-
11、Python 闭包实现原理
一、内存的逻辑状态
在了解闭包之前,让我们简单了解下内存逻辑状态。内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区
- 栈内存:稳定性差,用于临时存储数据,存储数据比较快。方法中定义的变量都存放在这个区域,但存放的只是名称和指向堆内存空间的地址
- 堆内存:稳定性高,用于长期存储数据,存储数据的速度慢。程序运行时会创建对像,对象会被保存堆内存中,以便反复利用。
- 常量区:可以永久存储软件中经常使用的固定数据
- 资源区: 可以存储程度运行的基本资源数据,如:运行的二进制代码
下图展示了基本的变量在内存中的逻辑关系:
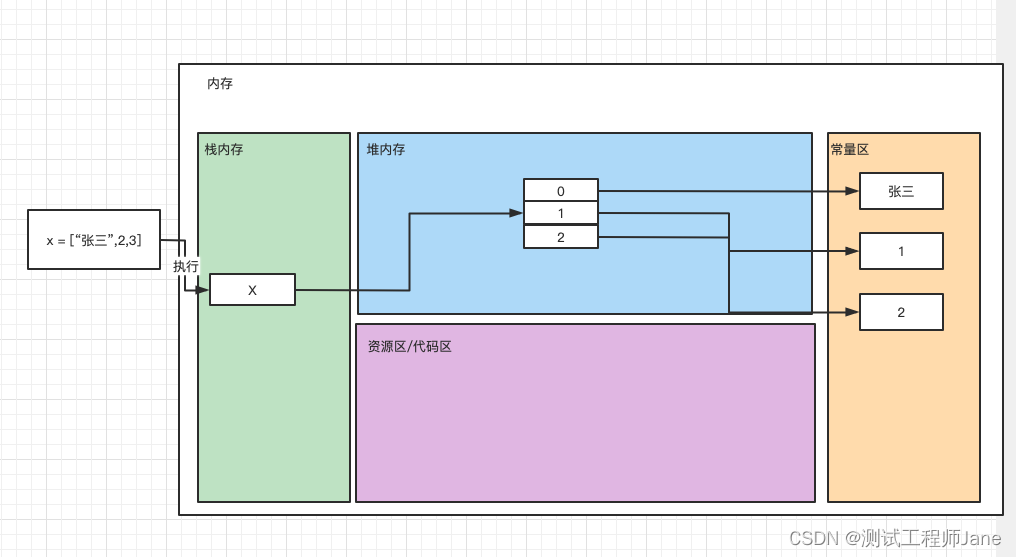
说明:堆内存中的对象不会随方法的结束而销毁,即使方法结束后,这个对象还可能被另一个引用变量所引用(方法的参数传递时很常见),则这个对象依然不会被销毁,只有当一个对象没有任何引用变量引用它时,系统的垃圾回收机制才会在核实的时候回收它。
二、闭包实现原理
有了以上的基础,我们现在对闭包进行详细的了解,闭包的本质是一个函数,而这个函数引用了上层局部命名空间的变量。
自由变量:未在本地作用域中定义的变量,例如:定义外层函数内被内层引用的变量
闭包:是一个概念,出现在嵌套函数中,指的是内层函数引用到了外层函数的自由变量,就形成了闭包,很多语言中都有这个概念,在Python中常见于装饰器中让我们来看个例子:
def outer(): c = [1] def inner(): c[0] =+ 1 #这一行会报错吗? return c[0] return inner foo = outer() foo() foo()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果:

为什么会出现以上结果,这是因为outer函数的执行结束后,outer的引用为0,刚释放了相应的堆栈空间,但C[0]仍被内层的inner引用,这时C[0]就r被保留了在了栈内,当Inner被调用时,便可以使用c[0]的值我们可以看粗略的看下闭包的图示过程,但下图仅供了解基本原理:
- 程序运行时,解释器会将代码以二进制形式加载到代码区,当我们执行到foo = outer()时,调用函数,从代码区找到内容,并在堆区创建Outer的堆空间,即栈针
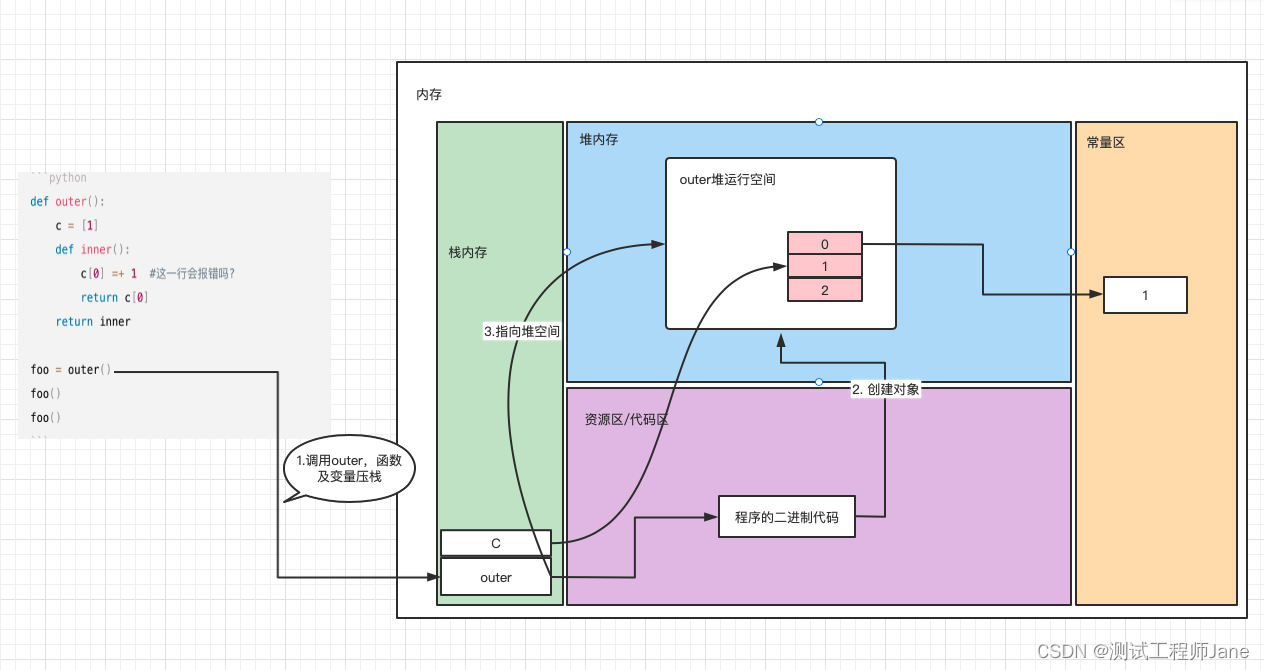
2.然后outer函数返回,foo变量名指向了内部inner函数。这时虽然Outer的运行空间被释放。
但由于函数加载的时候inner内使用了C[0],这样的话,在outer释放的时候,将c[0]与Inner进行了绑定,也就是说,C的引用计数不为0,这样它在堆栈内就未被释放 ,从而当我们在inner执行多次时,C[0]的值一直可以被使用,直到c[0]使用完成,引用计数为0被释放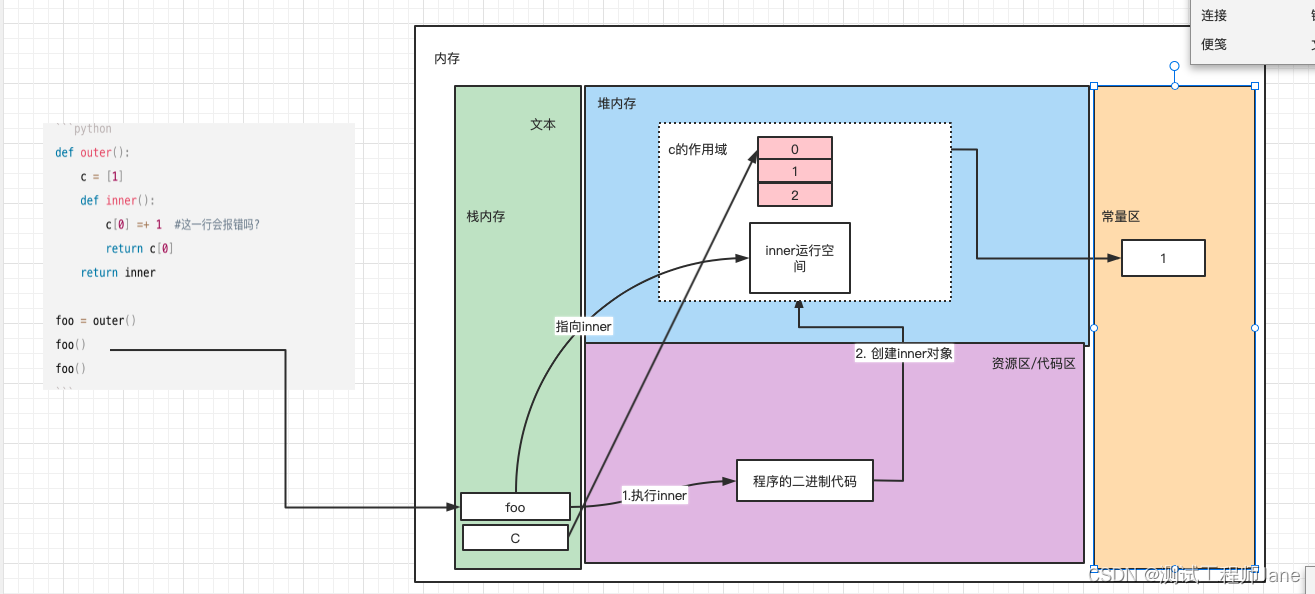
以上内容均为个人学习理解,如有不正确,还请指正,如果有转载请注明出处。
-
相关阅读:
若依框架入门一
[网络工程师]-网络层协议-移动IP协议
【云原生Docker系列第五篇】Docker数据管理(与其互为人间,不如自成宇宙)
数组力扣485题---最大连续1的个数
论文笔记之《Pre-trained Language Model for Web-scale Retrieval in Baidu Search》
Qt之自定义带游标的QSlider
探索ClickHouse——使用MaterializedView存储kafka传递的数据
js如何实现数组去重的常用方法
一次Python本地cache不当使用导致的内存泄露
Linux进程间通信
- 原文地址:https://blog.csdn.net/totorobig/article/details/126691647