-
基于用户行为的交易反欺诈探索
阅读收益:
1- 了解交易欺诈的主要行为模式
2- 学习无监督模型在交易风控场景的应用
3- 学习完整线上推理的流程
导读
本次分享的题目是基于用户行为的交易反欺诈检测,主要介绍在交易反欺诈场景下使用用户的浏览行为序列,采用端到端或者两段式,监督或者无监督的方法做了相关尝试,在不同场景下进行评测,对收益确有提升。
01 交易反欺诈背景介绍首先和大家分享交易反欺诈的背景。
1. 传统的交易反欺诈
下图展示了经典的交易反欺诈流程。
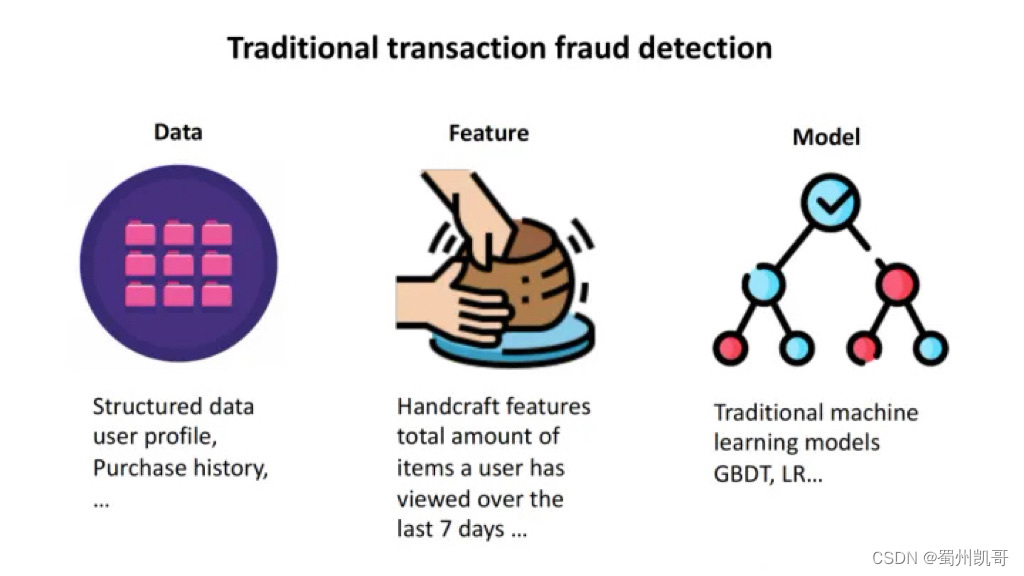
Data:首先会去收集数据,这里的数据一般是结构化数据、用户画像(例如性别、年龄等基本信息)、交易中的数据、当次交易的金额、时间点等;
Feature:接下来,根据专家经验,或根据部分样本去做手工特征,这在整个流程中是最为耗时耗力的部分;
Model:有了这些特征后进行处理、过滤,然后开始建模。传统模型例如LR、树模型GBDT。有了模型后,就可以对目标有一个判断。
整个过程简单、直接、高效。2. 用户行为数据分析
上述流程是基于结构化数据,当我们要处理非结构化数据的时候,例如用户的行为序列数据,如果仍采用上述传统模型,可能会有局限性。

在电商平台,广告、推荐等应用场景下,用户行为序列是被广泛使用的、信息量很高的一部分特征。传统的风险管理很少使用行为数据,因此我们希望在交易反欺诈的场景下尝试使用用户行为序列,看效果如何。下面主要介绍两类交易欺诈的类型:
① 盗号 (Account takeover)
