-
Linux 内存管理 概述与深入理解
为什么要学习内存管理 (WHY)
关注越界访问,避免有类型错误或者算术溢出带来的内存问题
比如 char类型,在127+1后编程-128,导致越界访问或者擦写内存的问题。
避免内存泄漏
了解内存分配与释放机制,避免进行某些会导致内存泄漏的操作。
段错误
了解段错误发生的机制,淡定填坑。
Double Free
关注双重释放带来的后果,对free操作有敬畏之心。
内存碎片与性能
了解分配机制,避免内存碎片以及分配和释放带来的性能影响
性能瓶颈问题分析
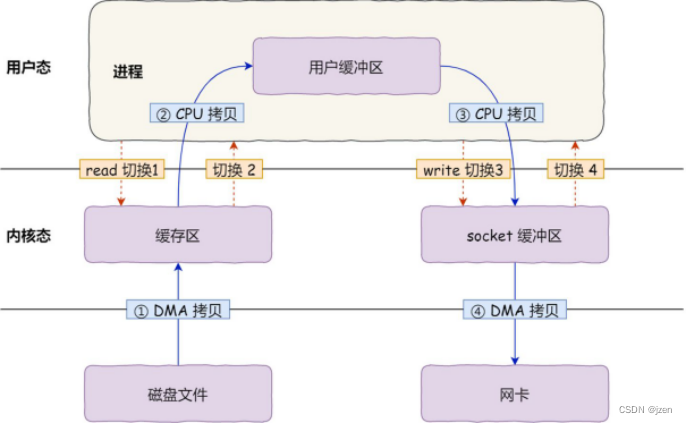
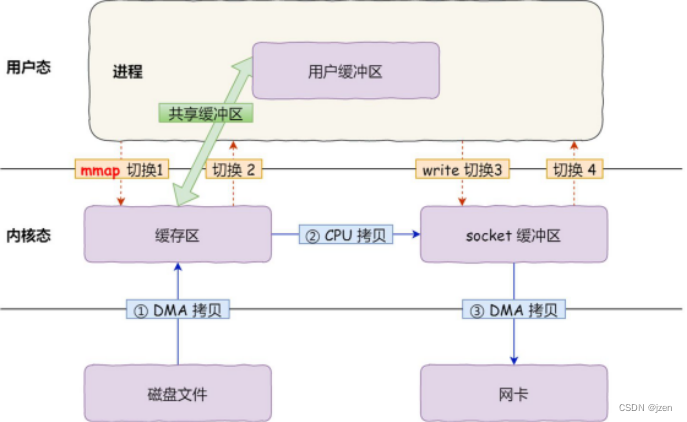
应用可能一条语句,内核就要执行上千条。正所谓“领导一句话,下属跑断腿” io read write发生了两次,用mmap只需要一次拷贝
- 如何处理CPU指令重排问题?
- 如何高效利用Cpu Cache?
- 如何利用CPU 分支预测(乱序执行)?
- 如何利用内存指令重排代替锁,实现无锁队列或同步问题?
