-
CSP 2021 入门级第一轮
CSP 2021 入门级第一轮
一、单项选择题
第 1 题
题目
以下不属于面向对象程序设计语言的是 ( ) ;
A. C++
B. Python
C. Java
D. C分析
面向对象程序设计语言有 Smalltalk,Eiffel,C++,Java,Python 等;
C 为面向过程程序设计语言;
答案
D
第 2 题
题目
以下奖项与计算机领域最相关的是 ( ) ;
A. 奥斯卡奖
B. 图灵奖
C. 诺贝尔奖
D. 普利策奖分析
与计算机领域最相关的奖项为图灵奖;
答案
B
第 3 题
题目
目前主流的计算机储存数据最终都是转换成 ( ) 数据进行储存;
A. 二进制
B. 十进制
C. 八进制
D. 十六进制分析
主流的计算机储存数据最终都是转换成 二进制 数进行储存;
答案
A
第 4 题
题目
以比较作为基本运算,在 N N N 个数中找出最大数,最坏情况下所需要的最少的比较次数为 ( ) ;
A. N 2 N^{2} N2
B. N N N
C. N − 1 N-1 N−1
D. N + 1 N+1 N+1分析
在 N N N 个数中找出最大数,则先将最大值设为第一个数,则用此数依次与后面的 N − 1 N - 1 N−1 个数进行比较;
答案
C
第 5 题
题目
对于入栈顺序为 a, b, c, d, e 的序列,下列 ( ) 不是合法的出栈序列;
A. a, b, c, d, e
B. e, d, c, b, a
C. b, a, c, d, e
D. c, d, a, e, b分析
设在一次入栈后栈内所有元素立即出栈,用 ; ; ; 分割两次入栈,一次入栈中不同元素用 , , , 分割;
对于 A 选项,入栈为, a ; b ; c ; d ; e ; a; b; c; d; e; a;b;c;d;e; ;
对于 B 选项,入栈为, a , b , c , d , e ; a, b, c, d, e; a,b,c,d,e; ;
对于 C 选项,入栈为, a , b ; c ; d ; e ; a, b; c; d; e; a,b;c;d;e; ;
对于 D 选项,入栈为, a , b , c ; a, b, c; a,b,c; 后出栈 c c c 元素,入栈 d d d ,出栈,则此时,栈顶元素为 b b b ,元素 a a a 在其下面,所以此序列不合法;
答案
D
第 6 题
题目
对于有 n n n 个顶点、 m m m 条边的无向连通图 (m>n),需要删掉 ( ) 条边才能使其成为一棵树;
A. n − 1 n-1 n−1
B. m − n m-n m−n
C. m − n − 1 m-n-1 m−n−1
D. m − n + 1 m-n+1 m−n+1分析
对于一颗 n n n 个顶点的无根树,其边数为 n − 1 n - 1 n−1 条,由于原有 m m m 条边,所以应删去 m − n + 1 m - n + 1 m−n+1 条边;
答案
D
第 7 题
题目
二进制数 101.11 对应的十进制数是 ( ) ;
A. 6.5
B. 5.5
C. 5.75
D. 5.25分析
使用权值相加法,
( 101.11 ) 2 = 1 ∗ 2 1 + 1 ∗ 2 0 + 1 ∗ 2 − 1 + 1 ∗ 2 − 2 = 5.75 (101.11)_2 = 1 * 2^1 + 1 * 2^0 + 1 * 2^{-1} + 1 * 2^{-2} = 5.75 (101.11)2=1∗21+1∗20+1∗2−1+1∗2−2=5.75 ;
答案
C
第 8 题
题目
如果一棵二叉树只有根结点,那么这棵二叉树高度为 1。请问高度为 5 的完全二叉树有 ( )种不同的形态?