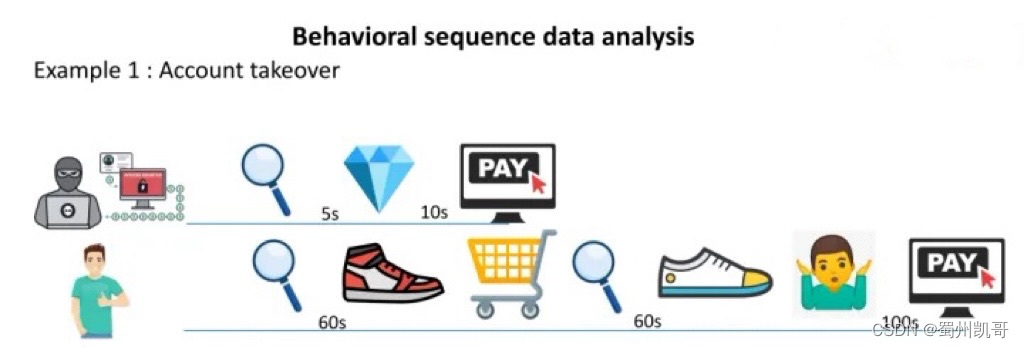
对于正常用户,进入平台后,首先会进行搜索,有了搜索结果后可能会去浏览,这个过程大概是1分钟左右的时间,然后把喜欢的物品加入购物车,之后可能再去浏览同类的产品或者同卖家的其他产品,这个过程可能也会花费几分钟左右,很多人有选择困难的问题,所以到最终购买完成,可能还会有部分思考时间。对于欺诈者,他们的浏览行为目的性强,操作也比较流畅,用盗来的账号一般会去买一些比较贵重的物品,例如钻石、首饰、金银珠宝或者3C一类的物品。

上图是两种盗号(Account takeover)的用户行为数据:
欺诈者登录后,用时15s去搜索一个airports,又用27s的时间来浏览界面,最后用了10s的时间来完成支付操作,从登录到完成结账整个过程不超过1分钟,目的性很强,操作熟练;
欺诈者登录后,明确去搜索一个4k的电视,而后又用比较短的时间完成付款,静默一段时间后又发生购买行为,继续重复这样的过程。
② 偷卡 (Stolen financial)偷盗者窃取银行卡信用卡等设备,其进入平台先浏览,浏览后付款,付款需要绑卡,在这里偷窃者会绑定这张偷来的卡去做交易,之后又会浏览不同的商品,一般也都是比较贵重的。
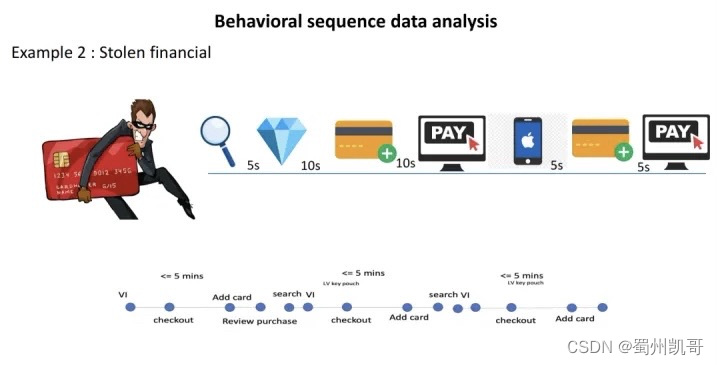
再来宏观地看一下正常用户和盗号用户的区别:
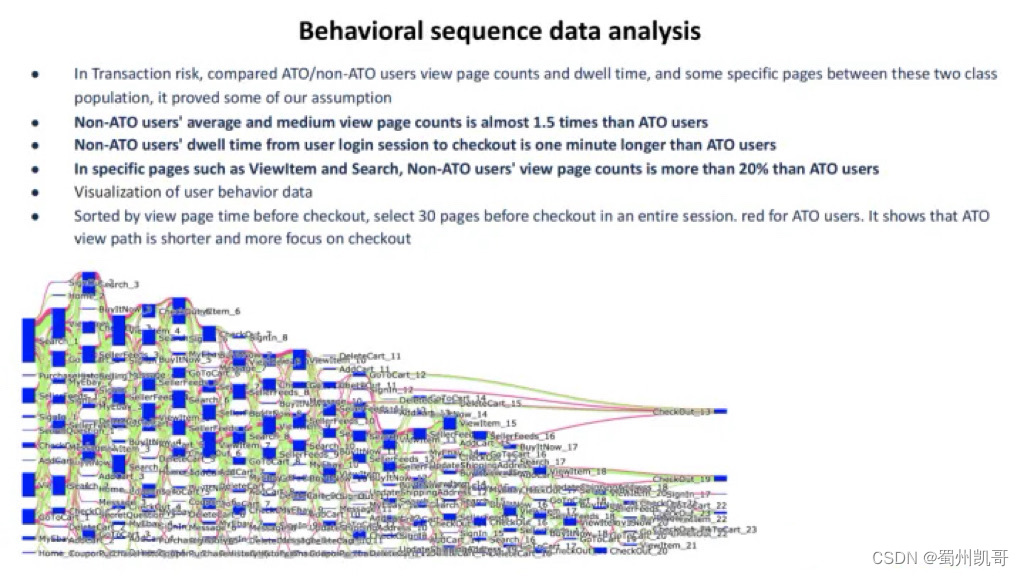
正常用户浏览页面的次数是盗号用户的1.5倍;
正常用户的平均浏览时长约比盗号用户长1分钟;
正常用户在特定页面(如ViewItem或者Search)的浏览次数比盗号用户多20%。
