-
【目标检测】42、RepVGG | 使用结构重参数化来实现精度和速度平衡的主干网络

论文:RepVGG: Making VGG-style ConvNets Great Again
代码:https://github.com/megvii-model/RepVGG
出处:CVPR2021 | 清华大学 旷世
RepVGG 的贡献:
- 使用结构重参数化的方法将训练和推理结构进行解耦,训练使用多分支结构,推理使用单分支结构,实现了一个 speed-accuracy trade-off 的简单网络结构
- 在分类和分割上展示了良好的效果,且易于部署
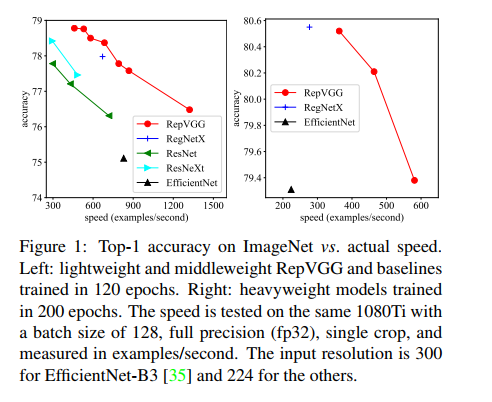
一、背景
随着 Inception、ResNet、DenseNet 等方法的提出,卷积神经网络越来越复杂,还有一些基于自动或手动框架选择,虽然这些复杂的网络能够带来好的效果,但仍然会有很多问题:
- 复杂的多分支网络让模型更复杂,执行或定制起来更难,降低推理效率
- 很多组件(如 depthwise、Xception、MobileNet等)会提高显存,在一些设备上难以支持,虽然这些方法都验证了自己的 FLOPs,但该指标并不能准确的反应其真实的速度,有些在指标上快于 VGG 和 ResNet,但实际跑起来也不一定快。
所以本文提出了 RepVGG,是一个 VGG-style 的结构,有如下优势:
- RepVGG 和 VGG 结构类似,没有旁路分支
- 只使用了 3x3 conv 和 ReLU
- 整个具体的结构没有使用自动查找、微调等,也没有复杂的设计
RepVGG 面临的问题:
- 只用单路的结构很难打得过 resnet 那种多路的结构,resnet 的多路结构能保证其梯度传递
RepVGG 如何解决上述问题:结构重参数化(训练和推理使用不同的结构)
- 既然多路结构有利于训练,那么就使用多路结构来训练,如图 2B 所示,使用 1x1 conv 和恒等映射作为旁路
- 但多路结构不利于推理,那么就使用单路结构来推理,如图 2C 所示,只有 3x3 conv + ReLU
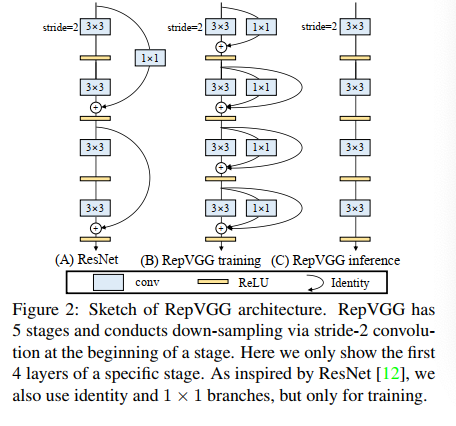
二、方法
2.1 使用简单结构的卷积神经网络的三个原因
- Fast:VGG-16 has 8.4× FLOPs as EfficientNet-B3 [35] but runs 1.8× faster on 1080Ti
- Memory-economical:使用多分支(如分支相加),其显存占用就约为输入的 2x
- Flexible:ResNet 强调需要将模型设置为残差结构,限制了网络的灵活性,比如在残差相加时,两个相加的 tensor 必须等大,且多分支结构难以使用通道剪枝等等
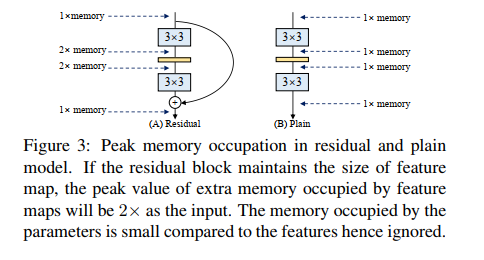
2.2 使用多分支结构的训练时长
- ResNet 其实很严格的验证了使用恒等映射可以很好的实现模型能力的增加,每个 block 都有一个高速通路,假设有 n 个 blocks,那么就可以得到 2 n 2^n 2n 个模型,为什么呢,因为每个 block 有两个通道。
虽然多分支的结构在推理的时候效率严重不足,但其胜在训练的效果,所以 RepVGG 在训练的时候选择了多分支结构,而且选择的是 3 分支结构(比 ResNet 还多一个分支):
- 一个主分支
- 一个 1x1 conv 分支
- 一个恒等映射分支
所以 RepVGG 训练的 block 可以表示为: y = x + g ( x ) + f ( x ) y = x + g(x) + f(x) y=x+g(x)+f(x)
当有 n 个 blocks 时,相当于有 3 n 3^n 3n 个模型
2.3 边端设备推理的重参数化
RepVGG 如何在推理阶段进行重参数化呢?
