-
【笔试】2022/9/4 网易互联网开发岗满分
本次笔试包含四道编程题,ACM模式。
1.给定包含n个数字的数组a和数字k,可以给a中每个数字任意次+k,问最多可以让多少个数字相等。n 1e5。
思路:既然可以任意次+k,那么对于模k相同的数字来说一定可以加到一个足够大的数字使得每个数字都相等。所以本题的本质其实就是在找a[i]%k相等的数字的最多是多少个,只需要用一个哈希表记录并维护最大值即可。
时间复杂度O(n)。
- #include
- using namespace std;
- const int N=1e5+5;
- int n,k,x,ans;
- int main(){
- scanf("%d %d",&n,&k);
- unordered_map<int,int> cnt;
- for(int i=1;i<=n;i++){
- scanf("%d",&x);
- cnt[x%k]++;
- if(cnt[x]>ans)
- ans=cnt[x];
- }
- cout<
- return 0;
- }
2.给定n,k,t,需要构造一个01字符串,长度为n,包含k个1,且相邻1的对数为t。无法构造出来时输出-1。n 1e5
题意杀:111算两对,题目里没说,需要做题经验比较丰富。
思路:其实本题的关键是要找出什么情况下能构造出来,也就是根据n和k求出可以构造的t的最小值mint和最大值maxt。显然maxt=k-1;mint需要考虑一下,如果1的数量小于等于0的数量加上1,则mint=0,因为可以通过0隔开1;否则,在此基础上每增加一个1就必然会增加一对相邻的1,因此mint=k-(n-k+1)。找到能构造出的t的范围后,就可以直接将t+1个1放在开头,得到t对相邻的1,其余的1一定可以用0隔开。
时间复杂度O(n)。
代码被覆盖了,懒得重写一遍了。
3.n个数字的数组a,允许进行k次操作,每次操作可以给一个数字减x,求操作后最大的数字最小是多少。n 1e5,a[i]和k 1e9。
思路:有一类题,求xx操作后最小的最大值(最大的最小值),常常会先二分答案,然后检查是否可以满足答案。这里首先也二分答案,左边界是-k*x(开头下意识设左边界0,由于必须进行k次操作,其实是可能到负数的),右边界是max{a[i]}。假设当前的答案是mid,可以计算使得每个数都小于等于mid需要操作多少次,即(a[i]-mid+x-1)/x,如果总次数不超过k次,说明可能存在更小的答案,缩小右边界;如果总次数超过k词,说明答案一定在更大的数字区间内,左边界增大。这样可行的原因就是因为答案存在单调性:某个答案可行时更大的答案一定可行,不需要再考虑右边的答案了;某个答案不可行时,更小的答案一定不可行,不需要再考虑左边的答案了。
二分答案个数O(logn),每次检查需要的操作次数O(n),总复杂度O(nlogn)。
- #include
- using namespace std;
- const int N=1e5+5;
- int n;
- #define ll long long
- ll k,x,a[N];
- bool check(ll mid){
- ll res=0;
- for(int i=1;i<=n;i++){
- if(a[i]>mid){
- res+=(a[i]-mid+x-1)/x;
- if(res>k)
- return false;
- }
- }
- return true;
- }
- int main(){
- scanf("%d %lld %lld",&n,&k,&x);
- for(int i=1;i<=n;i++){
- scanf("%lld",&a[i]);
- }
- ll l=-k*x,r=*max_element(a+1,a+1+n),mid,ans=0;
- while(l<=r){
- mid=(l+r)/2;
- if(check(mid)){
- r=mid-1;
- ans=mid;
- }
- else{
- l=mid+1;
- }
- }
- cout<
- return 0;
- }
4.给定n个节点的树,每个节点给定一个数字ai,一棵子树的权值是子树所有节点的ai的乘积的因子个数,求所有子树的权值和。n 1e5,ai 1e5.
