-
Spark性能调优之广播变量
一、背景
举例来说,(虽然是举例,但是基本都是用我们实际在企业中用的生产环境中的配置和经验来说明的)。50个executor,1000个task。一个map,10M。默认情况下,1000个task,1000份副本。10G的数据,网络传输,在集群中,耗费10G的内存资源。
如果使用了广播变量。50个execurtor,50个副本。500M的数据,网络传输,而且不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的bockmanager上拉取变量副本,网络传输速度大大增加;500M的内存消耗。10000M,500M,20倍。20倍~以上的网络传输性能消耗的降低;20倍的内存消耗的减少。
对性能的提升和影响,还是很客观的。虽然说,不一定会对性能产生决定性的作用。比如运行30分钟的spark作业,可能做了广播变量以后,速度快了2分钟,或者5分钟。但是一点一滴的调优,积少成多。最后还是会有效果的。
没有经过任何调优手段的spark作业,16个小时;三板斧下来,就可以到5个小时;然后非常重要的一个调优,影响特别大,shuffle调优,2-3个小时;应用了10个以上的性能调优的技术点,JVM+广播,30分钟。16小时~30分钟。
二、流程图示
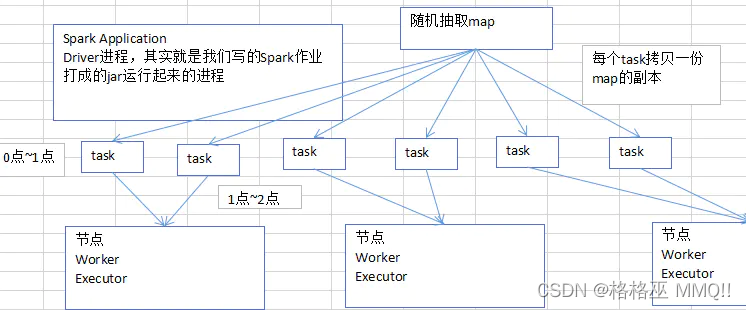
传统task分发示意图- 1
如果说,task使用大变量(1m~100m),明知道会导致性能出现恶劣的影响。那么我们怎么来解决呢?
广播,Broadcast,将大变量广播出去。而不是直接使用Question
这种默认的,task执行的算子中,使用了外部的变量,每个task都会获取一份变量的副本,有什么缺点呢?在什么情况下,会出现性能上的恶劣的影响呢?
Answer
1、map,本身是不小,存放数据的一个单位是Entry,还有可能会用链表的格式的来存放Entry链条。所以map是比较消耗内存的数据格式。2、比如,map是1M。总共,你前面调优都调的特好,资源给的到位,配合着资源,并行度调节的绝对到位,1000个task。大量task的确都在并行运行。
3、这些task里面都用到了占用1M内存的map,那么首先,map会拷贝1000份副本,通过网络传输到各个task中去,给task使用。总计有1G的数据,会通过网络传输。网络传输的开销,不容乐观啊!!!网络传输,也许就会消耗掉你的spark作业运行的总时间的一小部分。
4、map副本,传输到了各个task上之后,是要占用内存的。1个map的确不大,1M;1000个map分布在你的集群中,一下子就耗费掉1G的内存。对性能会有什么影响呢?
5、不必要的内存的消耗和占用,就导致了,你在进行RDD持久化到内存,也许就没法完全在内存中放下;就只能写入磁盘,最后导致后续的操作在磁盘IO上消耗性能;
6、你的task在创建对象的时候,也许会发现堆内存放不下所有对象,也许就会导致频繁的垃圾回收器的回收,GC。GC的时候,一定是会导致工作线程停止,也就是导致Spark暂停工作那么一点时间。频繁GC的话,对Spark作业的运行的速度会有相当可观的影响。
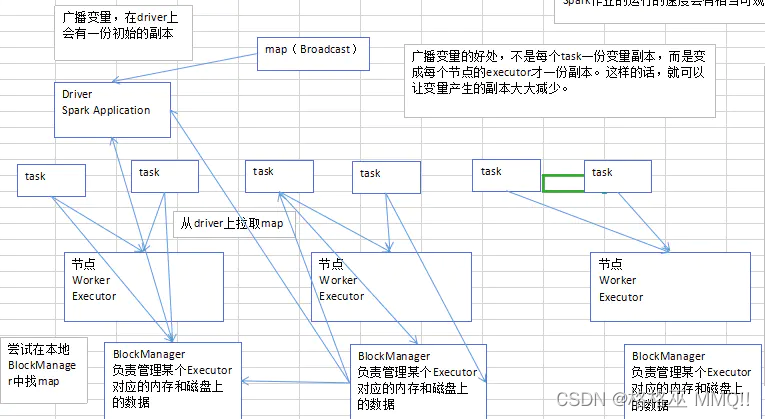
广播变量分发Task- 1
Answer
广播变量,初始的时候,就在Drvier上有一份副本。
task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,那么就从Driver远程拉取变量副本,并保存在本地的BlockManager中;此后这个executor上的task,都会直接使用本地的BlockManager中的副本。executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本,举例越近越
BlockManager,也许会从远程的Driver上面去获取变量副本;也有可能从距离比较近的其他节点的Executor的BlockManager上去获取。
-
相关阅读:
【教程】Derby数据库安装与使用
JavaScript 65 JavaScript 类 65.2 JavaScript 类继承
免费Scrum管理工具-Leangoo领歌
华为OD机试 - 最长的指定瑕疵度的元音子串 - 正则表达式(Java 2023 B卷 200分)
大势浏览器DasViewer里面的查询和选择功能,如何实现与矢量数据关联?
【SpringCloud微服务实战02】Ribbon 负载均衡
复现一篇简单的基于滑模控制的扩张状态观测器LESO
上周热点回顾(3.14-3.20)
Linux:1.进程介绍+2.Linux父子进程+3.终止进程kill和killall+4.查看进程树pstree+5.service服务管理
[深度学习]使用python转换pt并部署yolov10的tensorrt模型封装成类几句完成目标检测加速任务
- 原文地址:https://blog.csdn.net/weixin_43214644/article/details/126931474