-
Python05、字典、键值对、文件、标准库
字典
字典是Python里面的内置类型
字典是一种存储键值对的结构
# 创建字典,大括号{}表示字典 a = {}# 方法1 print(type(a)) b = dict()# 方法2 print(type(b)) # 创建字典的同时设置初始值 a = {"id": 1, "name": "zhang"} # 字典a中包含了两个键值对 # "id": 1 key就是"id",value就是1 # "name": "zhangsan" key就是"name",value就是"zhang" # 一个字典中的key的类型不一定都一样 # 一个字典中的value的类型也不必都一样 # 字典对于key是什么类型是有约束的 # 对于value是什么类型是有约束的 # 建议分开多行来写 a = { "id": 1, "name": "zhang",# 这样写成字典的初始值的时候,最后一个键值对后面的逗号可有可无 }键值对
键值对: 计算机中的一个非常非常重要的概念
键(key)值(value)对:根据key能够快速找到value,也就是把key和value构造了一个映射关系
例如:某个学号对应某个学生
在Python字典中,可以同时包含很多个键值对,同时要求这些键不能重复
在字典里查找key
# 想要查找key,先得判断key是否存在 # 1.使用in来判断某个key是否在字典中存在 # a = { # "id": 1, # "name": "zhang", # } # # print("id" in a)# 在,返回True # print("class_id" in a) # #上面这两个操作只是判断key是否存在,和value无关 # print("zhang" in a)# 像这样是不行的 # # # not in来判定key在字典中不存在 # print("id" not in a) # print("class_id" not in a) # 2.使用[]来根据key获取到value a = { "id": 1, "name": "zhang", 100: "li", } print(a["id"])# 方括号里面写key的内容的时候,是根据key找到value print(a["name"]) print(a[100])# 注意,这里的100是key,不是下标 # print(a["class_id"])# 会报错 # 对于字典来说,使用in或[]来获取value都是非常高效的操作。因为字典背后使用了特殊的数据结构(哈希表),是属于比较高效的 # 对于列表来说,使用in是比较低效的,而使用[]是比较高效的。因为它需要把整个列表遍历一遍关于字典的新增和修改操作
# 在字典中新增/修改元素,使用[]来进行 a = { "id": 1, "name": "zhang", } a["score"] = 90# 像这样的操作,就是往字典里插入新的键值对 print(a) # key不存在的时候不是会出现异常吗?之所以前面出现异常,是因为我们尝试进行打印,是一个读操作,存在了才被读,不存在还读所以是错误的 # 但是我们这里是写操作,不要求说原来必须存在 # 在字典中,根据key修改value,也是使用[]来进行的 a["score"] = 100 print(a) # 如果key不存在,往里写入,相当于新增键值对,这个行为是写操作 # 如果key存在,往里写入,相当于根据key修改value,当然,这个行为是写操作 # 在字典中,想要删除键值对。