-
Python面试知识点
Python面试知识点
垃圾回收机制

垃圾回收机制(简称:GC) 是python解释器中自带的一种机制, 专门用来回收不同的变量值所占用的内存空间
1 引用计数: 变量值被变量名关联的次数
1.1 直接引用
1.2 间接引用
在列表,集合,字典中引用
2 标记清除
问题一:循环引用
引用计数机制存在着一个致命的弱点,即循环引用(也称交叉引用)
解决方案
1、标记
通俗地讲就是:栈区相当于“根”,凡是从根出发可以访达(直接或间接引用)的,都称之为“有根之人”,有根之人当活,无根之人当死。
具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),
然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。2、清除
清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
问题二:效率问题
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,
于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。解决方案:分代回收
分代:分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,
gc对其扫描的频率会降低,具体实现原理如下:
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,
那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),
会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,
这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低字符编码
ASCII表
1 只支持英文字符串 2 采用8位二进制数对应一个英文字符串- 1
- 2
GBK表
1 支持英文, 中文字符 2 采用8位(8 bit =1 Bytes) 二进制数对应一个英文字符串 采用16位(16 bit = 1 Bytes) 二进制数敌营一个中文字符串- 1
- 2
- 3
unicode(内存中统一使用unicode)
1 兼容万国字符 与万国字符都有关系 2 采用16位(16 bit = 1 Bytes) 二进制数对应一个中文字符串 个别生僻字会采用 4 Bytes 或者 8 Bytes 两个版本: ucs2: 用两个字节对应一个字符 ucs4: 用四个字节对应一个字符- 1
- 2
- 3
- 4
- 5
- 6
- 7
utf-8: unicode transform format - 8
unicode码位范围 转换模版 0000-007F 用1个字节表示 0XXXXXXX 0080-07FF 用2个字节表示 110XXXXX10XXXXXX 0800-FFFF 用3个字节标识 1110XXXX10XXXXXX10XXXXXX 10000-10FFFF 用4个字节表 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 英文 - 1 Bytes 汉字 - 3 Bytes- 1
- 2
- 3
- 4
- 5
- 6
- 7
结论:
1 内存固定使用 Unicode 我们可以改变的是存入硬盘采用的格式 英文, 中文 -> unicode -> GBK 英文, 日文 -> unicode -> shift-jis 万国字符 -> Unicode -> utf-8 2 文本文件存取乱码问题 2.1 存乱: 解决方法, 编码格式应该设置成支持文件内字符串格式 2.2 取乱: 解决方法: 文件是以什么编码格式存在硬盘的, 就以什么编码格式读入内存 3 python 解释器默认读文件的编码 python3: utf-8 python2: ASCII 4 保证运行 python 程序的前两个阶段不乱码的核心法则 指定文件头 #-*- utf-8 -*- # coding: 文件当初存入银盘是所采用的的编码格式 # coding: utf-8- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
装饰器
无参装饰器
def outter(func): @wraps(func) # 效果跟下述注释代码相同 def wrapper(*args, **kwargs): # 1 调用原函数 # 2 为其添加新功能 res = func(*args, **kwargs) return res return wrapper @outter def func1(): pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
有参装饰器
def outter(par1="Par1", par2="Par2"): def deco(func): @wraps(func) def wrapper(*args, **kwargs): # 1 调用原函数 # 2 为其添加新功能 res = func(*args, **kwargs) return res return wrapper return deco @outter(par1="hello", par2="zhangsan") def func2(): pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
装饰器叠加
def deco1(func): def wrapper(*args, **kwargs): print("deco1.wrapper is running") res = func(*args, *kwargs) print("deco1.wrapper is end") return res return wrapper def deco2(func): def wrapper(*args, **kwargs): print("deco2.wrapper is running") res = func(*args, *kwargs) print("deco2.wrapper is end") return res return wrapper def deco3(x): def outter(func): def wrapper(*args, **kwargs): print("deco3.wrapper is running") res = func(*args, *kwargs) print("deco3.wrapper is end") return res return wrapper return outter # 1 加载顺序 : 自下而上 """ @deco1 # index = deco1(deco2.wrapper) => index = deco1.wrapper 的内存地址 @deco2 # deco2.wrapper = deco2(deco2.wrapper) => index = deco2.wrapper 的内存地址 @deco3(11) # deco3.wrapper = deco3(index) => index = deco3.wrapper 的内存地址 def index(): pass """ # 2 运行顺序 自上而下 """ deco1.wrapper is running deco2.wrapper is running deco3.wrapper is running index is running deco3.wrapper is end deco2.wrapper is end deco1.wrapper is end """ @deco1 @deco2 @deco3(1) def index(): print("index is running") index()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
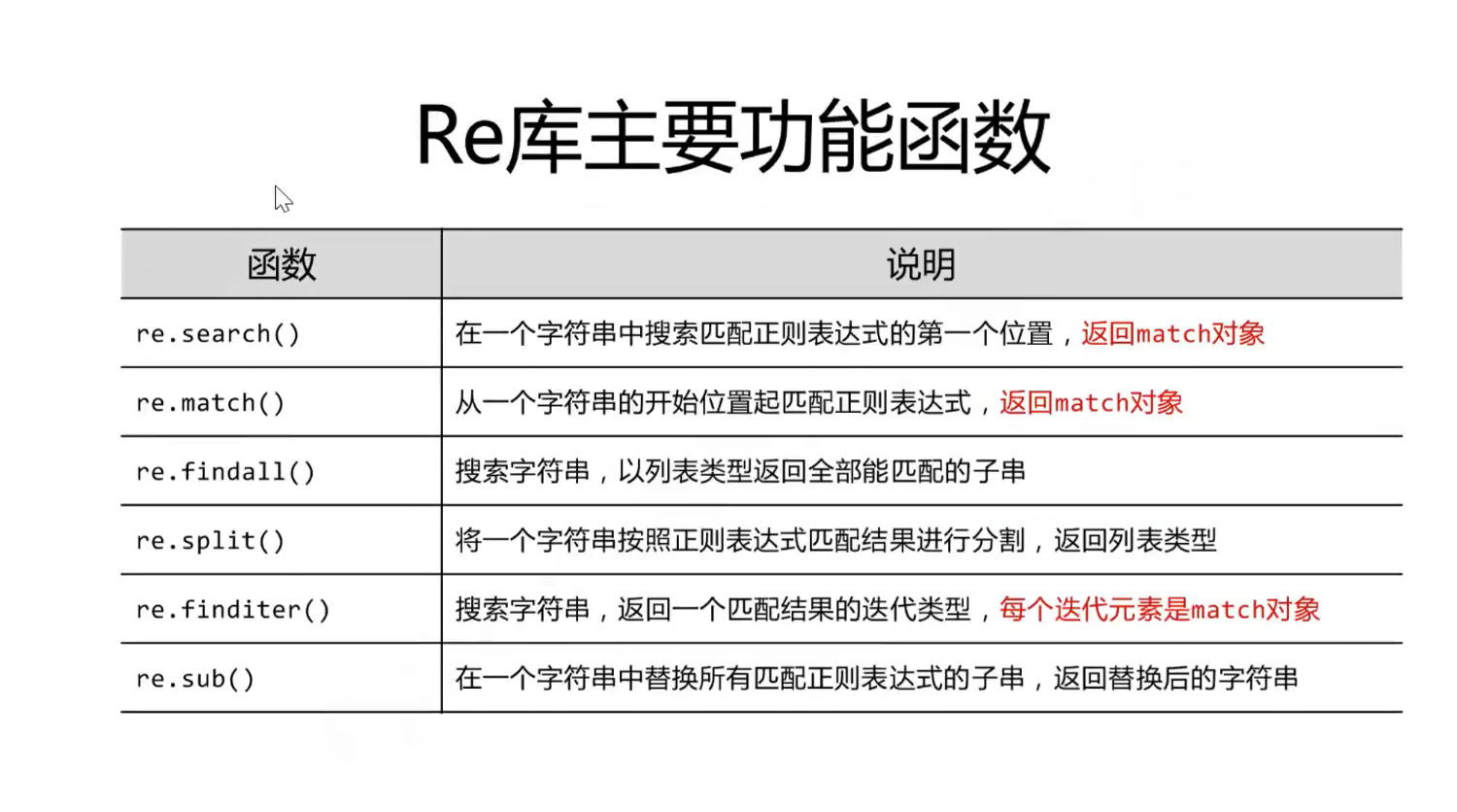
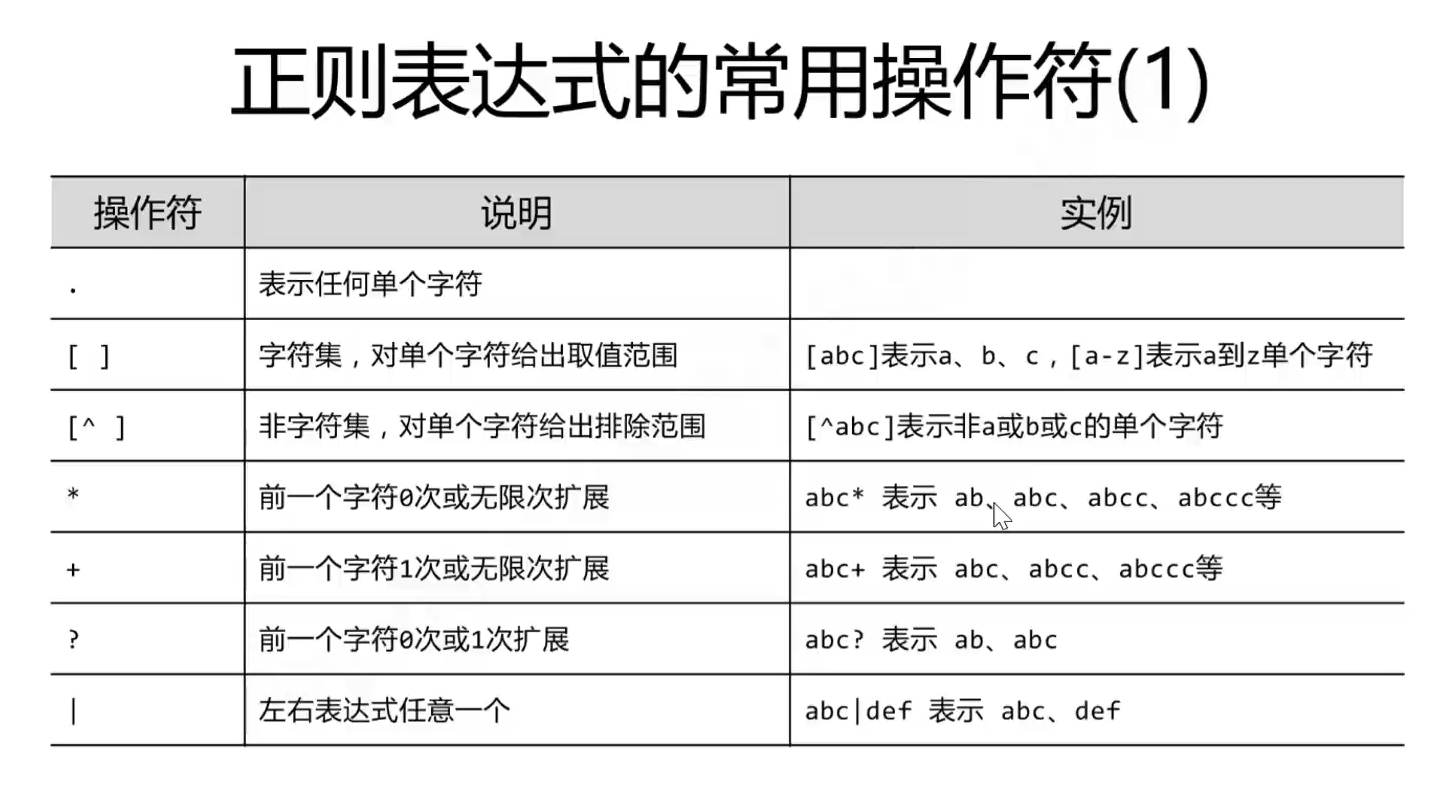
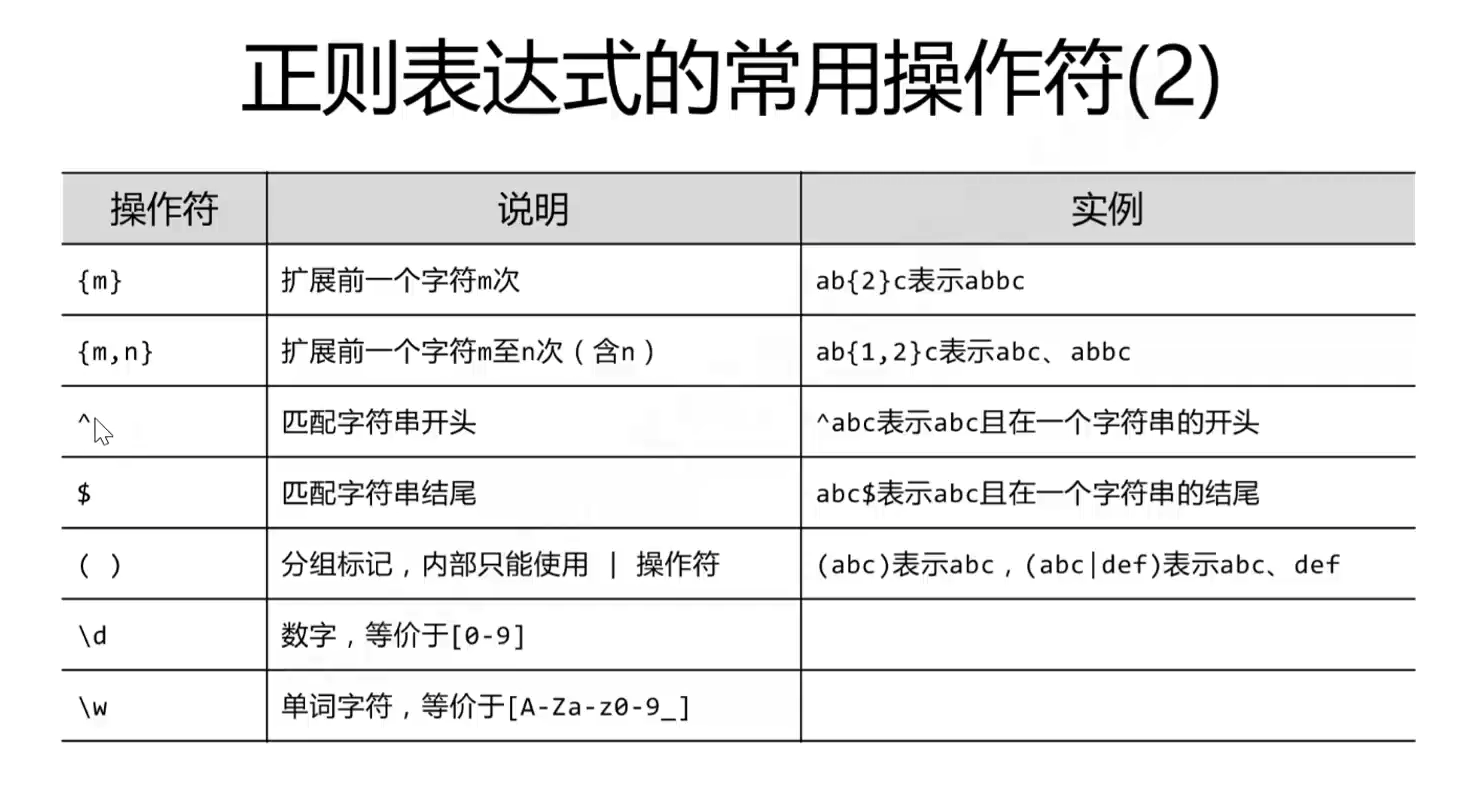
RE模块

网络编程
OSI七层模型及ARP协议及状态码
