-
Sqoop的columns到底是用来干什么的
无论是在面试还是实际使用中,我们会遇到按需导入导出部分字段操作,这个时候大部分人会想到sqoop的columns参数,大部分人认为其就是按需导入需求的解,但其实并不是,甚至columns就是个鸡肋,且只能在导入操作时使用,它的正确用途是调整导入数据集中字段的顺序,下面通过一个例子来具体理解一下
首先我们在hive和mysql中各准备一张表用来做本次用例的操作
create table test( `id` string , `name` string , `sex` string ) row format delimited fields terminated by ','- 1
- 2
- 3
- 4
- 5
create table test( `id` VARCHAR(5), `name` VARCHAR(5), `sex` VARCHAR(5) )- 1
- 2
- 3
- 4
- 5
在mysql表中随便准备一些数据
现在使用sqoop将数据导入hive中,第一次导入不用columns,先全表看一下效果bin/sqoop import \ --connect jdbc:mysql://192.168.0.106:3306/test \ --username root \ --password 123456 \ --query 'select * from test where $CONDITIONS ' \ --hive-import \ --hive-overwrite \ --hive-table default.test \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 2 \ --split-by id \ --fields-terminated-by ','- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
去hive中查询test数据表,就可以看到效果
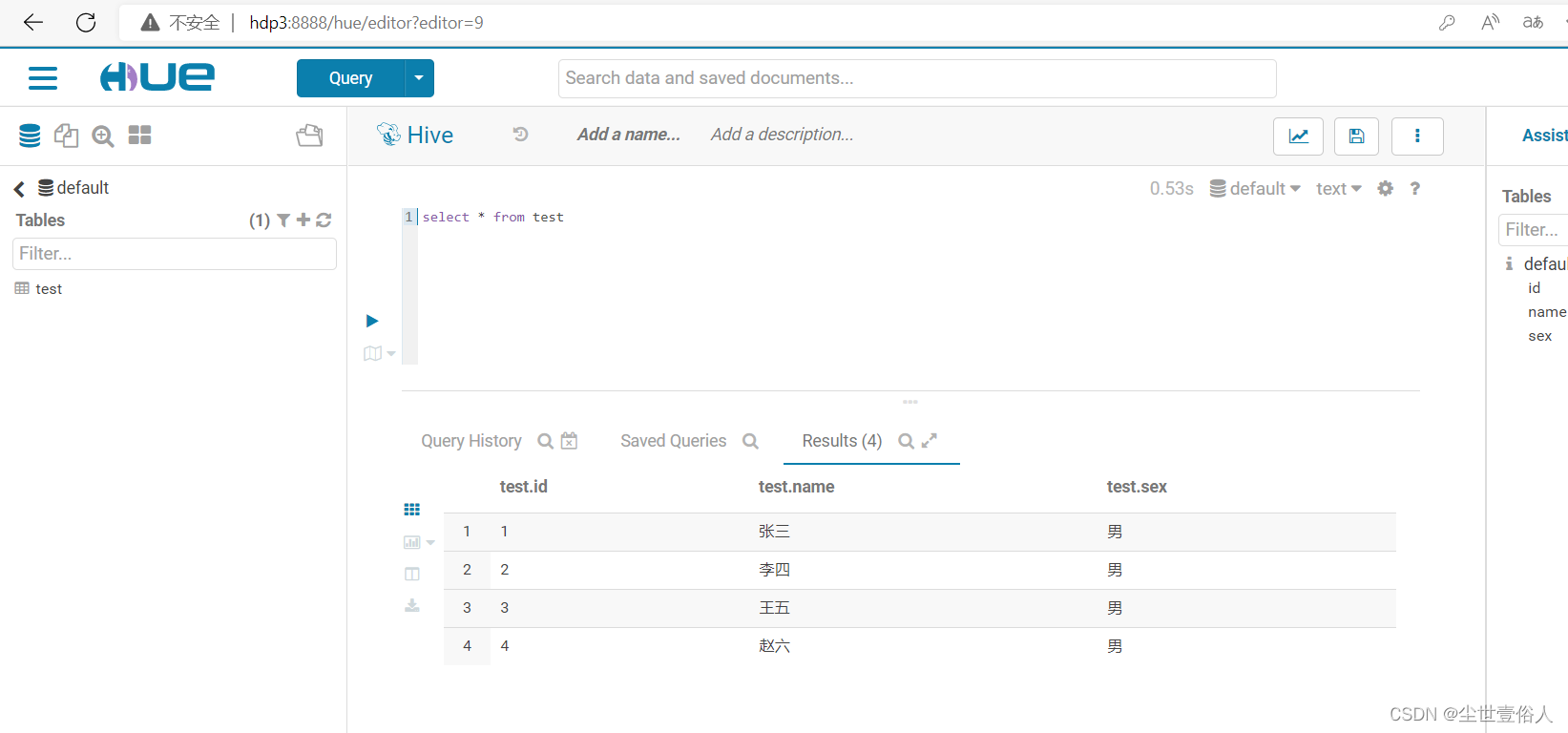
此时上图中的效果,是因为hive和mysql的字段顺序是一致的,且我们是全表导入,现在我们将hive中的表删除掉新建一张并把字段顺变一下TRUNCATE table test; drop table test; create table test( `id` string , `sex` string , `name` string ) row format delimited fields terminated by ','- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们在运行导入命令,导入命令什么都不变,命令结束后看效果,如下
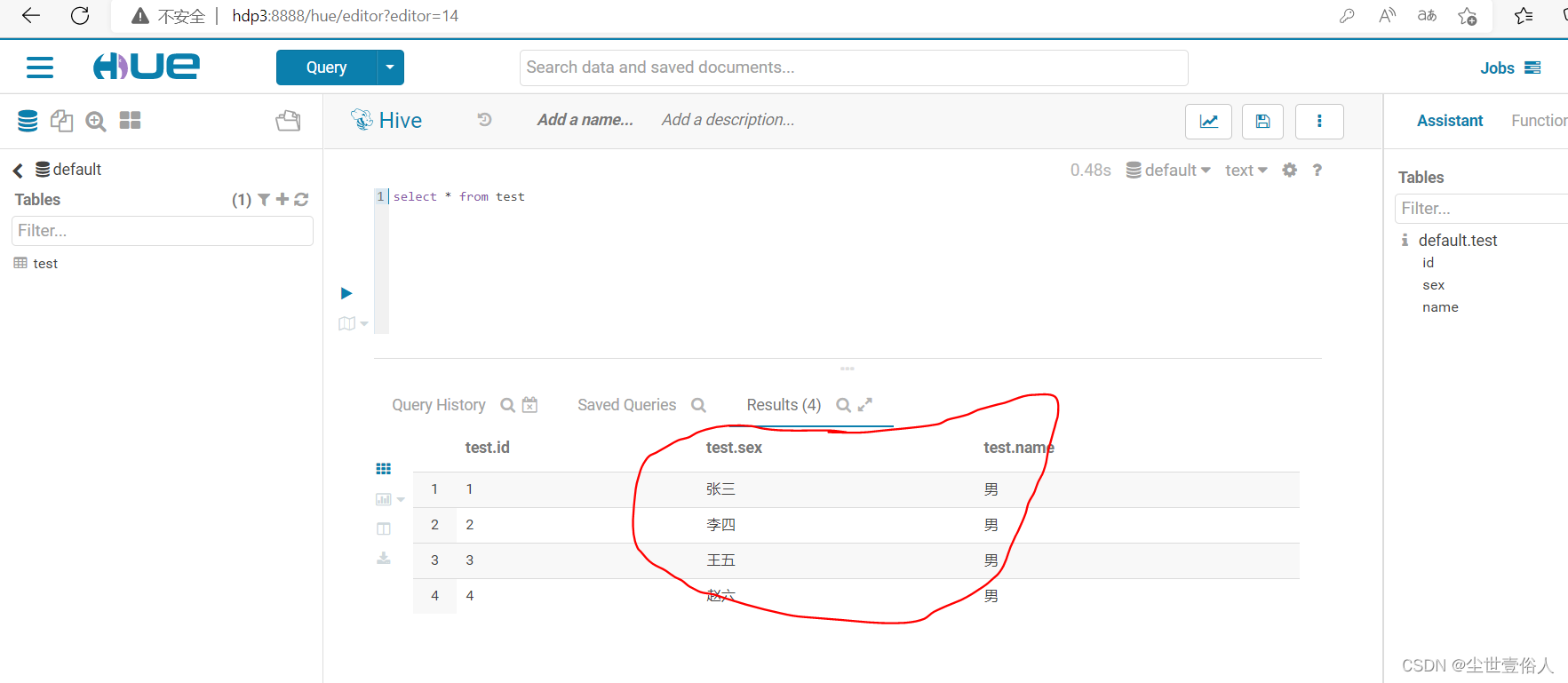
此时你就会发现一个问题,后面两个字段导入用的是mysql的顺序,和hive中的不一样,导致后两个字段错位了此时就用到了
columns,它可以调整导入命令操作的数据集中的字段顺序,当然为了验证columns是否可以完成按需导入操作我们只导入两个字段id和name,因此我们运行下面的命令bin/sqoop import \ --connect jdbc:mysql://192.168.0.106:3306/test \ --username root \ --password 123456 \ --query 'select * from test where $CONDITIONS ' \ --hive-import \ --hive-overwrite \ --hive-table default.test \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 2 \ --split-by id \ --fields-terminated-by ',' \ --columns 'id,name'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
导入操作结束我们查询hive表数据
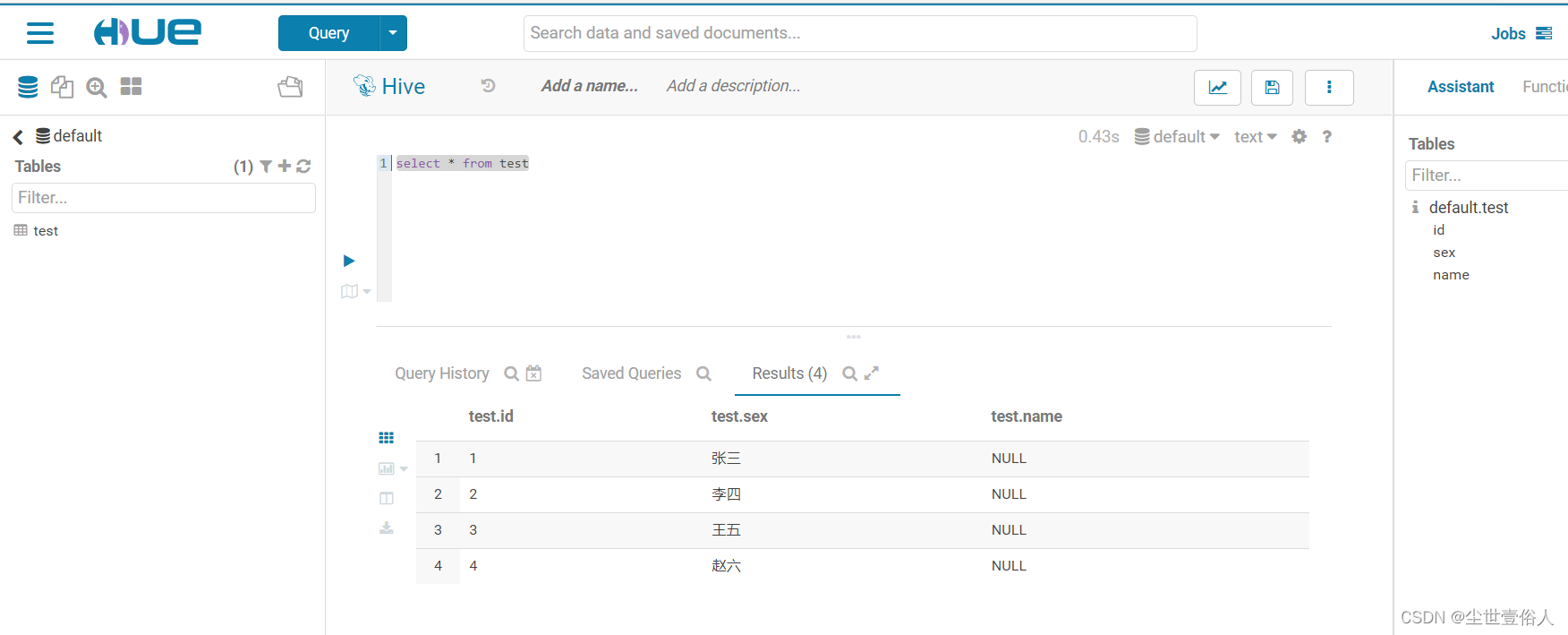
从结果中我们可以证实如下结论
1、columns不能完成按需对应并导入字段数据的需求,它只能按照从左到右的顺序插入字段数据
2、columns很鸡肋,它只能重新定义被导入命令查询到的数据集中的字段顺序,可我们完全可以在query中通过查询语句定义字段顺序和字段个数对于第二点,我们可以测试一下,比如虽然不可以无中生有一个字段,但我们可以多插入一个
Nullbin/sqoop import \ --connect jdbc:mysql://192.168.0.106:3306/test \ --username root \ --password 123456 \ --query 'select * from test where $CONDITIONS ' \ --hive-import \ --hive-overwrite \ --hive-table