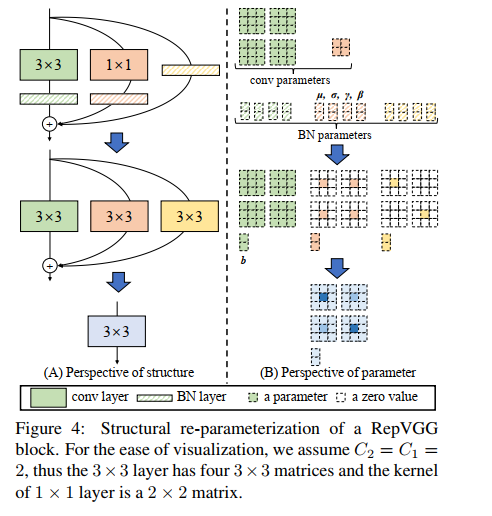
- 将 3 分支网络等价转换,简化成单分支网络
- 具体实现方法是依据卷积核的可加性,先对卷积 “吸BN”(即将 conv+bn 转换成一个带 bias 的 conv),然后将三个卷积以中心点为基准相加,将 3 个卷积合并为 1 个
具体做法如下:
首先介绍一下使用的符号:
- W ( 3 ) ∈ R C 2 × C 1 × 3 × 3 W^{(3)} \in R^{C_2 \times C_1 \times 3 \times 3} W(3)∈RC2×C1×3×3:表示 3x3 conv,输入通道为 C 1 C_1 C1,输出通道为 C 2 C_2 C2
- W ( 1 ) ∈ R C 2 × C 1 W^{(1)} \in R^{C2 \times C1} W(1)∈RC2×C1:表示 1x1 卷积
- μ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) \mu^{(3)},\sigma^{(3)} ,\gamma^{(3)} ,\beta^{(3)} μ(3),σ(3),γ(3),β(3) :表示跟在 3x3 conv 后面的 BN 的均值、标准差、尺度因子、偏置
- μ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) \mu^{(1)},\sigma^{(1)} ,\gamma^{(1)} ,\beta^{(1)} μ(1),σ(1),γ(1),β(1) :表示跟在 1x1 conv 后面的 BN 的均值、标准差、尺度因子、偏置
- μ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) \mu^{(0)},\sigma^{(0)} ,\gamma^{(0)} ,\beta^{(0)} μ(0),σ(0),γ(0),β(0) :表示跟恒等映射的 BN 的均值、标准差、尺度因子、偏置
假设:
-
输入为 M ( 1 ) ∈ R N × C 1 × H 1 × W 1 M^{(1)} \in R^{N \times C_1 \times H_1 \times W_1} M(1)∈RN×C1×H1×W1
-
输出为 M ( 2 ) ∈ R N × C 2 × H 2 × W 2 M^{(2)} \in R^{N \times C_2 \times H_2 \times W_2} M(2)∈RN×C2×H2×W2
-
在 C/H/W 输入输出相同时,则有如下结论:
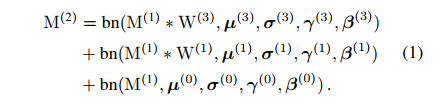
-
当不使用恒等映射分支时,则只有前两项,此时的 bn 是推理时的 BN,形式如下:
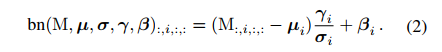
-
将每个 BN 和其前面的 conv 可以转换成一个【conv with bias vector】,假设 { W ′ , b ′ } \{W', b'\} {W′,b′} 分别为 从 W , μ , σ , γ , β W, \mu, \sigma, \gamma, \beta W,μ,σ,γ,β 转换而来的 kernel 和 bias,则有:
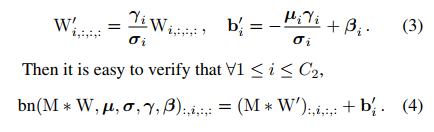
