-
ElasticSearch - 初步检索
一、基本概念
1、Near Realtime(NRT 近实时)
ElasticSearch 是一个近实时的搜索平台。这意味着从您索引一个文档开始直到它可以被查询时会有轻微的延迟时间(通常为一秒)。
2、Cluster(集群)
cluster(集群)是一个或者多个节点的集合,它们一起保存数据并且提供所有节点联合索引以及搜索功能。集群存在一个唯一的名字身份且默认为 “elasticsearch”。这个名字非常重要,因为如果节点安装时通过它自己的名字加入到集群中的话,那么一个节点只能是一个集群中的一部分。
3、Node(节点)
node(节点)是一个单独的服务器,它是集群的一部分,存储数据,参与集群中的索引和搜索功能。像一个集群一样,一个节点通过一个在它启动时默认分配的一个随机的 UUID(通用唯一标识符)名称来识别。如果您不想使用默认名称您也可自定义任何节点名称。这个名字是要识别网络中的服务器对应,这在您的 Elasticsearch 集群节点管理的目的是很重要的。
4、Index(索引)
动词,相当于MySQL中的insert;
名词,相当于MySQL中的Database5、Type(类型)
在 Index(索引)中,可以定义一个或多个类型。
类似于MySQL中的Table;每一种类型的数据放在一起;
5.x以前的版本里边,一个index下面是支持多个type的,
6.x的版本里改为一个index只支持一个type,type可以自定义。
7.x的版本所有的type默认为_doc(自定义type也能用,但是会提示不推荐)6、Document(文档)
保存在某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的,Document就像是MySQL中的某个Table里面的内容
7、Shards & Replicas(分片 & 副本)
索引可以存储大量数据,可以超过单个节点的硬件限制。例如,十亿个文档占用了 1TB 的磁盘空间的单个索引可能不适合放在单个节点的磁盘上,并且从单个节点服务请求会变得很慢。
为了解决这个问题,ElasticSearch 提供了把 Index(索引)拆分到多个 Shard(分片)中的能力。在创建索引时,您可以简单的定义 Shard(分片)的数量。每个 Shard 本身就是一个 fully-functional(全功能的)和独立的 “Index(索引)”,(Shard)它可以存储在集群中的任何节点上。
Sharding(分片)非常重要两个理由是 :
1)水平的拆分/扩展。
2)分布式和并行跨 Shard 操作(可能在多个节点),从而提高了性能/吞吐量。
每个索引可以被拆分成多个分片,一个索引可以设置 0 个(没有副本)或多个副本。开启副本后,每个索引将有主分片(被复制的原始分片)和副本分片(主分片的副本)。分片和副本的数量在索引被创建时都能够被指定。在创建索引后,您也可以在任何时候动态的改变副本的数量,但是不能够改变分片数量。二、初步检索
1、_cat
GET /_cat/nodes:查看所有节点 GET /_cat/health:查看es健康状况 GET /_cat/master:查看主节点 GET /_cat/indices:查看所有索引- 1
- 2
- 3
- 4
2、索引一个文档
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/_doc/1;在customer索引下的external类型下保存1号数据为
PUT和POST都可以,
POST新增。如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号