""" 1 CS架构 Client <--------------> Server 客户端软件send 服务端软件recv 操作系统 操作系统 计算机硬件 <----物理介质---> 计算机硬件 2 BS架构 Browser <--------------> Server 3 网络通信 网络存在的意义就是跨地域数据传输 -> 称之为 通信 网络 = 物理链接介质 + 互联网通信协议 OCI七层协议 应用层, 表示层, 会话层, 传输层, 网络层, 物理链路层, 物理层 五层协议 应用层, 传输层, 网络层, 物理链路层, 物理层 四层协议 应用层, 传输层, 网络层, 网络接口层 协议:规定数据的组织格式 格式: 头部 + 数据部分 封包: 数据外加头 解包: 拆掉头获取数据 五层协议详解 计算机1 计算机2 应用层 应用层 传输层 段 传输层 网络层 包 网络层 数据链路层 帧 数据链路层 物理层 <--------交互机---------> 物理层 客户端软件send 服务端软件recv 操作系统 操作系统 计算机硬件 <----物理介质---> 计算机硬件 ethernet头 + ip头 + tcp头 + 应用层的头 + 应用层数据 真实连接 计算机1 应用层 -> 传输层 -> 网络层 -> 数据链路层 -> 物理层 👇 计算机2 应用层 <- 传输层 <- 网络层 <- 数据链路层 <- 物理层 <- 交互机 4.1 物理层负责发送电信号 一组物理层数据称之为: 1 位 单纯的电信号毫无意义, 必须对其进行分组 4.2 数据链路层, ethernet 以太网协议 ARP协议 规定1 一组数据称之为: 1 帧 规定2 数据帧分成两个部分 --> 头 + 数据 头包含: 原地址与目标地址, 该地址是mac地址 数据包含 网络层发过来的整体的部分 规定3 规定但凡介入互联网的主机必须有一块网卡, 每块网卡在出厂时都会烧制好一个世界上独一无二的mac地址 注意: 计算机通信基本靠吼: 即以太网协议的工作方式时广播 4.3 网络层: IP协议 划分广播域 每一个广播域但凡要接通外部, 一定要有一个网关帮内部的计算机转发包到公网 网关与外界通信走的是路由协议 规定1 数据帧分成两部分 => 头 + 数据 头包含: 原地址与目标地址, 该地址为IP地址 数据包含: 传输层发过来的整体的内容 4.4 传输层, tcp\udp ===> 基于端口 socket 端口范围 0-65535, 0-1023 为系统占用端口 基于tcp协议通信之前: 必须建立一个双向通信的连接(逻辑层面上的) C ---------------------> S C <--------------------- S 三次握手建立链接: 建立链接视为了传数据做准备的, 三次握手即可 四次挥手断开连接 断开连接时, 由于链接内有数据传输, 所以必须分四次断开 tcp 是可靠传输的 原理: 如果接收不到, 则重新发送, 直至可以接收到 客户端每发一个数据, 服务端需要回应一个数据, 客户端接收到信息才会删除发出的信息 如果达到一定时间没有收到服务端传回的数据, 则客户端从新发一份数据给服务端 PS: 当服务器大量处于 TIME_WAIT 状态时意味着服务器处于高并发状态 4.5 应用层 (HTTP 协议) 自定义协议需要注意的问题 1 两大组成部分 == 头部 + 数据部分 头部: 放对数据的描述信息 例: 数据接受者, 数据类型, 数据长度 数据部分: 想要发送的数据 2 头部的长度必须固定 因为接收端要通过头部获取所接受数据的详细信息 3 端口号 HTTP: 80/tcp HTTPS: 443/tcp 443/udp 计算机1 计算机2 应用层 应用层 传输层 传输层 网络层 网络层 数据链路层 数据链路层 物理层 <-------三层交换机-------> 物理层 0101010111101010... (源mac地址, 目标mac地址) (源IP地址, 目标IP地址) 数据 事先知道的是对方的 ip 地址 但是计算机的底层通信是基于 Ethernet 以太网协议的 mac 地址通信 ARP 协议 # 两台计算机在同一个局域网 计算机1(172.16.10.10/24) 直接传输 计算机2(172.16.10.11/24) 自己的ip, 对方的ip 1 计算机二者的网络地址, 如果一样, 直接拿到计算机2 的mac地址 2 发送端mac FF:FF:FF:FF:FF:FF 172.16.10.10/24 172.16.10.11/24 数据 # 两台计算机不在同一个局域网 计算机1 网关 计算机2 101.100.200.11/10 自己的ip, 对方的ip 1 计算机二者的网络地址, 如果不一样, 拿到网关 的mac地址 2 发送端mac FF:FF:FF:FF:FF:FF 172.16.10.10/24 172.16.10.1/24 数据 ###### 总结 ip地址 + mac地址 ==> 标识全世界范围内独一无二的一台计算机 或者 ip地址 ==> 标识全世界范围内独一无二的一台计算机 ip + port 找到世界范围内独一无二的应用进程\ 1xx 表示【临时响应】并需要请求者继续执行操作的状态代码 2xx 表示【成功】处理了请求的状态代码 3xx 表示要完成请求,需要进一步操作。通常,这些状态代码用来【重定向】 4xx 表示【请求可能出错】,妨碍了服务器的处理 5xx 表示【服务器】在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错 100: (继续)请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。 101: (切换协议)请求者已要求服务器切换协议,服务器已确认并准备切换。 200:请求被正常处理 204:请求被受理但没有资源可以返回 206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。 301: (永久性重定向)请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 302: (临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 303: (查看其他位置)请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 304: (未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。 305: (使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。 307: (临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。与302类似,只是强制要求使用POST方法 400:请求报文语法有误,服务器无法识别 401:请求需要认证 403:请求的对应资源禁止被访问 404:服务器无法找到对应资源 500:服务器内部错误 503:服务器正忙 """- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
TCP的三次握手、四次挥手
前面介绍了TCP协议是OSI参考模型中传输层的代表协议,因此TCP协议是为了保障通信可靠性的,那具体TCP协议是如何保障通信可靠性的呢?那就是TCP协议通过“三次握手”的建立连接的方式和“四次挥手的”断开连接的方式保障的。
1、三次握手
物理层、数据链路层在物理层面上架设好了通信链路,网络层确定了通信双方的地址,那下一步就是传输层建立逻辑层面上的通信连接,将从应用层获得的报文数据从源端发送给接受端。TCP的三次握手就是在发送数据前通过“三次握手”的方式建立起这个通信连接,建立这个连接的目的是让源端和目的端确认一下双方的发送报文能力和接收报文能力是正常的,实际上就是通过三次握手这个操作将下面的表填完整:
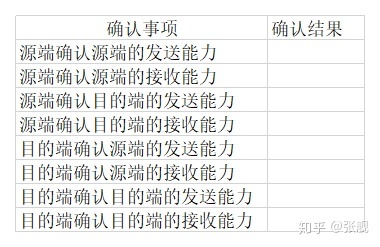
下面具体介绍三次握手的过程,并在每次握手时填充这个表格,当表格填满后,意味着源端和目的端已确认完毕双方的发送报文能力和接收报文能力是正常的,三次握手结束,通信双方的连接已成功建立。
1.1 TCP报文首部
在介绍三次握手前先介绍一下TCP报文的首部,报文首部可以理解为报文的元数据,里面存放着与这次报文相关的其他信息,图我就不摆了,介绍一下跟三次握手相关的报文首部字段。
(1)序号seq
对字节流的编号。例如第一个字节的序号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。注意第一份报文段的序号是随机生成的,后面的报文段序号是根据上一个报文段序号及报文长度生成的。
(2)确认号ack
期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
(3)SYN
控制位的一种,用于建立连接,该位设为 1,表示希望建立连接,并对第一份报文的序号进行随机初始化。
(4)ACK
控制位的一种,确认应答的字段有效,TCP规定除了最初建立连接时的 SYN 包以外该位必须设为 1。
(5)FIN
控制位的一种,当FIN=1,表明此报文的发送方的数据已经发送完毕,要求关闭连接。
1.2 三次握手具体过程
TCP三次握手的过程如图所示,图来自连接3。
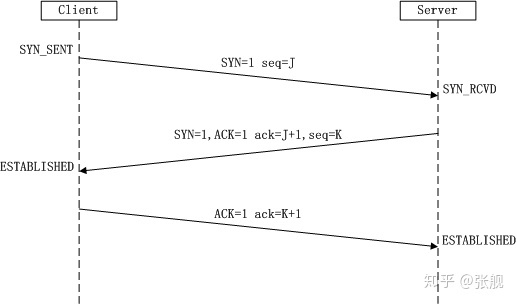
(1)第一次握手
Client端将SYN置为1,表示希望与Server端建立连接;序号seq初始化为J,并将该数据包发送给Server端,Client进入SYN_SENT状态,等待Server确认。
(2)第二次握手
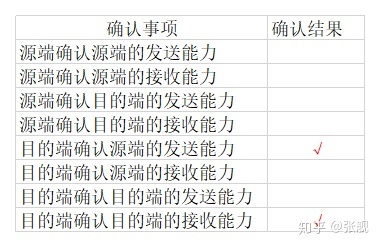
Server端检查报文发现SYN为1,知道了Client端想建立连接;Server端将SYN置为1,表示Server端也希望与Clinet端建立连接;Server端将ACK置为1,表示收到了Client端建立连接的请求;Server端将seq初始化为K;Server端将ack置为J+1,这里ack=seq + 1,还有疑问(如果控制位占1字节,为什么第三次握手时有ACK=1、SYN=1,ack为什么不是+2?如果+1只是告诉服务端收到了消息,那ACK控制位就已经达到目的了,为什么还要多次一举再加一个ack?)。第二次握手包括服务端确认客户端发来的报文和服务端向客户端发送报文两个过程。
