-
西山居测试开发二面
-
delete和delete[]的区别
delete只调用一次析构函数,delete[]会调用每个一成员的析构函数。当delete操作符用于数组时,他会为每个数组元素调用析构函数,然后调用operation delete释放内存。delete与new配套,delete[]和new[]配套。 -
子类析构的时候会调用基类的析构函数吗?
会
析构函数调用的次序是先派生类的析构后基类的析构,也就是说在基类的的析构调用的时候,派生类的信息已经全部销毁了。定义一个对象时先调用基类的构造函数、然后调用派生类的构造 函数;析构的时候恰好相反:先调用派生类的析构函数、然后调用基类的析构函数。 -
内存模型
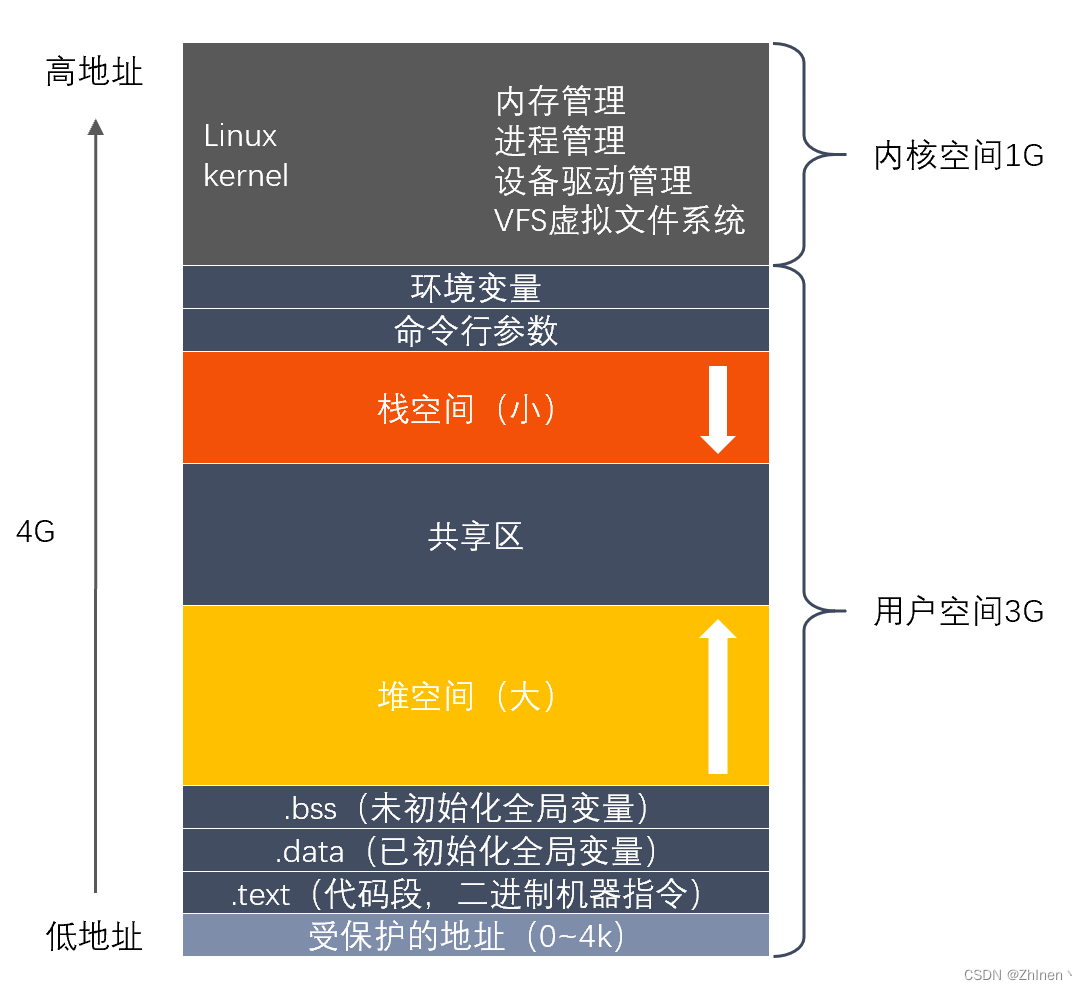
栈区:存储局部变量、函数参数值。栈从高地址向低地址增长。是一块连续的空间。
文件映射区,位于堆和栈之间。
堆区:动态申请内存用。堆从低地址向高地址增长。
BSS 段:存放程序中未初始化的全局变量和静态变量的一块内存区域。
数据段:存放程序中已初始化的全局变量和静态变量的一块内存区域。
代码段:存放程序执行代码的一块内存区域。只读,代码段的头部还会包含一些只读的常数变量。 -
内存泄漏是怎么一个回事?
