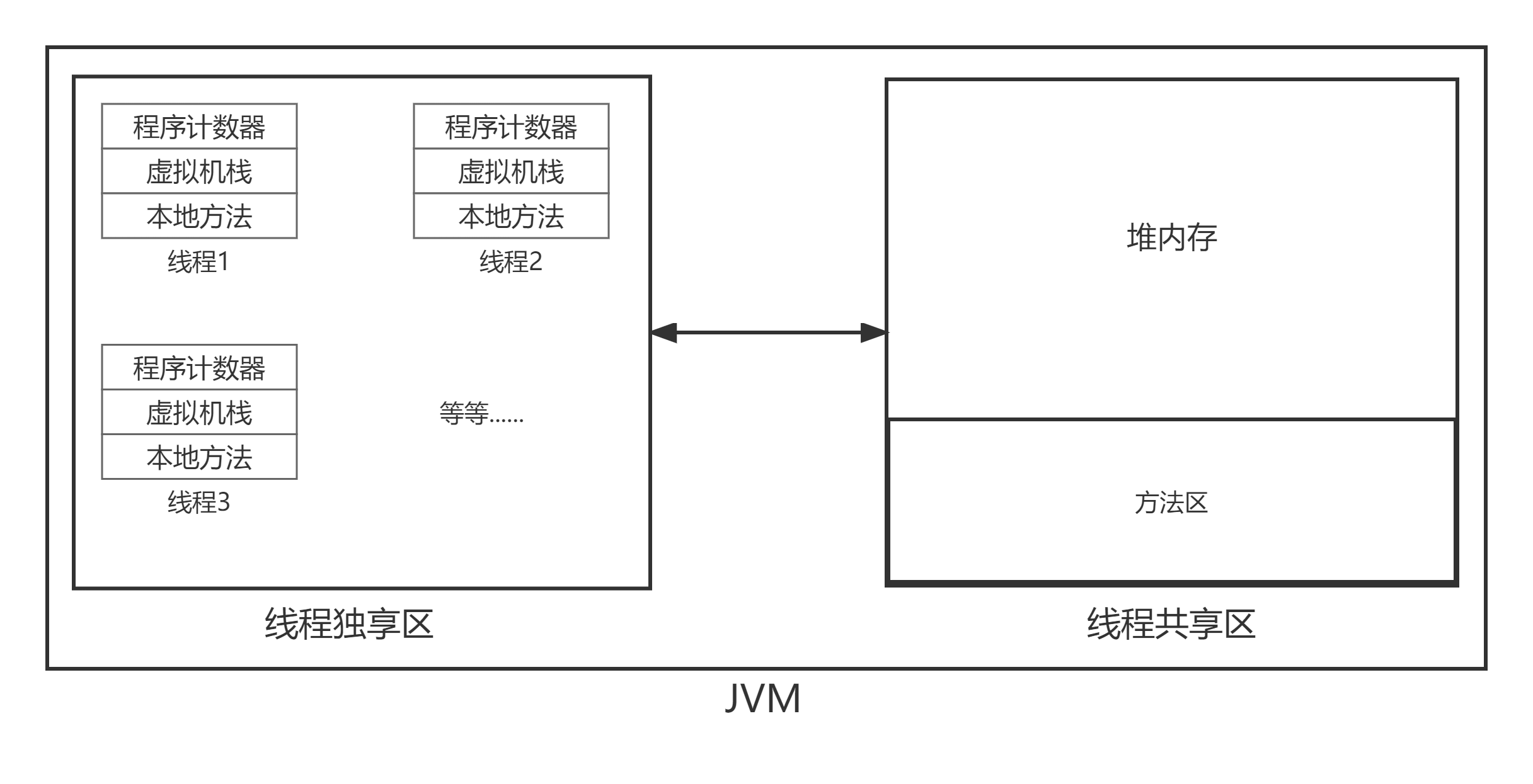
- 首先,JVM 按照线程是否共享将内存首先分成两大类
- 线程独享区
- 线程共享区
- 图解如下
- OK,我们进一步往下解剖这五大区域
- 程序计数器(Program Counter Register)
- Java 虚拟机栈(Java Virtual Machine Stacks)
- 本地⽅法栈(Native Method Stack)
- Java 堆(Java Heap)
- ⽅法区(Methed Area)
- JVM调优的参数
本文讲解的名词有,JVM,程序计数器,栈,堆,方法区,幸存区,元空间,永久代,老年代,新生代,伊甸园区,常量池等等。
什么是JVM?