第二次握手时表格填充结果如下:
(3)第三次握手
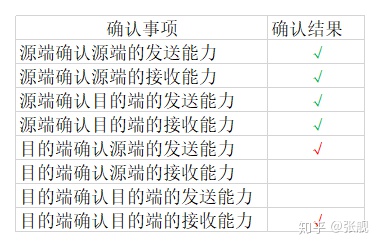
Client收到报文后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。第三次握手包括客户端确认服务端发来的报文,客户端向服务端发送报文和服务端确认客户端发来的报文三个过程。
第三次握手客户端确认信息后填充表格如下:
第三次握手服务端确认信息后填充表格如下:
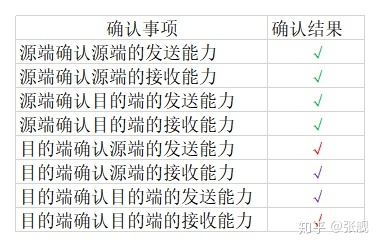
至此,表格填充完毕,三次握手也结束,连接成功建立。有些面试官会问为什么不是2次握手?因为2次握手表格填充不完,源端和目的端无法确认双方的收发能力;为什么不是4次握手?3次握手表格就填充完毕了,不需要再多一次握手了。
2、四次挥手
三次握手是建立TCP连接,四次挥手是断开TCP连接,即客户端和服务端总共要收发4个包才能确定断开连接。
2.1 四次挥手的具体过程
四次挥手的过程如图所示,图摘自连接4:
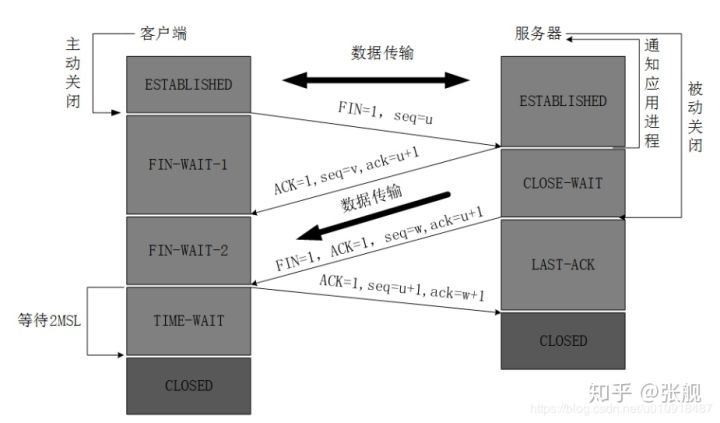
(1)第一次挥手
假设客户端主动发起断开请求,客户端向服务端发送报文,报文首部包括FIN=1,这个控制位代表客户端想要断开连接;序列号seq=u,这时客户端进入FIN-WAIT-1(终止等待1)状态,停止发送数据,并等待服务端的确认。
(2)第二次挥手
服务端收到客户端的报文后发出确认报文,控制位ACK=1;确认号ack=u+1;序列号seq=v;然后服务端就进入CLOSE-WAIT(关闭等待)状态。TCP服务端会告知上层的应用进程来自客户端的连接即将关闭,让应用程序做好相应的准备。此时客户端已经没有数据向服务端发送了,但服务端向客户端发送数据,客户端依然能接收。
(3)第三次挥手
客户端收到服务器确认报文后,进入FIN-WAIT-2状态。此时服务器再次发送报文,报文首部控制位FIN=1,表示服务端向客户端发送断开连接请求;确认标志ACK=1;确认序号ack=u+1;序号seq=w,然后服务器进入LAST-ACK(最后确认态),等待客户端确认。
(4)第四次挥手
客户端收到了服务端的断开连接的报文后,必须发出确认报文,标志位ACK=1;确认号ack=w+1;序号seq=u+1;之后客户端就进入了TIME-WAIT(时间等待)状态。注意此时客户端的TCP连接还没有释放,必须经过2*MSL(最长报文段寿命)的时间后,客户端才进入CLOSED状态关闭连接。而服务端只要收到了客户端发送的确认报文后就会进入CLOSED状态关闭服务端连接。当客户端和服务端都进入了CLOSED状态后,客户端和服务端之间的连接才完全断开。
2.2 为什么会有TIME_WAIT状态?
上面介绍第四次挥手的过程中,客户端在发送完给服务端的回执报文后没有立刻进入CLOSED状态,而是进入TIME-WAIT状态,然后等待2*MSL(最长报文段寿命)的时间后才进入CLOSED状态,这是为什么?原因有以下两点:
- 客户端发送给服务端回执后,有可能这个回执报文在传输途中丢失等原因,服务端并没有收到,此时服务端会再次向客户端发送FIN=1的断开请求报文,如果客户端没有等待2*MSL时间而直接进入了CLOSED状态,客户端就会收不到服务端再次发送的断开连接的请求报文,导致服务端无法进入CLOSED状态;
- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
注:MSL是Maximum Segment Lifetime英文的缩写,中文可以译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
2.3 为什么是四次挥手而不是三次或者五次?
第二次挥手和第三次挥手都是服务端向客户端发送报文,第二次挥手是服务端收到了客户端的断开请求,通知客户端俺收到了,此时客户端没有数据向服务端发送了,但不代表服务端也没有数据向客户端发送,因为服务端要把剩余还没有发送的报文发送完毕再断开连接;第三次挥手是服务端数据全部发送完毕,向客户端发送断开请求报文(FIN=1)。
如果是三次挥手,即把服务端向客户端发送报文的第二次挥手和第三次挥手合为一次,会造成服务端发送了回执后立刻又发送断开请求,造成服务端有数据没有全部发送至客户端,因此必须将第二次挥手和第三次挥手分开;五次挥手则完全没必要,多此一举。
多道技术
并发 看起来像同时运行的就可以称之为并发 并行 真正意义上的同时执行 ps: 并行 可以称之为并发, 并发 不可以称之为并行 单核的计算机肯定斌能实现并行, 但是可以实现并发 补充: 我们直接假设单核就是一个核, 干活的就是一个人, 不考虑cpu里面的内核数 作用: 节省多个程序运行的总耗时 重点: 空间上的复用和时间上的复用 空间上的复用 多个程序公用一套计算机硬件 时间上的复用 eg: 洗衣服30s 做饭 50s, 烧水30 单道 30+50+30 多道 只需要任务最长的那个一个的时间 切换节省时间 例: 边烧水,边做饭, 保存状态 切换 + 保存状态 切换(CPU)分为两种情况 1 当一个程序遇到IO操作的时候, 操作系统会剥夺该程序的CPU执行权限 作用:提高了CPU的利用率, 并且也不影响程序的执行效率 2 当一个程序长时间占用CPU的时候, 操作系统也会剥夺该程序的CPU执行权限 作用:降低了程序的执行效率, (原本时间 + 切换时间 + 其他程序运行时间)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
进程理论
程序与进程的区别
程序就是一堆躺在硬盘上的代码, 是“死”的 进程则表示程序正在执行的过程, 是“活”的- 1
- 2
进程调度
先来先服务调度算法
对长作业有利, 对短作业无益- 1
短作业优先调度算法
对短作业有益, 对长作业无益- 1
时间片轮转法 + 多级反馈队列
时间片
将固定的时间切分成N多份, 每一份就表示一个时间片- 1
进程三状态转换
三状态
就绪, 运行, 阻塞- 1
三状态转换图
创建 -(提交)-> 就绪 -(时间调度)-> 运行 -(释放)-> 退出 ↑ ↖ ↙ ↓ | (时间片到) | (事件发生) (事件请求) ↖ ↙ ↖---阻塞---↙- 1
- 2
- 3
- 4
- 5
- 6
两对重要概念
同步和异步
描述的是任务的提交方式- 1
同步
任务提交之后, 原地等待任务的返回结果, 等待的过程中不做任何事情 程序成眠上表现出来的感觉是 “卡住了”- 1
- 2
异步
任务提交之后, 不愿地等待任务的返回结果, 直接去做其他事情 我提交的任务结果如何获取? 任务的返回结果会有一个异步回调机制自动处理- 1
- 2
- 3
阻塞和非阻塞
描述的是程序的运行状态- 1
阻塞
阻塞态- 1
非阻塞
就绪态, 运行态- 1
总结
上述概念的组合最高效的一种组合就是 “异步非阻塞"
理想状态: 我们应该让我们的代码一直处于就绪态和运行态
开启进程的两种方式
方式一
if __name__ == '__main__': # 1 创建一个对象 p = Process(target=task, args=('egon',)) # ps: 容器类型哪怕里面只有一个元素, 也建议使用都好隔开 # 2 开启进程 p.start() # 告诉操作系统创建一个进程 异步 print('main')- 1
- 2
- 3
- 4
- 5
- 6
- 7
方式二
# 类的继承 class MyProcess(Process): def run(self) -> None: print('hello world') time.sleep(1) print("over") if __name__ == '__main__': p = MyProcess() p.start() print('main')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
进程对象
一台计算机上面运行这很多进程, 那么计算机是如何区分并管理这些进程服务端的呢? 计算机会给每一个运行的进程分配一个 PID 号 如何查看 Windows: 进入 cmd 输入 tasklist 查看查看全部进程 tasklist |find PID 查看具体的进程 mac: 进入终端, 输入 ps aux 查看全部进程 ps aux|grep PID 查看具体的进程- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
两种特殊的进程
# 僵尸进程 死了但是没有死透 当开设了子进程之后, 该进程死后不会立刻释放占用的进程号 因为我要让父进程能够查看到它开设的子进程的一些基本信息, 占用的pid, 运行时间 等等 所有的进程都会步入僵尸进程 有害的僵尸进程: 父进程不死, 并且在无限制的创建子进程且子进程也不结束 回收子进程占用的pid号 父进程等待子进程运行结束 父进程调用join方法 # 孤儿进程 子进程存活, 父进程意外死亡 操作系统会开设一个 '儿童福利院' 专门用来管理孤儿进程回收相关资源- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
互斥锁
