-
python函数运行加速
前言:
博主在处理一个任务的时候,需要需要遍历一个文件夹下面所有的文件,但是单个文件的处理特别耗时,发现cp几乎在单核工作,根本没有发挥计算机的性能,下面来看一下具体的操作,调用所有的核心一起工作。
基本原理可参看这篇Python GIL锁_两只蜡笔的小新的博客-CSDN博客
一、代码改动前的被调用函数:
为了能够将使用方法讲清楚,下面详细说明函数改造前后的对比。
- def batch_process(imgdir, savedir_d1, savedir_d3):
- for i in tqdm(os.listdir(imgdir)):
- if i.split('.')[-1] != 'png':
- # print('continue..')
- continue
- direction_process_d1(os.path.join(imgdir, i), savedir_d1)
- direction_process_d3(os.path.join(imgdir, i), savedir_d3)
- start = time.time()
- ## connectivity cube
- batch_process(gt_path, connect_d1_path, connect_d3_path)
- end = time.time()
- print('Finished Creating connectivity cube, time {0}s'.format(end - start))
运行界面截图

然后可以看出cpu的核心使用情况,有两个核心上下跳动,说明两个核心在工作但不是同时工作。

二、代码改动后:
函数改造:
- def batch_process(imgdir, savedir_d1, savedir_d3,range_list=[0,None]):
- for i in tqdm(os.listdir(imgdir)[range_list[0]:range_list[-1]]):
- if i.split('.')[-1] != 'png':
- # print('continue..')
- continue
- direction_process_d1(os.path.join(imgdir, i), savedir_d1)
- direction_process_d3(os.path.join(imgdir, i), savedir_d3)
改造原理,可以看出我在函数的出入参数位置加了一个 range_list=[0,None],
并将for循环遍历的语句:
for i in tqdm(os.listdir(imgdir)):-》改为
for i in tqdm(os.listdir(imgdir)[range_list[0]:range_list[-1]]):
可以检查函数的功能,在不传入任何参数的情况下,该函数的功能保持和原函数一致。
而这个range_list的具体作用应该很明显,用于控制函数操作的文件夹下面的文件的范围,
正是这个可以控制的范围让这个函数在稍后可以并行运行。
主函数改造:
- start = time.time()
- ## connectivity cube
- import multiprocessing
- from functools import partial
- BUCKET_NUM = 8 #并行线程数量
- #### 生成 range_list ###################################
- BUCKET_SIZE = int(len(os.listdir(gt_path)) / BUCKET_NUM)
- range_list =[]
- for x in range(BUCKET_NUM):
- end_f = True if len(os.listdir(gt_path))%BUCKET_NUM==0 else False
- range_list.append([x*BUCKET_SIZE,(x+1)*BUCKET_SIZE])
- range_list.append([(x + 1) * BUCKET_SIZE,None]) if end_f else ''
- ##### finish ###########################################
- pool = multiprocessing.Pool()# 构造多线程池
- func = partial(batch_process, gt_path, connect_d1_path, connect_d3_path)#包装函数
- pool.map(func, range_list) #传入可变参数
- pool.close()
- pool.join()
- # batch_process(gt_path, connect_d1_path, connect_d3_path)
- end = time.time()
- print('Finished Creating connectivity cube, time {0}s'.format(end - start))
函数运行过程截图:这里只展示了一个进程,等待运行结束就会显示所有的进程。
运行结束截图:

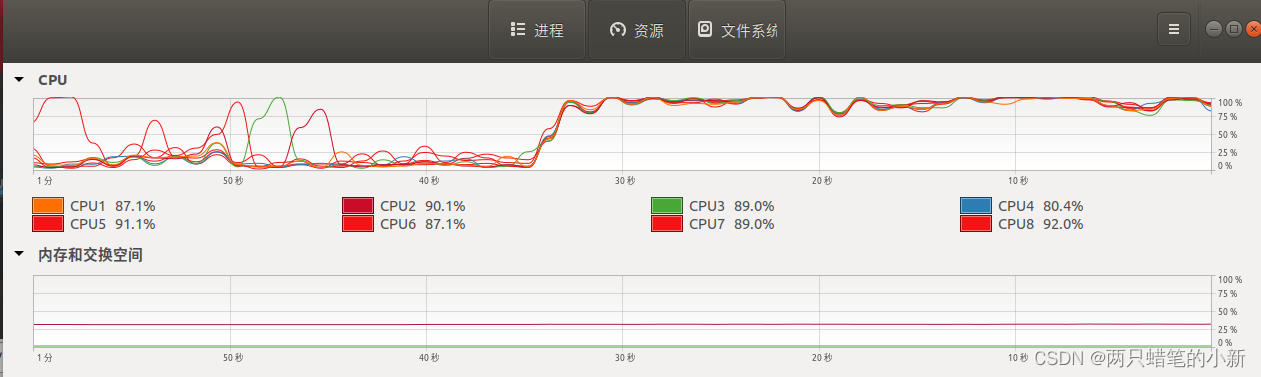
之前的1h的代码,下载只需要9分30秒 ,再来看看CPU的使用情况:
-
相关阅读:
Synchronized和Lock的区别
【【萌新的STM32的学习--非正点原子视频的中断设计思路】】
【C/C++】宏定义中的#和##
C语言题收录(一)
使用brainconn工具绘制的大脑连接数据,比BrainNet更方便和灵活
nms非极大抑制
开源大数据 Studio 应用开发: Apache Dolphinscheduler + Notebook
重读GPDB 和 TiDB 论文引发的 HTAP 数据库再思考
2024年csdn最新最全面的fiddler教程【1】
校园论坛(Java)—— 帖子模块
- 原文地址:https://blog.csdn.net/weixin_44503976/article/details/126764308