-
<Linux>进程地址空间
目录
一、认识概念
0.验证地址空间排布(打印各种地址 --- 进程打印!!!)
Linux环境下的 验证代码如下:
先解释一下Makefile文件:$@代表mytest $^代表:后面的文件
- mytest:mytest.c
- gcc -o $@ $^
- 1 #include
- 2 #include
- 3 #include
- 4
- 5 int g_unval;
- 6 int g_val = 100;
- 7
- 8 int main(int argc, char* argv[], char* env[])
- 9 {
- 10 int i = 0;
- 11
- 12 printf("code addr: %p\n", main); //代码段
- 13 printf("init global addr: %p\n", &g_val); //初始化全局区
- 14
- 15 printf("uninit global addr: %p\n", &g_unval); //未初始化全局区
- 16
- 17 char* heap_mem = (char*)malloc(10);
- 18 printf("heap addr: %p", heap_mem); //堆区
- 19 printf("stack addr: %p\n", &heap_mem);
- 20
- 21 for (i = 0; i22 {23 printf("argc[%d]: %p\n", i, argv[i]);24 }2526 for (i = 0; env[i]; ++i)27 {28 printf("env[%d]: %p\n", i, env[i]);29 }3031 return 0;32 }

(扩展问题:mallco开辟空间后,free时,怎么知道我们需要释放的空间大小呢?)
原因:malloc在申请空间时会多申请几个字节的空间,用来存放开辟空间的信息。
代码区和字符常量区的属性是一样的(只读),都放在一个地址区域;
(补充内容)
用户空间 vs 内核空间
在32位下,一个进程的地址空间的取值范围是0x0000 0000 ~ 0xFFFF FFFF
[0, 3G]:用户空间
[3G,4G]:内核空间
Linux vs windows
上面的验证代码,在window下会跑出不一样的结果,所以默认在Linux下有效。
二、什么是地址空间
程序打印地址,是进程打印地址,是程序运行之后打印的地址。
每一个进程都有一个地址空间!
讲个故事例子:
有一个大富翁 有10亿美金 还有3个私生子。大富翁给每一个私生子都画10亿美金的饼,大富翁面对每一个私生子都需要画对应的饼。
我们将其对应起来大富翁 -- 操作系统,10亿美金 -- 地址空间,私生子 -- 进程。
那么地址空间就相当于操作系统给进程画的大饼,是一个虚拟的空间。
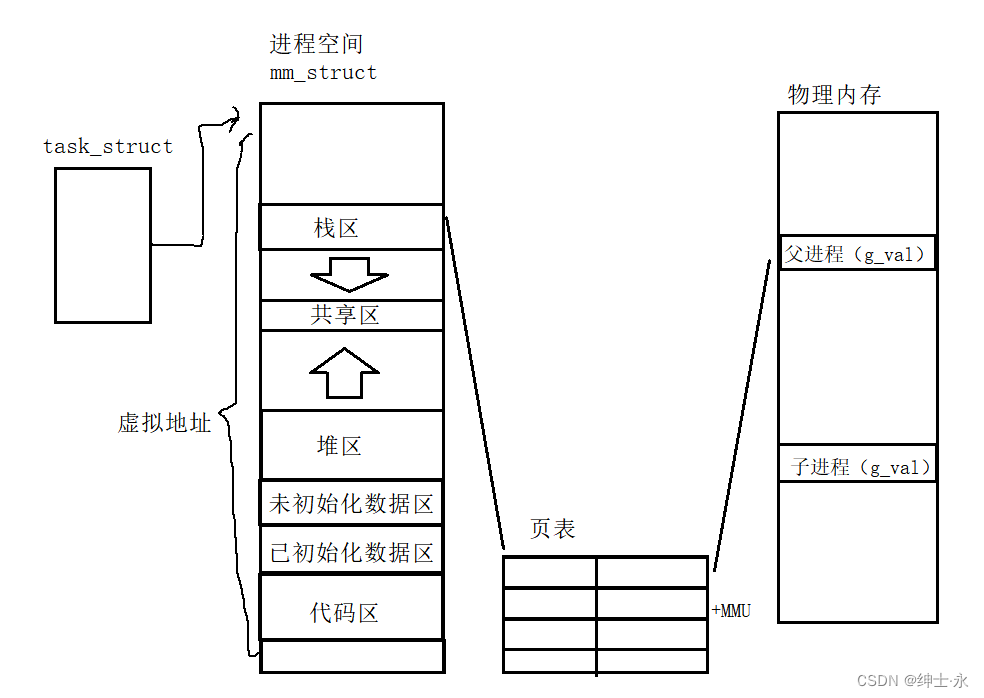
内核中的地址空间本质也一定是一种数据结构。
将来要和一个特定的进程关联起来。
如果直接使用物理内存,指针可能会访问到其他进程的空间,特别不安全!!
所以不能直接使用物理地址!
