-
基于大数据的工业设备故障诊断模型设计
目 录
摘 要 I
Abstract II
1 绪论 1
1.1 选题背景和意义 1
1.2 国内外研究现况及发展趋势 2
1.2.1 国内研究现状 2
1.2.2 国外研究现状 2
1.3 主要研究内容 3
2 故障诊断的总体设计方案 4
2.1 故障模型的要求 4
2.2 决策树建立故障树模型 4
2.2.1 信息熵 4
2.2.2 信息增益 5
2.2.3 ID3算法 5
2.3 支持向量机二分类原理 8
2.3.1 SVM原理 8
2.3.2 对偶问题 11
2.3.3 SVM核函数 13
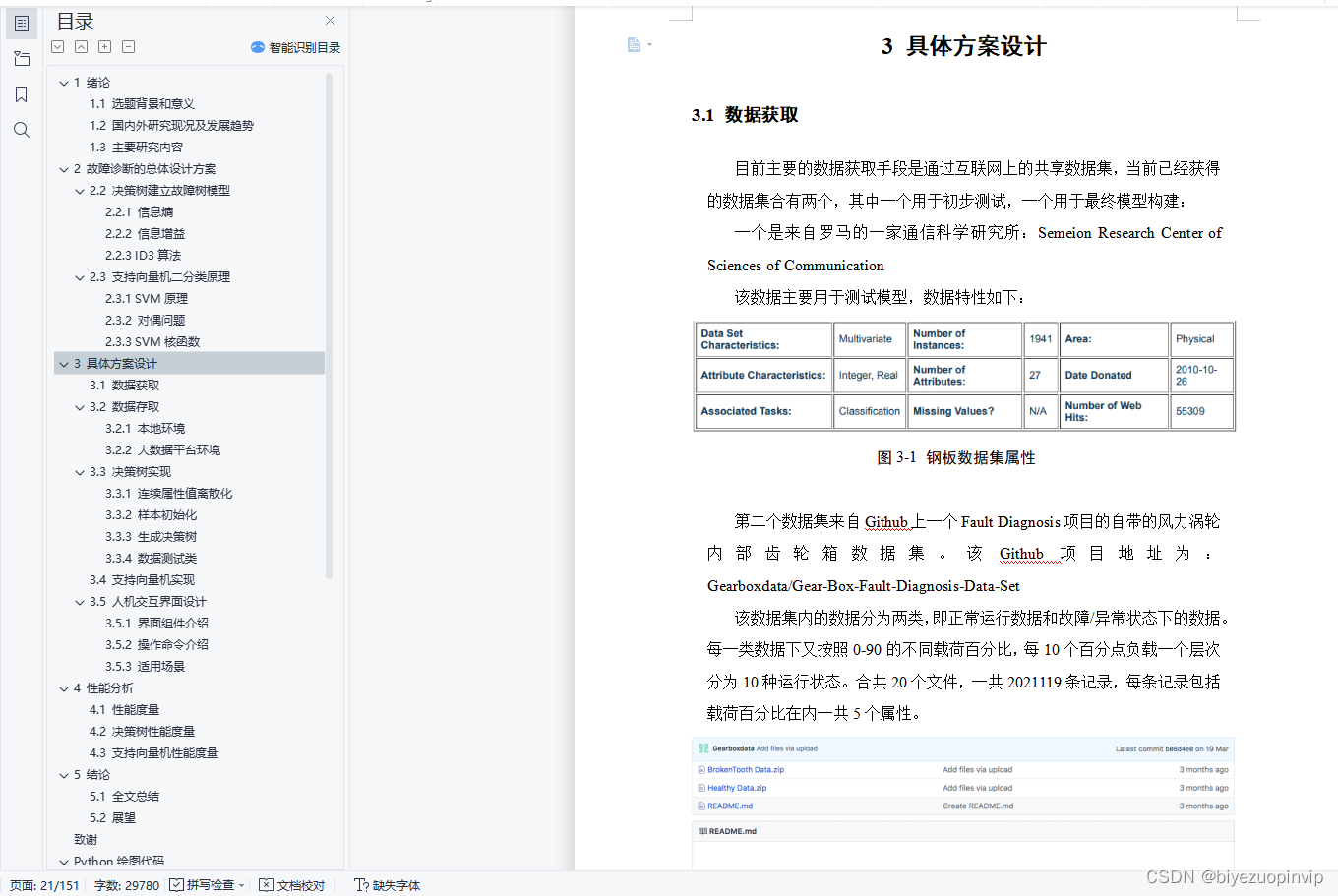
3 具体方案设计 16
3.1 数据获取 16
3.2 数据存取 17
3.2.1 本地环境 17
3.2.2 大数据平台环境 19
3.3 决策树实现 21
3.3.1 连续属性值离散化 21
3.3.2 样本初始化 23
3.3.3 生成决策树 25
3.3.4 数据测试类 29
3.4 支持向量机实现 30
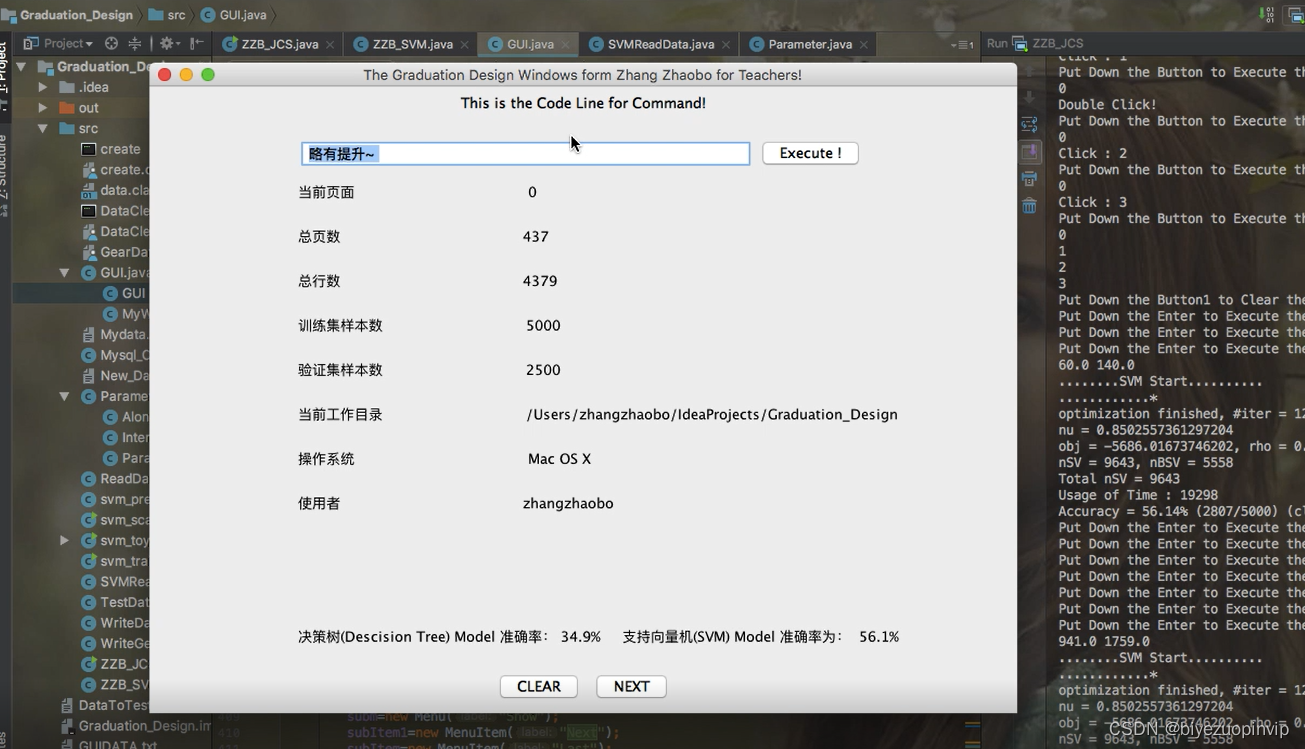
3.5 人机交互界面设计 32
3.5.1 界面组件介绍 33
3.5.2 操作命令介绍 34
3.5.3 适用场景 36
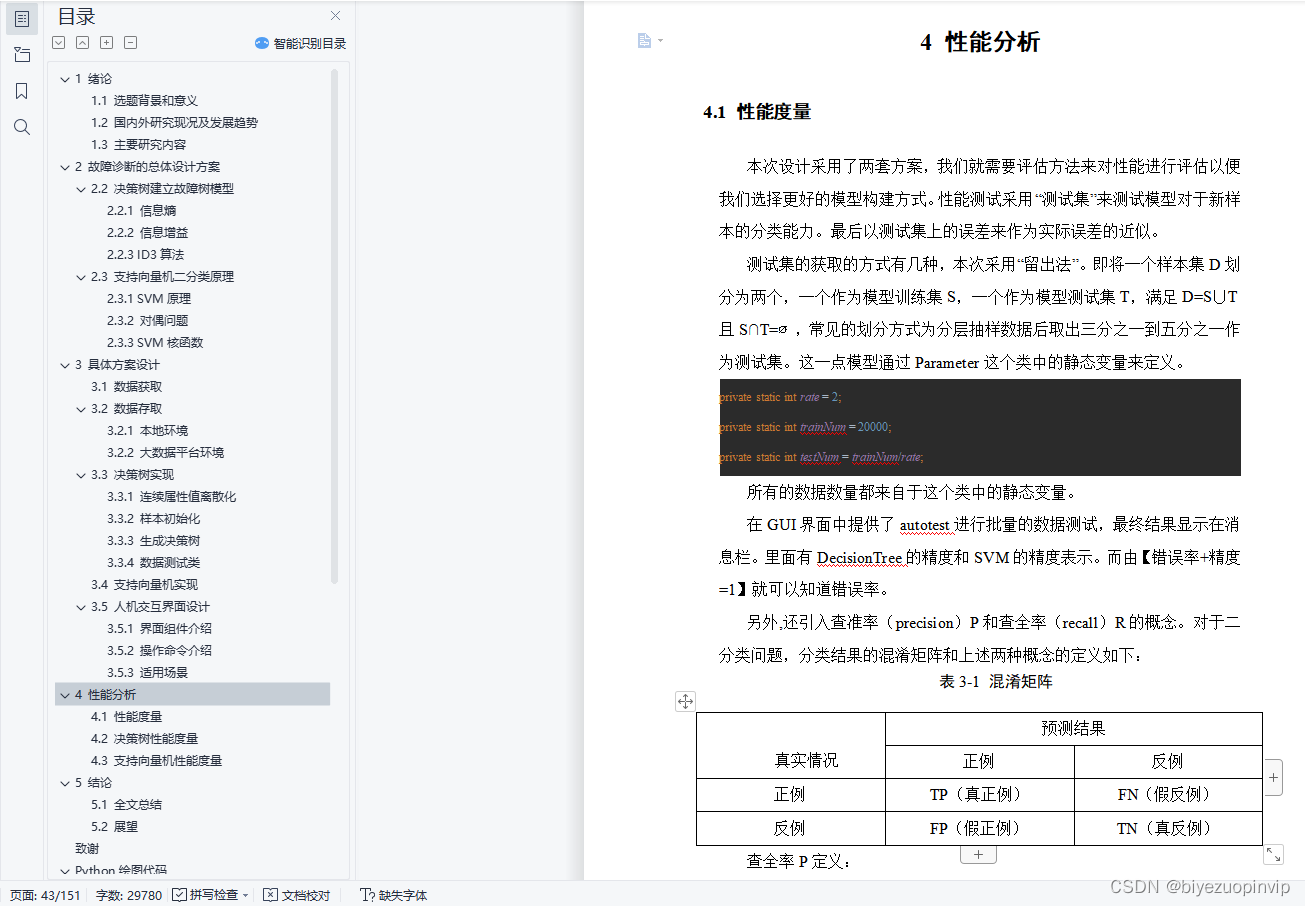
4 性能分析 38
4.1 性能度量 38
4.2 决策树性能度量 39
4.3 支持向量机性能度量 40
5 结论 42
5.1 全文总结 42
5.2 展望 43
致谢 44
参考文献 45
附录 48
5 结论
5.1 全文总结
本次设计内容总体达到了预期进度,成功的建立了故障诊断的模型和人工交互界面。并且通过划分训练集和测试集,实现了对故障或者异常情况的推理。
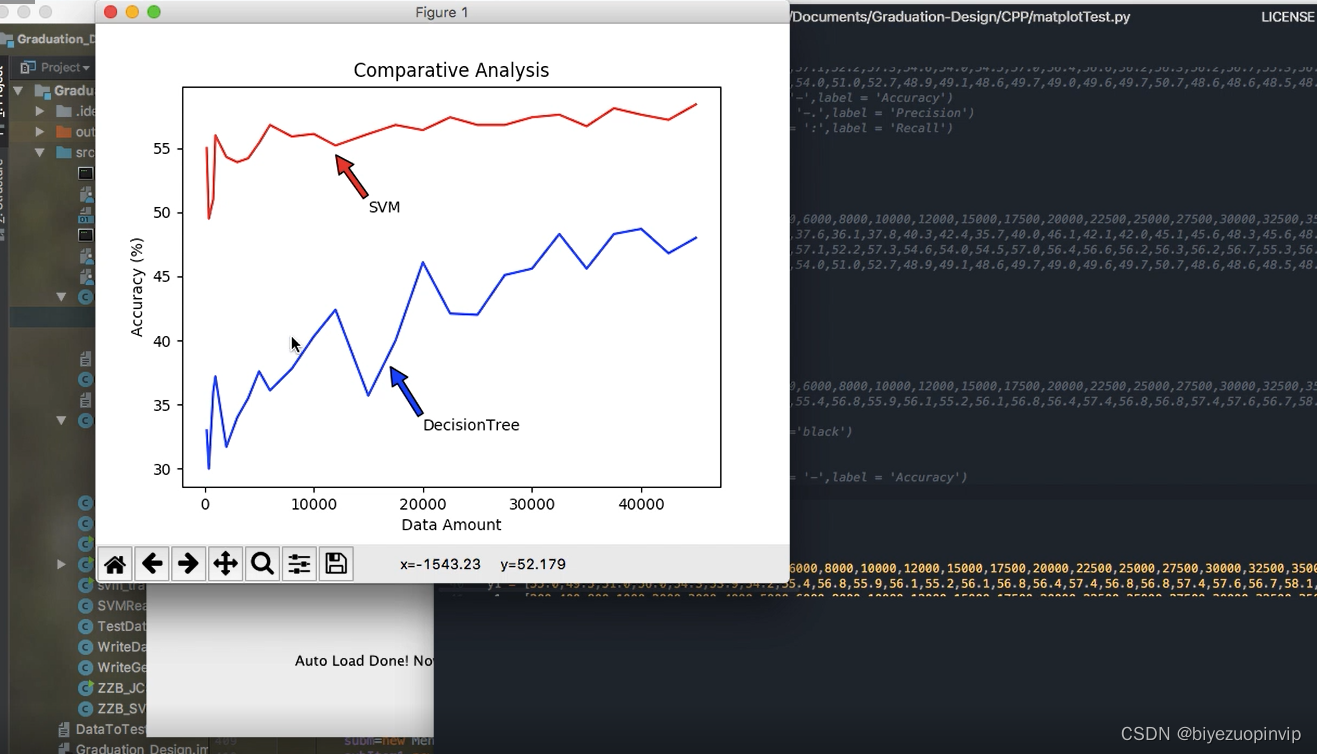
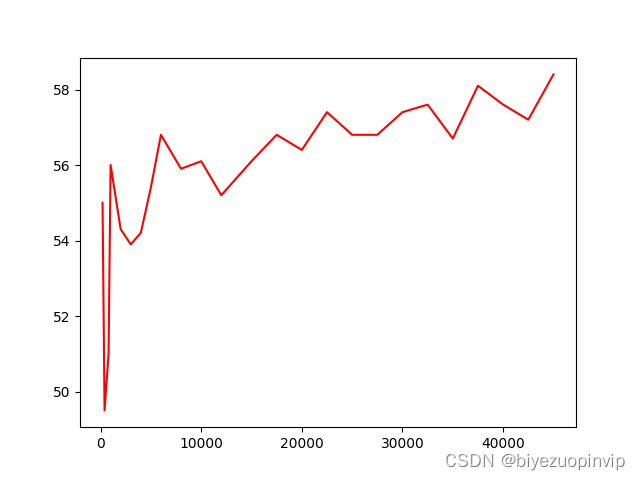
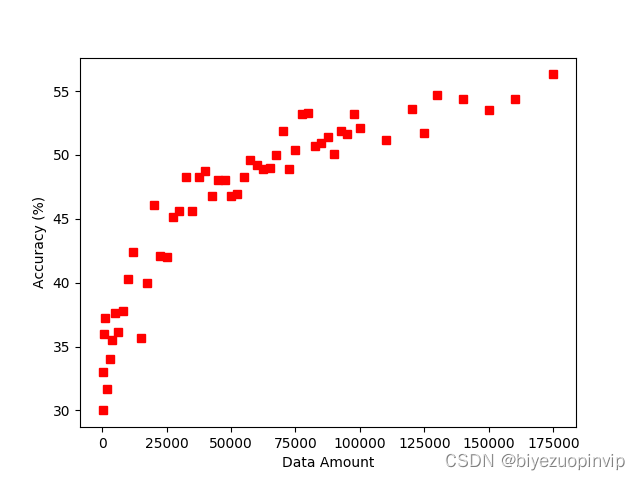
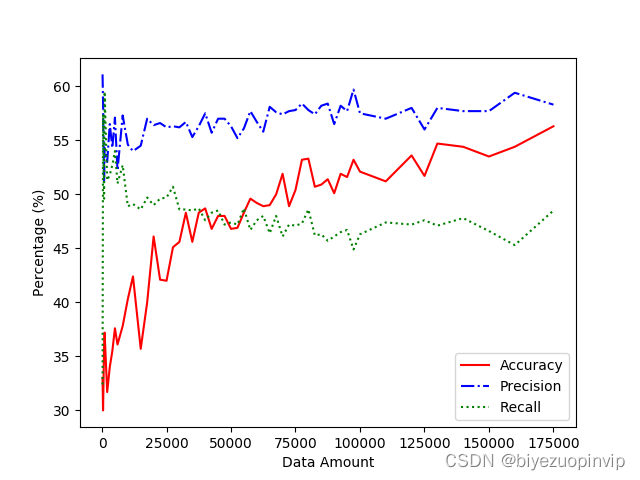
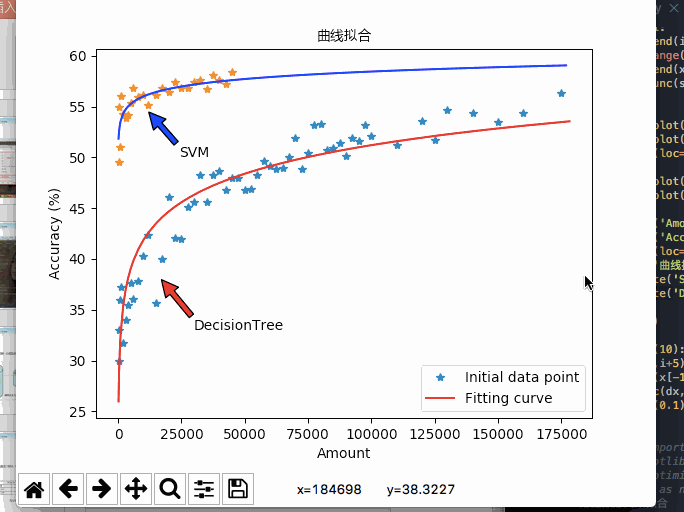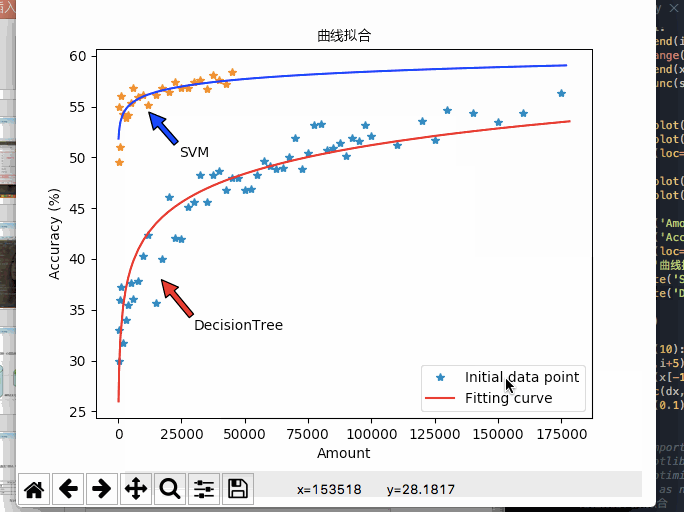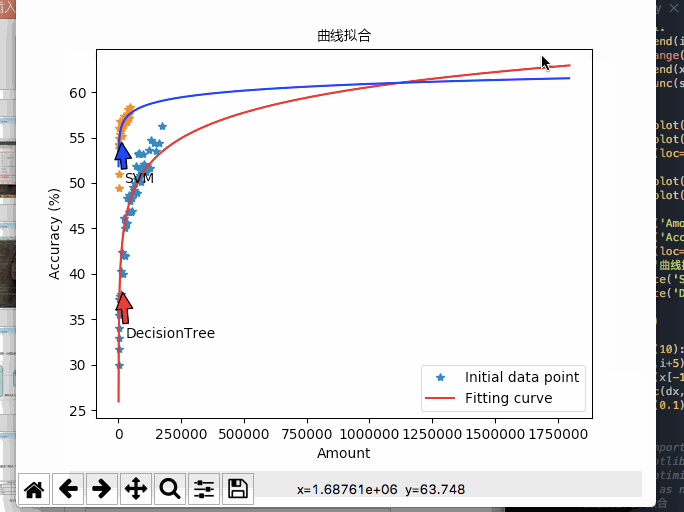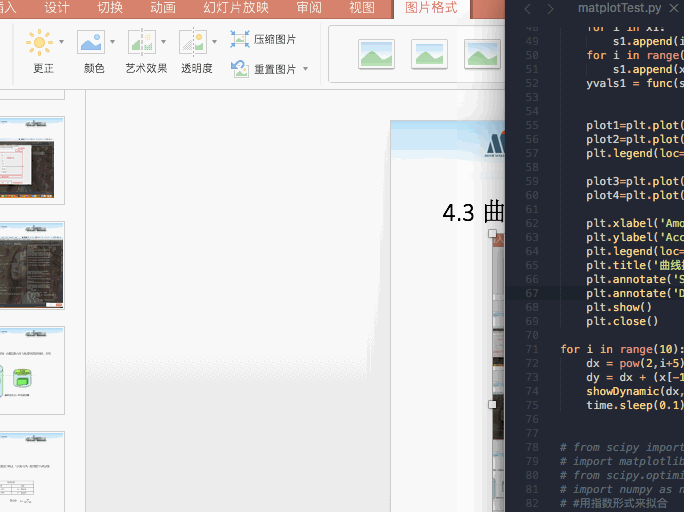