# 问题 多个进程操作同一份数据的时候, 会出现数据错乱的问题 # 解决方案 加锁处理, 将并发变成串行, 牺牲效率但是保证了数据安全- 1
- 2
- 3
- 4
进程间通信的五种方式
管道, FIFO(命名管道), 消息队列, 信号量, 共享内存 # 几种方式比较 管道:速度慢、容量有限 消息队列:容量收到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题。 信号量:不能传递复杂信息,只能用来同步。 共享内存:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全。- 1
- 2
- 3
- 4
- 5
- 6
- 7
进程同步机制
1.信号量机制 一个信号量只能置一次初值,以后只能对之进行p操作或v操作。 由此也可以看到,信号量机制必须有公共内存,不能用于分布式操作系统,这是它最大的弱点。 2.自旋锁 旋锁是为了保护共享资源提出的一种锁机制。 调用者申请的资源如果被占用,即自旋锁被已经被别的执行单元保持,则调用者一直循环在那里看是否该自旋锁的保持着已经释放了锁,自旋锁是一种比较低级的保护数据结构和代码片段的原始方式,可能会引起以下两个问题; (1)死锁 (2)过多地占用CPU资源 3.管程 信号量机制功能强大,但使用时对信号量的操作分散,而且难以控制,读写和维护都很困难。因此后来又提出了一种集中式同步进程——管程。其基本思想是将共享变量和对它们的操作集中在一个模块中,操作系统或并发程序就由这样的模块构成。这样模块之间联系清晰,便于维护和修改,易于保证正确性。 4.会合 进程直接进行相互作用 5.分布式系统 由于在分布式操作系统中没有公共内存,因此参数全为值参,而且不可为指针。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
总结
创建进程就是在内存中申请一块内存空间, 将需要运行的代码丢进去 一个进程对应在内存中就是一块独立的内存空间 多个进程对应在内存中就是多块独立的内存空间 进程与进程之间数据默认情况下是无法直接交互的 如果想进行交互可以借助于第三方工具, 模块- 1
- 2
- 3
- 4
- 5
join 方法
join 是让主进程等待子进程代码运行结束之后, 再继续运行, 不影响其他子进程的运行- 1
- 2
线程理论
什么是线程 进程: 资源单位 线程: 执行单位 将操作系统比喻成一个大工厂 那么进程就相当于工厂里面的车间 线程就是车间里面的流水线 # 每一个进程肯定自带一个线程 总结: 进程 : 资源单位(起一个进程仅仅实在内存孔家你开辟一块独立的空间) 线程 : 执行单位(真正被cpu执行的其实是进程里面的线程, 线程指导的就是代码的执行过程, 执行代码中所需要使用到的资源都要找 所在的进程索要) 进程和线程都是虚拟单位, 只是为了我们更加方便的描述问题 为什么要有线程 开设进程的步骤 1 申请内存空间 耗费资源 2 拷贝代码 耗费资源 开设线程 一个线程内可以开合多个线程, 在用一个线程内开设多个线程无需再次申请 内存空间及拷贝代码的操作 总结: 开设线程的开销要远远小于进程的开销 同一个进程下的多个线程数据是共享的 eg: 我们要开发一款文本编辑器 功能列表 1 获取用户输入的功能 2 实时展示到屏幕的功能 3 自动保存到硬盘的功能 针对上面的三个功能, 开设进程还是线程合适 开三个线程处理上面的三个功能更加合适- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
开启线程的两种方式
开线程和开线程的步骤基本是一样的, 只是导入的模块不一样而已 开进程代码必须写在 main 下面 而开线程无需这么做(但也习惯于卸载main下面) 一. 类的对象调用方法 二. 类的继承重写 run 方法- 1
- 2
- 3
- 4
- 5
线程间通信的方式
1, 同步; 2, 轮询; 3, wait/notify; 4, 管道- 1
线程的五种状态
1. 新建(NEW):新创建了一个线程对象。 2. 可运行(RUNNABLE):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu 的使用权 。 3. 运行(RUNNING):可运行状态(runnable)的线程获得了cpu 时间片(timeslice) ,执行程序代码。 4. 阻塞(BLOCKED):阻塞状态是指线程因为某种原因放弃了cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。阻塞的情况分三种: (一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。 (二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。 (三). 其他阻塞:运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。 5. 死亡(DEAD):线程run()、main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
线程同步方式
互斥量 Synchronized/Lock:采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问
信号量 Semphare:它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量
事件(信号),Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操
TCP 服务端实现并发
将接客和服务的活分开- 1
线程对象的 join 方法
等待当前线程对象结束之后, 在继续往下执行- 1
同一个进程内的多个线程数据是共享的
同一个进程内可以开设多个线程 进程: 资源单位 线程: 执行单位- 1
- 2
- 3
线程对象属性和方法
current_thread 获取线程的名称 active_count 获取当前活跃的线程数- 1
- 2
守护线程
子线程非守护线程 主线程必须等待所有非守护线程的结束才结束 else: 主线程死亡, 守护线程一起死亡 t.daemon = True # 必须在 start 之前 t.start- 1
- 2
- 3
- 4
- 5
- 6
- 7
线程互斥锁
当多个线程在操作同一份数据的时候可能会造成数据的错乱 这个时候为了保证数据的安全 我们通常会枷锁处理 锁: 将并发变成串行, 降低了程序的运行效率但是保证了数据的安全 锁的问题在我们后面写代码的过程中一般都不会遇到, 都是别人 底层封装好的, 无需考虑- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
GIL全局解释器锁
1 GIL 是 CPython 解释器的特点, 不是 Python的特点 2 GIL 本质也是一把互斥锁, 但是它是解释器级别的锁 3 它的存在是疑问 CPython解释器的内存管理不是线程安全的 垃圾回收机制 1 引用计数 当一个东东 被一个变量引用的时候 这个东东的引用计数 +1 2 标记清除 当一个东东的 引用变量 被删除或者指向了其他东东 引用计数 -1 3 分代回收 当一个东东的引用计数 为0 , 且系统内存占用过多, 则执行垃圾回收, 回收这些 引用计数为0 的垃圾 4 也就意味着 GIL 的存在导致了一个进程下的多个线程无法利用多核优势(不能同时运行) 5 针对不同的数据应该加不同的锁来保证安全- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
验证python多线程是否有用
应该结合任务的具体类型在做判断 应该对任务分两种情况讨论 IO密集型 多线程更加节省资源 计算密集型 多进程更加合理 多进程和多线程都是有用的, 并且 后面的东东 都是 多进程和多线程的同时使用 从而达到效率最大化- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
死锁
死锁现象
即便知道如何抢锁和释放锁, 也极有可能造成程序的死锁现象 但是后序在写项目的时候, 不会自己处理锁的问题, 都是底层封装好的- 1
- 2
- 3
什么是死锁,产生死锁的原因和必要条件
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所 站用不会释放的资源而处于的一种永久等待状态。死锁的四个必要条件: • 互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。 • 请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。 • 非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。 • 循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等 待相邻进程正占用的资源。 java 中产生死锁可能性的最根本原因是:1)是多个线程涉及到多个锁,这些锁存在着交叉, 所以可能会导致了一个锁依赖的闭环;2) 默认的锁申请操作是阻塞的。 如,线程在获得一个锁L1的情况下再去申请另外一个锁L2,也就是锁L1想要包含了锁L2, 在获得了锁 L1,并且没有释放锁 L1 的情况下,又去申请获得锁 L2,这个是产生死锁的最根本原因。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
