-
深度前馈网络(三)、隐藏单元
参考 python的单元测试代码编写流程 - 云+社区 - 腾讯云
目录
隐藏单元的设计是前馈神经网络一个独有的问题:该如何选择隐藏单元的类型,这些隐藏单元用在模型的隐藏层中。隐藏单元的设计是一个非常活跃的领域,并且还没有许多明确的指导性理论原则。
整流线性单元是隐藏层单元几号的默认选择。许多其他类型的隐藏单元也是可用的。决定何时使用那种类型的隐藏单元是困难的事(尽管整流线性单元是一个可接受的选择)。我们这里描述对于每种隐藏单元的一些基本直觉。这些直觉可用用来建议我们何时尝试一些单元。通常不可能预先预测出哪种隐藏单元工作做的好。设计过程充满了试验和错误,先直觉认为某种隐藏单元可能表现良好,然后用它组成神经网络进行训练,最后用试验集来评估它的性能。
这里列出的一些隐藏单元可能并不是在所有的输入点上都是可微的。例如,整流线性单元
 在
在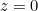 处不可微。这似乎使得g对于基于梯度的学习算法无效。在实践中,梯度下降对这些机器学习模型仍然表现得足够好。部分原因是神经网络训练算法通常不会达到代价函数的局部最小值,而是仅仅显著的减少它的值。因为我们不再期望训练能够实际达到梯度为0的点,所以代价函数的最小值对应于梯度未定义的点是可接受的。不可微的隐藏单元通常是在少数点上不可微。一般来说,函数
处不可微。这似乎使得g对于基于梯度的学习算法无效。在实践中,梯度下降对这些机器学习模型仍然表现得足够好。部分原因是神经网络训练算法通常不会达到代价函数的局部最小值,而是仅仅显著的减少它的值。因为我们不再期望训练能够实际达到梯度为0的点,所以代价函数的最小值对应于梯度未定义的点是可接受的。不可微的隐藏单元通常是在少数点上不可微。一般来说,函数 具有左导数和右导数,左导数定位为在紧邻在
具有左导数和右导数,左导数定位为在紧邻在 左边的函数的斜率,右导数定义为紧邻在右边的函数的斜率。只有当函数在
左边的函数的斜率,右导数定义为紧邻在右边的函数的斜率。只有当函数在 处的左导数和右导数都有定义并且相等时,函数在点处才是可微的。神经网络中用到的函数通常对左导数和右导数都有定义。在
处的左导数和右导数都有定义并且相等时,函数在点处才是可微的。神经网络中用到的函数通常对左导数和右导数都有定义。在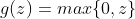 的情况下,在
的情况下,在z = 0 " role="presentation">处的左导数是0,右导数是1。神经网络训练的软件实现通常返回左导数和右导数的其中一个,而不是报告导数未定义或产生一个错误。这可以观察到在数字计算机上基于梯度的优化总是受到数值误差的影响来启发式地给出理由。当一个函数要被计算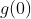 时,底层值真正为0是不大可能的。相对的,它可能是被舍入为0的一个小量
时,底层值真正为0是不大可能的。相对的,它可能是被舍入为0的一个小量 。在某些情况下,理论上有更好的理由,但这通常对神经网络的训练并不适用。重要的是,在实践中,我们可以放心的忽略下面描述的隐藏单元激活函数的不可微性。除非另有说明,大多数的隐藏单元都可以忽略下面描述的隐藏单元激活函数的不同微性。
。在某些情况下,理论上有更好的理由,但这通常对神经网络的训练并不适用。重要的是,在实践中,我们可以放心的忽略下面描述的隐藏单元激活函数的不可微性。除非另有说明,大多数的隐藏单元都可以忽略下面描述的隐藏单元激活函数的不同微性。 1、整流线性单元及其扩展
整流线性单元使用激活函数
。整流线性单元易于优化,因为它们和线性单元非常相似。线性单元和整流线性单元的唯一区别在于整流线性单元在其一半的定义域上输出为零。这使得只要整流线性单元处于激活状态。它的导数都能报出较大。它的梯度不但大而且一致。整流操作的二阶导数几乎处处为0,并且在整流线性单元处于激活状态时,它的一阶导数处处为1。这意味着相比于引入二阶相应的激活函数来说,它的梯度方向对于学习来说更加有用。整流线性单元通常作用于仿射变换之上:
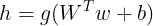
当初始化仿射变换的参数时,可以将