本次设计所采用的数据均为连续性数据,在支持向量机的模型中影响不大, 但是对于决策树模型的精度影响十分之大。后来经过EADC算法的离散化处理,决策树模型的精度有了很大的进步。而且在性能分析中提到:决策树对于数据量十分敏感,在运行环境的最大承载能力下,决策树的精度能达到58%左右,而且上升趋势仍然十分明显。由此可见如果将决策树模型应用于实际生产环境,辅之以足够的运算能力,也会有一定的实际应用价值。同时因为模型的计算过程较快,所以数据的更新迭代可以周期性的展开,确保数据驱动所使用的数据都是近期的历史数据,紧随着生产设备的实际情况而更新。不用过多的拘泥于过往的先验知识。
当然,基于数据驱动模型的缺陷也是显而易见的:对于未曾出现过的故障类型或者是异常数据,就会有无法处理或者是判定错误的现象,在这一点上钟福磊的混合故障诊断模型显然更加具有实用性。
另外借鉴与LibSVM的支持向量机模型由于其集成度很高,内部相当完善,所以在数据量的变化过程中具有较好的表现。但是由于其在运算时所需要的时间与内存等相较于决策树模型更多,而且其精度与数据量的关系远没有决策树那么明显。
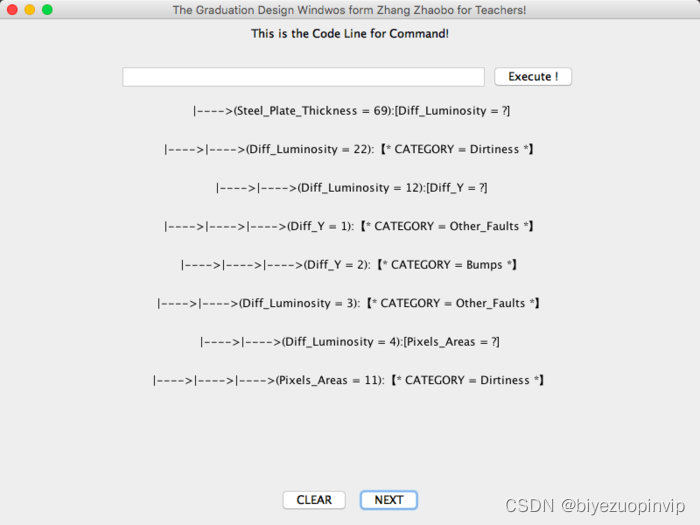
所以在实际的应用中,决策树适合于数据量较大,对于精度要求高,易于理解的场合中。而且本次设计的GUI界面配套了决策树的输出,本文转载自http://www.biyezuopin.vip/onews.asp?id=15234利于操作人员理解使用。而SVM更加适合于数据量较小,但是对于精度有一定要求的场合。5.2 展望
本次毕设过程中,我学习到了很多的知识,尤其是对于算法实现,数据选取,数据挖掘,模型优化等内容有了长足的认识与进步。而在模型建立过程中,还有很多理论和技术上的问题需要解决:
(1)本次设计对于各个属性的选取并未经过严格考虑,在实际应用中应该提前对数据进行筛选和清理,比如计算各个属性参数之间的关联度剔除一些很明显的错误训练样本和验证样本,这样不仅能降低训练、测试开销,而且还能提高模型的预测精度;
(2)对于模型的处理问题,剪枝方法未曾实现,而且剪枝虽然能提高模型对一些特定数据的精度并且减少预测开销,但是在一定程度上也限制了被剪枝模型对于更大范围数据的分类能力;
(3)另外,在数据获取部分,应该使用一些机械方面的预备知识,对数据检测模块进行优化,使得获得的数据在计算关联度之前就先天利于模型构建;
(4)SVM模块的内容并未深入,参数均采用默认类型。在实际使用时,可以调节一些参数,使得支持向量机模型更加适合于不同的工作环境;
(5)GUI的功能可以进行扩充,同时改进人机交互体验;
(6)Java与Mysql的使用在设计过程中还有待改进与优化的余地。
如果完成了上面所述的内容,配合基于数据驱动的模型只需提前设置好规范的数据格式即可适应于各类环境的特性,相信构建的模型会具有更大的实用价值。