A. 16
B. 15
C. 17
D. 32分析
由于对于深度为 k k k 的完全二叉树,其最后一层应有 2 k − 1 2^{k - 1} 2k−1 个节点,所以,可根据二叉树最后一层的形态确定整棵树的形态,由于树要保留 5 层,所以最后一层应至少有一个节点,所以原树应有 2 k − 1 − 1 2^{k - 1} - 1 2k−1−1 种形态;
答案
A
第 9 题
题目
表达式 a ∗ ( b + c ) ∗ d a*(b+c)*d a∗(b+c)∗d 的后缀表达式为 ( ) ,其中 * 和 + 是运算符;
A. ∗ ∗ a + b c d **a+bcd ∗∗a+bcd
B. a b c + ∗ d ∗ abc+*d* abc+∗d∗
C. a b c + d ∗ ∗ abc+d** abc+d∗∗
D. ∗ b ∗ + b c d *b*+bcd ∗b∗+bcd分析
将中缀表达式转后缀表达式的步骤大约为,
-
先按照运算符的优先级对中缀表达式加括号,变成 ( ( a ∗ ( b + c ) ) ∗ d ) ((a * (b + c)) * d) ((a∗(b+c))∗d)
-
将运算符移到括号的后面,变成 ( ( a ( b c ) + ) ∗ d ) ∗ ((a (b c) + ) * d) * ((a(bc)+)∗d)∗
-
去括号,得到 a b c + ∗ d ∗ a b c + * d * abc+∗d∗
答案
B
第 10 题
题目
6 个人,两个人组一队,总共组成三队,不区分队伍的编号。不同的组队情况有 ( ) 种;
A. 10
B. 15
C. 30
D. 20分析
则对于前两个人选择时为从 6 个人中无顺序的选择 2 个,对于中间两个人为从 4 个人中无顺序的选择 2 个,对于最后两个人为从 2 个人中无顺序的选择 2 个,但又由于队伍不分编号,所以还要去掉受编 3 个队伍的排列数量;
C 6 2 ∗ C 4 2 ∗ C 2 2 ÷ A 3 3 = 15 C_6^2 * C_4^2 * C_2^2 \div A_3^3 = 15 C62∗C42∗C22÷A33=15
答案
B
第 11 题
题目
在数据压缩编码中的哈夫曼编码方法,在本质上是一种 ( ) 的策略;
A. 枚举
B. 贪心
C. 递归
D. 动态规划分析
哈夫曼编码,又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码的一种;
Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码);由于该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,则利用贪心策略;
答案
B
第 12 题
题目
由 1,1,2,2,3 这五个数字组成不同的三位数有 ( ) 种;
A. 18
B. 15
C. 12
D. 24分析
先看对于不重复使用数字的情况,有 3 ∗ 2 ∗ 1 = 6 3 * 2 * 1 = 6 3∗2∗1=6 种;
再看对于重复使用数字的情况,有 3 ∗ 4 ∗ 1 = 12 3 * 4 * 1 = 12 3∗4∗1=12 种;
答案
A
第 13 题
题目
考虑如下递归算法
solve(n) if n<=1 return 1 else if n>=5 return n*solve(n-2) else return n*solve(n-1)- 1
- 2
- 3
- 4
则调用
solve(7)得到的返回结果为 ( ) ;
A. 105
B. 840
C. 210
D. 420分析
则可模拟程序计算;
solve(1)= 1;solve(2)= 2;solve(3)= 6;solve(4)= 24;solve(5)= 30;solve(6)= 144;solve(7)= 210;答案
C
第 14 题
题目
以 a a a 为起点,对下边的无向图进行深度优先遍历,则 b , c , d , e b,c,d,e b,c,d,e 四个点中有可能作为最后一个遍历到的点的个数为 ( ) ;
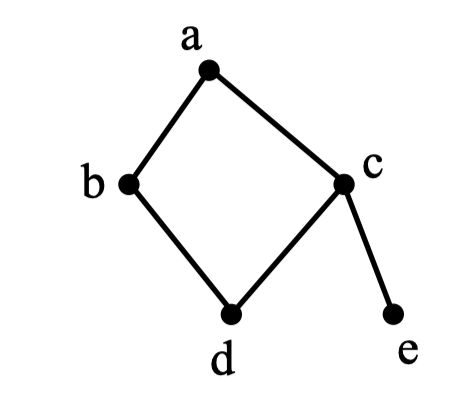
A. 1
B. 2
C. 3
D. 4分析
则对于此图的深度优先遍历的序列为,
-
a → b → d → c → e a \rightarrow b \rightarrow d \rightarrow c \rightarrow e a→b→d→c→e
-
a → c → e → d → b a \rightarrow c \rightarrow e \rightarrow d \rightarrow b a→c→e→d→b
则有两种可能;
答案
B
第 15 题
题目
有四个人要从 A 点坐一条船过河到 B 点,船一开始在 A 点。该船一次最多可坐两个人。 已知这四个人中每个人独自坐船的过河时间分别为 1, 2, 4, 8,且两个人坐船的过河时间为两人独自过河时间的较大者。则最短 ( ) 时间可以让四个人都过河到 B 点(包括从 B 点把船开回 A 点的时间);
A. 14
B. 15
C. 16
D. 17分析
此题使用贪心算法,贪心策略为尽量使用速度快的人划返程船;
过程如下,