递归锁
它是一把互斥锁, 但是它可以被第一个抢到它的人连续的 acquire 和 release 每 acquire 一次 内部 引用计数 +1 每 release 一次 内部 引用计数 -1 只要引用计数不为 0 那么此锁永远无法被其他人抢到- 1
- 2
- 3
- 4
- 5
信号量
信号量在不同的领域和知识阶段可能对应不同的概念 如果将互斥锁比喻成一个厕所, 那么信号量就相当于 多个厕所- 1
- 2
进程池和线程池
''' 硬件的发展速度是赶不上软件的开发速度的 我们以前借助于开设进程和线程来实现TCP服务端的并发 每来一个客户端就开设一个进程或者线程 无论开设进程还是开设进程还是开设线程其实都需要消耗一定的资源 我们应该在保证计算机硬件安全的情况下, 最大限度的利用计算机 池的概念 保证计算机硬件的安全 降低了程序的运行效率, 但是保证了计算机硬件安全 ''' ## 进程池和线程池都不需要我们自己去造, 直接使用封装好的模块 from concurrent.futures import ThreadPoolExecutor, ProcessPoollExecutor # 1 生成进程池和线程池 pool1 = ThreadPoolExecutor() 不填默认为 cpu 个数 的 五倍 pool2 = ProcessPoolExecutor() 不填默认为 cpu 个数 # 2 向池子中提交任务 res = pool1.submit(task,args...) 异步提交 # 3 submit 会返回一个 Future类的对象, 该对象调用 result就能获取到任务的结果 res.result() 同步 # 4 池子对象的方法 pool1.shotdown() 关闭池子, 等待池子中所有的任务运行结束, 在往后执行代码 # 5 异步回调机制 给每一个异步提交的任务绑定一个方法, 一旦任务有了结果会立刻触发该方法 注意: 异步回调函数拿到的也是一个对象- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
协程
单线程下实现并发 程序员自己想出来的概念 多道基础 切换 + 保存状态 通过代码层面自己检测 IO行为, 一旦遇到 IO 代码层面实现切换 这样给操作系统的感觉就好似我这个程序 一直在运行 没有 IO 欺骗操作系统从而最大化的利用CPU 一味的切换 + 保存状态 也有可能降低程序的效率 计算密集型 降低效率 IO 密集型 提高效率- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
gevent 模块
# 该模块能够帮我们检测 IO 并实现切换 from gevent import monkey; mokey.patch_all() from gevent import spawn # spawn 在检测的时候 是异步提交的 g = spawn(server) g.join()- 1
- 2
- 3
- 4
- 5
- 6
Final summary
理想状态 我们可以通过 多进程下面开设多线程 多线程下面开设协程程序 从而使得我们的程序执行效率提升- 1
- 2
- 3
- 4
- 5
IO 模型
五种IO Model
* blocking IO 阻塞IO * nonblocking IO 非阻塞IO * IO multiplexing IO多路复用 * signal driven IO 信号驱动IO * asynchronous IO 异步IO #1)等待数据准备 (Waiting for the data to be ready) #2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同步异步, 阻塞非阻塞
同步异步 阻塞非阻塞 常见的网络阻塞状态 accept recv recvfrom send (虽然它也有 IO 操作, 但是不在我们的考虑范围之内)- 1
- 2
- 3
- 4
- 5
- 6
- 7
阻塞 IO (blocking IO model)
我们之前写的都是 阻塞 IO 协程除外 在服务端开设多进程或者多线程 其实还是没有解决 IO 问题 该等的地方还是得等 没有规避 只不过多个人等待的彼此互不干扰- 1
- 2
- 3
- 4
- 5
非阻塞 IO(Nonblocking I/O model)
代码详见 package 非阻塞 IO 模型 总结: 虽然 非阻塞 IO 给你的感觉非常好 但是 该模型会长时间占用着 CPU 但是不干活(让CPU 不停的空转) 我们实际应用中也不会考虑使用非阻塞 IO 模型- 1
- 2
- 3
- 4
- 5
- 6
- 7
IO 多路复用
当监管的对象只有一个的时候, 其实 IO 多路复用的的效率连 阻塞 IO 都比不上 但是 IO 多路复用可以一次性监管很多个对象 监管机制是操作系统本身就有的 如果想要用该监管机制(select) 需要导入对应的 select 模块 server = socket.socket() conn = server.accept- 1
- 2
- 3
- 4
- 5
- 6
- 7
对上总结
监管机制其实有很多, select 机制 Windows linux 都有 poll 机制 只在linux上有 poll 和select 都可以监管多个对象 但是 poll 可以监管的数量更多 上述 select 和 poll 机制其实都不是很完美 可能会出现 极其大的演示响应 epoll 机制 只有 linux 有 它给每一个监管对象都绑定一个会带哦机制 一旦有响应 回调机制立刻发起提醒 针对不同的操作系统需要不同的检测机制, 书写代码太多繁琐 有一个模块可以根据你跑的平台的不同自动帮你选择对应的监管机制 selectors 模块- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
异步 IO
异步 IO 模型是所有模型中效率最高的, 也是使用最广泛的 相关的模块 和 框架: 模块: asyncio 模块 异步框架: sanic tronado twisted 速度快!!!! , 可以开发一些游戏的服务端- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Redis
一, 数据结构
redis的性能高的原因之一是它每种数据结构都是经过专门设计的,并都有一种或多种数据结构来支持,依赖这些灵活的数据结构,来提升读取和写入的性能。如果要了解redis的数据结构,可以从两个不同的层面来讨论它:
(1)第一种分类:
# 从使用者的角度,这一层面也是Redis暴露给外部的调用接口,比如 string list hash set sorted set- 1
- 2
- 3
- 4
- 5
- 6
(2)第二种分类:
dict sds ziplist quicklist skiplist intset- 1
- 2
- 3
- 4
- 5
- 6
Redis数据结构的内部实现
这两个层面的数据结构之间的关系:Redis如何通过组合第二个层面的各种基础数据结构来实现第一个层面的更高层的数据结构
在讨论任何一个系统的内部实现的时候,我们都要先明确它的设计原则,这样我们才能更深刻地理解它为什么会进行如此设计的真正意图。在本文接下来的讨论中,我们主要关注以下几点:存储效率。Redis是专用于存储数据的,它对计算机资源的主要消耗就在于内存,因此节省内存是它非常非常重要的一个方面。这意味着Redis一定是非常精细地考虑了压缩数据、减少内存碎片等问题。
快速响应时间。与快速响应时间相对的,是高吞吐量。Redis是用于提供在线访问的,对于单个请求的响应时间要求很高,因此,快速响应时间是比高吞吐量更重要的目标。
单线程。Redis的性能瓶颈不在于CPU资源,而在于内存访问和网络IO。而采用单线程的设计带来的好处是,极大简化了数据结构和算法的实现。相反,Redis通过异步IO和pipelining等机制来实现高速的并发访问。显然,单线程的设计,对于单个请求的快速响应时间也提出了更高的要求。二、redisObject:两层数据结构的桥梁
redisObject数据结构详解:http://zhangtielei.com/posts/blog-redis-robj.html
1、什么是redisObject:
从Redis的使用者的角度来看,一个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系,这个映射关系的key是string类型,而value可以是多种数据类型,比如:string, list, hash、set、sorted set等。 而从Redis内部实现的角度来看,database内的这个映射关系是用一个dict来维护的。dict的key固定用一种数据结构来表达就够了,这就是动态字符串sds;而value则比较复杂,为了在同一个dict内能够存储不同类型的value,这就需要一个通用的数据结构,这个通用的数据结构就是robj,全名是redisObject- 1
- 2
- 3
举个例子:
如果value是list类型,那么它的内部存储结构是一个quicklist或者是一个ziplist
如果value是string类型,那么它的内部存储结构一般情况下是一个sds。但如果string类型的value的值是一个数字,那么Redis内部还会把它转成long型来存储,从而减小内存使用。
所以,一个robj既能表示一个sds,也能表示一个quicklist,甚至还能表示一个long型。2、redis的数据结构定义:(基于Redis3.2版本)
/* Object types */ #define OBJ_STRING 0 #define OBJ_LIST 1 #define OBJ_SET 2 #define OBJ_ZSET 3 #define OBJ_HASH 4 /* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 /* Encoded as integer */ #define OBJ_ENCODING_HT 2 /* Encoded as hash table */ #define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */ #define OBJ_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */ #define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */ #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */ #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */ #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */ #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */ #define LRU_BITS 24 typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */ int refcount; void *ptr; } robj;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
(1)一个robj包含如下5个字段:
type: 对象的数据类型。占4个bit。可能的取值有5种:OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH,分别对应Redis对外暴露的5种数据结构 encoding: 对象的内部表示方式(也可以称为编码)。占4个bit。可能的取值有10种,即前面代码中的10个OBJ_ENCODING_XXX常量。 lru: 做LRU替换算法用,占24个bit。这个不是我们这里讨论的重点,暂时忽略。 refcount: 引用计数。它允许robj对象在某些情况下被共享。 ptr: 数据指针。指向真正的数据。比如,一个代表string的robj,它的ptr可能指向一个sds结构;一个代表list的robj,它的ptr可能指向一个quicklist。- 1
- 2
- 3
- 4
- 5
(2)encoding字段的说明:
这里特别需要仔细察看的是encoding字段。对于同一个type,还可能对应不同的encoding,这说明同样的一个数据类型,可能存在不同的内部表示方式。而不同的内部表示,在内存占用和查找性能上会有所不同。- 1
当type = OBJ_STRING的时候,表示这个robj存储的是一个string,这时encoding可以是下面3种中的一种: OBJ_ENCODING_RAW: string采用原生的表示方式,即用sds来表示。 OBJ_ENCODING_INT: string采用数字的表示方式,实际上是一个long型。 OBJ_ENCODING_EMBSTR: string采用一种特殊的嵌入式的sds来表示。- 1
- 2
- 3
- 4
- 5
当type = OBJ_HASH的时候,表示这个robj存储的是一个hash,这时encoding可以是下面2种中的一种: OBJ_ENCODING_HT: hash采用一个dict来表示 OBJ_ENCODING_ZIPLIST: hash采用一个ziplist来表示- 1
- 2
- 3
- 4
(3)10种encoding的取值说明:
OBJ_ENCODING_RAW: 最原生的表示方式。其实只有string类型才会用这个encoding值(表示成sds)。 OBJ_ENCODING_INT: 表示成数字。实际用long表示。 OBJ_ENCODING_HT: 表示成dict。 OBJ_ENCODING_ZIPMAP: 是个旧的表示方式,已不再用。在小于Redis 2.6的版本中才有。 OBJ_ENCODING_LINKEDLIST: 也是个旧的表示方式,已不再用。 OBJ_ENCODING_ZIPLIST: 表示成ziplist。 OBJ_ENCODING_INTSET: 表示成intset。用于set数据结构。 OBJ_ENCODING_SKIPLIST: 表示成skiplist。用于sorted set数据结构。 OBJ_ENCODING_EMBSTR: 表示成一种特殊的嵌入式的sds。 OBJ_ENCODING_QUICKLIST: 表示成quicklist。用于list数据结构。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、robj的作用:
redisObject就是Redis对外暴露的第一层面的数据结构:string, list, hash, set, sorted set,而每一种数据结构的底层实现所对应的是哪些第二层面的数据结构(dict, sds, ziplist, quicklist, skiplist等),则通过不同的encoding来区分。可以说,robj是联结两个层面的数据结构的桥梁。 为多种数据类型提供一种统一的表示方式。 允许同一类型的数据采用不同的内部表示,从而在某些情况下尽量节省内存。 支持对象共享和引用计数。当对象被共享的时候,只占用一份内存拷贝,进一步节省内存。- 1
- 2
- 3
- 4
第一层数据结构
1、String:
String是最简单的数据类型,一般用于复杂的计数功能的缓存:微博数,粉丝数等。
(1)底层实现方式:动态字符串sds 或者 long
String的内部存储结构一般是sds(Simple Dynamic String),但是如果一个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从而减少内存的使用。- 1
确切地说,String在Redis中是用一个robj来表示的。
用来表示String的robj可能编码成3种内部表示:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。其中前两种编码使用的是sds来存储,最后一种OBJ_ENCODING_INT编码直接把string存成了long型。
在对string进行incr, decr等操作的时候,如果它内部是OBJ_ENCODING_INT编码,那么可以直接进行加减操作;如果它内部是OBJ_ENCODING_RAW或OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作。
对一个内部表示成long型的string执行append, setbit, getrange这些命令,针对的仍然是string的值(即十进制表示的字符串),而不是针对内部表示的long型进行操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。而如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执行setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作。2、Hash:
Hash适合用于存储对象,因为一个对象的各个属性,正好对应一个hash结构的各个field,可以方便地操作对象中的某个字段。
(1)底层实现方式:压缩列表ziplist 或者 字典dict
当数据量较少的情况下,hash底层会使用压缩列表ziplist进行存储数据,也就是同时满足下面两个条件的时候:- 1
hash-max-ziplist-entries 512:当hash中的数据项(即filed-value对)的数目小于512时
hash-max-ziplist-value 64:当hash中插入的任意一个value的长度小于64字节
当不能同时满足上面两个条件的时候,底层的ziplist就会转成dict,之所以这样设计,是因为当ziplist变得很大的时候,它有如下几个缺点:每次插入或修改引发的realloc操作会有更大的概率造成内存拷贝,从而降低性能。
一旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更大的一块数据。
