-
Kafka3.x核心速查手册二、客户端使用篇-3、消息序列化机制
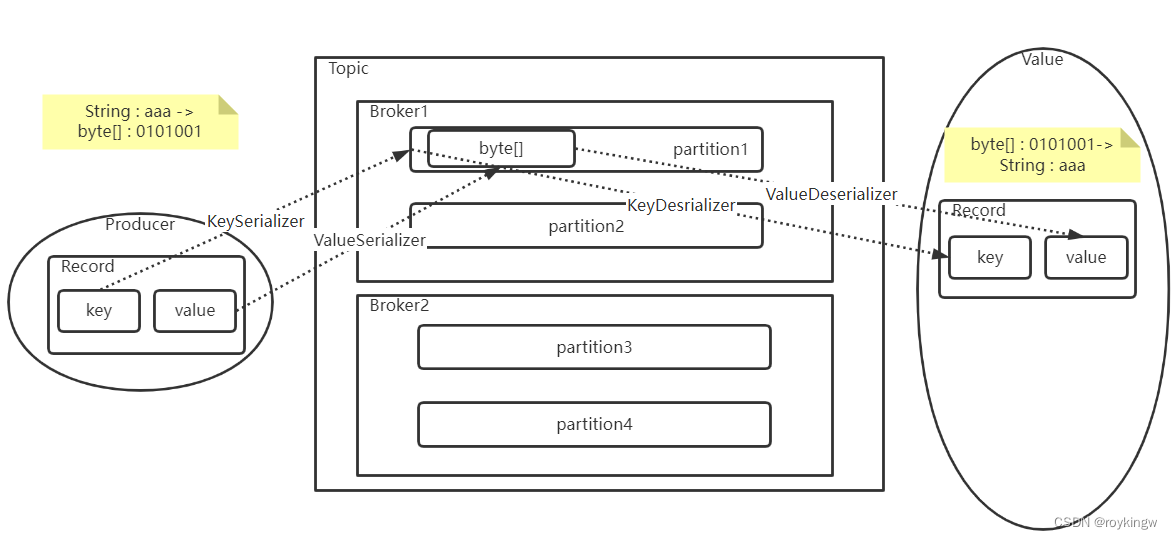
在之前的简单示例中,Producer指定了两个属性KEY_SERIALIZER_CLASS_CONFIG和VALUE_SERIALIZER_CLASS_CONFIG,对于这两个属性,在ProducerConfig中都有配套的说明属性。
public static final String KEY_SERIALIZER_CLASS_CONFIG = "key.serializer"; public static final String KEY_SERIALIZER_CLASS_DOC = "Serializer class for key that implements theorg.apache.kafka.common.serialization.Serializerinterface."; public static final String VALUE_SERIALIZER_CLASS_CONFIG = "value.serializer"; public static final String VALUE_SERIALIZER_CLASS_DOC = "Serializer class for value that implements theorg.apache.kafka.common.serialization.Serializerinterface.";- 1
- 2
- 3
- 4
这些这些属性,在下面都会加载默认配置。
从描述中可以看到,这两个属性是对消息的key和value进行格式化的配置。
对于生产者,key和value的作用分别如下:
- key是用来进行分区的可选项。Kafka通过key来判断消息要分发到哪个Partition。
如果没有填写key,那么Kafka会使Round-robin轮询的方式,自动选择Partition。
如果填写了key,那么会通过声明的Serializer序列化接口,将key转换成一个byte[]数组,然后对key进行hash,选择Partition。这样可以保证key相同的消息会分配到相同的Partition中。
- Value是业务上比较关心的消息。Kafka同样需要将Value对象通过Serializer序列化接口,将Key转换成byte[]数组,这样才能比较好的在网络上传输Value信息,以及将Value信息落盘到操作系统的文件当中。
生产者要对消息进行序列化,那么消费者拉取消息时,自然需要进行反序列化。所以,在Consumer中,也有反序列化的两个配置
public static final String KEY_DESERIALIZER_CLASS_CONFIG = "key.deserializer"; public static final String KEY_DESERIALIZER_CLASS_DOC = "Deserializer class for key that implements theorg.apache.kafka.common.serialization.Deserializerinterface."; public static final String VALUE_DESERIALIZER_CLASS_CONFIG = "value.deserializer"; public static final String VALUE_DESERIALIZER_CLASS_DOC = "Deserializer class for value that implements theorg.apache.kafka.common.serialization.Deserializerinterface.";- 1
- 2
- 3
- 4
在Kafka中,对于常用的一些基础数据类型,都已经提供了对应的实现类。但是,如果需要使用一些自定义的消息格式,比如自己定制的POJO,就需要定制具体的实现类了。
在自己进行序列化机制时,需要考虑的是如何用二进制来描述业务数据。例如对于一个通常的POJO类型,可以将他的属性拆分成两种类型:一种类型是定长的基础类型,比如Integer,Long,Double等。这些基础类型转化成二进制数组都是定长的。这类属性可以直接转成序列化数组,在反序列化时,只要按照定长去读取二进制数据就可以反序列化了。另一种是不定长的浮动类型,比如String,或者基于String的JSON类型等。这种浮动类型的基础数据转化成二进制数组,长度都是不一定的。对于这类数据,通常的处理方式都是先往二进制数组中写入一个定长的数据的长度数据(Integer或者Long类型),然后再继续写入数据本身。这样,反序列化时,就可以先读取一个定长的长度,再按照这个长度去读取对应长度的二进制数据,这样就能读取到数据的完整二进制内容。
-
相关阅读:
nodejs+vue+elementui医院挂号预约管理系统4n9w0
教程 - 深度探讨在 Vue3 中引入 CesiumJS 的最佳方式
RFID电力资产全周期智能化管理应用解决方案
【算法|动态规划No.7】leetcode300. 最长递增子序列
SpringBoot 10 登录功能和登录拦截器
Docker实践笔记6:PHP容器制作
开发那些事儿:如何在视频中添加文字水印?
『PyQt5-Qt Designer篇』| 09 Qt Designer中分割线和间隔如何使用?
Go内存管理一文足矣
形式化验证方法研究综述
- 原文地址:https://blog.csdn.net/roykingw/article/details/126743810