内存映射几种类型
私有匿名映射
各进程不共享,fork之后,会进行写时复制
mmap(NULL, 1024, PORT_WRITE|PORT_READ, MAP_ANON|MAP_PRIVATE, -1, 0)共享匿名映射
各进程共享,会写时复制,常用进程间通信
mmap(NULL, 1024, PORT_WRITE|PORT_READ, MAP_ANON|MAP_SHARED, -1, 0)私有文件映射
各进程不共享,常见是私有的动态库加载
mmap(NULL, 1024, PORT_WRITE|PORT_READ, MAP_RPIVATE, fd, 0)共享文件映射
各进程共享,文件映射,传输
mmap(NULL, 1024, PORT_WRITE|PORT_READ, MAP_SHARED, fd, 0)查看命令:
cat /proc/<pid>/maps进程地址空间

简介
在Linux中,3G~4G的内存空间,划分给了内核,所有进程中该部分都是一样的。 地址由低到高,分别是代码段区域,数据段区域(Data, Bss)、堆区、栈区。其中栈区和堆区之间,存放着mmap开辟的内存映射区域。一般栈的生长方向是由高地址向低地址。而堆则是由低至高地址生长。堆区的顶部指针,称为brk地址。在内核空间中,将一部分虚拟地址空间线性映射至物理地址空间中,32位中一般为896M,这部分称为低端内存。剩下一部分常规可分配内存称为高端内存(还有一部分是DMA内存区)。
内存分配
从进程地址空间可以看出,用户分配小内存,则是在堆区线性扩展。向上增大或者向下减小区域,对于通过brk系统调用来完成。 另外,对于分配大内存,超过128K时,使用mmap系统调用来在堆区和栈区之间分配内存。
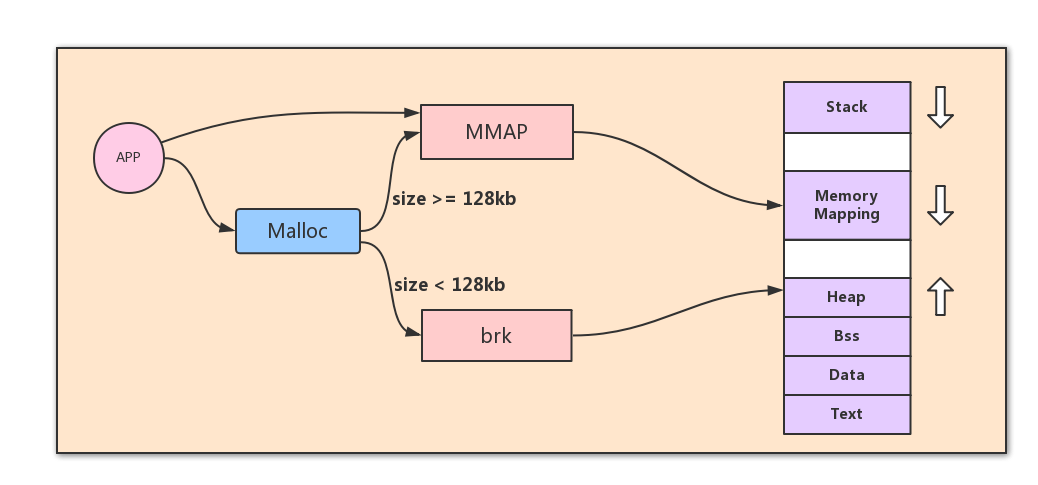
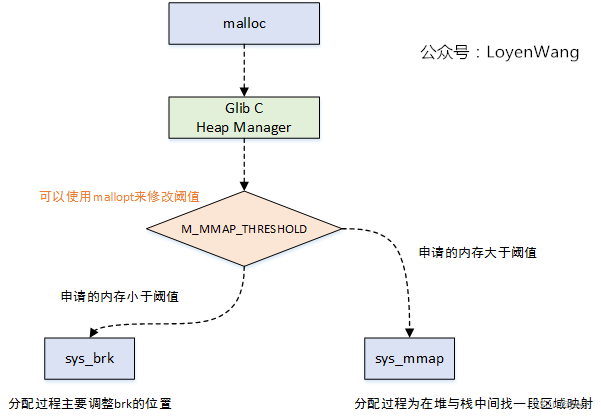
malloc工作原理
参考:linux - How does glibc malloc work? - Reverse Engineering Stack Exchange
malloc内存块组织方式

- 内存块头部
- {
- 块状态: 空闲,在使用;
- 前一块指针;
- 下一块指针;
- 内存块大小:
- }
glic malloc源码位置:malloc.c source code [glibc/malloc/malloc.c] - Woboq Code Browser
分配的特点是通过bins管理大小相近的内存。对于ptmalloc一般有fast bins, smaller bins, unsorted bins , larger bins, 四种类型。基本上每种bins的相邻间隔为8个字节,每个bin可能是单向链表或双向链表。对于fast bins一般是不大于64B, smaller bins <= 512B, larger bins > 512B 且128K。 unsorted bins没有规定具体大小,是一个临时管理链表可以存放临时合并的chunk。 对于大于128K之类的内存,会统一放在mmaped chunk 中,释放时直接归还给系统。