上图中下半部分的图将用户行为数据可视化。每个蓝色框是序列中的一个具体行为,如search,buy等。后面的数字是行为在序列中的位置。绿色的线串联起来的框是正常用户的行为轨迹,红色的线是盗号的人的行为轨迹。可以看到,对于一些特定的页面流转,比如search后直接购买,这样的行为流转动作中盗号的占比要更高。以上例子和数据证明,用户行为序列对于交易反欺诈场景是有帮助的。
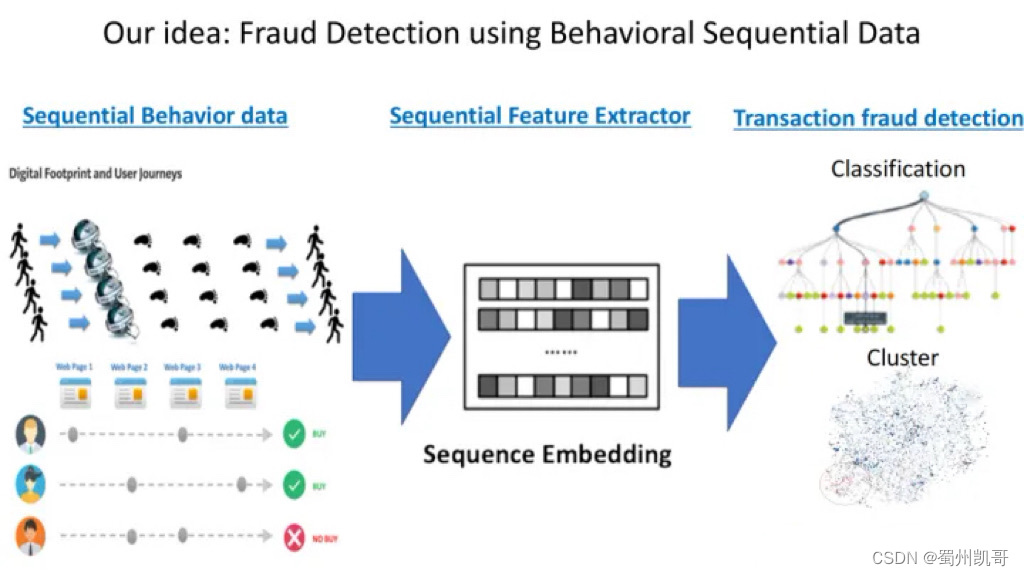
首先将用户行为数据收集起来,进行一些基本处理,去做encode或者脏数据清理,接下来将收集到的行为序列做embedding,有了embedding之后,就可以将其应用到下游不同的任务当中。
02 模型介绍1. 有监督模型
① 端到端的方法
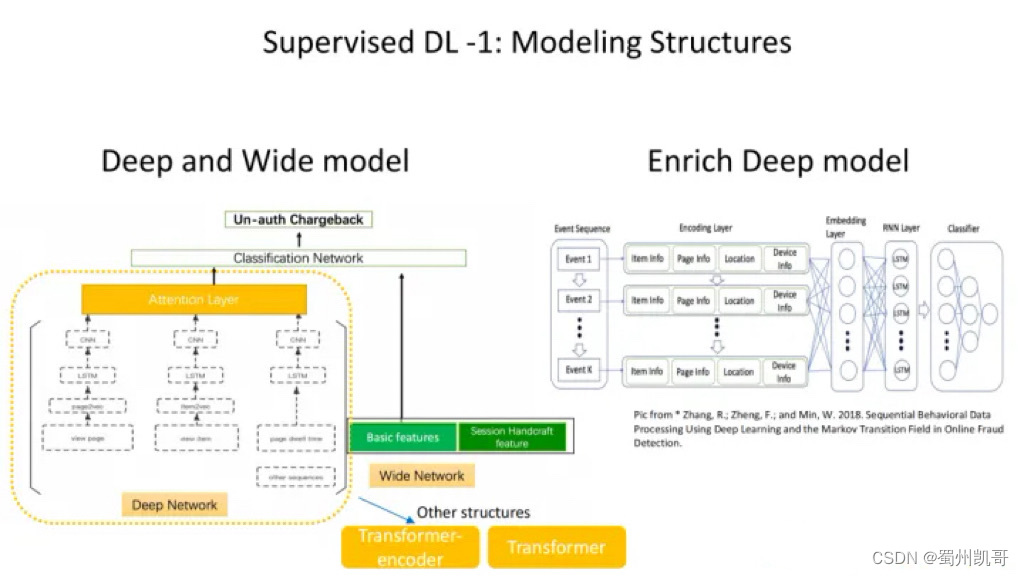
借鉴了Deep and Wide的结构,首先介绍Deep部分,Deep部分会把不同的行为序列进入各自深度的塔里面,对于不同的sequence,先做embedding,然后过一个LSTM的结构,之后又加了CNN的结构,最终为了将不同sequence的信息更好地融合,模型又加了attention的机制,从attention输出之后,会跟Wide部分的特征“碰面”,Wide部分我们会选择一些在交易反欺诈领域比较传统的手工特征,最后进行分类。
在Deep部分,我们不仅尝试了上述结构,还尝试了将LSTM和attention部分全部替换成transformer中的encoder结构,或者直接全部用Transformer结构替换,不同的结果在不同的情况下效果会有差异。