- 使过河时间为 1, 2 的人过河,再使过河时间为 1 的人划返程船;
- 使过河时间为 4, 8 的人过河,再使过河时间为 2 的人划返程船;
- 使过河时间为 1, 2 的人过河;
总时间为 2 + 1 + 8 + 2 + 2 = 15 2 + 1 + 8 + 2 + 2 = 15 2+1+8+2+2=15 ;
答案
B
二、阅读程序
第 16 题
代码
#includeusing namespace std; int n; int a[1000]; int f(int x) { int ret = 0; for (; x; x &= x - 1) { ret++; } return ret; } int g(int x){ return x & -x; } int main() { cin >> n; for (int i = 0; i < n;i++) cin >> a[i]; for (int i = 0; i < n;i++) cout << f(a[i]) + g(a[i]) << " "; cout << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
程序解释
#includeusing namespace std; int n; int a[1000]; int f(int x) // 对于非负数,为 x 二进制中 1 的个数,对于负数,为 x 中二进制位数 { int ret = 0; for (; x; x &= x - 1) { ret++; } return ret; } int g(int x){ // x 二进制最后一位 return x & -x; } int main() { cin >> n; for (int i = 0; i < n;i++) cin >> a[i]; for (int i = 0; i < n;i++) cout << f(a[i]) + g(a[i]) << " "; cout << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
判断题
-
输入的 n 等于 1001 时,程序不会发生下标越界; ( )
分析
数组 a 的下标范围为 0 ∼ 999 0 \sim 999 0∼999 所以当 n 为 1001 时,程序会越界;
答案
错误
-
输入的 a[i] 必须全为正整数,否则程序将陷入死循环; ( )
分析
当 a[i] = 0 时,程序正常运行;
答案
错误
-
当输入为
5 2 11 9 16 10时,输出为3 4 3 17 5; ( )分析
则有,
原数 2 11 9 16 10 二进制 10 1011 1001 10000 1010 f(n) 1 3 2 1 2 g(n) 2 1 1 16 2 输出 3 4 3 17 4 应输出
3 4 3 17 4答案
错误
-
当输入为
1 511998时,输出为18; ( )分析
511998 = ( 1111100111111111110 ) 2 511998 = (111 1100 1111 1111 1110)_2 511998=(1111100111111111110)2 ,则输出 18;
答案
正确
-
将源代码中
g函数的定义( 14 ∼ 17 14\sim 17 14∼17 行)移到 main 函数的后面,程序可以正常编译运行; ( )分析
如要将函数程序移到main 函数的后面,则应在 main 函数的前面声明定义才可过编译;
答案
错误
单选题
-
当输入为
2 -65536 2147483647时,输出为 ( ) ;
A.65532 33
B.65552 32
C.65535 34
D.65554 33分析
原数 -65536 2147483647 二进制 1 0000 0000 0000 0000 1111111111111111111111111111111 f(n) 16 31 g(n) 65536 1 输出 65552 32 答案
B
第 17 题
代码
#includeusing namespace std; char base[64]; char table[256]; void init() { for (int i = 0; i < 26; i++) base[i] = 'A' + i; for (int i = 0; i < 26; i++) base[26 + i] = 'a' + i; for (int i = 0; i < 10; i++) base[52 + i] = '0' + i; base[62] = '+', base[63] = '/'; for (int i = 0; i < 256; i++) table[i] = 0xff; for (int i = 0; i < 64; i++) table[base[i]] = i; table['='] = 0; } string decode(string str) // 解码 { string ret; int i; for (i = 0; i < str.size(); i += 4){ ret += table[str[i]] << 2 | table[str[i + 1]] >> 4; if (str[i + 2] != '=') ret += (table[str[i + 1]] & 0x0f) << 4 | table[str[i + 2]] >> 2; if(str[i + 3] != '=') ret += table[str[i + 2]] << 6 | table[str[i + 3]]; } return ret; } int main() { init(); cout << int(table[0]) << endl; string str; cin >> str; cout << decode(str) << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