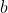 的所有元素设置成一个小的正值,例如0.1。这使得整流线性单元很可能初始化时就对训练集中的大多数输入呈现激活状态,并且允许导数通过。有很多整流线性单元的扩展存在。大多数这些扩展的表现比得上整流线性单元,并且偶尔表现得更好。整流线性单元的一个缺陷是它们不能通过基于梯度的方法学习那些使得他们激活为零的样本。整流线性单元的各种扩展保证了它们能在各个位置都接收梯度。
的所有元素设置成一个小的正值,例如0.1。这使得整流线性单元很可能初始化时就对训练集中的大多数输入呈现激活状态,并且允许导数通过。有很多整流线性单元的扩展存在。大多数这些扩展的表现比得上整流线性单元,并且偶尔表现得更好。整流线性单元的一个缺陷是它们不能通过基于梯度的方法学习那些使得他们激活为零的样本。整流线性单元的各种扩展保证了它们能在各个位置都接收梯度。整流线性单元的3个扩展基于当
z i < 0 " role="presentation">时使用的一个非零的斜率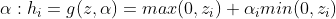 。绝对值整流固定
。绝对值整流固定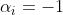 来得到
来得到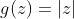 。它用于图像中的对象识别,其中寻找在输入照明极性反转下不变的特征是由意义的。整流线性单元的扩展比这个应用更广泛。渗漏整流线性单元(Leaky ReLU)将
。它用于图像中的对象识别,其中寻找在输入照明极性反转下不变的特征是由意义的。整流线性单元的扩展比这个应用更广泛。渗漏整流线性单元(Leaky ReLU)将 固定成一个类似0.01的小值,参数化整流线性单元(parametric ReLU)或者PReLU将作为学习的参数。
固定成一个类似0.01的小值,参数化整流线性单元(parametric ReLU)或者PReLU将作为学习的参数。maxout单元进一步扩展了整流线性单元。maxout单元将
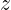 划分为每组具有
划分为每组具有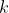 个值的组,而不是使用作用于每个元素的函数
个值的组,而不是使用作用于每个元素的函数 。每个maxout单元输出每组中的最大元素:
。每个maxout单元输出每组中的最大元素:g ( z ) i = m a x j ∈ G ( i ) z j 这里
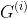 是组i的输入索引集
是组i的输入索引集 。这里提供了一种方法来学习对输入x空间中多个方向响应的分段线性函数。
。这里提供了一种方法来学习对输入x空间中多个方向响应的分段线性函数。maxout单元可以学习具有多达
段的分段线性的凸函数。maxout函数因此可以视为学习激活函数本身,而不仅仅是单元之间的关系。使用足够大的,maxout单元可以以任意的精确度来近似任何凸函数。特别地,具有两块的maxout层可以学习实现和传统层相同的输入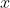 的函数,这些传统层可以使用整流线性激活函数、绝对值整流、渗漏整流线性单元或参数化整流线性单元,或者可以学习实现与这些都不同的函数。maxout层的参数化当然将于这些层不同,所以即使是maxout学习实现和其他种类的层是相同的x的函数这种情况下,学习的机理也是不一样的。
的函数,这些传统层可以使用整流线性激活函数、绝对值整流、渗漏整流线性单元或参数化整流线性单元,或者可以学习实现与这些都不同的函数。maxout层的参数化当然将于这些层不同,所以即使是maxout学习实现和其他种类的层是相同的x的函数这种情况下,学习的机理也是不一样的。每个maxout单元现在由
个权重向量来参数化,而不仅仅是一个,所以maxout单元通常比整流线性单元需要更多的正则化。如果训练集很大并且每个单元的块数保持很低的话,它们可以在没有正则化的情况下工作得不错。maxout单元还有一些其他的优点。在某些情况下,要求更少的参数可以获得一些统计和计算上的优点。具体来说,如果由n个不同的线性滤波器描述的特征可以在不损失信息的情况下,用每一组k个特征的最大值来概括的话,那么下一层可以获得k倍更少的权重数。因为每个单元有多个滤波器驱动,maxout单元具有一些冗余来帮助它们抵抗一种被称为灾难遗忘的现象,这个现象是说神经网络忘记了如何执行它们过去训练的任务。整流线性单元和它们的这些扩展都是基于一个原则,那就是如果它们的行为更接近线性,那么模型更容易优化。使用线性行为更容易优化的一般性原则同样也适用于除深度线性网络以外的情景。循环网络可以从序列中学习并产生状态饿输出的序列。当训练它们时,需要通过一些时间步来传播信息,当其中包含一些线性计算(具有大小接近1的某些方向导数)时,这会更容易。作为性能最好的循环网络结构之一,LSTM通过求和在时间上传播信息,这是一种特别直观的线性激活函数。