Enrich Deep model借鉴了PPT图下面的paper,首先对于输入的一个behavior sequence,它由不同的event、viewed page组成,对于用户停留的每一个页面,会有不同的属性,所以我们在输入的时候会做全对齐,之后会做embedding,后面接RNN的结构,最后去做分类。
② 两段式的方法
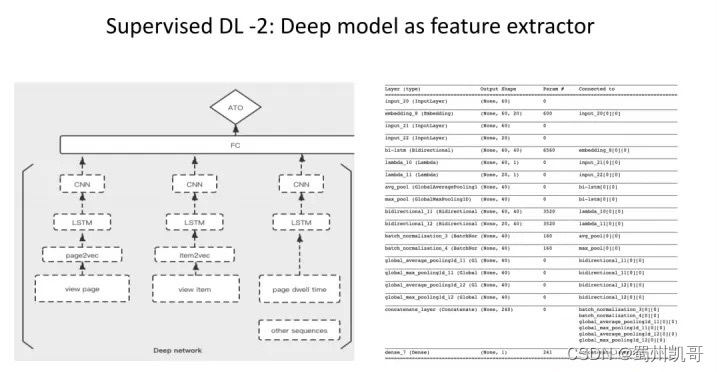
先用深度学习的模型把sequence部分的信息提取出来,即对sequence做embedding,抽取出embedding后将embedding加入到下游传统的模型里面,作为behavior sequence的特征。
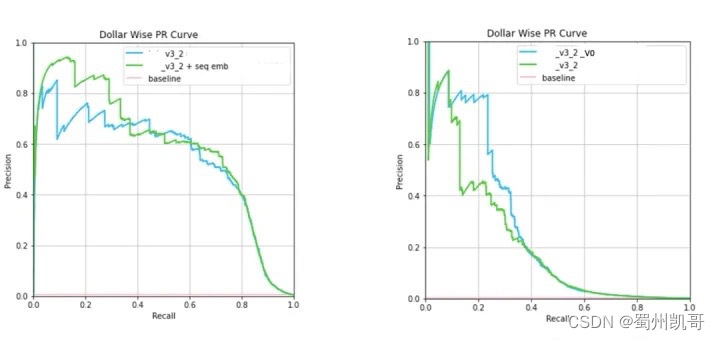
上图是Performance的展示,无论是端到端还是两段式,加入behavior数据后都会有所提升。
2. 无监督模型
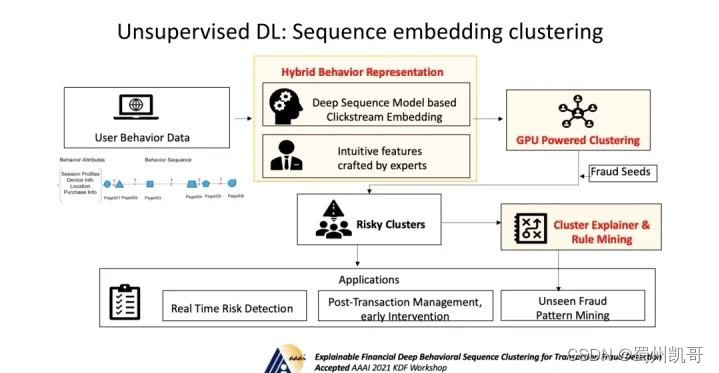
采用无监督聚类这一整体思路,主要分为两部分:先用无监督的方式把behavior embedding学出来,有了embedding后再做无监督的聚类,聚类完成后,借Fraud Seeds从cluster中找到risky cluster,从而承接下游不同的任务。
① 如何采用无监督的方法获取behavior sequence embedding
这里的无监督是指我们没有用到欺诈的标签。
