-
gtsummary绘制三线表/基线资料表/表格
在R语言中绘制表格的包我们介绍了非常多,除了专门绘制基线资料表的
compareGroups/tableone/table1,还介绍了绘制普通表格的gt,以及扩展包gtExtra。gtsummary包是专门用来画表格的,高度自定义的多种选项,快速绘制发表级表格。可用于总结汇总数据集、多种模型等。-
快速绘制 描述性统计表格、基线资料表(例如医学期刊常见的表1!) 。自动检测数据集中的连续、多分类和二分类变量,选择合适的描述性统计方法,还包括每个变量的缺失值。 -
绘制回归模型结果。自动识别常见的回归模型,如逻辑回归和Cox比例风险回归,会在表格中自动填充适当的列标题(即优势比和风险比)。 -
高度自定义的表格。字体字号、增加P值,合并单元格等,通通支持自定义。 -
联合 broom/gt/labelled等R包,可以直接生成发表级的结果,配合rmarkdown,可自定输出到Word、PDF、HTML等多种文件中。
本期目录:
安装
# 2选1
install.packages("gtsummary")
remotes::install_github("ddsjoberg/gtsummary")- 1
tbl_summary
自动计算描述性统计指标,支持连续型变量、分类变量,生成的表格支持自定义细节。
可用于绘制我们临床中常见的表1(基线资料表/三线表)!
library(gtsummary)
suppressPackageStartupMessages(library(tidyverse))- 1
使用自带的
trial数据集进行演示,这个数据集也是临床中常见的数据类型。包含200个病人的基本信息,比如年龄、性别、治疗方式、肿瘤分级等,分为2组,一组用A药,另一组用B药。# 查看一下数据结构
glimpse(trial)
## Rows: 200
## Columns: 8
## $ trt"Drug A", "Drug B", "Drug A", "Drug A", "Drug A", "Drug B", "…
## $ age23, 9, 31, NA, 51, 39, 37, 32, 31, 34, 42, 63, 54, 21, 48, 71…
## $ marker0.160, 1.107, 0.277, 2.067, 2.767, 0.613, 0.354, 1.739, 0.144…
## $ stageT1, T2, T1, T3, T4, T4, T1, T1, T1, T3, T1, T3, T4, T4, T1, T…
## $ gradeII, I, II, III, III, I, II, I, II, I, III, I, III, I, I, III,…
## $ response0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0…
## $ death0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 0…
## $ ttdeath24.00, 24.00, 24.00, 17.64, 16.43, 15.64, 24.00, 18.43, 24.00… - 1
基本使用
-
数据类型自动检测(连续型变量或者分类变量) -
如果列有属性值(label attributes),自动添加 -
自动添加脚注
# 选取部分数据,方便演示
trial2 <- trial %>% select(trt,age,grade)
trial2 %>% tbl_summary()- 1
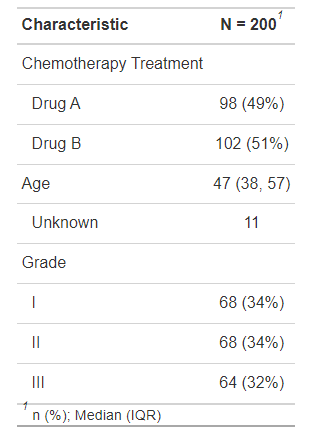
image-20220704180759636 当然是支持分组比较的,添加P值不在话下!
trial2 %>% tbl_summary(by = trt) %>% add_p()- 1