程序解释
Base64就是用来将非 ASCII 字符的数据转换成 ASCII 字符的一种方法,特别适合在 http,mime 协议下快速传输数据,也可以用来加密;#includeusing namespace std; char base[64]; char table[256]; void init() { for (int i = 0; i < 26; i++) base[i] = 'A' + i; // 用 base[0] ~ base[25] 存储所有大写字母 for (int i = 0; i < 26; i++) base[26 + i] = 'a' + i; // 用 base[26] ~ base[51] 存储所有小写字母 for (int i = 0; i < 10; i++) base[52 + i] = '0' + i; // 用 base[52] ~ base[61] 存储所有数字 base[62] = '+', base[63] = '/'; // 用 base[62] 存储 + , base[63] 存储 / for (int i = 0; i < 256; i++) table[i] = 0xff; // 初始化 table; for (int i = 0; i < 64; i++) table[base[i]] = i; // 则对于 table[i] 存储 i 在 base 的下标 table['='] = 0; } string decode(string str) // 解码 { string ret; int i; for (i = 0; i < str.size(); i += 4){ // 以每 4 个字符一次遍历字符串,并对字符串解码 ret += table[str[i]] << 2 | table[str[i + 1]] >> 4; if (str[i + 2] != '=') ret += (table[str[i + 1]] & 0x0f) << 4 | table[str[i + 2]] >> 2; if(str[i + 3] != '=') ret += table[str[i + 2]] << 6 | table[str[i + 3]]; } return ret; } int main() { init(); cout << int(table[0]) << endl; // 由于 base 内没有存储 0 ,所以 table[0] 值应为 0xff,由于 char 为 8 位,所以输出 -1 string str; cin >> str; // 输入字符串 cout << decode(str) << endl; // 解码 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
判断题
-
输出的第二行一定是由小写字母、大写字母、数字和 +,/,= 构成的字符串; ( )
分析
由于 table 数组下标的有效位为 0 - 63,但在解码过程中进行位运算时,其的值会超过此范围,所以还会输出其他的字符,例如空格;
答案
错误
-
可能存在输入不同,但输出的第二行相同的情形; ( )
分析
由于字符串结尾的
=不会参与解码,则a=与a==输出结果相同;答案
正确
-
输出的第一行为
-1; ( )分析
0xFF = FF(16) = 11111111(2) = char(-1) ,则正确;
答案
正确
单选题
-
设输入字符串长度为 n,
decode函数的时间复杂度为 ( ) ;A. O ( n ) O(\sqrt{n}) O(n)
B. O ( n ) O(n) O(n)
C. O ( n log n ) O(n \log n) O(nlogn)
D. O ( n 2 ) O(n^2) O(n2)分析
decode函数中循环为以每 4 个字符一次遍历字符串,则复杂度为 O ( n ) O(n) O(n) ;答案
B
-
当输入为
Y3Nx时,输出的第二行为 ( ) ;A.
csp
B.csq
C.CSP
D.Csp分析
带入计算即可;
字母 table表下标table表下标二进制Y 24 011000 3 55 110111 N 13 001101 x 49 110001 则原字符串为
011000 110111 001101 110001;将以上数据链接并重新编码得
01100011 01110011 01110001;转化为
csq;答案
B
-
当输入为
Y2NmIDIwMjE=时,输出的第二行为 ( ) ;A.