malloc分配的是虚拟地址,管理的是虚拟内存的分配。那么对于物理内存如何管理呢?物理内存的分配使用相关的有slab/slub/slob分配器,还有著名的buddy system伙伴系统。
Buddy System 伙伴系统
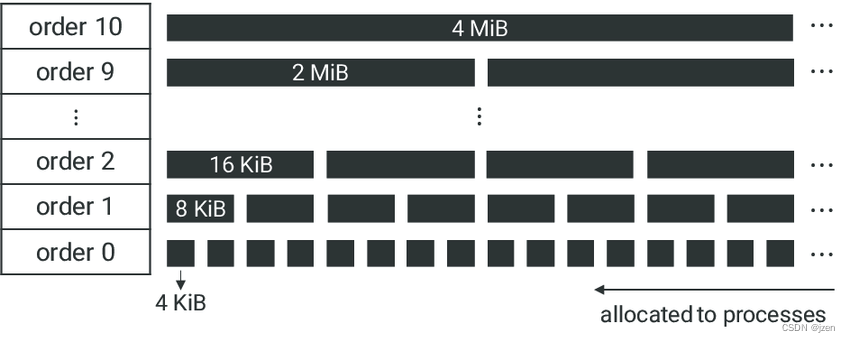
伙伴系统最小分配单位是页,并且以页的阶数分配。两个页快是否为伙伴的规则如下:
- 大小相同,物理连续的两个页块。
- n阶的页块,第一个页框编号为2^n的整数倍
- 两个相邻n阶页块合并成n+1阶之后,第一个页框编号也为2^(n+1)的整数倍
linux默认最大分配是10阶页块。在include/linux/mmzone.h 中设置。
伙伴系统的引入主要是用来解决内存外部碎片的问题。既然有内存外部碎片问题,那就有内存内部碎片的问题。外部碎片是指,没有分配的内存无法利用起来。内部碎片是指已经分配的内存只利用了部分,剩下的内存没有利用起来。而slab分配器的引入,解决了内存内部碎片的问题。
Slab 分配器
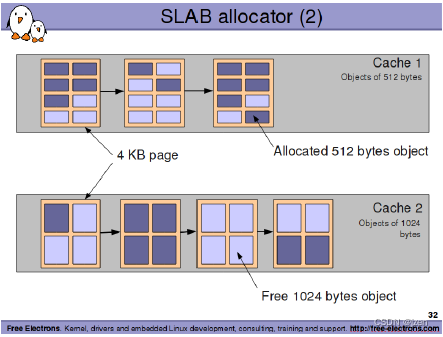
slab是按照对象的概念来缓冲的。比如上述如果一个对象是512个字节,那么一页就可以换成8个对象。slab的工作就是管理这个8个对象的分配和释放。这里slab管理的内存区为线性映射器区,即虚拟地址和物理地址是线性关系,对于linux一般这个区域大小为896M。常见的内核驱动的对象分配比如kmalloc,kmem_cache_alloc这些接口内部即使使用slab来管理。
虚拟地址与物理地址的映射关系

1. 为什么不直接一一映射?内存不足
2. 为什么采用了多级的映射?节约内存
3. 为什么有TLB块表?cache
4. 相同虚拟地址TLB如何区分?flush, ASID。
5. 不同进程访问共享的内核地址空间如何提高效率?nG , G标志
6. 为什么有写时复制?避免在fork时就拷贝大量的物理内存数据
7. mmu和cache哪个先访问?都可以,取决于TLB放在Cache之前还是之后。各有利弊
8. cache这么小如何缓存这么大的地址空间? (set) = (memory address) / (line size) % (number of sets)
(critical stride) = (number of sets) * (line size) = (total cache size) / (number of ways).