使用pop,根据key来删除键值对 a.pop("name") print(a) # 字典的各种操作,都是针对key来进行的。新增,删除,获取value,修改value... # 字典被设计出来的初衷,不是为了实现遍历,而是为了增删改查 # 字典是哈希表,进行增删改查操作,效率都是非常高的 # 而字典的遍历效率就要差一些 # 为什么它的增删改查效率高呢?因为哈希表这个结构被设计的非常巧妙,能够以“常数级(增删改查操作的时间都是固定的,不会因为元素多了操作就慢了)”时间复杂度来完成增删改查 # 注意。字典中的key是要求不能重复的遍历字典元素
# 遍历字典元素 # 直接用for循环遍历字典 # a = { # "id": 1, # "name": "zhang", # "score": 90, # } # for key in a: # print(key, a[key]) # 在C++/Java中,哈希表里面的键值对存储的顺序是无序的 # 但是在Python中还不一样,Python中做了特殊处理,能够保证遍历出来的顺序,就是和插入的顺序是一致的 # Python中的字典,说是一个字典,又不是一个单纯得哈希表 # keys:获取到字典中的所有key # values:获取到字典中的所有value # items:获取到字典中的所有键值对 # # print(a.keys())# 获取所有keys的数据 # # 返回的结果看起来像列表,又不完全是,它是一个自定义类型。使用的时候也可以把它当做一个列表来使用 # print(a.values()) # print(a.items()) # 首先是一个列表一样的结构,里面每个元素又是一个元组,元组里面包含了键和值 # a = { # "id": 1, # "name": "zhang", # "score": 90, # } # for key, value in a.items(): # print(key, value)字典中合法key的类型
# 字典中合法key的类型 # 要求类型是可哈希的,那么如何判断数据是否可哈希呢? # 使用hash函数能够计算出一个变量的哈希值 # print(hash(0)) # print(hash(3.14)) # print(hash("hello")) # print(hash(True)) # print(hash((1, 2, 3))) # # # 有的类型是不能计算哈希值的 # print(hash([1, 2, 3]))# TypeError: unhashable type: 'list'。这个类型不能哈希 # print(hash({ }))# 这样也是不可计算的 # 像布尔类型,整数,浮点数,字符串,元组都是可哈希的,像列表,字典,是不可哈希的,所以前面那几种都可以作为字典的key # 一个不可变的对象,一般就是可哈希的,一个可变的对象,一般就是不可哈希的 # 字典,列表,元组都是Python中非常常用的内置类型,相比于int,str,float,它们的内部可以再包含其他元素 # 像这样的一些特殊的类型,我们也把它称为容器/集合类文件
变量是把数据保存到内存中,要想能让数据被持久化存储,就可以把数据存储到硬盘中,也就是在文件中保存
通过文件的后缀名 , 可以看到文件的类型 . 常见的文件的类型如下 :文本文件 (txt)可执行文件 (exe, dll)图片文件 (jpg, gif)视频文件 (mp4, mov)office 文件 (.ppt, docx)一个机器上 , 会存在很多文件 , 为了让这些文件更方面的被组织 , 往往会使用很多的 " 文件夹 "( 也叫做 目录)来整理文件。
