-
pytorch dataloader使用注意
我一直构造pytorch的Dataset时,传入的数据必须是tensor
,例如from torch.utils.data import Dataset import torch import numpy as np class TensorDataset(Dataset): # TensorDataset继承Dataset, 重载了__init__, __getitem__, __len__ # 实现将一组Tensor数据对封装成Tensor数据集 # 能够通过index得到数据集的数据,能够通过len,得到数据集大小 def __init__(self, data_tensor, target_tensor): self.data_tensor = data_tensor self.target_tensor = target_tensor def __getitem__(self, index): return self.data_tensor[index], self.target_tensor[index] def __len__(self): return self.data_tensor.shape[0] # size(0) 返回当前张量维数的第一维 # 生成数据 ################################################# ################################################# ################################################# data_tensor = torch.randn(4, 3) # 4 行 3 列,服从正态分布的张量 print(data_tensor) target_tensor = torch.rand(4) # 4 个元素,服从均匀分布的张量 print(target_tensor) # 将数据封装成 Dataset (用 TensorDataset 类) tensor_dataset = TensorDataset(data_tensor, target_tensor) ################################################# ################################################# ################################################# ################################################# print("===================================================") ################################################# loader =torch.utils.data.DataLoader( # 从数据库中每次抽出batch size个样本 dataset = tensor_dataset, # torch TensorDataset format batch_size = 2, # mini batch size shuffle=True, # 要不要打乱数据 (打乱比较好) num_workers=2, # 多线程来读数据 ) def show_batch(): for step, (batch_x, batch_y) in enumerate(loader): print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y)) show_batch()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
结果如下
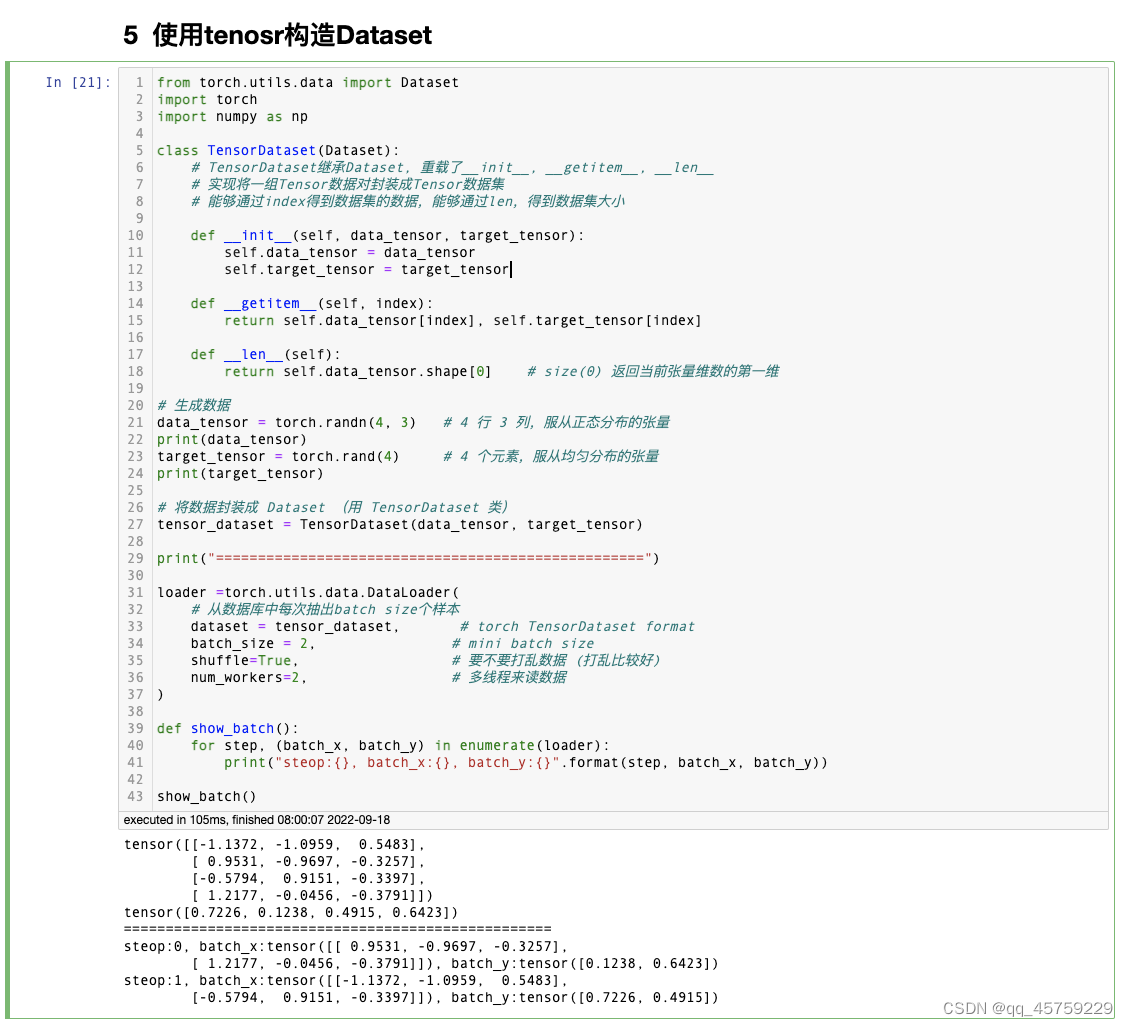 可以看到,data_tensor是首先创建的torch的tensor,但是其实是不必要的,pytorch可以给你自动转换