image-20220704180828586 自定义输出
超多自定义选项:
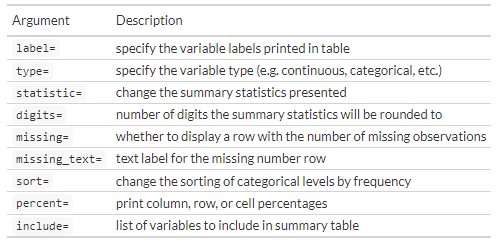
自定义选项 自定义输出表格外观:
trial2 %>%
tbl_summary(
by = trt, # 分组
# 根据变量类型选择显示方式,和case_when()的使用非常像哦
statistic = list(all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} / {N} ({p}%)"),
# 控制小数点
digits = all_continuous() ~ 2,
# 列名
label = grade ~ "Tumor Grade",
# 缺失值
missing_text = "(Missing)"
) %>%
add_p()- 1
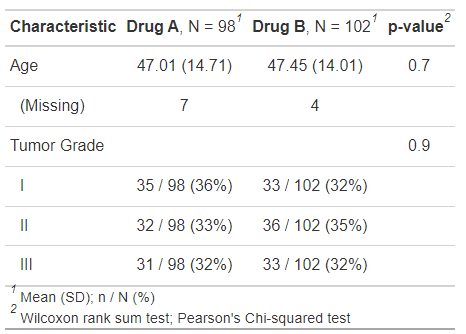
image-20220704180901410 根据变量类型选择显示方式,有多种实现方法,下面列出了支持的3种方式:
方法1 方法2 方法3 all_continuous() ~ "{mean}" c("age", "marker") ~ "{mean}" list(age = "{mean}", marker = "{mean}") list(all_continuous() ~ "{mean}") c(age, marker) ~ "{mean}" - - list(c(age, marker) ~ "{mean}") - 修改变量显示的名称也可以用同样的方法。
修改统计方法
可以为不同的列自定义不同的统计方法。
trial2 %>%
tbl_summary(
by = trt, # 分组
# 根据变量类型选择显示方式,和case_when()的使用非常像哦
statistic = list(all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} / {N} ({p}%)"),
# 控制小数点
digits = all_continuous() ~ 2,
# 列名
label = grade ~ "Tumor Grade",
# 缺失值
missing_text = "(Missing)"
) %>%
add_p(test = list(age ~ "t.test", # 为不同的列选择不同的统计方法
grade ~ "kruskal.test"
),
pvalue_fun = ~style_pvalue(.x, digits = 2)
)- 1

image-20220704180944272 除了添加P值外,还可以添加超多东西:

添加其他统计值 修改表格细节的选项:

修改表格细节 一个简单的小例子:
trial2 %>%
tbl_summary(by = trt) %>%
add_p(pvalue_fun = ~style_pvalue(.x, digits = 2)) %>%
add_overall() %>%
add_n() %>%
modify_header(label ~ "**Variable**") %>%
modify_spanning_header(c("stat_1", "stat_2") ~ "**Treatment Received**") %>%
modify_footnote(
all_stat_cols() ~ "Median (IQR) or Frequency (%)"
) %>%
modify_caption("**Table 1. Patient Characteristics**") %>%
bold_labels()- 1

image-20220704181012122 还可以和
gt包连用。使用as_gt()函数转换为gt对象后们就可以使用gt包的函数了。trial2 %>%
tbl_summary(by = trt, missing = "no") %>%
add_n() %>%
as_gt() %>% # 转换为gt对象
gt::tab_source_note(gt::md("*This data is simulated*"))- 1