default.test \ --target-dir /user/company \ --delete-target-dir \ --num-mappers 2 \ --split-by id \ --fields-terminated-by ',' \ --columns 'id,Null,name'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
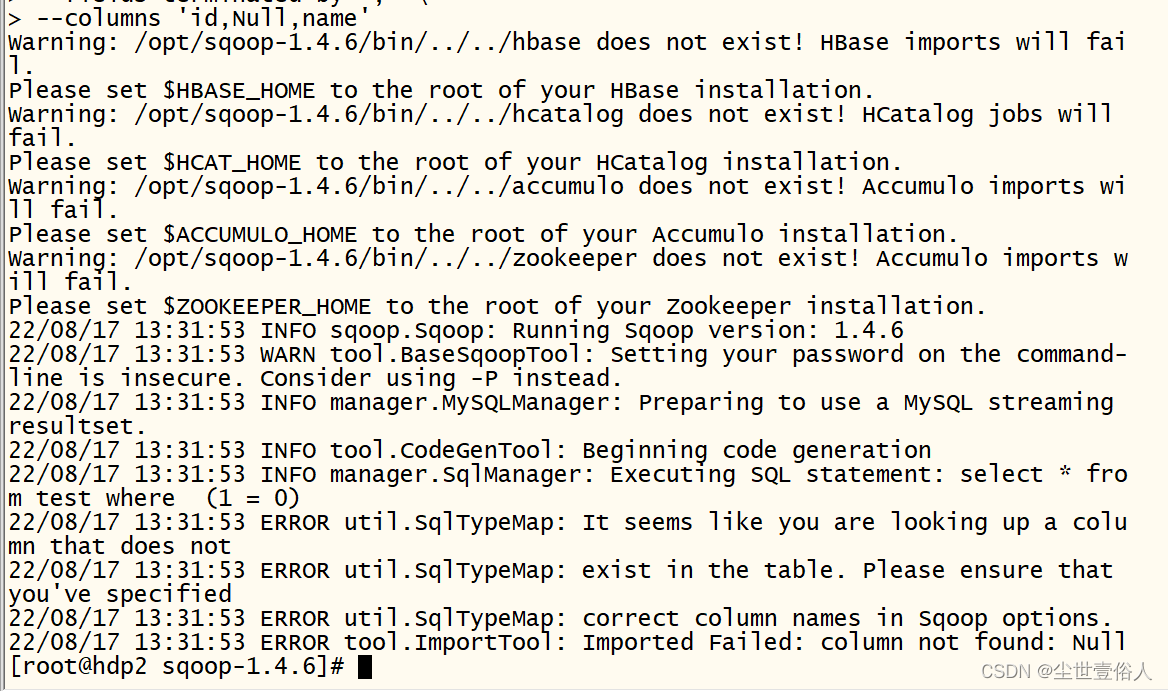
运行后会报错告诉你,sqoop把Null识别成了一个字段名,且数据集中没有这个字段
前面说过columns只能用在导入中,不能用在导出中,下面我们来验证一下
将hive表中的数据清空,用前面的命令重新建立test表并导入数据,不要被字段和数据不对应而影响下面导出的验证,重新导入后运行下面的命令
bin/sqoop export \ --connect jdbc:mysql://192.168.0.106:3306/test \ --username root \ --password 123456 \ --table test \ --num-mappers 2 \ --export-dir /hiveData/test \ --input-fields-terminated-by ',' \ --columns 'id,sex'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
运行后,我们到mysql中查看,会发现columns影响了导出的结果,使得结果是错误的,他用在导出操作上大家可以试一试,它不会筛选字段而是按照顺序将数据放到指定的字段上,如果目的表的字段不足,其它数据就舍弃了,如果目的表是一张不存在的表,那就会按照所指定的列名建立表