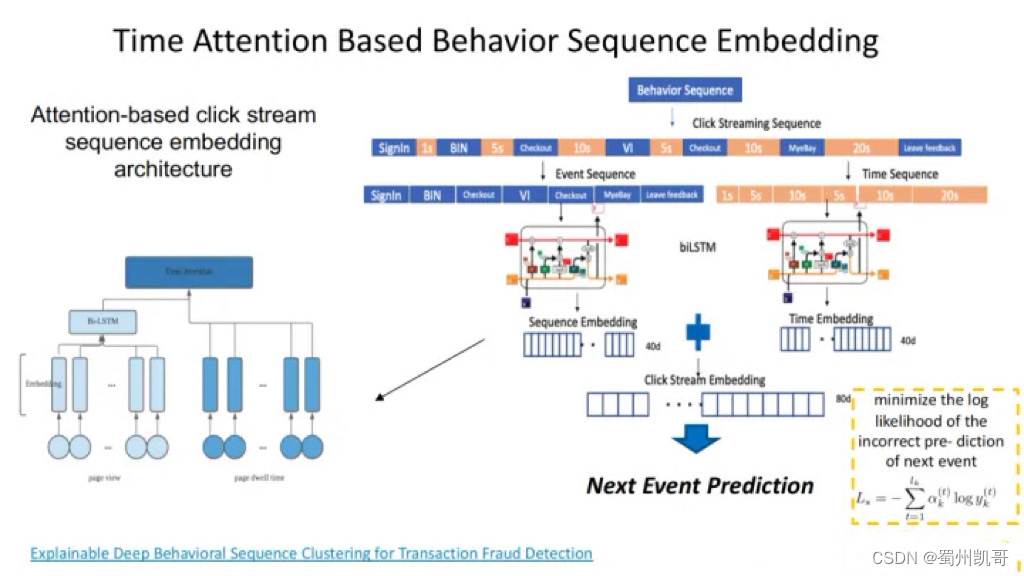
我们首先将一个behavior sequence分成event sequence和time sequence,两个sequence分别进入双向LSTM网络(biLSTM), 盗卡用户在绑卡过程中对于密码或安全问题等的不熟悉,因此他们在特定页面可能会停留更长的时间,我们利用attention机制将event sequence和time sequence更好地融合起来,而后组合两部分向量去做我们的next event prediction。
② 如何利用behavior embedding进行聚类

使用HDBSCAN把高维的向量映射到三维空间,PPT右边的图是一个实际的效果图,蓝色的点是正常的点,红色点是欺诈点,从图中也可以看出,欺诈点有明显的点聚集特性。
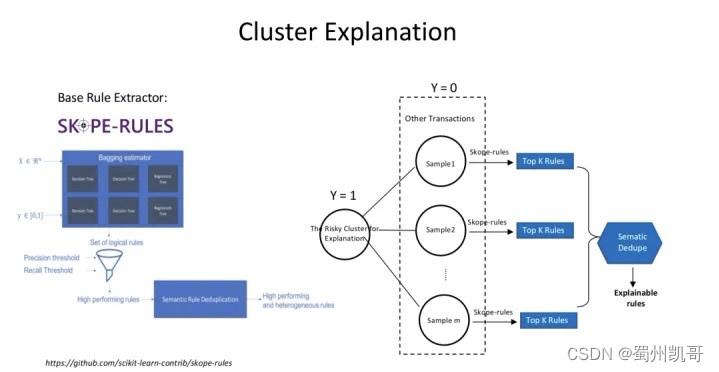
为了让业务同学更好地使用,我们有一个Cluster解释模块,主要参考了SKOPE-RULES工具。其思路是,要对某个cluster做解释,会把这个cluster中的样本看作是一类(Y=1),而其它cluster中的样本看作是其它类(Y=0),为了更好地区分它们,通过决策树不同的分枝,生成不同的rule,以这些rule为这个cluster做解释供下游使用。
HDBSCAN优化:
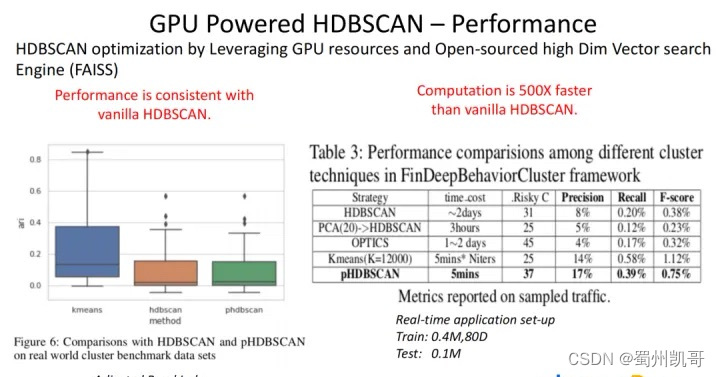
我们利用GPU资源基于FAISS做了一些相关优化,以及在HDBSCAN最小生成树的算法部分进行了优化。
