-
IJCAI22:Language Models as Knowledge Embeddings
研究问题
同时利用结构信息和文本信息,在对比学习框架下提升长尾实体的表示
背景动机
目前知识图嵌入有两种计算方法,即基于结构的方法和基于描述的方法
- 基于结构的方法如TransE和RotatE,可以保存知识图谱的结构信息,并对各种属性进行建模。其缺陷在于无法对大量结构信息匮乏的长尾实体进行建模,对RotatE在WN18RR数据集上的统计如下图所示

- 基于描述的方法如DKRL和KEPLER,通过使用语言模型编码实体的描述来获得表示,因而具有inductive (zero-shot) 的能力。但这些方法在效果上比不上基于结构的方法,原因是语言模型的效率过低,限制了负采样的规模,而这对模型的性能很重要。另外并不是所有实体都能拥有文本描述,直接丢弃这部分实体的操作忽视了它们的结构信息
模型方法
LMKE基础设定
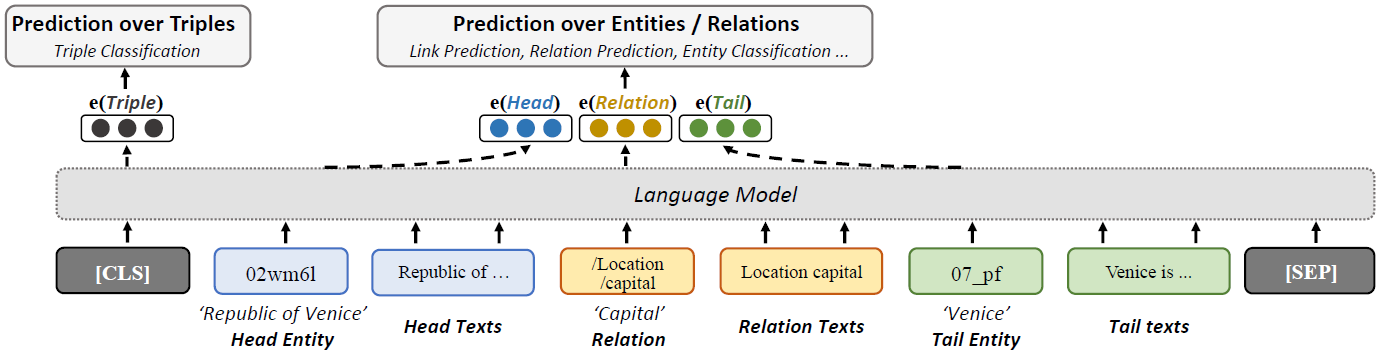
给定三元组 h , r , t h, r, t h,r,t,其描述分别为 S h , S r , S t S_h, S_r, S_t Sh,Sr,St,其中 s e = ( x 1 , … , x n e ) s_e=\left(x_1, \ldots, x_{n_e}\right) se=(x1,…,xne)为token的序列。输入可以表示为 s u = ( h , s h , r , s r , t , s t ) = ( h , x 1 h , … , x n h h , r , x 1 r , … , x n r r , t , x 1 t , … , x n t t ) s_u=\left(h, s_h, r, s_r, t, s_t\right)=\left(h, x_1^h, \ldots, x_{n_h}^h, r, x_1^r, \ldots, x_{n_r}^r, t, x_1^t, \ldots, x_{n_t}^t\right) su=(h,sh,r,sr,t,st)=(h,x1h,…,xnhh,r,x1r,…,xnrr,t,x1t,…,xntt),在开头和末尾分别添加[CLS]和[SEP]标识。将 s u s_u su作为一个整体输入预训练语言模型,分别得到三元组各部分的嵌入表示 h , r , t ∈ R d \mathbf{h}, \mathbf{r}, \mathbf{t} \in \mathbb{R}^d h,r,t∈Rd以及三元组整体的表示 u \mathbf{u} u,三元组成立的概率为 p ( u ) = σ ( w u + b ) p(u)=\sigma(\mathbf{w} \mathbf{u}+b) p(u)=σ(wu+b)。
在执行链路预测任务时,上述方法的缺陷在于要为每一个负样本生成整个三元组的表示,使得整体计算复杂度过高。

更加高效的对比学习框架:C-LMKE

在链路预测任务中,将给定的头实体和关系及其文本描述视为查询q,将要预测的尾实体视为键k,一个batch内的原始qk对视为正样本对,同batch内的其他三元组的k与q视为负样本对。在计算相似度时,考虑到1-N关系的存在,没有使用通常的余弦相似度,而是用了MLP实现。