这种变换同样可以被用于恒等映射分支,因为恒等映射分支可以被看做一个 【1x1 conv with an identity matrix as the kernel】
经过这种变换后,就能得到:
- 1 个 3x3 kernel
- 2 个 1x1 kernel
- 3 个 bias vectors
然后:
- 将 3 个 bias vectors 相加,就能得到最终的 bias
- 将 2 个 1x1 kernels 和 1 个 3x3 kernels 相加(边缘补 0),就能得到最终的 3x3 kernel
2.4 结构细节
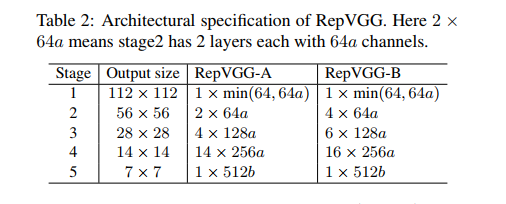
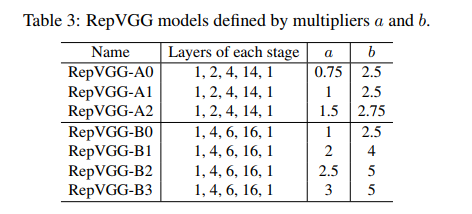
表 2 展示了 RepVGG 的设计细节,包括宽度和深度,其中主要使用了 3x3 conv,没有使用 max pooling。
深度:
- 有 5 个 stages,每个 stage 的第一层的 3x3 conv 会下采样 2 倍
- RepVGG-A:每个 stage 分别有 1,2,4,14,11 层(对比 ResNet-18/34/50)
- RepVGG-B:每个 stage 分别有 1,4,6,16,11 层(对比更大的模型)
- 第一个和最后一个 block 没有增加层数的原因在于,第一层图分辨率很大,容易带来耗时,最后一层通道很多,也同样带来耗时
宽度:
- 每个 stage 的基础通道数设置为 [64, 128, 256, 512]
- 使用 a a a 作为前 4 层的缩放比, b b b 作为最后一层的缩放比,且一般 b > a b>a b>a
- 为了进一步降低参数和耗时,使用了分组卷积,给 RepVGG-A 的 3/5/7…/21 层设置了分组数
g
g
g,给 RepVGG-B 的 23/25/27 层也设置了分组数
g
g
g
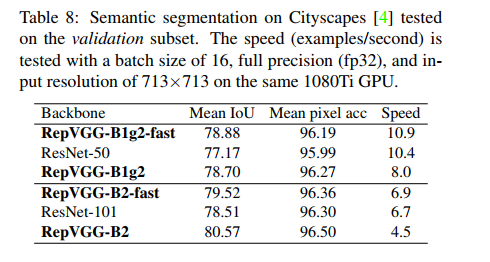
三、效果
不同版本的 RepVGG 结构如下:
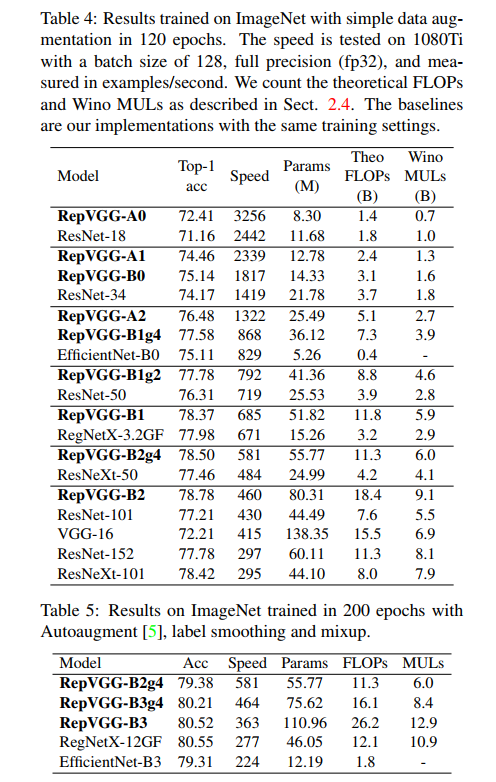
从实验上证明重参数化的强大效果,所有模型都训练 120 个 epochs
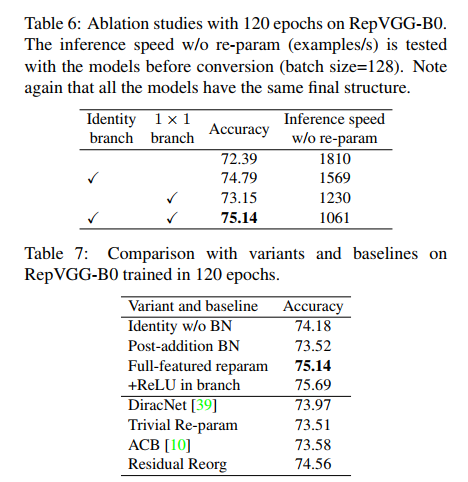
1、移除 RepVGG-B0 的恒等映射分支/1x1 conv 分支,来看训练模型的效果,如表 6:
- 两个分支都移除后,训练模型准确度跌到 72.39%
- 使用 1x1 分支升到 73.15%
- 使用恒等映射升到 74.79%
- 使用 3 个分支升到 75.14%。
2、移除恒等映射分支/1x1 conv 分支后,看推理速度,如表 7:

-
相关阅读:
还在找PDF合并文件的方法?这就有3个实用方法
uniapp中easycom用法详解
计算机毕业设计Java教师教学质量评估系统(源码+系统+mysql数据库+lw文档)
面试官:如何实现微服务全链路灰度发布?
GEE|时间序列分析(二)
技术管理进阶——谁能成为Leader,大Leader该做什么
Matlab中关于 : 的使用
使用C++实现DNS欺骗攻击
java实现html转pdf(node+puppeteer)
写一个基于C语言的保守垃圾回收器
- 原文地址:https://blog.csdn.net/jiaoyangwm/article/details/126806563