当ziplist数据项过多的时候,在它上面查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在一起组成连续的内存空间,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存realloc,可能导致内存拷贝。3、List:
list 的实现为一个双向链表,经常被用作队列使用,支持在链表两端进行push和pop操作,时间复杂度为O(1);同时也支持在链表中的任意位置的存取操作,但是需要对list进行遍历,时间复杂度为O(n)。
list 的应用场景非常多,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。可以利用lrange命令,做基于redis的分页功能。- 1
(1)Redis3.2之前的底层实现方式:压缩列表ziplist 或者 双向循环链表linkedlist
当list存储的数据量较少时,会使用ziplist存储数据,也就是同时满足下面两个条件:
列表中数据个数少于512个
list中保存的每个元素的长度小于 64 字节
当不能同时满足上面两个条件的时候,list就通过双向循环链表linkedlist来实现了(2)Redis3.2及之后的底层实现方式:quicklist
quicklist是一个双向链表,而且是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,结合了双向链表和ziplist的优点- 1
4、Set:
set是一个存放不重复值的无序集合,可做全局去重的功能,提供了判断某个元素是否在set集合内的功能,这个也是list所不能提供的。基于set可以实现交集、并集、差集的操作,计算共同喜好,全部的喜好,自己独有的喜好等功能。
(1)底层实现方式:有序整数集合intset 或者 字典dict
当存储的数据同时满足下面这样两个条件的时候,Redis 就采用整数集合intset来实现set这种数据类型:
存储的数据都是整数
存储的数据元素个数小于512个
当不能同时满足这两个条件的时候,Redis 就使用dict来存储集合中的数据5、Sorted Set:
Sorted set 相比 set 多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
(1)底层实现方式:压缩列表ziplist 或者 zset
当 sorted set 的数据同时满足下面这两个条件的时候,就使用压缩列表ziplist实现sorted set
元素个数要小于 128 个,也就是ziplist数据项小于256个
集合中每个数据大小都小于 64 字节
当不能同时满足这两个条件的时候,Redis 就使用zset来实现sorted set,这个zset包含一个dict + 一个skiplist。dict用来查询数据到分数(score)的对应关系,而skiplist用来根据分数查询数据(可能是范围查找)。第二层数据结构
1、sds:
sds数据结构详解:http://zhangtielei.com/posts/blog-redis-sds.html
(1)什么是sds:
sds全称是Simple Dynamic String,具有如下显著的特点:
① 可动态扩展内存。sds表示的字符串其内容可以修改,也可以追加。
② 采用预分配冗余空间的方式来减少内存的频繁分配,从而优化字符串的增长操作
③ 二进制安全(Binary Safe)。sds能存储任意二进制数据,而不仅仅是可打印字符。
④ 与传统的C语言字符串类型兼容。
(2)sds的数据结构:
sds是Binary Safe的,它可以存储任意二进制数据,不能像C语言字符串那样以字符’\0’来标识字符串的结束,因此它必然有个长度字段。但这个长度字段在哪里呢?实际上sds还包含一个header结构:- 1
struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
sds一共有5种类型的header。之所以有5种,是为了能让不同长度的字符串可以使用不同大小的header。这样,短字符串就能使用较小的header,从而节省内存。 所以,sds字符串的完整结构,由在内存地址上前后相邻的header和字符数组两部分组成:- 1
- 2
- 3
① header:除了sdshdr5,一个header结构都包含3个字段:字符串的真正长度len、字符串的最大容量alloc和flags,flags总是占用一个字节。其中的最低3个bit用来表示header的类型。
② 字符数组:字符数组的长度等于最大容量+1,存放了真正有效的字符串数据。在真正的字符串数据之后,是空余未用的字节(一般以字节0填充),允许在不重新分配内存的前提下让字符串数据向后做有限的扩展。在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符。
header的类型共有5种,在sds.h中有常量定义:
#define SDS_TYPE_5 0 #define SDS_TYPE_8 1 #define SDS_TYPE_16 2 #define SDS_TYPE_32 3 #define SDS_TYPE_64 4- 1
- 2
- 3
- 4
- 5
sds字符串的header,其实隐藏在真正的字符串数据的前面(低地址方向),这样的一个定义,有如下几个好处:
header和数据相邻,从而不需要分成两块内存空间来单独分配,有利于减少内存碎片,提高存储效率
虽然header有多个类型,但sds可以用统一的char *来表达。且它与传统的C语言字符串保持类型兼容。如果一个sds里面存储的是可打印字符串,那么我们可以直接把它传给C函数,比如使用strcmp比较字符串大小,或者使用printf进行打印。
(3)String robj的编码与解码过程:OBJ_STRING类型的字符串对象的编码和解码过程在Redis里非常重要,应用广泛。
当我们执行Redis的set命令的时候,Redis首先将接收到的value值(string类型)表示成一个type = OBJ_STRING并且encoding = OBJ_ENCODING_RAW的robj对象,然后在存入内部存储之前先执行一个编码过程,试图将它表示成另一种更节省内存的encoding方式。这一过程的核心代码,是object.c中的tryObjectEncoding函数。
当我们需要获取字符串的值,比如执行get命令的时候,我们需要执行与前面讲的编码过程相反的操作——解码。这一解码过程的核心代码,是object.c中的getDecodedObject函数。
对于编码的核心代码tryObjectEncoding函数和解码的核心代码getDecodedObject函数的详细说明,样请读者移步这篇文章:Redis内部数据结构详解(3)——robj - 铁蕾的个人博客
(4)为什么 Redis 的 String 底层数据结构使用 sds:
看到这里,我们就可以大概明白,为什么 String 底层数据结构要使用 sds:- 1
① 性能高:
sds 数据结构主要由 len、alloc、buf[] 三个属性组成,其中 buf[] 为实际保存字符串的 char 类型数组;len 表示 buf[] 数组所保存的字符串的长度。由于使用 len 记录了保存的字符串长度,所以在获取字符串长度的时候,不需要从前往后遍历数组,直接获取 len 的值就可以了- 1
② 内存预分配,优化字符串的增长操作:
当需要修改数据时,首先会检查 sds 空间 len 是否满足,不满足则自动扩容空间,然后再执行修改。sds 在分配空间时,还会分配额外的未使用空间 free,下次再修改就先检查未使用空间 free 是否满足,如果满足则不用再扩展空间。通过空间预分配策略,有效较少在字符串连续增长情况下产生的内存重分配次数。- 1
额外分配 free 空间的规则:
如果 sds 字符串修改后,len 值小于 1M,则额外分配未使用空间 free 的大小为 len
如果 sds 字符串修改后,len 值大于等于 1M,则额外分配未使用空间 free 的大小为1M
③ 惰性空间回收,优化字符串的缩短操作:当缩短 SDS 字符串后,并不会立即执行内存重分配来回收多余的空间,如果后续有增长操作,则可直接使用。- 1
2、dict:
dict数据结构详解:http://zhangtielei.com/posts/blog-redis-dict.html
dict是一个用于维护key-value映射关系的数据结构。Redis的一个database中所有key到value的映射,就是使用一个dict来维护的。不过,这只是它在Redis中的一个用途而已,它在Redis中被使用的地方还有很多。比如,Redis的hash结构,当它的field较多时,便会采用dict来存储。再比如,Redis配合使用dict和skiplist来共同维护一个sorted set。 dict本质上是为了解决算法中的查找问题,是一个基于哈希表的算法,在不要求数据有序存储,且能保持较低的哈希值冲突概率的前提下,查询的时间复杂度接近O(1)。它采用某个哈希函数并通过计算key从而找到在哈希表中的位置,采用拉链法解决冲突,并在装载因子(load factor)超过预定值时自动扩展内存,引发重哈希(rehashing),为了避免扩容时一次性对所有key进行重哈希,Redis采用了一种称为增量式重哈希(incremental rehashing)的方法,将重哈希的操作分散到对于dict的各个增删改查的操作中去。这种方法能做到每次只对一小部分key进行重哈希,而每次重哈希之间不影响dict的操作。dict之所以这样设计,是为了避免重哈希期间单个请求的响应时间剧烈增加,这与前面提到的“快速响应时间”的设计原则是相符的。 当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右;当数据动态减少之后,为了节省内存,当装载因子小于 0.1 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约2 倍大小。- 1