PUT可以新增可以修改。PUT必须指定id;由于PUT需要指定id,我们一般都用来做修改操作,不指定id会报错。PUT customer/_doc/1 { "name": "John Doe" }- 1
- 2
- 3
- 4
3、查询文档
GET customer/_doc/1- 1
4、更新文档
不同点:
- POST:
- 带有_update:会对比源文档数据,如果相同不会有什么操作,文档version不增加。
- 不带有_update:与PUT是一样的,都是总会将数据重新保存并增加version版本。
- PUT:总会将数据重新保存并增加version版本。
使用场景:
- 对于大并发更新,不带update;
- 对于大并发查询偶尔更新,带update;对比更新,重新计算分配规则。
简单更新
POST customer/_doc/1/_update { "doc":{ "name": "John Doew" } } 或者 PUT customer/_doc/1 { "name": "John Doew" } 或者 POST customer/_doc/1 { "name": "John Doew" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
更新同时增加属性
PUT customer/_doc/1 { "doc": { "name": "Jane Doew", "age": 20 } }- 1
- 2
- 3
- 4
- 5
简单脚本更新
PUT customer/_doc/1 { "script" : "ctx._source.age += 5" }- 1
- 2
- 3
- 4
5、删除文档&索引
DELETE customer/_doc/1 DELETE customer- 1
- 2
- 3
6、bulk批量API(不是原子性的)
语法格式:
{ action: { metadata }} { request body } { action: { metadata }} { request body }- 1
- 2
- 3
- 4
- 5
-
action(必须是以下选项之一):
- create:如果文档不存在,那么就创建它。
- index:创建一个新文档或者替换一个现有的文档。
- update:部分更新一个文档。
- delete:删除一个文档。
-
metadata:应该指定被索引、创建、更新或者删除的文档的 _index 、 _type 和 _id 。
-
request body:行由文档的 _source 本身组成—文档包含的字段和值。它是 index 和create、update 操作所必需的,而删除操作不需要 request body 行。
简单实例:
POST customer/_doc/_bulk {"index":{"_id":"1"}} {"name": "John Doe" } {"index":{"_id":"2"}} {"name": "Jane Doe" }- 1
- 2
- 3
- 4
- 5
复杂实例:
POST _bulk { "delete": { "_index": "website", "_type": "_doc", "_id": "123" }} { "create": { "_index": "website", "_type": "_doc", "_id": "123" }} { "title": "My first blog post" } { "index": { "_index": "website", "_type": "_doc" }} { "title": "My second blog post" } { "update": { "_index": "website", "_type": "_doc", "_id": "123"} } { "doc" : {"title" : "My updated blog post"} }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