JVM是Java Virtual Machine(Java虚拟机)的缩写,可以理解成一个专门运行.java文件的微型操作系统。
有三种JVM(不止),本文主要探讨jdk8版本的HotSpot
例如:
- SUN公司的Hotspot
- BEA公司的JRockit
- IBM公司的J9
JRE、JDK和JVM的关系
JDK(Java Development Kit,Java开发工具包)> JRE(Java Runtime Environment, Java运行环境)> JVM(Java Virtual Machine, Java虚拟机)
JVM的主要组成部分
类加载器(ClassLoader)
运⾏时数据区(Runtime Data Area)
执⾏引擎(Execution Engine)
本地库接⼝(Native Interface)JVM执行程序
⾸先通过类加载器(ClassLoader)会把 java 代码转换成字节码,运⾏时数据区(Runtime Data Area)再把字节码加载到内存中,⽽字节码⽂件只是 jvm 的⼀套指令集规范,并不能直接交给底层操作系统去执⾏,因此需要特定的命令解析器执⾏引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执⾏,⽽这个过程中需要调⽤其他语⾔的本地库接⼝(Native Interface)来实现整个程序的功能。
JVM 内存划分(重点来了)

首先,JVM 按照线程是否共享将内存首先分成两大类
线程独享区
这里面就放着
- 程序计数器(Program Counter Register)
- Java 虚拟机栈(Java Virtual Machine Stacks)
- 本地⽅法栈(Native Method Stack)
实际上,我们所说的程序计数器,栈,在jvm中从来就不止一个,线程有几个它就有几个。
线程共享区
我们所说的GC垃圾回收,JVM调优,都是在堆里。
这里面就放着
- Java 堆(Java Heap)
- ⽅法区(Methed Area)
有意思的知识点是,方法区也称之为非堆(逻辑上是堆,但物理上不属于堆)。一个jvm的堆(方法区也可以说属于堆)就只有一个,所有的线程都在堆里找数据。
图解如下
OK,我们进一步往下解剖这五大区域
- 程序计数器(Program Counter Register):当前线程所执⾏的字节码的⾏号指示器,字节码解析器的⼯作是通过改变这个计数器的值,来选取下⼀条需要执⾏的字节码指令,分⽀、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成;
- Java 虚拟机栈(Java Virtual Machine Stacks):⽤于存储局部变量表、操作数栈、动态链接、⽅法出⼝等信息;
- 本地⽅法栈(Native Method Stack):与虚拟机栈的作⽤是⼀样的,只不过虚拟机栈是服务 java ⽅法的,⽽本地⽅法栈是为虚拟机调⽤ Native ⽅法服务的;
- Java 堆(Java Heap):java 虚拟机中内存最⼤的⼀块,是被所有线程共享的,⼏乎所有的对象实例都在这⾥分配内存;
- ⽅法区(Methed Area):⽤于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
程序计数器(Program Counter Register)
用于记录下一条jvm指令的执行地址,分支、循环、跳转、异常、线程恢复等都依赖于计数器。
- 线程私有。
- 不会存在内存溢出。
Java 虚拟机栈(Java Virtual Machine Stacks)
栈中保存基本数据类型的值和对象以及基础数据的引用。
- 基本数据类型:变量在声明的时候,能够确认占用内存的大小。
- 引用数据类型:引用数据类型将值的引用存放到虚拟机栈中,而对象存放在堆内存中,引用数据类型占用 8个字节存放地址(64位jvm虚拟机,即我们jdk8 64位版本的Hotspot)。
栈帧
每一个线程都会对应一个虚拟机栈,线程中的每个方法都会创建一个栈帧,存放本次方法执行过程中所需要的所有数据。
-
局部变量:存放当前方法的局部变量,基本数据类型存值,引用数据类型存堆内存地址。
-
操作数栈:对方法中的变量提供计算的区域。
-
常量数据的引用:常量数据会存放到方法区的常量池中,不管是基本数据类型还是引用数据类型都会存放常量。
-
池的地址:方法返回值的地址 方法返回数据会存到计算机内存的寄存器中。
栈溢出(StackOverflowError)
如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出StackOverflowError异常。
解决方案(未必有用):
可以通过修改虚拟机栈的内存大小设置栈帧的最大深度,指令为:-Xss 用来修改虚拟机栈内存大小
注意:这是一个Error异常,是非常严重的,这里应该去检查你代码是不是有问题。
本地⽅法栈(Native Method Stack)
作⽤于本地⽅法执⾏的⼀块Java内存区域,用来⽀持native⽅法执⾏,native关键字说明其⽅法是一个原⽣态方法,方法对应的实现不是在当前文件,⽽是在⽤其他语⾔(如C和C++)实现的文件中。这里面存放着调用本地方法的接口。
Java 堆(Java Heap)
声明:这里以jdk8的视角讲解堆,我在写这篇之前一直分不清幸存区,新生代,老年代,伊甸园区,持久代,永久代,元空间等等名词,这一篇的目的也在于梳理这些名词,搞懂它们。
首先,堆有两种说法,第一种说堆等于堆内存+方法区,第二种说法方法区不属于堆,下面开始展开讲解。
下面的内容都是我查看大量资料所见的,希望大家坚定相信!
ok,我们先梳理这两种说法,看看是否要将堆和方法区分开讲解!