- 2
- 3
- 4
- 5
3、ziplist:
ziplist数据结构详解:http://zhangtielei.com/posts/blog-redis-ziplist.html
ziplist是一个经过特殊编码的双向链表,可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。它能以O(1)的时间复杂度在表的两端提供push和pop操作。 一个普通的双向链表,链表中每一项都占用独立的一块内存,并通过地址指针连接起来,但这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。而ziplist使用了一整块连续的内存,将表中每一项存放在前后连续的地址空间内,类似于一个数组。另外,ziplist为了在细节上节省内存,对于值的存储采用了变长的编码方式,大概意思是说,对于大的整数,就多用一些字节来存储,而对于小的整数,就少用一些字节来存储。 总的来说,ziplist使用一块连续的内存空间来存储数据,并采用可变长的编码方式,支持不同类型和大小的数据的存储,更加节省内存,而且数据存储在一片连续的内存空间,读取的效率也非常高。- 1
- 2
- 3
- 4
- 5
4、quicklist:
quicklist数据结构详解:http://zhangtielei.com/posts/blog-redis-quicklist.html
(1)什么是quicklist:
quicklist是一个基于ziplist的双向链表,quicklist的每个节点都是一个ziplist,比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:- 1
双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。(2)quicklist中每个ziplist长度的配置:
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。list-max-ziplist-size -2- 1
这个参数可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
-5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
-4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
-3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
-2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
-1: 每个quicklist节点上的ziplist大小不能超过4 Kb。5、intset:
intset数据结构详解:http://zhangtielei.com/posts/blog-redis-intset.html
(1)什么是intset:
intset是一个由整数组成的有序集合,从而便于进行二分查找,用于快速地判断一个元素是否属于这个集合。它在内存分配上与ziplist有些类似,是连续的一整块内存空间,而且对于大整数和小整数(按绝对值)采取了不同的编码,尽量对内存的使用进行了优化。- 1
(2)intset的数据结构:
typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset; #define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
各个字段含义如下:
encoding: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。 length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。 contents: 是一个柔性数组(flexible array member),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于encoding * length。柔性数组在Redis的很多数据结构的定义中都出现过(例如sds, quicklist, skiplist),用于表达一个偏移量。contents需要单独为其分配空间,这部分内存不包含在intset结构当中。- 1
- 2
- 3
其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
最开始,新创建的intset使用占内存最小的INTSET_ENC_INT16(值为2)作为数据编码。
每添加一个新元素,则根据元素大小决定是否对数据编码进行升级。
(3)intset与ziplist相比:ziplist可以存储任意二进制串,而intset只能存储整数。
ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段len),而intset只能整体使用一个统一的编码(encoding)。
6、skiplist:
skiplist数据结构详解:http://zhangtielei.com/posts/blog-redis-skiplist.html(1)什么是跳表:
跳表是一种可以进行二分查找的有序链表,采用空间换时间的设计思路,跳表在原有的有序链表上面增加了多级索引(例如每两个节点就提取一个节点到上一级),通过索引来实现快速查找。跳表是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度都为O(logn),空间复杂度为 O(n)。跳表非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。- 1
① 跳表的删除操作:除了要删除原始链表中的节点,还要删除索引中的节点。
② 插入元素后,索引的动态更新:不停的往跳表里面插入数据,如果不更新索引,就有可能出现某两个索引节点之间的数据非常多的情况,甚至退化成单链表。针对这种情况,我们在添加元素的时候,通过一个随机函数,同时选择将这个数据插入到部分索引层。比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第K级这K级的索引中
redis缓存穿透、缓存雪崩、缓存击穿(热点Key)解决方案
redis缓存穿透:查询一个数据库中不存在的数据,比如商品详情,查询一个不存在的ID,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成过大地压力
解决方案:当通过某一个key去查询数据的时候,如果对应在数据库中的数据都不存在,我们将此key对应的value设置为一个默认的值,比如“NULL”,并设置一个缓存的失效时间,这时在缓存失效之前,所有通过此key的访问都被缓存挡住了。后面如果此key对应的数据在DB中存在时,缓存失效之后,通过此key再去访问数据,就能拿到新的value了。reds缓存雪崩:是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:将系统中key的缓存失效时间均匀地错开,防止统一时间点有大量的key对应的缓存失效。比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。redis缓存击穿(热点Key):缓存中的一个Key(比如一个促销商品),在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:使用互斥锁(mutex key)。对缓存查询加锁,如果KEY不存在,就加锁,然后查DB入缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回数据或者进入DB查询 -
相关阅读:
案例:MySQL主从复制与读写分离
我眼中的阿里不完美,但值得去学5年
微视网媒:出光润滑油,只有老司机知道它的好
深度之眼(二十)——Python:Pandas库
第11集丨你其实是个“富二代”
vue3父子通信+ref,toRef,toRefs使用实例
或许是 WebGIS 下一代的数据规范 - OGC API 系列
Swin Transformer V2 Scaling Up Capacity and Resolution(CVPR2022)
JAVA直播购物平台计算机毕业设计Mybatis+系统+数据库+调试部署
记一次加锁导致ECS服务器CPU飙高的处理
- 原文地址:https://blog.csdn.net/tenyearsWait/article/details/126777041