2、logistic sigmoid与双曲正切函数
在引入整流线性单元之前,大多数神经网络使用logistic sigmoid激活函数
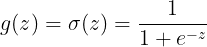
或者是双曲正切激活函数
g ( z ) = t a n h ( z ) " role="presentation">这些激活函数紧密相关,因为
 。
。我们已经看过sigmoid单元作为输出单元用来二值型变量取值为1的概率。与分段线性单元不同,sigmoid单元在其最大部分定义域内都饱和------当z取绝对值很大的正值时,它们饱和到一个高值,当z取绝对值很大的负值时,它们饱和到一个低值,并且仅仅当z接近0时它们才会对输入强烈敏感。sigmoid单元的广泛饱和性会使得基于梯度的学习变得非常困难。因为这个原因,现在不鼓励将它们作为前馈神经网格中的隐藏单元。当使用一个合格的代价函数来抵消sigmoid的饱和性时,它们作为输出单元可以与基于梯度的学习相兼容。
当必须要使用sigmoid激活函数时,双曲正切激活函数通常要比logistic sigmoid函数表现更好。在tanh(0)=0而
 的意义上,它更像是单位函数。因为tanh在0附近与单位函数类似,训练深层神经网络的激活能够被保持地很小。这使得训练tanh网络更加容易。sigmoid激活函数在除了前馈神经网络以外的情景中更为常见。循环网络,许多概率模型以及一些自编码器有一些额外的要求使得它们不能使用分段线性激活函数,并且使得sigmoid单元更具有吸引力,尽管它存在饱和性的问题。
的意义上,它更像是单位函数。因为tanh在0附近与单位函数类似,训练深层神经网络的激活能够被保持地很小。这使得训练tanh网络更加容易。sigmoid激活函数在除了前馈神经网络以外的情景中更为常见。循环网络,许多概率模型以及一些自编码器有一些额外的要求使得它们不能使用分段线性激活函数,并且使得sigmoid单元更具有吸引力,尽管它存在饱和性的问题。3、其他隐藏单元
也存在许多其他单种类的隐藏单元,但它们明显不常用。一般来说,很多种类的可微函数都表现得很好。许多未发布的激活函数与流行的激活函数表现得一样好。为了提供一个具体的例子,作者在MNIST数据集上使用
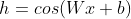 测试了一个前馈网络,并且获得了小于1%的误差率,这可以与更为传统的激活函数获得的结果相媲美。在新技术的研究和开发期间,通常会测试许多不同的激活函数,并且会发现许多标准方法变体表现非常好。这意味着,通常新的隐藏单元表现大致相当,那么他们是非常常见的,不会引起别人的兴趣。列出文献中出现的所有隐藏单元类型是不切实际的。我们只对一些特别有用和独特的类型进行强调。其中一种是完全没有激活函数,也可以认为这是使用单位函数作为激活函数的情况。我么已经看过线性单元可以作为神经网络的输出。它也可以用作隐藏单元。如果神经网络的每一层都仅由线性变换组成,那么网络作为一个整体也将是线性的。然而,神经网络的一些层是纯线性也是可以接受的。考虑具有n个输入和p个输出的神经网络层
测试了一个前馈网络,并且获得了小于1%的误差率,这可以与更为传统的激活函数获得的结果相媲美。在新技术的研究和开发期间,通常会测试许多不同的激活函数,并且会发现许多标准方法变体表现非常好。这意味着,通常新的隐藏单元表现大致相当,那么他们是非常常见的,不会引起别人的兴趣。列出文献中出现的所有隐藏单元类型是不切实际的。我们只对一些特别有用和独特的类型进行强调。其中一种是完全没有激活函数,也可以认为这是使用单位函数作为激活函数的情况。我么已经看过线性单元可以作为神经网络的输出。它也可以用作隐藏单元。如果神经网络的每一层都仅由线性变换组成,那么网络作为一个整体也将是线性的。然而,神经网络的一些层是纯线性也是可以接受的。考虑具有n个输入和p个输出的神经网络层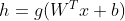 。我们可以用两层来代替它,一层使用权重矩阵U,另一层使用权重矩阵V。如果第一层没有激活函数,那么我们对基于W的原始层的权重矩阵进行因式分解。分解分解方法是计算