其中 d = [ log ( d q + 1 ) ; log ( d k + 1 ) ] \mathbf{d}=\left[\log \left(d_q+1\right) ; \log \left(d_k+1\right)\right] d=[log(dq+1);log(dk+1)]通过度的对数来考虑结构信息,有点奇怪最终的损失函数如下,好像和之前基于负采样的损失函数看上去没有很大区别

实验
最后两行的效果确实提升非常大,在FB数据集上,是基于描述的方法第一次超过基于结构的方法。另外,所有基于描述的方法在WN数据集上都显著超越基于结构的方法,因为WN数据集中的实体本来就是词,根据文本就能推断出它们之间的关系。而FB数据集就得同时依赖文本和结构信息。

三元组分类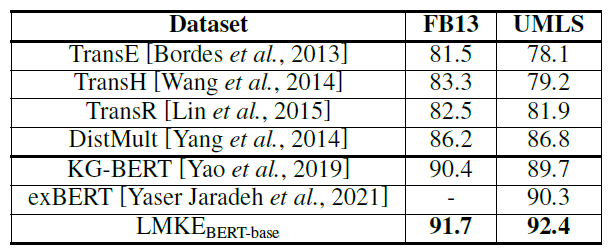
不同度的实体的效果比较,可以看到度数较小的长尾实体效果显著提升了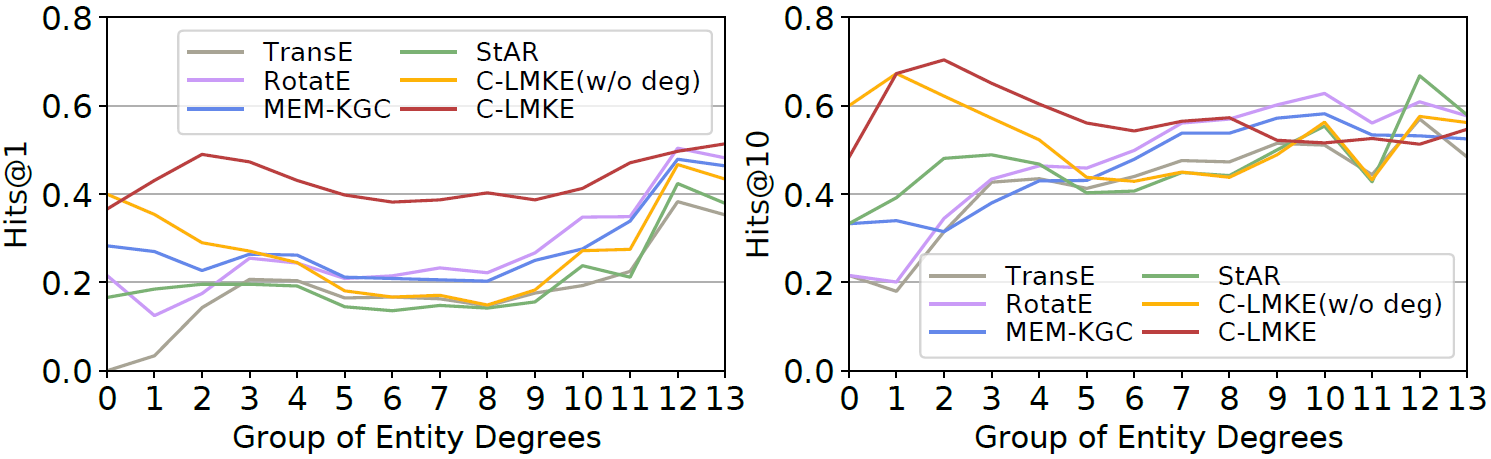
负样本对越多,效果越好
总结
虽然说是对比学习,但感觉对正负样本对的定义有点奇怪,其实还是负采样,跟之前的方法没有本质区别,最大的创新点是把头实体加关系、以及尾实体分别用文本表示了
看了一下github上放出来的代码,运行时间有点吓人,跑一次模型需要两天以上

- 基于结构的方法如TransE和RotatE,可以保存知识图谱的结构信息,并对各种属性进行建模。其缺陷在于无法对大量结构信息匮乏的长尾实体进行建模,对RotatE在WN18RR数据集上的统计如下图所示
-
相关阅读:
buuctf_练[CISCN2019 华东南赛区]Web4
STM8单片机在医疗设备中的应用和优势
C++中的类的继承的构造函数和析构函数
Unity可视化Shader工具ASE介绍——3、ASE的Shader类型介绍
分析并实现Android中的MVC、MVP架构模式
中创算力:打造区块链产业生态,助力郑州创建国家级区块链先导区
电脑入门:如何进入路由器(TP-LINK,PPPoE)设置界面
30 C++ 预处理器
C语言求数组最大值和最小值、总和、平均值以及数组正序和逆序的输出
C++小坑:问号表达式的输出
- 原文地址:https://blog.csdn.net/jining11/article/details/126886227