在linux上,查看虚拟地址与物理地址的关系:https://github.com/jethrogb/ptdump
- git clone https://github.com/jethrogb/ptdump
- cd ptdump/dump/linux/
- make
- sudo insmod ptdump.ko
- ls /proc/page*

运行测试app. test_virtual_address例程:
- 运行:test_virtual_address, 读取father.log并跟cat /proc/
/maps比较,发现申请的内存并没有物理地址。
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- struct Page {
- uint64_t address;
- uint64_t entry[512];
- };
- uint64_t get_phy_address(uint64_t entry)
- {
- static const uint64_t mask = (1LL<<63) | ((1<<12)-1);
- return entry & ~mask;
- }
- bool writable(uint64_t entry)
- {
- return (entry & (1 << 1)) != 0;
- }
- bool executable(uint64_t entry)
- {
- return (entry & (1LL << 63)) == 0;
- }
- bool user_mode(uint64_t entry)
- {
- return (entry & (1LL << 2)) != 0;
- }
- void print_entry(FILE *fp, int level, uint64_t entry, uint64_t virtual_address)
- {
- fprintf(fp, "%d\t0x%-16llx\t0x%-16llx\t%d\t%d\t%d\n", level, get_phy_address(entry), virtual_address,
- writable(entry),executable(entry),user_mode(entry));
- }
- void dump(FILE *fp, const Page*& page, int level, uint64_t virtual_address)
- {
- const Page *curr_page=page++;
- for (int i = 0; i < 512; i++) {
- const uint64_t entry = curr_page->entry[i];
- const uint64_t child_virtual_address = (virtual_address << 9) | i;
- if (level > 0) {
- if (entry & 1) {
- if (!(entry &(1 << 7))) {
- dump(fp, page, level-1, child_virtual_address);
- }else {
- print_entry(fp, level, entry, child_virtual_address << (level*9+12));
- }
- }
- } else {
- if (entry) {
- print_entry(fp, level, entry, child_virtual_address << 12);
- }
- }
- }
- }
- void dump_table(FILE *fp)
- {
- std::ifstream ifs("/proc/page_table_3", std::ios::binary);
- if (!ifs) {
- return ;
- }
- std::string content((std::istreambuf_iterator<char>(ifs)), std::istreambuf_iterator<char>());
- const Page *page = (const Page *)&content[0];
- const Page *end_page = (const Page *)(&content[0]+content.length());
- dump(fp, page, 3, 0);
- std::cout<< (const void *)end_page << "\t" << (const void *)page << std::endl;