元空间
实际上为大家造成两种奇怪说法原因在于,方法区在设计上确实属于堆的一部分,方法区其实就是大家所说的元空间,没错,实际上大家一直争议的元空间,就是方法区,元空间就是方法区的具体实现!
方法区属于堆,但是元空间不属于堆,这也就是著名的非堆理论(方法区逻辑上属于堆,物理上不属于堆),堆的空间(约为系统内存的四分之一),元空间的被认为是无限大,内存多大它就多大,堆又怎么可能放得下元空间!
持久代已废弃,以后只有元空间。从物理角度来说,方法区不属于堆。
说完了结论,所以下文将把堆和方法区分开。
堆的划分
以下皆为物理划分,可以通过代码实验。
堆大小 = 年轻代 + 老年代
年轻代 = eden space (新生代,官方说法就是伊甸园区) + from survivor(来自幸存区) + to survivor(前往幸存区)清晰可见
我们包含的名词有新生代,老年代,年轻代,伊甸园区,幸存区,元空间。
JVM线程共享区 = 堆 + 方法区
堆 = 年轻代 + 老年代
方法区 = 元空间
年轻代 = 新生代 + 幸存区
新生代 = 伊甸园区
幸存区 = form幸存区 + to幸存区
所谓的垃圾回收,就在堆里大量进行,对象在form幸存区和to幸存区来回跳跃,每来回一次,年龄+1,加到15时就可以进老年代了。 对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
堆溢出Out of Memory
堆参数(-Xmx 与-Xms)
垃圾回收GC(Garbage Collection)
主要目的:防止内存溢出 Out of Memory
垃圾回收算法
- 标记-清除算法:标记⽆⽤对象,然后进⾏清除回收。缺点:效率不⾼,⽆法清除垃圾碎⽚。
- 标记-整理算法:标记⽆⽤对象,让所有存活的对象都向⼀端移动,然后直接清除掉端边界以外的内存。
- 复制算法:按照容量划分⼆个⼤⼩相等的内存区域,当⼀块⽤完的时候将活着的对象复制到另⼀块上,然后再把已使⽤的内存空间⼀次清理掉。缺点:内存使⽤率不⾼,只有原来的⼀半。
- 分代算法:根据对象存活周期的不同将内存划分为⼏块,⼀般是新⽣代和⽼年代,新⽣代基本采⽤复制算法,⽼年代采⽤标记整理算法。
⽅法区(Methed Area)
1. 元空间就是方法区的具体实现
2. 大名鼎鼎的常量池就在方法区,不过,JDK8的HotSpot VM中,运行时常量池在方法区,而字符串常量池被移到了堆中了。此时常量池存储的就是字符串的引用了。
方法区会存储类信息、静态变量、常量(JDK8 之后不存放字符串常量)、本地机器指令。
JVM调优的参数
-Xms2g 初始化推⼤⼩为 2g;
-Xmx2g 堆最⼤内存为 2g;
-XX:NewRatio=4 设置年轻的和⽼年代的内存⽐例为 1:4;
-XX:SurvivorRatio=8 设置新⽣代 Eden 和 Survivor ⽐例为 8:2;
-XX:+UseParNewGC 指定使⽤ ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC 指定使⽤ ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC 指定使⽤ CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC 开启打印gc信息;
-XX:+PrintGCDetails 打印gc详细信息。 -
相关阅读:
Java学习笔记(三十)
云栖大会,一场边缘云计算的「超前瞻」之约
leetcode 1668. 最大重复子字符串
AI低代码维格云甘特视图怎么用?
Linux用户空间与内核空间通信(Netlink通信机制)
数据库事务相关问题
Vue中使用js-audio-recorder插件实现录音功能并实现上传Blob数据到SpringBoot后台接口
红黑树刷题(上)
自学黑客(网络安全),一般人我劝你还是算了吧
阿里云张新涛:连接产业上下游,构建XR协作生态
- 原文地址:https://blog.csdn.net/weixin_43982359/article/details/126963806