思路:这个题相对前三题来说很难了,我最后也没去花时间证明自己的时间复杂度是完全正确的,这里讲一下大概思路和过程。
首先需要一定的数论知识:每一个数都存在一个唯一的素因式分解,例如
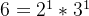 ,
,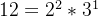 。假设x的素因式分解为
。假设x的素因式分解为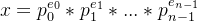 ,f(x)是x的因子个数,则
,f(x)是x的因子个数,则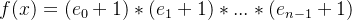 。
。我们可以通过线性筛O(1e5)预处理出1e5内所有数字是否是素数,以及每个数的最小素因子。然后通过最小素因子就可以O(log a[i])的分解每个a[i]。
接下来首先介绍我的暴力思路:预先分解每个a[i],并对于每个节点用哈希表存下素因子和对应的幂次;考虑到需要求子树的所有节点,因此采用递归回溯的方式,对于当前节点,将所有子节点处理完毕后的哈希表合并,维护当前节点的素因子表,最后根据素因子表计算以当前节点为根的子树权值。
提交时超内存了,很容易想到,每个节点最终维护的是子树的素因子表,粗略的假设每个节点的是一个不同的素数,那么最终表的总空间会是n^2级别。而且这种做法的时间复杂度和空间复杂度应该是一致的,因为每次都需要遍历整个素因子表,所以哪怕不超内存也会超时。
接下来就是思考如何优化,本题显然存在一个合并素因子表的过程,那么启发式合并就自然成了优化的方向。启发式合并是一种思想,合并的时候耗时的大头尽量不动,利用好此前已知的信息,将占比少的部分合并到大头上。
在本题中,就是每次将子节点中素因子数量最多的素因子表作为大头,假设称之为X,对应的答案称之为x。把其他素因子表合并到该表中,假设当前素因子p幂次为e,如果此前不在X中,则x*=(e+1);如果当前素因子此前在X中,且在X中的幂次为e',则x=x/(e'+1)*(e+1)。其中带模数的除法需要用到逆元的知识点。
优化后通过了本题。
- #include
- using namespace std;
- const int N=2e5+5;
- int n,a[N];
- vector
- vector
- bool np[N];
- int tot,prime[N],minp[N];
- void init(){
- np[1]=true;
- for(int i=2;iif(!np[i]){prime[tot++]=i;minp[i]=i;}for(int j=0;jnp[prime[j]*i]=true;minp[prime[j]*i]=prime[j];if(i%prime[j]==0){break;}}}}void fenjie(int i,int x){while(x!=1){cnt[i][minp[x]]++;x/=minp[x];}}#define ll long longconst int mod=1e9+7;ll ans[N],inv[N];int to[N];ll qpow(ll a,ll b){ll res=1;while(b){if(b&1)res=res*1ll*a%mod;a=a*1ll*a%mod;b>>=1;}return res;}void dfs(int u,int pre){int maxv=-1,maxx;ans[u]=1;to[u]=u;for(int v:G[u]){if(v!=pre){dfs(v,u);if(maxv==-1||cnt[to[v]].size()>maxx){maxx=cnt[to[v]].size();maxv=v;}}}if(maxv==-1){for(auto it=cnt[u].begin();it!=cnt[u].end();it++){ans[u]=ans[u]*(it->second+1)%mod;}return;}int tmaxv=to[maxv];to[u]=tmaxv;ans[u]=ans[maxv];int p,now,vv;for(int v:G[u]){if(v!=pre&&v!=maxv){vv=to[v];for(auto it=cnt[vv].begin();it!=cnt[vv].end();it++){if(!cnt[tmaxv].count(it->first)){cnt[tmaxv][it->first]=it->second;ans[u]=(ans[u]*(it->second+1))%mod;}else{auto it1=cnt[tmaxv].find(it->first);p=it1->second;now=it->second+it1->second;it1->second=now;ans[u]=ans[u]*inv[p+1]%mod*(now+1)%mod;}}}}for(auto it=cnt[u].begin();it!=cnt[u].end();it++){if(!cnt[tmaxv].count(it->first)){cnt[tmaxv][it->first]=it->second;ans[u]=ans[u]*(it->second+1)%mod;}else{auto it1=cnt[tmaxv].find(it->first);p=it1->second;now=it->second+it1->second;it1->second=now;ans[u]=ans[u]*inv[p+1]%mod*(now+1)%mod;}}}int main(){init();for(int i=1;iinv[i]=qpow(i,mod-2);assert(inv[i]*1ll*i%mod==1);}scanf("%d",&n);cnt=vectorG=vectorfor(int i=1;i<=n;i++){scanf("%d",&a[i]);fenjie(i,a[i]);}int u,v;for(int i=1;iscanf("%d %d",&u,&v);G[u].push_back(v);G[v].push_back(u);}dfs(1,0);ll res=0;for(int i=1;i<=n;i++){res=(res+ans[i])%mod;}printf("%lld\n",res);return 0;}
- 相关阅读:
【MATLAB图像处理实用案例详解(12)】——基于纹理特征的指纹识别方法
登录认证,登录校验
将nginx注册为Windows系统服务
手把手教你用Nodejs 实现一个简单的 Redis客户端
如何使用组件切换器做话题导航
你知道不同U盘在ARM+Linux下的读写速率吗?
【补题日记】[2022杭电暑期多校3]B-Boss Rush
从源码彻底理解 Prometheus/VictoriaMetrics 中的 relabel_configs/metric_relabel_configs 配置
【数据聚类】基于蝙蝠算法实现数据聚类附matlab代码
首次曝光 唯一全域最高等级背后的阿里云云原生安全全景图
- 原文地址:https://blog.csdn.net/qq_38515845/article/details/126724239