image-20220704181032609 同一个变量展示多个统计量
对于连续型变量,可以在多行显示多个统计值,只要设置
type = all_continuous() ~ "continuous2"即可。trial2 %>%
select(age, trt) %>%
tbl_summary(
by = trt,
type = all_continuous() ~ "continuous2",
statistic = all_continuous() ~ c("{N_nonmiss}",
"{median} ({p25}, {p75})",
"{min}, {max}"),
missing = "no"
) %>%
add_p(pvalue_fun = ~style_pvalue(.x, digits = 2)) #修改P值小数点- 1
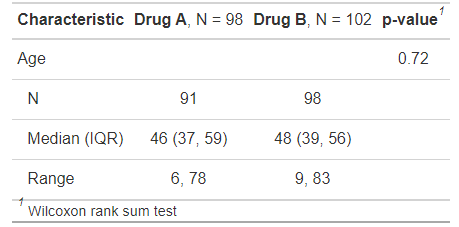
image-20220704181053665 交叉表
可以非常方便的绘制交叉表,临床上我们喜欢叫列联表~
trial %>%
tbl_cross(
row = stage, # 指定行
col = trt, # 指定列
percent = "cell"
) %>%
add_p()- 1
image-20220704181115122 和compareGroups包进行比较
这么多画表格的包,这个很强,比
gt强不少!但我还是喜欢用compareGroups包,因为简单,一句代码即可搞定,所以,必须比较下,哪个好用,尤其是在画基线资料表方面!library(compareGroups)
data("predimed")
glimpse(predimed)
## Rows: 6,324
## Columns: 15
## $ groupControl, Control, MedDiet + VOO, MedDiet + Nuts, MedDiet + V…
## $ sexMale, Male, Female, Male, Female, Male, Female, Male, Male, …
## $ age58, 77, 72, 71, 79, 63, 75, 66, 71, 76, 64, 76, 76, 65, 63, …
## $ smokeFormer, Current, Former, Former, Never, Former, Never, Never…
## $ bmi33.53, 31.05, 30.86, 27.68, 35.94, 41.66, 25.90, 25.95, 30.9…
## $ waist122, 119, 106, 118, 129, 143, 88, 85, 90, 79, 100, 89, 123, …
## $ wth0.7530864, 0.7300614, 0.6543210, 0.6941177, 0.8062500, 0.803…
## $ htnNo, Yes, No, Yes, Yes, Yes, No, Yes, Yes, Yes, Yes, Yes, Yes…
## $ diabNo, Yes, Yes, No, No, Yes, Yes, Yes, No, Yes, No, No, Yes, Y…
## $ hypercholYes, No, No, Yes, Yes, Yes, Yes, No, Yes, No, Yes, No, Yes, …
## $ famhistNo, No, Yes, No, No, No, No, Yes, No, No, No, No, No, Yes, N…
## $ hormoNo, No, No, No, No, NA, NA, No, No, No, No, No, No, No, No, …
## $ p1410, 10, 8, 8, 9, 9, 8, 9, 14, 9, 10, 8, 6, 10, 11, 12, 12, 1…
## $ toevent5.37440109, 6.09719372, 5.94661188, 2.90759754, 4.76112270, …
## $ eventYes, No, No, Yes, No, Yes, No, No, Yes, No, No, Yes, No, No,… - 1
首先是
compareGroups:# 一样代码,太简单!不会写复杂代码的可以直接输出到Word里面修改
restab <- descrTable(group ~ ., data = predimed)
restab
##
## --------Summary descriptives table by 'Intervention group'---------
##
## ____________________________________________________________________________________
## Control MedDiet + Nuts MedDiet + VOO p.overall
## N=2042 N=2100 N=2182
## ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯
## Sex: <0.001
## Male 812 (39.8%) 968 (46.1%) 899 (41.2%)
## Female 1230 (60.2%) 1132 (53.9%) 1283 (58.8%)
## Age 67.3 (6.28) 66.7 (6.02) 67.0 (6.21) 0.003
## Smoking: 0.444
## Never 1282 (62.8%) 1259 (60.0%) 1351 (61.9%)
## Current 270 (13.2%) 296 (14.1%) 292 (13.4%)
## Former 490 (24.0%) 545 (26.0%) 539 (24.7%)
## Body mass index 30.3 (3.96) 29.7 (3.77) 29.9 (3.71) <0.001
## Waist circumference 101 (10.8) 100 (10.6) 100 (10.4) 0.045
## Waist-to-height ratio 0.63 (0.07) 0.62 (0.06) 0.63 (0.06) <0.001
## Hypertension: 0.249
## No 331 (16.2%) 362 (17.2%) 396 (18.1%)
## Yes 1711 (83.8%) 1738 (82.8%) 1786 (81.9%)
## Type-2 diabetes: 0.017
## No 1072 (52.5%) 1150 (54.8%) 1100 (50.4%)
## Yes 970 (47.5%) 950 (45.2%) 1082 (49.6%)
## Dyslipidemia: 0.423
## No 563 (27.6%) 561 (26.7%) 622 (28.5%)
## Yes 1479 (72.4%) 1539 (73.3%) 1560 (71.5%)
## Family history of premature CHD: 0.581
## No 1580 (77.4%) 1640 (78.1%) 1675 (76.8%)
## Yes 462 (22.6%) 460 (21.9%) 507 (23.2%)
## Hormone-replacement therapy: 0.850
## No 1811 (98.3%) 1835 (98.4%) 1918 (98.2%)
## Yes 31 (1.68%) 30 (1.61%) 36 (1.84%)
## MeDiet Adherence score 8.44 (1.94) 8.81 (1.90) 8.77 (1.97) <0.001
## follow-up to main event (years) 4.09 (1.74) 4.31 (1.70) 4.64 (1.60) <0.001
## AMI, stroke, or CV Death: 0.064
## No 1945 (95.2%) 2030 (96.7%) 2097 (96.1%)
## Yes 97 (4.75%) 70 (3.33%) 85 (3.90%)
## ¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯¯- 1
然后是
gtSummary:predimed %>%
tbl_summary(by = group,
type = all_dichotomous() ~ "categorical"
) %>%
add_overall() %>%
# 可以自定义每一列的统计方法,这里就不演示了
add_p(pvalue_fun = ~style_pvalue(.x, digits = 3)) %>%
# 添加spanner
modify_spanning_header(c("stat_1","stat_2","stat_3") ~ "**Diet Received**")- 1