文件路径
实际一个文件往往是放在一系列的目录结构之中的。为了方便确定一个文件所在的位置, 使用 文件路径 来进行描述

文件操作
读写文件之前要先打开文件,读写文件之后呢要关闭文件
读文件:把硬盘上的数据取出来,读到内存里
写文件:把内存的数据保存到硬盘之中
打开文件、读文件、写文件、关闭文件
文件操作
要使用文件,主要是通过文件来保存数据,并且在后续把保存的数据读取出来
但是要想读写文件,需要先打开文件,读写完毕之后还要关闭文件
打开文件
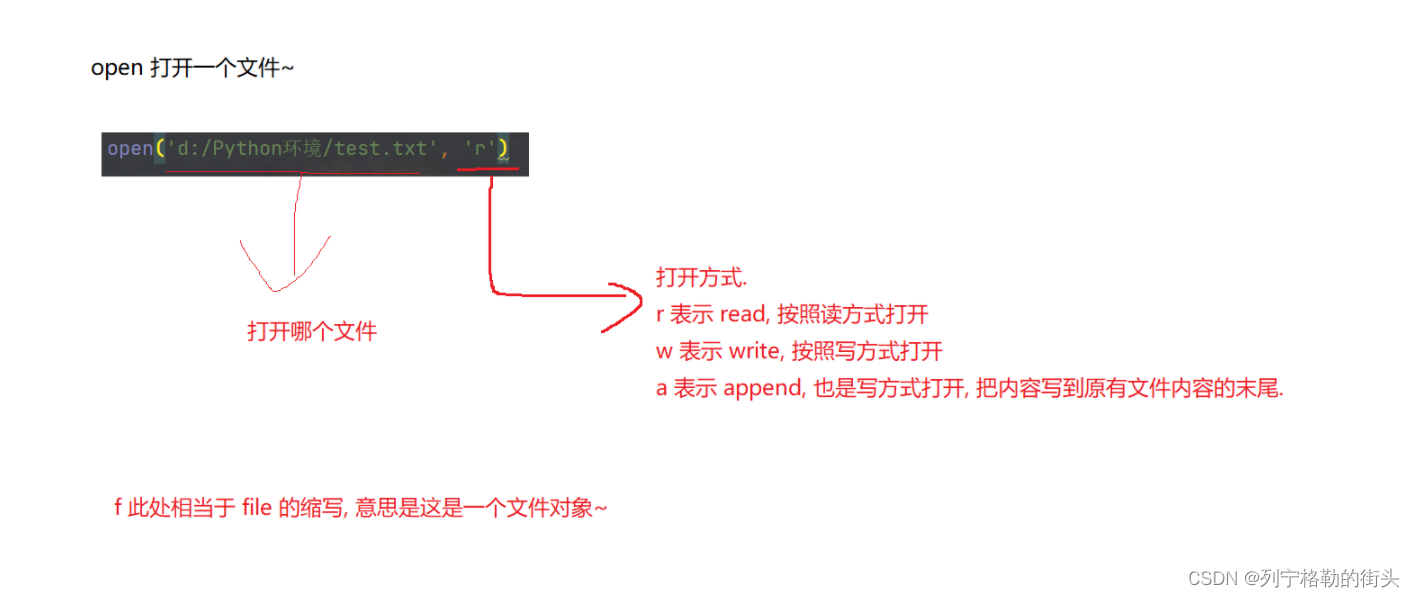
使用内建函数open 打开一个文件
f = open ( 'd:/test.txt' , 'r' )第一个参数是一个字符串,表示要打开的文件路径第二个参数是一个字符串,表示打开方式,其中r表示按照读方式打开,w表示按照写方式打开,a表示追加写方式打开如果文件打开成功,返回一个文件对象,后续的读写文件操作都是围绕这个文件对象展开如果打开文件失败(比如路径指定的文件不存在),就会抛出异常# 文件 # 打开文件 # 使用open来打开一个文件 # open("d:/test/test.txt")# 如果文件不存在,则报错 # open("d:/test/test.txt", "r")# 此处的r是read的缩写,代表打开方式 # open函数的返回值是一个文件对象,是用来表示文件的对象,这里用f表示一下 f = open("d:/test/test.txt", "r") print(f) print(type(f))
关闭文件
使用close 方法关闭已经打开的文件
f.close()
使用完毕的文件要记得及时关闭
# 文件 # 打开文件 # 使用open来打开一个文件 # open("d:/test/test.txt")# 如果文件不存在,则报错 # open("d:/test/test.txt", "r")# 此处的r是read的缩写,代表打开方式 # open函数的返回值是一个文件对象,是用来表示文件的对象,这里用f表示一下 # f = open("d:/test/test.txt", "r") # print(f) # print(type(f)) # f.close() # 看着好像没啥用,文件在打开完之后,使用完之后,也就一定要关闭 # 打开文件,其实是在申请一定的系统资源。不再使用文件的时候,资源就应该及时释放,有借有还再借不难。 # 否则,可能造成文件资源泄漏,进一步导致其他部分的代码无法顺利打开文件了 # 正是因为一个系统的资源是有限的,因此一个程序能打开的文件个数也是有上限的一个程序能同时打开的文件个数是存在上限的
flist = [ ]count = 0while True :f = open ( 'd:/test.txt' , 'r' )flist . append ( f )count += 1print ( f'count = { count } ' ) 如上面代码所示 , 如果一直循环的打开文件 , 而不去关闭的话 , 就会出现上述报错 .当一个程序打开的文件个数超过上限 , 就会抛出异常 .注意 : 上述代码中 , 使用一个列表来保存了所有的文件对象 . 如果不进行保存 , 那么 Python 内置的垃圾回收机制 , 会在文件对象销毁的时候自动关闭文件 .但是由于垃圾回收操作不一定及时 , 所以我们写代码仍然要考虑手动关闭 , 尽量避免依赖自动关闭 .