可以看到,data_tensor是首先创建的torch的tensor,但是其实是不必要的,pytorch可以给你自动转换from torch.utils.data import Dataset import torch import numpy as np class TensorDataset(Dataset): # TensorDataset继承Dataset, 重载了__init__, __getitem__, __len__ # 实现将一组Tensor数据对封装成Tensor数据集 # 能够通过index得到数据集的数据,能够通过len,得到数据集大小 def __init__(self, data_tensor, target_tensor): self.data_tensor = data_tensor self.target_tensor = target_tensor def __getitem__(self, index): return self.data_tensor[index], self.target_tensor[index] def __len__(self): return self.data_tensor.shape[0] # size(0) 返回当前张量维数的第一维 # 生成数据 data_tensor = np.random.randn(4,3) # 4 行 3 列,服从正态分布的张量 print(data_tensor) target_tensor = np.random.randn(4) # 4 个元素,服从均匀分布的张量 print(target_tensor) # 将数据封装成 Dataset (用 TensorDataset 类) tensor_dataset = TensorDataset(data_tensor, target_tensor) print("===================================================") loader =torch.utils.data.DataLoader( # 从数据库中每次抽出batch size个样本 dataset = tensor_dataset, # torch TensorDataset format batch_size = 2, # mini batch size shuffle=True, # 要不要打乱数据 (打乱比较好) num_workers=2, # 多线程来读数据 ) def show_batch(): for step, (batch_x, batch_y) in enumerate(loader): print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y)) show_batch()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
结果如下
 可以看到,我在构造Dataset传进去的时候numpy,然后使用Dataset构造DataLoader,但是我迭代dataloader时这个访问的batch数据自己变成了tensor类型的数据,连显式转换都不用了,可以作为一个小知识点,记录一下
可以看到,我在构造Dataset传进去的时候numpy,然后使用Dataset构造DataLoader,但是我迭代dataloader时这个访问的batch数据自己变成了tensor类型的数据,连显式转换都不用了,可以作为一个小知识点,记录一下 -
相关阅读:
如何自学网络安全?零基础入门看这篇就够了(含路线图)_网络安全自学
golang中的iota
微前端——qiankun(乾坤)实例
JS贪吃蛇源码附注释
C++语言学习笔记Day1-C++概述
LabVIEW在 XY Graph中选择一组点
ospf多区域原理和配置
AWS】在EC2上创建root用户,并使用root用户登录
Laravel 框架数据库配置&构造器的查询.分块.聚合 ⑤
ffmpeg从一个视频中提取音频
- 原文地址:https://blog.csdn.net/qq_45759229/article/details/126913565