。我们可以用两层来代替它,一层使用权重矩阵U,另一层使用权重矩阵V。如果第一层没有激活函数,那么我们对基于W的原始层的权重矩阵进行因式分解。分解分解方法是计算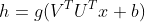 。如果
。如果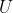 产生了g个输出,那么U和V一起仅包含
产生了g个输出,那么U和V一起仅包含 个参数,而W包含np个参数。如果很小,这可以在很大程度上节省参数。这是以将线性变换约束为低秩的代价函数来实现,但这些低秩关系往往是足够的。线性隐藏单元因此提供了一种减少网络中参数数量的有效方法。
个参数,而W包含np个参数。如果很小,这可以在很大程度上节省参数。这是以将线性变换约束为低秩的代价函数来实现,但这些低秩关系往往是足够的。线性隐藏单元因此提供了一种减少网络中参数数量的有效方法。softmax单元是另外一种经常用作输出的单元,但有时也可以用作隐藏单元。softmax单元很自然地表示具有k个可能值的离散型随机变量的概率分布,所以它们可以用作一种开关。这些类型的隐藏单元通常仅用于明确地学习操作内存的高级结构中。其他一些常见的隐藏单元类型包括:
径向基函数:
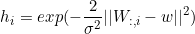 。这个函数在
。这个函数在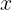 接近模板
接近模板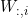 时更加活跃。因为它对大部分x都饱和到0,因此很难优化。
时更加活跃。因为它对大部分x都饱和到0,因此很难优化。softplus函数:
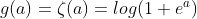 。这是整流线性单元的平滑版本,softplus和整流线性单元,发现后者的结果更好。通常不鼓励使用softplus函数。softplus表明隐藏单元类型的性能可能是非常反直觉的------因为它处处可导或者因为它不完全饱和,人们可能希望它具有优于整流线性单元的点,但根据经验来看,它并没有。
。这是整流线性单元的平滑版本,softplus和整流线性单元,发现后者的结果更好。通常不鼓励使用softplus函数。softplus表明隐藏单元类型的性能可能是非常反直觉的------因为它处处可导或者因为它不完全饱和,人们可能希望它具有优于整流线性单元的点,但根据经验来看,它并没有。硬双曲正切函数:它的形状和tanh以及整流线性单元类似,但是不同于后者,它是有界的,
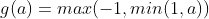 。
。noisy ReLUs:可将其包含Gaussian noise得到noisy ReLUs,
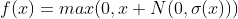 ,常用来在机器视觉任务里的restricted Boltzmann machines中。
,常用来在机器视觉任务里的restricted Boltzmann machines中。leaky ReLUs:当unit没有被激活时,允许小的非零的gradient

-
相关阅读:
【云备份|| 日志 day5】文件热点管理模块
Jnpf 快速开发平台框架源码 3.4全新版本上线 java+Netcore版本 旗舰版企业版
001:你好Direct 2D! 在对话框中初次使用D2D
Temu是否需要压货?Temu售后政策——站斧浏览器
Ansible最佳实践之委派任务和事实
java计算机毕业设计互联网校园家教兼职平台MyBatis+系统+LW文档+源码+调试部署
基于云平台的智能变电站远程监控系统
关于swiper插件在vue2的使用
Selenium自动化测试 —— 通过cookie绕过验证码的操作!
再来一次,新技术搞定老业务「GitHub 热点速览 v.22.44」
- 原文地址:https://blog.csdn.net/weixin_36670529/article/details/97497791