-
注意力机制(attention)学习笔记
注意力机制可以大幅提高模型的准确性,如在RNN文本翻译中其会计算与所有状态的相关性,并得出权重,即他会考虑所有状态并给出最重要的关注,这也就是注意力命名的由来,与此同时,关注所有的状态也必定需要大量的计算。
seq2seq模型(其有两个RNN网络构成,分别为encode和decode),一种常用于实现文本翻译的模型,其结构如下
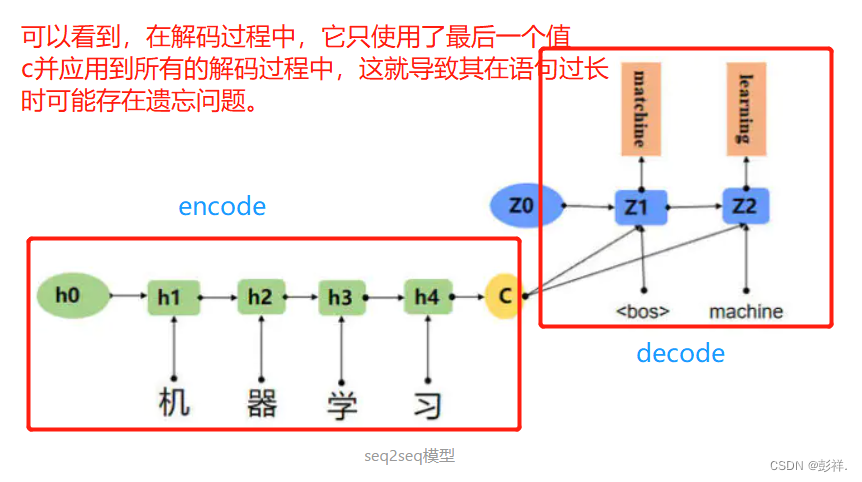
面对采用相同状态c导致的遗忘与无差别问题,我们提出了注意力机制。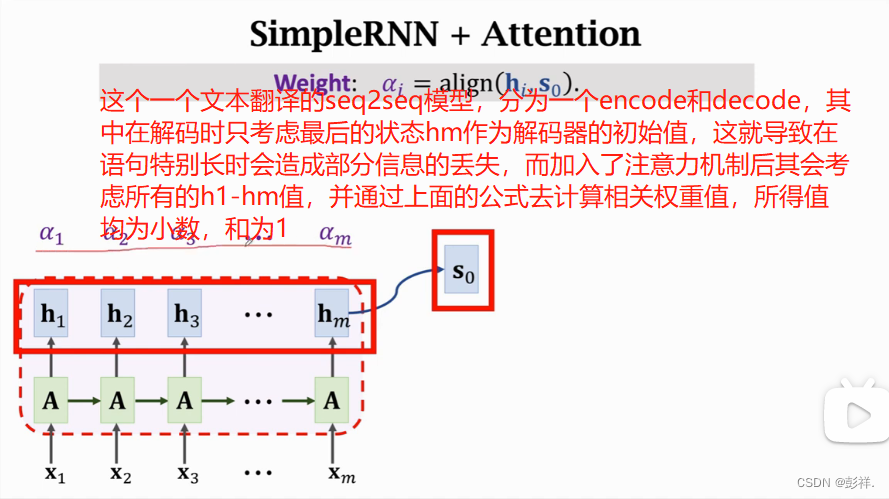
如何计算这个权重呢,这是注意力机制刚刚提出时采用的方法。
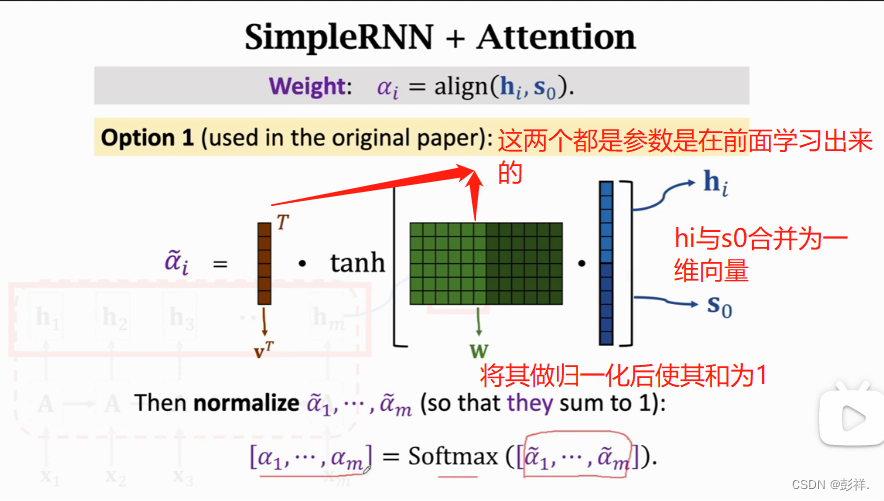
目前较为流行的方式:


c0所得即为其加权平均
在加入注意力机制后如何更新状态。
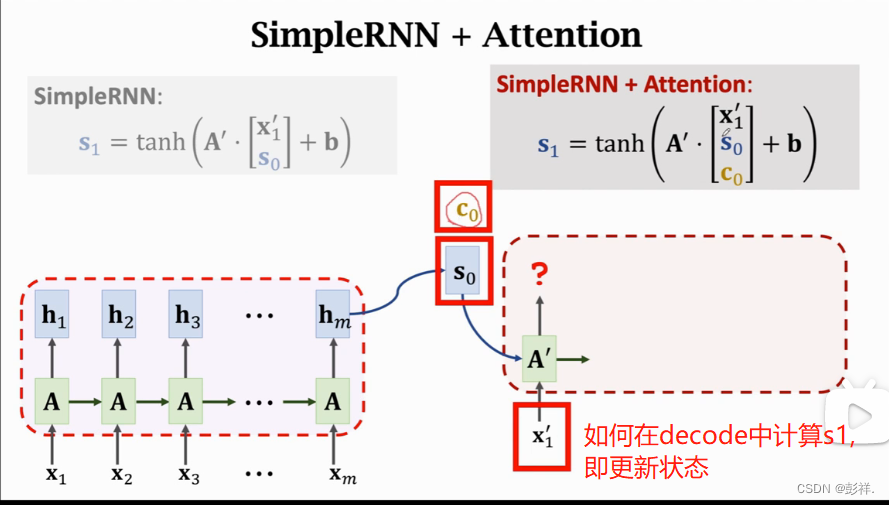
注意力机制使其考虑先前的所有信息,从而解决了遗忘的问题,第一次的权重值是通过与s0计算相关性得到的,同样,后面s1也与前面的hi计算相关性,以此类推。

我们要想计算出ci,则需要计算m个权重值,对于一个由t个状态的解码信息,我们总共需要计算m*t此权重,这个时间复杂度即为m*t,这个计算量是很高的,attention考虑所有的情况,解决了遗忘的问题,但付出的代价也是昂贵的。

直观理解注意力机制,即decode每要生成一种状态,都要去关注encode中的所有状态,即每个状态间都有连接,而连线的粗细则反映两者的相关程度,如法语中的zone就是英语中的Area,通过这个权重他告诉decode更去关注encode中哪一个状态,这也是attention命名的由来。


关于注意力机制的总结:
对于seq2seq模型,encode只关注当前的状态,即s1只看s2,而注意力机制的加入让其考虑前面encode中所有的状态,这就解决了遗忘的问题,同时由于计算了相关权重,其能够让我们知道更去关注哪个状态。
缺点:
高时间复杂度,同时伴随着大量的计算。Attention最开始时应用在了seq2seq模型中,但其并不局限于此,其可以用于任何RNN模型中。如LSTM



这就是self-attention,这种不再局限于简单的seq2seq,而是可以应用到所有的RNN模型中去提升精确度。 -
相关阅读:
Stability AI发布Stable Diffusion 3;谷歌修复Gemini大模型文生图多元化Bug;李一舟AI课遭下架
精准测试(针对人工执行的测试用例和自动化测试脚本)
如何将文件或者图片压缩成zip文件压缩包
传世引擎常见报错如何解决
Spring对JUnit的支持
京东JD开放平台API接口调用采集商品详情数据获取商品规格信息、销量、卖家信息抓取案例
操作系统MIT6.S081:[xv6参考手册第4章]->Trap与系统调用
SCI论文高效写作:Citespace、vosviewer和R语言在文献调研与论文撰写中的应用
springclout Config刷新配置源码解析
Linux:虚拟机的安转和静态IP的设置过程记录
- 原文地址:https://blog.csdn.net/pengxiang1998/article/details/126794934