如上面代码所示 , 如果一直循环的打开文件 , 而不去关闭的话 , 就会出现上述报错 .当一个程序打开的文件个数超过上限 , 就会抛出异常 .注意 : 上述代码中 , 使用一个列表来保存了所有的文件对象 . 如果不进行保存 , 那么 Python 内置的垃圾回收机制 , 会在文件对象销毁的时候自动关闭文件 .但是由于垃圾回收操作不一定及时 , 所以我们写代码仍然要考虑手动关闭 , 尽量避免依赖自动关闭 .写文件
文件打开之后就可以写文件了
写文件要使用写方式打开,open第二个参数设为"w"
使用write方法写入文件
f = open ( 'd:/test.txt' , 'w' )f . write ( 'hello' )f . close ()打开文件后即可看到文件修改后的内容如果是使用"r"方式打开文件,则写入时会抛出异常f = open ( 'd:/test.txt' , 'r' )f . write ( 'hello' )f . close () 使用"w"一旦打开文件成功,就会清空文件原有的数据使用"a"实现“追加写”,此时原有内容不变,写入的内容会存在于之前文件内容的末尾f = open ( 'd:/test.txt' , 'w' )f . write ( 'hello' )f . close ()f = open ( 'd:/test.txt' , 'a' )f . write ( 'world' )f . close ()针对已经关闭的文件对象进行写操作,也会抛出异常f = open ( 'd:/test.txt' , 'w' )f . write ( 'hello' )f . close ()f . write ( 'world' )
使用"w"一旦打开文件成功,就会清空文件原有的数据使用"a"实现“追加写”,此时原有内容不变,写入的内容会存在于之前文件内容的末尾f = open ( 'd:/test.txt' , 'w' )f . write ( 'hello' )f . close ()f = open ( 'd:/test.txt' , 'a' )f . write ( 'world' )f . close ()针对已经关闭的文件对象进行写操作,也会抛出异常f = open ( 'd:/test.txt' , 'w' )f . write ( 'hello' )f . close ()f . write ( 'world' )
读文件
读文件内容需要使用"r"的方式打开文件
使用read方法完成读操作,参数表示“读取几个字符”
f = open ( 'd:/test.txt' , 'r' )result = f . read ( 2 )print ( result )f . close ()如果文件是多行文本,可以使用for循环一次读取一行
认识标准库
库:别人已经写好的代码,我们拿来用。
Python中是通过模块来实现“库”的
库的优点:
1.降低程序员的学习成本
2.提高程序的开发效率
库可以分为两个大类:
1.标准库(Python自带的库)2.第三方库(其他大佬做出来的)
第三方库是非常非常庞大的,数量和种类远远多于标准库
第三方库
使用pip
Python官方搞了一个网站pypi,把各种第三方库收集起来了
又提供了一个pip工具,使用pip就能直接从pypi上下载你想要的第三方库
-
相关阅读:
深度学习笔记_4、CNN卷积神经网络+全连接神经网络解决MNIST数据
巡检机器人智能联网,促进工厂自动化
LeetCode 509 斐波那契数(动态规划)
“ObservationAndApproach“ app Tech Support(URL
技术内幕 | 阿里云EMR StarRocks 极速数据湖分析
WEB漏洞-文件操作之文件包含漏洞
Java while dowhile语法
ajax点击显示更多实例(静态更新)
Linux 性能分析工具- Atop安装和使用
c++ string的简单实现
- 原文地址:https://blog.csdn.net/weixin_60320290/article/details/126715585