③ 如何训练
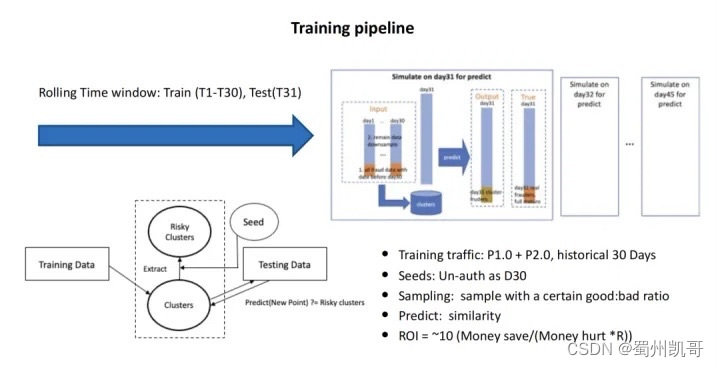
采用滑动窗口的概念,采用前30天的数据作为训练,第31天作为测试数据。拿历史数据找到当前的cluster,通过“坏样本”的种子找到risky cluster,risky cluster再跟我们的test data计算一个相似度,经过阈值或规则的判断来对当前的交易做一个评价。
03 工程部署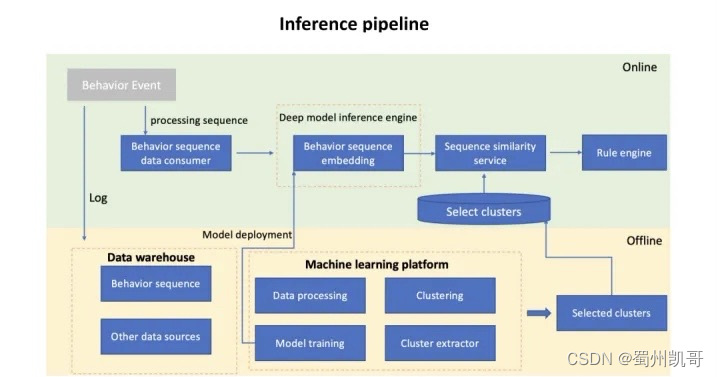
前面介绍的训练部分主要是上图中Offline模块,Offline模块主要包含两部分,一是用户behavior embedding提取部分,同时将它部署到Deep model inference engine里面,二是找到risky cluster同时将它存到线上select cluster库中。
线上我们会对实时的sequence做一些encode的处理,过inference embedding模型,将实时的sequence变成embedding向量,有了embedding向量后我们会将当前向量和之前聚类中心保存的cluster算similarity,而后在rule engine中判断这笔交易是正常还是欺诈。
04 总结
我们在交易反欺诈场景尝试了应用用户行为序列,经过分析它与标签的相关性,以及它的pattern等,我们发现欺诈行为会有一些特定的表现,可以进一步提升我们的欺诈检测和主动风险防御能力。
05 精彩问答Q:请问异构用户的行为信息怎么用deepmodel来做,不同属性的用户行为信息可能不同,有什么技巧?