image-20220704181158756 貌似结果比
compareGroups更好看...有些结果不太一样,因为默认方法不太一样。一个是一行代码出表,另一个只需要多加几行代码就可以绘制发表级别的表,选哪个呢?
为了方便大家复现结果,运行环境如下:
sessionInfo()
## R version 4.2.0 (2022-04-22 ucrt)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19044)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=Chinese (Simplified)_China.utf8
## [2] LC_CTYPE=Chinese (Simplified)_China.utf8
## [3] LC_MONETARY=Chinese (Simplified)_China.utf8
## [4] LC_NUMERIC=C
## [5] LC_TIME=Chinese (Simplified)_China.utf8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] compareGroups_4.5.1 forcats_0.5.1 stringr_1.4.0
## [4] dplyr_1.0.9 purrr_0.3.4 readr_2.1.2
## [7] tidyr_1.2.0 tibble_3.1.7 ggplot2_3.3.6
## [10] tidyverse_1.3.1 gtsummary_1.6.1
##
## loaded via a namespace (and not attached):
## [1] fs_1.5.2 lubridate_1.8.0 webshot_0.5.3
## [4] httr_1.4.3 tools_4.2.0 backports_1.4.1
## [7] utf8_1.2.2 R6_2.5.1 DBI_1.1.3
## [10] colorspace_2.0-3 nnet_7.3-17 withr_2.5.0
## [13] tidyselect_1.1.2 compiler_4.2.0 chron_2.3-57
## [16] cli_3.3.0 rvest_1.0.2 gt_0.6.0
## [19] HardyWeinberg_1.7.5 flextable_0.7.2 mice_3.14.0
## [22] xml2_1.3.3 officer_0.4.3 sass_0.4.1
## [25] scales_1.2.0 checkmate_2.1.0 commonmark_1.8.0
## [28] systemfonts_1.0.4 digest_0.6.29 rmarkdown_2.14
## [31] svglite_2.1.0 base64enc_0.1-3 pkgconfig_2.0.3
## [34] htmltools_0.5.2 dbplyr_2.2.0 fastmap_1.1.0
## [37] rlang_1.0.2 readxl_1.4.0 rstudioapi_0.13
## [40] generics_0.1.2 jsonlite_1.8.0 zip_2.2.0
## [43] magrittr_2.0.3 kableExtra_1.3.4 Matrix_1.4-1
## [46] Rcpp_1.0.8.3 munsell_0.5.0 fansi_1.0.3
## [49] gdtools_0.2.4 lifecycle_1.0.1 stringi_1.7.6
## [52] grid_4.2.0 parallel_4.2.0 crayon_1.5.1
## [55] lattice_0.20-45 haven_2.5.0 splines_4.2.0
## [58] hms_1.1.1 knitr_1.39 pillar_1.7.0
## [61] uuid_1.1-0 reprex_2.0.1 glue_1.6.2
## [64] evaluate_0.15 data.table_1.14.2 broom.helpers_1.7.0
## [67] modelr_0.1.8 vctrs_0.4.1 tzdb_0.3.0
## [70] cellranger_1.1.0 gtable_0.3.0 assertthat_0.2.1
## [73] xfun_0.31 broom_0.8.0 Rsolnp_1.16
## [76] survival_3.3-1 viridisLite_0.4.0 truncnorm_1.0-8
## [79] writexl_1.4.0 ellipsis_0.3.2- 1
本文由 mdnice 多平台发布
-
-
相关阅读:
java计算机毕业设计ssm基于JAVA的网上购物系统-商城购物网站
Hadoop3:MapReduce源码解读之Map阶段的数据输入过程整体概览(0)
三款“非主流”日志查询分析产品初探
ROS2时间同步(python)
KNN(上):数据分析 | 数据挖掘 | 十大算法之一
专业四第二周自测
jupyter notebook中查看python版本的解决方案
线性代数应用基础补充1
六、Zabbix — Proxy分布式监控
SqlServer 开启审计功能
- 原文地址:https://blog.csdn.net/Ayue0616/article/details/126869618