bulk API 以此按顺序执行所有的 action(动作)。如果一个单个的动作因任何原因而失败,它将继续处理它后面剩余的动作。当 bulk API 返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是不是失败了。参考文档
三、工作流程
1、Elasticsearch文档写入原理
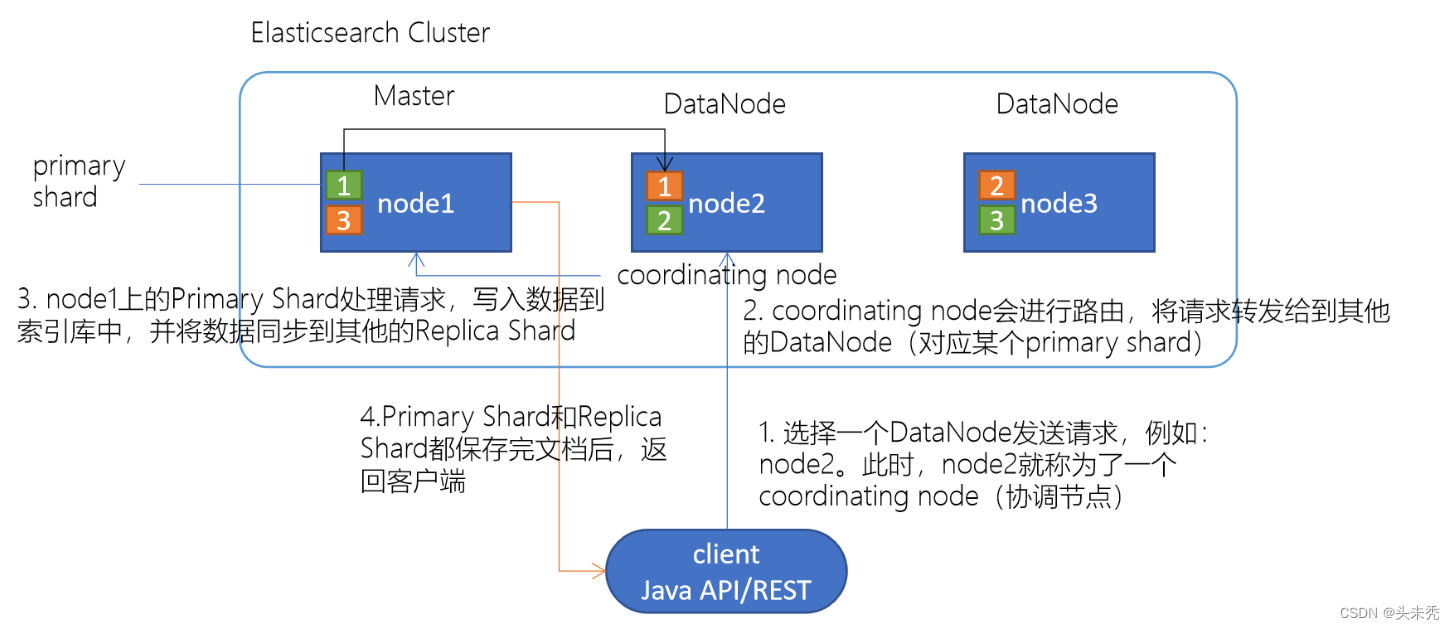
- 选择任意一个DataNode发送请求,例如:node2。此时,node2就成为一个协调节点(coordinating node)
- 计算得到文档要写入的分片,至于写入哪个分片中是由下面算法计算出来的,routing可以指定,默认是文档的id,算法的结果必定是在分片数量之间。(shard = hash(routing) % number_of_primary_shards)
3.协调节点(coordinating node)会进行路由,将请求转发给对应的主分片(primary shard)所在的DataNode(假设主分片(primary shard)在node1、副分片(replica shard)在node2) - node1节点上的主分片(primary shard)处理请求,写入数据到索引库中,并将数据同步到副分片(replica shard)
- 主分片(primary shard)和副分片(replica shard)都保存好了文档,返回client
2、Elasticsearch检索原理
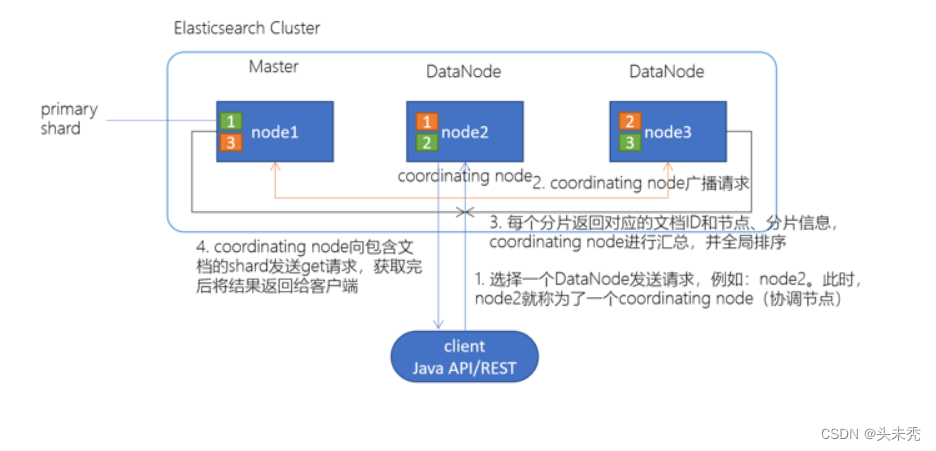
- client发起查询请求,某个DataNode接收到请求,该DataNode就会成为协调节点(coordinating node)。
- 协调节点(coordinating node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求。
- 每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点;协调节点将所有的结果进行汇总,并进行全局排序。(协调汇总,从这里也能看出数据节点压力大一些,要多分配一些内存)
- 协调节点(coordinating node)向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端
由此可见,分片越多,查询的效率肯定会有一定影响的。
-
相关阅读:
万界星空科技/免费MES系统/开源MES/免费追溯管理
blazor调试部署全过程
Java8特性-Lambda表达式
JavaScript事件高级导读
LoRaWAN物联网架构
JavaScript 测试基础,TDD、BDD、Benchmark
新增分组柱状图,DataEase开源数据可视化分析平台v1.14.0发布
代码随想录 --- day21 --- 530.二叉搜索树的最小绝对差、501.二叉搜索树中的众数 、236. 二叉树的最近公共祖先
[python 刷题] 49 Group Anagrams
自制一款远程控制软件——VeryControl
- 原文地址:https://blog.csdn.net/qq_42764269/article/details/126745515