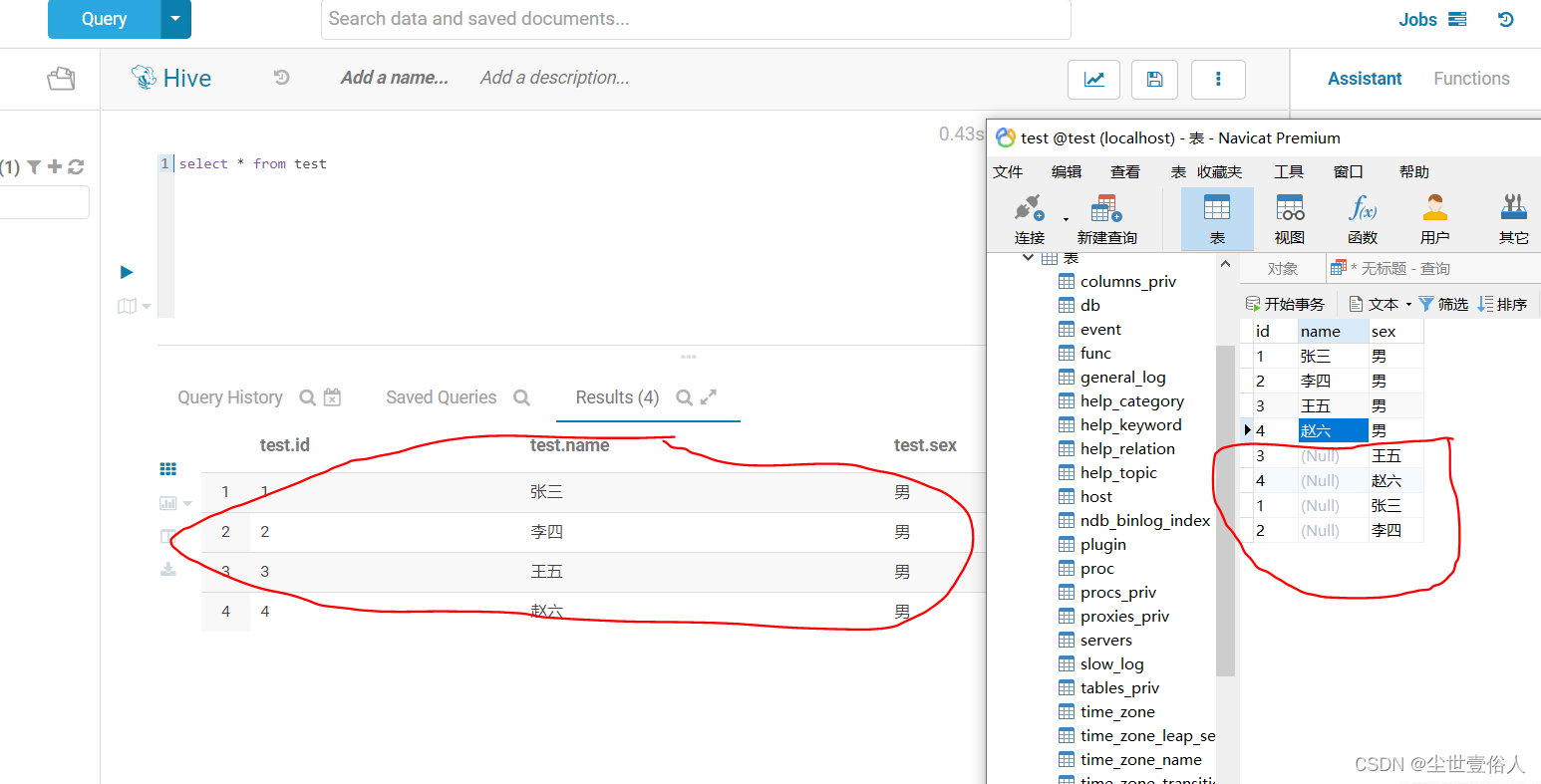
最后通过这个例子,可以确定columns并不可以用来解决按需导入导出操作,如果在实际项目实施中有这样的需求,我们可以写一个spark脚本把hive数据查出来用spark的write API写到数据库中,来代替sqoop脚本,这也是sqooo的一个缺陷,sqoop官网下载页面里也是老早不在更新了,有点摆烂的意思,总之我在让国企做项目的时候数据导入导出就是用sqooo和spark来配合解决的
Spark拉取hive数据参考:
https://blog.csdn.net/dudadudadd/article/details/114267024
Spark存数据到hive参考:https://blog.csdn.net/dudadudadd/article/details/114374448 -
相关阅读:
【python】爬虫记录每小时金价
Markdown(1):markdown设置标题、插入代码、插入图片、配置vscode插件
鸿蒙Cannot resolve symbol 'ResourceTable'
6. Python 异常、模块与包
隔离放大器
android系统硬件输入和软键盘输入属性
谈谈 Kafka 的幂等性 Producer
如何提高团队开发质量
elasticsearch--环境搭建
scrcpy-win64-v1.24使用
- 原文地址:https://blog.csdn.net/dudadudadd/article/details/126383731