内存泄漏因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。其实是就是内存空间由于某种原因程序未释放或无法释放。主要包括以下两个方面的内存泄漏:
1)堆内存泄露:只要通过malloc、new等从堆中分配的一块内存,用完后必须通过相应的free或者delete释放。假设程序的设计错误导致这部分内存没有被释放掉,那么以后这部分空间无法使用。
2)系统内存泄露:指程序使用系统分配的资源,没有使用对应的函数释放掉,导致系统资源的浪费,严重可导致系统效能的减少,系统执行不稳定。 -
栈会出现内存泄漏吗?
一个线程的栈内存是有限的。栈上的内存通常是由编译器来自动管理的。当在栈上分配一个新的变量时,或进入一个函数时,栈的指针会下移,相当于在栈上分配了一块内存,当这个变量的生命周期结束时,栈的指针会上移。由于栈上的内存的分配和回收都是由编译器控制的,所以在栈上是不会发生内存泄露的,只会发生栈溢出(Stack Overflow),也就是分配的空间超过了规定的栈大小。 -
hashmap和map的区别
c++ 标准库的std::map内部是排序的,内部使用的是红黑树实现,不管是增加还是查找的时间复杂度O(logN)。
而c++ 标准库的hashmap其实叫作std::unordered_map,其增加和查询的时间复杂度才是O(1)。它提供了类似map的方法。 -
为什么要选择epoll
select本质上是通过设置或者检查存放fd标志位的数据结构数据结构来进行下一步的处理,时间复杂度:O(n)
缺点:
1) 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
2) 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
3) 单个进程可监视的fd数量被限制;
4) 对socket进行扫描是线性扫描;
优点:
1)select的可移植性更好,在某些Unix系统上不支持poll()。
2)select对于超时值提供了更好的精度:微秒,而poll是毫秒。
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待对垒中加入一项继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,知道设备就绪或者主动超时,被唤醒后它又要再次遍历fd这个过程经理了多次无谓的遍历。时间复杂度O(n)
缺点:
1)大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义;
2)与select一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
优点:
1)poll() 不要求开发者计算最大文件描述符加一的大小。
2)poll() 在应付大数目的文件描述符的时候速度更快,相比于select。
3)它没有最大连接数的限制,原因是它是基于链表来存储的。
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
缺点:
1)相对select来说, epoll的跨平台性不够用 只能工作在linux下, 而select可以在windows linux apple上使用。
2)相对select来说 还是用起来还是复杂了一些, 不过和IOCP比起来 增加了一点点的复杂度却基本上达到了IOCP的并发量和性能, 而复杂度远远小于IOCP
3)相对IOCP来说 对多核/多线程的支持不够好, 性能也因此在性能要求比较苛刻的情况下不如IOCP.
优点:
1)IO效率不随FD数目增加而线性下降:epoll不存在这个问题,它只会对"活跃"的socket进行操作。
2)使用mmap加速内核与用户空间的消息传递:epoll通过内核和用户空间共享一块内存来实现的。

-
-
相关阅读:
基于共词分析的中国近代史实体关系图构建(毕业设计:数据处理)
项目进展(一)-晶振正常输出、焊接驱动芯片、查找芯片手册并学习
2021牛客OI赛前集训营-提高组(第六场)题解
【0102】【内存上下文】计算AllocSet内存消耗统计信息
详细指南:基于差分进化的马尔可夫链蒙特卡罗加速技术在MATLAB中的应用
PLC可以连接哪些工业设备实现远距离无线通讯?工业网关可以吗?
基于单片机的推箱子游戏仿真设计(#0014)
List、Set、数据结构、Collections-笔记
什么是集成测试?集成测试方法有哪些?
网络安全笔记-加解密算法
- 原文地址:https://blog.csdn.net/qq_40279192/article/details/126835809