A:我理解提问同学指的异构用户行为是指有item的属性、page属性、location属性、时间属性等,首先我们针对离散型或者连续型的数据都会进行一个离散化处理,离散化处理之后再做encode,encode之后再进行embedding等一列具体操作。
Q:请问cluster里输入的embedding是怎么得到的?
A:我们是采用无监督的方式,我们学这个embedding的目标并不是它是否发生在欺诈交易的一个序列,而是对下一个event做预测,比如我们会把输入的序列先打断,之前有100个行为,我们按照每20个进行划分,每一个都会有next event,相当于做预测,这样通过一个多分类的目标把输入的sequence数据的embedding学出来。
Q:请问使用有监督和无监督做行为序列embedding在业务效果和模型更新上有没有什么差异,比如有监督的序列embedding模型在训练时是不是要和主模型的周期避开?
A:确实会有上述问题存在,但还是要看怎么使用,如果只是想完全替换原来的某些模型,这种情况还好,更多的是想通过加入了不同的特征,整体特征候选集会有差异,所以它会学习到不同方面,我们的理想情况是,不同的模型,虽然它的目标相同,但是它可能抓住的人不同,加入用户sequence embedding后可能会抓到以前模型漏掉的欺诈用户,不同的模型虽有相同但也有互补。
Q:请问做sequence embedding时学习的y是什么,预测的问题是什么?
A: 我们这边采用的是有监督和无监督两种学习方式,如果是有监督y就是它是欺诈交易还是正常交易,如果是无监督的话我们就会对next event做prediction,然后embedding抽出来迁移到不同的任务中。
Q:做特征时时间范围的选取是怎么操作的?
A:如果是做聚类的情况,我们使用历史滑动窗口,比如30天,以30天以前的数据training,第31天的数据做test,它的特征就是从30天来取。
Q:在特征建模的时候,特征选取在什么粒度,是用户粒度还是交易粒度,行为序列是怎么截取的?
A:上述讲的方法都是在交易粒度。
Q:next event中event是怎么定义的?
A:大页面的view,比如说它是checkout页面,view页面还是search页面。
Q:关于反欺诈系统的搭建需要哪几个阶段,业务初期没有太多交易数据,在这种情况下需要怎么做,是不是要从积累变量和欺诈样本开始?
A:做模型,尤其是深度模型最好还是有大量的数据,如果初期数据不足,首先可以选用专家经验,这个专家经验可能不仅是你们公司专家你们的场景,其他相似的专家经验也可以迁移过来,也可以是通过一些主要的case去看到一些pattern,先去上一些规则,后面不断的累积,达到可以建模的规模后再上深度模型(深度模型改成模型)。
Q:对于用户不同的行为序列embedding之后是要concate拼接吗?
A: 对于viewpage的sequence、viewitem的sequence以及dwelltime的sequence相当于每一个经过不同的塔,塔之间是独立的,后面会concate起来。
-
相关阅读:
【Linux】Linux常用命令60条(含完整命令语句)
SwiftUI Preview传递参数问题
camunda_10_script_task_access_variable
大一作业HTML网页作业:简单的旅游 1页 (旅游主题)
商业建筑利用物联网设备实现能源效率的3种方式
C++ STL之stack
【C++】vector相关OJ
卷积神经网络实现咖啡豆分类 - P7
Undefined和Null的区别
amlogic 机顶盒关闭DLNA 后,手机还能搜到盒子
- 原文地址:https://blog.csdn.net/m0_72088858/article/details/126865429