-
【Django】开发日报_1.1_Day:模板语法
模板语法:在HTML中写一些占位符,由数据对这些占位符进行替换和处理。
目录
1、新建模板
新建html文件:
tpl.html:
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- body>
- html>
编写views视图函数和URL路径:
views.py:
- from django.shortcuts import render,HttpResponse
- # Create your views here.
- def index(request):
- return HttpResponse("Hello Django!")
- def user_list(requets):
- return render(requets,'user_list.html')
- def user_add(requets):
- return render(requets,'user_add.html')
- def tpl(requets):
- return render(requets,'tpl.html')
urls.py:
- from django.urls import path
- from app import views
- urlpatterns = [
- path('index/', views.index),
- path('user/list/',views.user_list),
- path('user/add/',views.user_add),
- path('tpl/',views.tpl)
- ]
打开http://127.0.0.1:8000/tpl/网页:
2、字典传参--基本数据类型&语法
(1)参数:字符串
views.py
- def tpl(requets):
- name="代码骑士"
- return render(requets,'tpl.html',{"n1":name})
tpl.html
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <div>{{ n1 }}div>
- body>
- html>
访问页面:

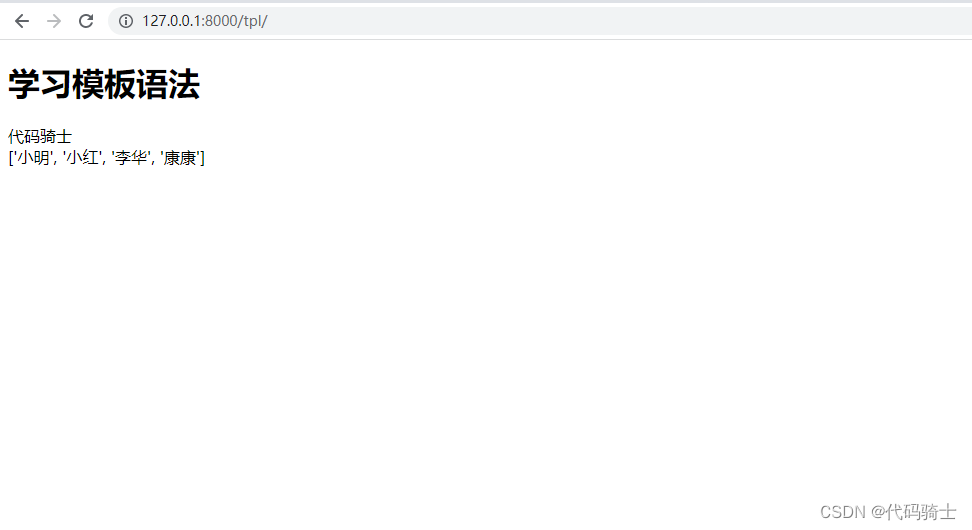
(2)参数:列表
views.py
- def tpl(requets):
- name="代码骑士"
- name_list=["小明","小红","李华","康康"]
- return render(requets,'tpl.html',{"n1":name,"n2":name_list})
tpl.html
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <div>{{ n1 }}div>
- <div>{{ n2 }}div>
- body>
- html>
访问页面
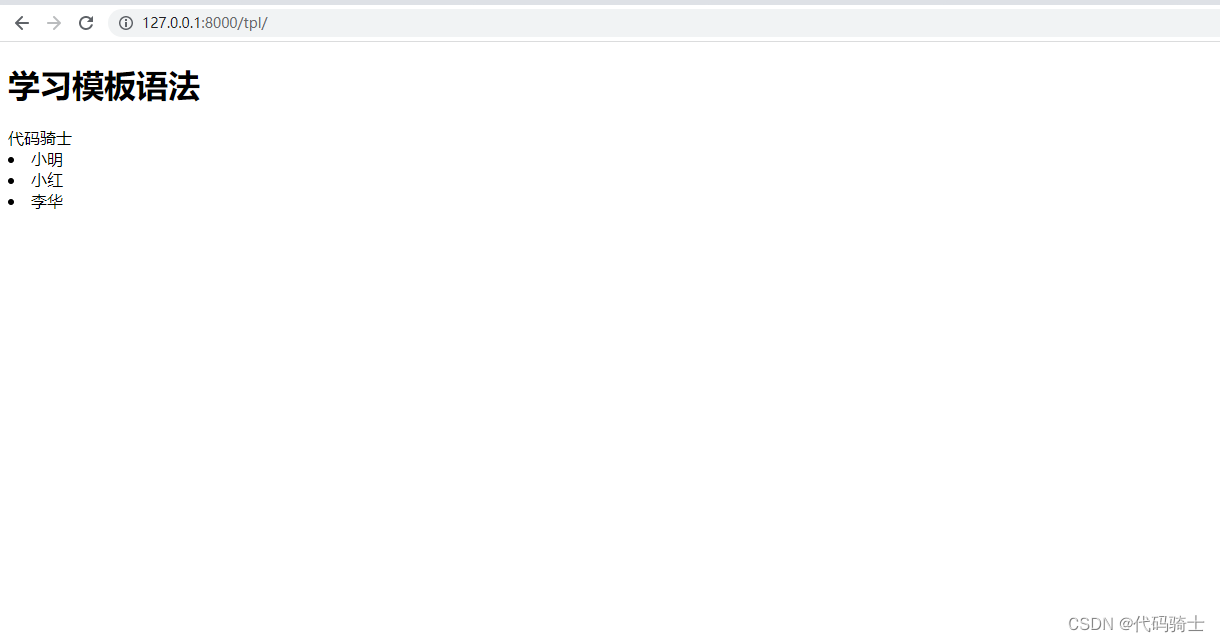
(3)用索引显示列表元素
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <div>{{ n1 }}div>
- <li>{{ n2.0 }}li>
- <li>{{ n2.1 }}li>
- <li>{{ n2.2 }}li>
- body>
- html>
访问页面:
(4)语法:循环
tpl.html
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <div>{{ n1 }}div>
- <div>
- {% for item in n2 %}
- <li>{{ item }}li>
- {% endfor %}
- div>
- body>
- html>
访问网页:

(5)参数:字典
views.py
- def tpl(requets):
- name="代码骑士"
- name_list=["小明","小红","李华","康康"]
- role_dicts={"name":"小明","salary":100000,"position":"CEO"}
- return render(requets,'tpl.html',{"n1":name,"n2":name_list,"n3":role_dicts})
对于处理字典值的不同写法
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <hr/>
- <div>{{ n1 }}div>
- <hr/>
- <div>
- {% for item in n2 %}
- <li>{{ item }}li>
- {% endfor %}
- div>
- <hr/>
- <div>
- {{ n3.name }}
- {{ n3.salary }}
- {{ n3.position }}
- <ul>
- {% for item in n3.keys %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for item in n3.values %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for item in n3.items %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for k,v in n3.items %}
- <li>{{ k }}={{ v }}li>
- {% endfor %}
- <hr/>
- ul>
- div>
- body>
- html>
访问页面:

(6)参数:字典列表
views.py
- def tpl(requets):
- name="代码骑士"
- name_list=["小明","小红","李华","康康"]
- role_dicts={"name":"小明","salary":100000,"position":"CEO"}
- data_list=[
- {"name": "小明", "salary": 100000, "position": "CEO"},
- {"name": "小红", "salary": 100000, "position": "HR"},
- {"name": "康康", "salary": 100000, "position": "CTO"}
- ]
- return render(requets,'tpl.html',{"n1":name,"n2":name_list,"n3":role_dicts,"n4":data_list})
tpl.py
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Titletitle>
- head>
- <body>
- <h1>学习模板语法h1>
- <hr/>
- <div>{{ n1 }}div>
- <hr/>
- <div>
- {% for item in n2 %}
- <li>{{ item }}li>
- {% endfor %}
- div>
- <hr/>
- <div>
- {{ n3.name }}
- {{ n3.salary }}
- {{ n3.position }}
- <ul>
- {% for item in n3.keys %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for item in n3.values %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for item in n3.items %}
- <li>{{ item }}li>
- {% endfor %}
- <hr/>
- {% for k,v in n3.items %}
- <li>{{ k }}={{ v }}li>
- {% endfor %}
- <hr/>
- ul>
- div>
- <hr/>
- <div>
- {{ n4.0 }}
- <br/>
- {{ n4.0.name }}
- <br/>
- {{ n4.0.salary }}
- div>
- <hr/>
- <div>
- 姓名|薪资
- {% for item in n4 %}
- <div>{{ item.name }}|{{ item.salary }}div>
- {% endfor %}
- div>
- body>
- html>
访问页面:

(7)语法:条件语句
tpl.html
- <div>
- {% if n1 == "代码骑士" %}
- <h2>Hello!h2>
- {% elif n1 == "代码超人" %}
- <h2>Hi!h2>
- {% else %}
- <h3>你找错人了。h3>
- {% endif %}
- div>
访问页面:

3、Django框架常用文件的基本流程

4、小案例:伪联通新闻中心(爬chong)
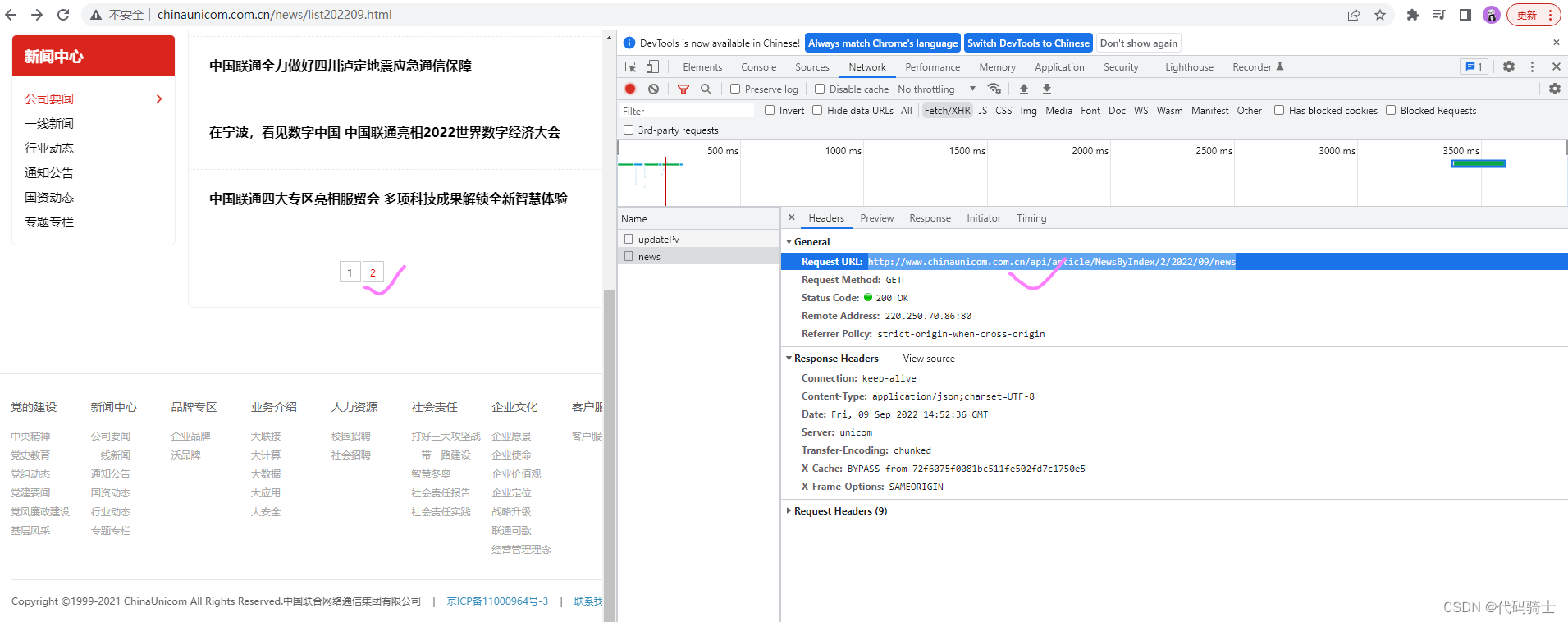
使用爬虫获取新闻网页数据:http://www.chinaunicom.com.cn/news/list202209.html
获取请求网址:http://www.chinaunicom.com.cn/api/article/NewsByIndex/2/2022/09/news
 编写views.py里面的视图函数
编写views.py里面的视图函数*注意爬虫消息头需要使用代理,否则爬取不到json文件
- def news(requet):
- #定义一个列表或字典存储数据
- #向网址:http://www.chinaunicom.com.cn/api/article/NewsByIndex/2/2022/09/news发送请求
- #使用第三方模块:requests
- import requests
- url = "http://www.chinaunicom.com.cn/api/article/NewsByIndex/2/2022/09/news"
- headers = {'User-Agent': 'Mozilla/4.0'}
- res = requests.get(url,headers=headers)
- data_list=res.json()
- print(data_list)
- return render(requet,'news.html',{"news_list":data_list})
编写urls.py文件
- path('news/',views.news)
编写模板news.html
- html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>联通新闻中心title>
- head>
- <body>
- <h1>联通新闻中心h1>
- <div>
- <ul>
- {% for item in news_list %}
- <li>新闻:{{ item.news_title }} 发布时间:{{ item.post_time }}li>
- {% endfor %}
- ul>
- div>
- body>
- html>
一个简单的爬虫页面就做好了:

5、最后不要忘记将改动的代码同步码云

-
相关阅读:
SPA项目开发之 分页+数据表格+分页
并发程序设计,你真的懂吗?
StretchBlt()、Bitblt用法详解
QT:绘图
JAVAEE框架技术之17之SSM综合案例 角色管理
制作一个简单HTML抗疫逆行者网页作业(HTML+CSS)
球场输了?卡塔尔背地里可能赢麻了!
aso标题关键词可以重复吗
Image Sensor卷帘曝光(Rolling Shutter)基本原理
delphi xe FMX里的窗口如何像处理像VCL里的消息又一示例
- 原文地址:https://blog.csdn.net/qq_51701007/article/details/126789665