ccf2021
B.ccf2022
C.ccf 2021
D.ccf 2022分析
由于原字符串位数为 12 位,所以现字符串应有 3 + 3 + 2 = 8 位,则可排除
A与B;则判断
MjE=解码为 21 还是 22 即可;即判断
jE=解码为 1 还是 2 即可;字母 table表下标table表下标二进制j 35 100011 E 4 000100 即
(100011 & 001111) << 4 | 100 >> 2 = 110001 = 49,即1;答案
C
第 18 题
代码
#includeusing namespace std; const int n = 100000; const int N = n + 1; int m; int a[N],b[N],c[N],d[N]; int f[N],g[N]; void init() { f[1] = g[1] = 1; for (int i = 2; i <= n; i++) { if (!a[i]) { b[m++] = i; c[i] = 1,f[i] = 2; d[i] = 1,g[i] = i + 1; } for (int j = 0; j < m && b[j] * i <= n; j++) { int k = b[j]; a[i * k] = 1; if (i * k == 0) { c[i * k] = c[i] + 1; f[i * k] = f[i] / c[i * k] * (c[i * k] + 1); d[i * k] = d[i]; g[i * k] = g[i] * k + d[i]; break; } else { c[i * k] = 1; f[i * k] = 2 * f[i]; d[i * k] = g[i]; g[i * k] = g[i] * (k + 1); } } } } int main() { init(); int x; cin >> s; cout << f[x] << ' ' << g[x] << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
程序解释
程序为改变后的欧拉筛;
a数组表示 i i i 是否为质数;b数组为质数表;c数组表示 i i i 中最小质因数的个数;f数组表示 i i i 因数的个数;g数组表示 i i i 因数的和;d数组有d[i] = (k + 1) * g[i],此时k为i的最小质因数;#includeusing namespace std; const int n = 100000; const int N = n + 1; int m; int a[N],b[N],c[N],d[N]; int f[N],g[N]; void init() { f[1] = g[1] = 1; for (int i = 2; i <= n; i++) { // 枚举倍数 i if (!a[i]) { // 质数 b[m++] = i; // 将 i 放入质数列表 c[i] = 1, f[i] = 2; // 先将 i 的最小质因数数量设为 1 ,再将因数个数设为 2 d[i] = 1, g[i] = i + 1; // i 为质数,因数和即为 i + 1 } for (int j = 0; j < m && b[j] * i <= n; j++) { // 最小质因数 * 倍数 <= n int k = b[j]; // k 为当前质数 a[i * k] = 1; // 标记质数 k 的 i 倍为合数 if (i % k == 0) { // i * k 的最小质因数为 k c[i * k] = c[i] + 1; // i * k 的最小质因数数量加 1 f[i * k] = f[i] / c[i * k] * (c[i * k] + 1); // 计算因数个数 d[i * k] = d[i]; g[i * k] = g[i] * k + d[i]; // 计算因数和 break; } else {// i 的最小质因数不为 k c[i * k] = 1; f[i * k] = 2 * f[i]; d[i * k] = g[i]; g[i * k] = g[i] * (k + 1); } } } } int main() { init(); int x; cin >> x; cout << f[x] << ' ' << g[x] << endl; // 输出 x 的因数个数与因数和 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
判断题
-
若输入不为
1,把第 13 行删去不会影响输出的结果; ( )分析
由于计算时没有有关
1的值,所以不会影响结果;答案
正确
-
第 25 行的
f[i] / c[i * k]可能存在无法整除而向下取整的情况; ( )分析
25 行时
i * k的最小质因数为k所以不会发生;答案
错误
-
在执行完
init()后,f数组不是单调递增的,但g数组是单调递增的; ( )分析
两数组均不单调;
答案
错误
单选题
-
init函数的时间复杂度为 ( ) ;A. O ( n ) O(n) O(n)
B. O ( n log n ) O(n \log n) O(nlogn)
C. O ( n n ) O(n\sqrt{n}) O(nn)
D. O ( n 2 ) O(n^2) O(n2)分析
欧拉筛为线性筛,每个数只会被筛一次,则时间复杂度为 O ( n ) O(n) O(n) ;
答案
A
-
在执行完
init()后,f[1], f[2], f[3], ... ,f[100]中有 ( ) 个等于 2;A. 23
B. 24
C. 25
D. 26分析
即为因数有 2 个的数的个数,即 1 ~ 100 中质数的个数,即 25 个;
答案
C
-
当输入为
1000时,输出为 ( ) ;A.