现代计算机提出的以下的方式:
- 每一个进程都有一个PCB结构体;
- 操作系统给每一个进程创建一个地址空间(进程地址空间/虚拟地址空间);
- 虚拟地址 - > 物理地址的过程:系统存在一种映射机制,将虚拟空间的地址内容映射到物理内存,即要访问物理内存需要先进行映射。
如果需要访问的虚拟地址是一个非法地址,操作系统就会禁止映射。
如何理解区域划分?
对于一段特定的空间,定义start和end;
虚拟地址空间究竟是什么?
地址空间是一种数据结构,它里面至少有:各个区域的划分
- struct addr_room
- {
- int code_start;
- int code_end;
- int init_start;
- int init_end;
- int uninit_start;
- int uninit_end;
- int stack_start;
- int stack_end;
- ....
- 其他属性
- }
- //进程是通过struc mm_struct来维护的
所谓的空间变化就是begin和end的变化。
映射关系的维护是谁做的?
- 通过一种表结构 -- 页表 来映射;
- 地址空间和页表(用户级) 是每一个进程都私有一份
- 只要保证,每一个进程的页表,映射的是物理内存的不同区域,就可以做到,进程之间是不会互相干扰,保证进程独立性!
扩展:
当我们的程序,在编译的时候,形成可执行程序的时候,没有被加载到内存中的时候,请问:我们程序内部,有地址吗?
答案:有的(虚拟地址)
地址空间不要仅仅理解为OS内部要遵守的,编译器也要遵守的!即编译器编译代码的时候,就已经为我们形成了各个区域,代码区区,数据区......, 并且,采用Linux中内核的方式一样的编码地址,给每一个变量,每一行代码都进行了编译,所以程序在编译的时候,每一个字段早已经具有了一个虚拟地址!!!
程序内部的地址,依旧时编译器编译好的虚拟地址;
当程序被加载到内存的时候,每行代码,每个变量便具有了一个外部的物理地址
当CPU读到指令的时候,指令内部也是有地址的,这个地址也是虚拟地址;
三、为什么要有地址空间
- 1.凡是非法的访问或者映射,OS都会识别,并终止这个进程;->保护了物理内存;
- 2.因为有地址空间和页表的存在,可以对未来的数据进行任意位置的加载 -> 物理内存的分配 和 进程的管理,可以做到没有任何关系;(内存管理 vs 进程管理 做到解耦合),所以在内存分配的时候,使用延迟分配的策略(内存的使用效率是100%);
- 3.因为在物理内存中是可以任意位置加载,那么是不是物理内存中的几乎所有的数据和代码在内存中是乱序的?(但是因为页表的存在,它可以将地址空间上的虚拟地址和物理地址进行映射,那么是不是在进程视角所有的内存分布,都可以是有序的!!即地址空间 + 页表,可以将内存分布有序化!)
-所以我们C/C++中的new,malloc申请空间,本质是在哪里?
本质是在虚拟空间申请的。
-如果申请了物理空间,但是我不立马使用,是不是浪费空间了呢?
是的。
-因为有地址空间的存在所以上层申请空间,其实是在地址空间上申请的,物理内存可以说是一个字节都不会给你!而当你真正对物理地址空间进行访问到时候,OS才执行内存的相关管理算法,帮你申请空间,构建页表映射关系,然后,再让你进行内存的访问。(完全是由操作系统自动完成的,用户包括进程是0感知的)
-CPU如何知道第一行命令在什么地址?
因为地址空间 + 页表将内存分布有序化了。
进程要访问的物理内存中的数据和代码,可能目前没有在物理内存中,同样的,也可以让不同的进程进程映射到不同的物理内存,就很容易实现进程的独立性!
- 因为有地址空间的存在,每一个进程都认为自己拥有4GB的内存,并且各个区域是有序的,进而可以通过页表映射到不同的区域,来实现进程的独立性;
- 每一个进程不知道有其他进程的存在;
重新理解什么是挂起?
-加载本质就是创建进程,那么是不是必须非得立马把所有的程序代码和数据加载到内存中,并创建内核数据结构建立映射关系?
答案:不是的,甚至极端情况下,只有内核结构被构建出来了。(新建状态)
根据上面的理解,进程可以分批加载,那么也可以分批换出,这个进程被换出了后,就是挂起状态。
- 相关阅读:
二叉树的最近公共祖先
Flink学习13:Flink外接kafka数据源
Mybatis的二级缓存 (ehcache方式)
LIRA: Learnable, Imperceptible and Robust Backdoor Attacks 论文笔记
求一篇排除干扰信息对目标检测改进的论文
16 el-tree 保存树的 选择状态, 展开状态
mysql数据多表查询、主键、主外键
Linux系统及应用复习题
MySQL知识总结 (六) MySQL调优
asp.net core 8.0 使用 Autofac ioc 容器 具体实例
- 原文地址:https://blog.csdn.net/weixin_63246064/article/details/126770931