import numpy as np import matplotlib.pyplot as plt ##########################三条曲线对照图########################## # evenly sampled time at 200ms intervals # x = [200,400,800,1000,2000,3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,47500,50000,52500,55000,57500,60000,62500,65000,67500,70000,72500,75000,77500,80000,82500,85000,87500,90000,92500,95000,97500,100000,110000,120000,125000,130000,140000,150000,160000,175000,] # y1 = [33.0,30.0,36.0,37.2,31.7,34.0,35.5,37.6,36.1,37.8,40.3,42.4,35.7,40.0,46.1,42.1,42.0,45.1,45.6,48.3,45.6,48.3,48.7,46.8,48.0,48.0,46.8,46.9,48.3,49.6,49.2,48.9,49.0,50.0,51.9,48.9,50.4,53.2,53.3,50.7,50.9,51.4,50.1,51.9,51.6,53.2,52.1,51.2,53.6,51.7,54.7,54.4,53.5,54.4,56.3,] # y2 = [61.1,58.5,51.1,54.3,53.0,56.5,54.3,57.1,52.2,57.3,54.6,54.0,54.5,57.0,56.4,56.6,56.2,56.3,56.2,56.7,55.3,56.3,57.5,55.7,57.0,57.0,56.3,55.2,56.1,57.7,56.7,55.8,58.1,57.6,57.4,57.7,57.8,58.4,57.8,57.4,58.2,58.4,56.5,58.2,57.7,59.7,57.5,57.0,58.0,56.0,58.0,57.7,57.7,59.4,58.3,] # y3 = [32.4,57.4,49.6,59.5,51.3,51.8,52.7,54.0,51.0,52.7,48.9,49.1,48.6,49.7,49.0,49.6,49.7,50.7,48.6,48.6,48.5,48.7,47.6,48.3,48.5,47.2,47.4,47.2,48.7,46.7,47.6,48.0,46.4,48.0,46.1,47.2,47.1,47.3,48.6,46.2,46.3,45.7,46.1,46.5,46.7,44.9,46.3,47.4,47.2,47.6,47.1,47.8,46.6,45.3,48.5,] # plt.plot(x,y1,color = 'red',linestyle = '-',label = 'Accuracy') # plt.plot(x,y2,color = 'blue',linestyle = '-.',label = 'Precision') # plt.plot(x,y3,color = 'green',linestyle = ':',label = 'Recall') # plt.xlabel('Data Amount') # plt.ylabel('Percentage (%)') # plt.legend(loc='lowwer right') # plt.show() ##########################三条曲线对照图########################## ##########################查全率、查准率精度变化图########################## # x = [3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,47500,50000,52500,55000,57500,60000,62500,65000,67500,70000,72500,75000,77500,80000,82500,85000,87500,90000,92500,95000,97500,100000,110000,120000,125000,130000,140000,150000,160000,175000,] # y2 = [56.5,54.3,57.1,52.2,57.3,54.6,54.0,54.5,57.0,56.4,56.6,56.2,56.3,56.2,56.7,55.3,56.3,57.5,55.7,57.0,57.0,56.3,55.2,56.1,57.7,56.7,55.8,58.1,57.6,57.4,57.7,57.8,58.4,57.8,57.4,58.2,58.4,56.5,58.2,57.7,59.7,57.5,57.0,58.0,56.0,58.0,57.7,57.7,59.4,58.3,] # y3 = [51.8,52.7,54.0,51.0,52.7,48.9,49.1,48.6,49.7,49.0,49.6,49.7,50.7,48.6,48.6,48.5,48.7,47.6,48.3,48.5,47.2,47.4,47.2,48.7,46.7,47.6,48.0,46.4,48.0,46.1,47.2,47.1,47.3,48.6,46.2,46.3,45.7,46.1,46.5,46.7,44.9,46.3,47.4,47.2,47.6,47.1,47.8,46.6,45.3,48.5,] # plt.plot(x,y2,color = 'blue',linestyle = '-.',label = 'Precision') # plt.plot(x,y3,color = 'green',linestyle = ':',label = 'Recall') # plt.xlabel('Data Amount') # plt.ylabel('Percentage (%)') # plt.legend(loc='upper left') # plt.title('Comparative Analysis',color='black') # plt.annotate('Precision', xy=(63000, 55.5), xytext=(70000, 53), arrowprops=dict(facecolor='blue', shrink=0.01), ) # plt.annotate('Recall', xy=(55000, 49), xytext=(70000, 51), arrowprops=dict(facecolor='green', shrink=0.01), ) # plt.show() ##########################查全率、查准率精度变化图########################## # ##########################P-R图########################## # y2 = [61.1,58.5,51.1,54.3,53.0,56.5,54.3,57.1,52.2,57.3,54.6,54.0,54.5,57.0,56.4,56.6,56.2,56.3,56.2,56.7,55.3,56.3,57.5,55.7,57.0,57.0,56.3,55.2,56.1,57.7,56.7,55.8,58.1,57.6,57.4,57.7,57.8,58.4,57.8,57.4,58.2,58.4,56.5,58.2,57.7,59.7,57.5,57.0,58.0,56.0,58.0,57.7,57.7,59.4,58.3,] # y3 = [32.4,57.4,49.6,59.5,51.3,51.8,52.7,54.0,51.0,52.7,48.9,49.1,48.6,49.7,49.0,49.6,49.7,50.7,48.6,48.6,48.5,48.7,47.6,48.3,48.5,47.2,47.4,47.2,48.7,46.7,47.6,48.0,46.4,48.0,46.1,47.2,47.1,47.3,48.6,46.2,46.3,45.7,46.1,46.5,46.7,44.9,46.3,47.4,47.2,47.6,47.1,47.8,46.6,45.3,48.5,] # y2=y2[20:] # y3=y3[20:] # plt.plot(y2,y3,color = 'blue',linestyle = ':') # plt.xlabel('Precision') # plt.ylabel('Recall') # plt.legend(loc='lowwer right') # plt.show() ##########################P-R图########################## ##########################决策树精度变化图########################## # x = [200,400,800,1000,2000,3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,47500,50000,52500,55000,57500,60000,62500,65000,67500,70000,72500,75000,77500,80000,82500,85000,87500,90000,92500,95000,97500,100000,110000,120000,125000,130000,140000,150000,160000,175000,] # y1 = [33.0,30.0,36.0,37.2,31.7,34.0,35.5,37.6,36.1,37.8,40.3,42.4,35.7,40.0,46.1,42.1,42.0,45.1,45.6,48.3,45.6,48.3,48.7,46.8,48.0,48.0,46.8,46.9,48.3,49.6,49.2,48.9,49.0,50.0,51.9,48.9,50.4,53.2,53.3,50.7,50.9,51.4,50.1,51.9,51.6,53.2,52.1,51.2,53.6,51.7,54.7,54.4,53.5,54.4,56.3,] # y2 = [61.1,58.5,51.1,54.3,53.0,56.5,54.3,57.1,52.2,57.3,54.6,54.0,54.5,57.0,56.4,56.6,56.2,56.3,56.2,56.7,55.3,56.3,57.5,55.7,57.0,57.0,56.3,55.2,56.1,57.7,56.7,55.8,58.1,57.6,57.4,57.7,57.8,58.4,57.8,57.4,58.2,58.4,56.5,58.2,57.7,59.7,57.5,57.0,58.0,56.0,58.0,57.7,57.7,59.4,58.3,] # y3 = [32.4,57.4,49.6,59.5,51.3,51.8,52.7,54.0,51.0,52.7,48.9,49.1,48.6,49.7,49.0,49.6,49.7,50.7,48.6,48.6,48.5,48.7,47.6,48.3,48.5,47.2,47.4,47.2,48.7,46.7,47.6,48.0,46.4,48.0,46.1,47.2,47.1,47.3,48.6,46.2,46.3,45.7,46.1,46.5,46.7,44.9,46.3,47.4,47.2,47.6,47.1,47.8,46.6,45.3,48.5,] # plt.plot(x,y1,'rs') # plt.title('DecisionTree',color='black') # plt.xlabel('Data