15 1340
B.15 2340
C.16 2340
D.16 1340分析
即 1000 的因数个数与因数之和;
答案
A
三、完善程序
第 19 题
(Josephus 问题)有 n 个人围成一个圈,依次标号 0 至 n - 1。从 0 号开始,依次 0 , 1 , 0 , 1 , … 交替报数,报到 1 的人会离开,直至圈中只剩下一个人。求最后剩下人的编号。
试补全模拟程序。
#includeusing namespace std; const int MAXN=1000000; int F[MAXN]; int main(){ int n; scanf("%d",&n); int i=0,p=0,c=0; while( ① ){ if(F[i]==0){ if( ② ){ F[i]=1; ③; } ④ ; } ⑤ ; } int ans=-1; for(int i=0;i - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
通过 13,15 行可猜测
f[i]表示 i 是否报过数;-
①处应填 ( ) ;
A.i < n
B.c < n
C.i < n- 1
D.c < n-1分析
则判断何时完成报数,即淘汰个数
c等于n - 1时;答案
D
-
②处应填 ( ) ;
A.i % 2 == 0
B.i % 2 == 1
C.p
D.!p分析
即判断此时人报 0 还是 1 ,所以判断报数
p是否为1即可;答案
C
-
③处应填 ( ) ;
A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1分析
15 行表示报到 1 标记了离开,则计数
c应 +1;答案
C
-
④处应填 ( ) ;
A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1分析
即应让
p0,1 交替,所以使用^即可;答案
D
-
⑤处应填 ( ) ;
A.i++
B.i = (i + 1) % n
C.c++
D.p ^= 1分析
⑤处为判断当前情况完毕后,则应继续寻找下一个位置,又因为人排成了环,所以应取模;
答案
B
第 20 题
(矩形计数) 平面上有 n 个关键点,求有多少个四条边都和 x 轴或者 y 轴平行的矩形,满足四个顶点都是关键点。给出的关键点可能有重复,但完全重合的矩形只计一次。
#includeusing namespace std; struct point{ int x, y, id; }; bool equals(point a, point b){ return a.x == b.x && a.y == b.y; } boolt cmp(point a, point b){ return ①; } void sort(point A[], int n){ for(int i = 0; i < n; i++) for(int j = 1; j < n; j++) if(cmp(A[j], A[j - 1])){ struct point t=A[j]; A[j] = A[j - 1]; A[j - 1] = t; } } int unique(point A[],int n){ int t=0; for(int i = 0; i < n; i++) if(②) A[t++] = A[i]; return t; } bool binary_search(point A[], int n, int x, int y){ point p; p.x = x; p.y = y; p.id = n; int a = 0, b = n - 1; while(a < b){ int mid=③; if(④) a = mid + 1; else b = mid; } return equals(A[a], p); } const int MAXN = 1000; point A[MAXN]; int main(){ int n; cin >> n; for(int i = 0; i < n; i++){ cin >> A[i].x >> A[i].y; A[i].id = i; } sort(A,n); n = unique(A, n); int ans = 0; for(int i = 0; i < n; i++) for(int j = 0; j < n; j++) if(⑤&& binary_search(A, n, A[i].x, A[j].y) && binary_search(A, n, A[j].x, A[i].y)){ ans++; } cout << ans << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
试补全枚举算法。
-
①处应填 ( ) ;
A.a.x != b.x ? a.x < b.x : a.id < b.id
B.a.x != b.x ? a.x < b.x : a.y < b.y
C.equals(a, b) ? a.id < b.id : a.x < b.x
D.equals(a, b) ? a.id < b.id : (a.x != b.x ? a.x < b.x : a.y < b.y)分析
排序中从交换操作看出使用冒泡排序,按照 x, y 双关键字排序;
答案
B
-
②处应填 ( ) ;
A.i == 0 || cmp(A[i], A[i - 1])
B.t == 0 || equals(A[i], A[t - 1])
C.i == 0 || !cmp(A[i], A[i - 1])
D.t == 0 || !equals(A[i], A[t - 1])分析
由于点可能重复,所以应该去重,即判断上一个点与当前点是否相同;
答案
D
-
③处应填 ( ) ;
A.b - (b - a) / 2 + 1
B.a + b + 1) >> 1
C.(a + b) >> 1
D.a + (b - a + 1) / 2分析
二分找中点;
答案
C
-
④处应填 ( ) ;
A.!cmp(A[mid], p)
B.cmp(A[mid], p)
C.cmp(p, A[mid])
D.!cmp(p, A[mid])分析
即满足何条件向大的方向查找,则为用 mid 比要找的 p 小了;
答案
B
-
⑤处应填 ( ) ;
A.A[i].x == A[j].x
B.A[i].id < A[j].id
C.A[i].x == A[j].x && A[i].id < A[j].id
D.A[i].x < A[j].x && A[i].y < A[j].y分析
由于不能保证 i 与 j 为一左一右,所以 j 与 i 会产生一样的矩形,则判断即可;
答案
D
-

如何在windows linux子系统Ubuntu 22.04.2 TLS中安装nvm
【软件测试】作为测试人,因工作与开发吵了一架碰撞,该咋办......
【PAT甲级 - C++题解】1120 Friend Numbers
QT 5.14.2版本 MAC环境安装部署流程
react中受控组件与非受控组件
基于vue+node+mysql的视频校对系统
深入探索Spring AI:源码分析流式回答
【LeetCode刷题】面试题 17.19. 消失的两个数字
5、Spring cloud注册中心之zookeeper