Amount') # plt.ylabel('Accuracy (%)') # plt.show() ##########################决策树精度变化图########################## ##########################SVM精度变化图########################## # x = [200,400,800,1000,2000,3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,] # y1 = [55.0,49.5,51.0,56.0,54.3,53.9,54.2,55.4,56.8,55.9,56.1,55.2,56.1,56.8,56.4,57.4,56.8,56.8,57.4,57.6,56.7,58.1,57.6,57.2,58.4,] # plt.plot(x,y1,'rs') # plt.title('Support Vector Machine',color='black') # plt.xlabel('Data Amount') # plt.ylabel('Accuracy (%)') # # plt.plot(x,y1,color = 'red',linestyle = '-',label = 'Accuracy') # plt.show() ##########################SVM精度变化图########################## ##########################精度变化对比分析图########################## # x = [200,400,800,1000,2000,3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,] # y1 = [55.0,49.5,51.0,56.0,54.3,53.9,54.2,55.4,56.8,55.9,56.1,55.2,56.1,56.8,56.4,57.4,56.8,56.8,57.4,57.6,56.7,58.1,57.6,57.2,58.4,] # x1 = [200,400,800,1000,2000,3000,4000,5000,6000,8000,10000,12000,15000,17500,20000,22500,25000,27500,30000,32500,35000,37500,40000,42500,45000,47500,50000,52500,55000,57500,60000,62500,65000,67500,70000,72500,75000,77500,80000,82500,85000,87500,90000,92500,95000,97500,100000,110000,120000,125000,130000,140000,150000,160000,175000,] # y2 = [33.0,30.0,36.0,37.2,31.7,34.0,35.5,37.6,36.1,37.8,40.3,42.4,35.7,40.0,46.1,42.1,42.0,45.1,45.6,48.3,45.6,48.3,48.7,46.8,48.0,48.0,46.8,46.9,48.3,49.6,49.2,48.9,49.0,50.0,51.9,48.9,50.4,53.2,53.3,50.7,50.9,51.4,50.1,51.9,51.6,53.2,52.1,51.2,53.6,51.7,54.7,54.4,53.5,54.4,56.3,] # s1 = [] # count = 0 # sy1 = [] # while count<len(x): # s1.append(x1[count]) # sy1.append(y2[count]) # count+=1 # plt.plot(x,y1,'r',s1,sy1,'b') # plt.title('Comparative Analysis',color='black') # plt.annotate('SVM', xy=(12000, 54.5), xytext=(15000, 50), arrowprops=dict(facecolor='red', shrink=0.01), ) # plt.annotate('DecisionTree', xy=(17000, 38), xytext=(20000, 33), arrowprops=dict(facecolor='blue', shrink=0.01), ) # plt.xlabel('Data Amount') # plt.ylabel('Accuracy (%)') # # plt.plot(x,y1,color = 'red',linestyle = '-',label = 'Accuracy') # plt.show() ##########################精度变化对比分析图##########################- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103










-
相关阅读:
Java数据类型
4.每天不同时间段通过微信发消息提醒女友
c++ SFML ftp切换工作目录并且删除目录
二分查找 分数 10
【Java 数据结构】栈与OJ题
利用curl测试WSS连接的建立
基于SSM的住院病人监测预警信息管理系统毕业设计源码021054
【C语言基础】:操作符详解(二)
AMP256_wf_610万迭代美女高参万能底丹,高参模型分享
linux下重置sql密码的办法
- 原文地址:https://blog.csdn.net/newlw/article/details/126739341