- std::flush(std::cout);
- }
- int main(int argc, char **argv)
- {
- int cpu_index =0;
- if(argc >= 3) cpu_index=atoi(argv[2]);
- cpu_set_t set;
- CPU_ZERO(&set);
- CPU_SET(cpu_index, &set);
- sched_setaffinity(0, sizeof(set), &set);
- const size_t asize = 1024*1024*8;
- bool hugetable = false;
- bool do_fork = false;
- bool do_write = false;
- if (argc >= 2) {
- switch (argv[1][0])
- {
- case 'h': hugetable=true;do_write=true; break;
- case 'f': do_fork=true;do_write=true; break;
- case 'w': do_write=true; break;
- default:break;
- }
- }
- char *virtual_ptr = (char *)mmap(NULL, asize, PROT_READ|PROT_WRITE,
- MAP_ANONYMOUS|MAP_PRIVATE|(hugetable?MAP_HUGETLB:0), -1, 0);
- if (do_write) *virtual_ptr = '\0';
- FILE *fp = NULL;
- std::cout<< "father pid: " << getpid() << std::endl;
- if (do_fork) {
- pid_t pid = fork();
- if (pid == 0) {
- fp = fopen("child.log", "w");
- std::cout<< "child pid: " << getpid() << std::endl;
- }else {
- fp = fopen("father.log", "w");
- }
- } else {
- fp = fopen("father.log", "w");
- }
- fprintf(fp, "pid=%d map address: %p\n", getpid(), virtual_ptr);
- dump_table(fp);
- fclose(fp);
- while(true) {
- usleep(10000);
- }
- return 0;
- }
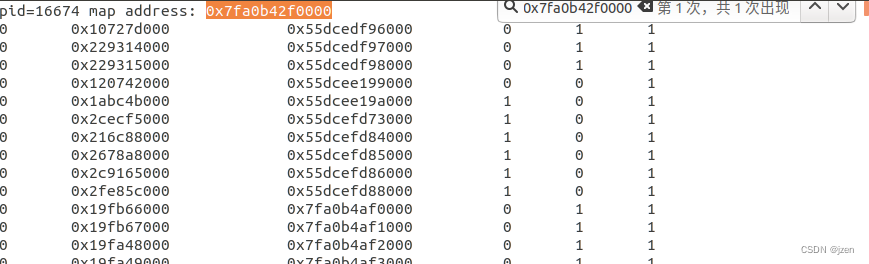
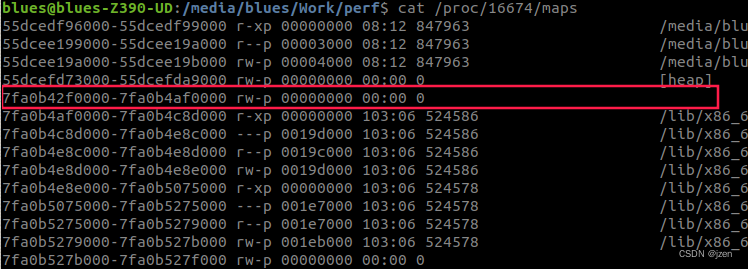
- 运行:test_virtual_address w, 读取father.log并跟cat /proc/
/maps比较,发现申请的内存有了物理地址。
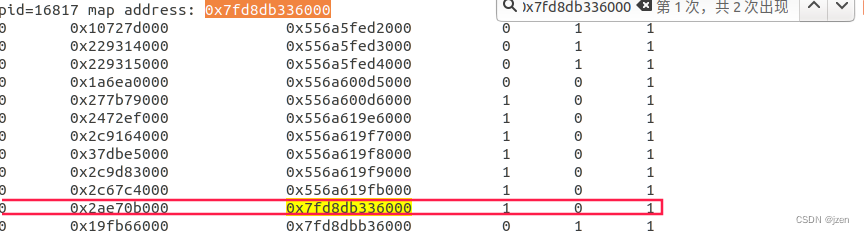

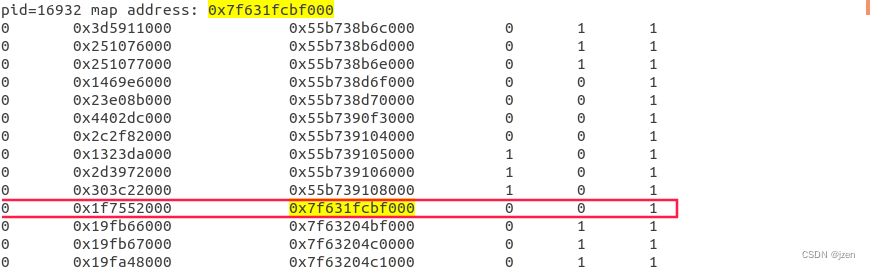
- 运行:test_virtual_address f, 读取father.log和child.log并跟cat /proc/
/maps比较,可以看到写时复制时的工作原理。注意看权限的不同。



普通文件read和文件映射mmap读取速度比较
- static void test_file_read()
- {
- FILE *fp = NULL;
- fp = fopen(FILE_NAME, "rb+");
- char *buff = (char *)malloc(1024);
- int len = 0;
- size_t sum = 0;
- size_t fsize;
- fseek(fp,0,SEEK_END);
- fsize=ftell(fp);
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 100; n++) {
- fseek(fp,0,SEEK_SET);
- while((len=fread(buff, 1,1024, fp)) >0 ) {
- sum +=len;
- }
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "test_file_read elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- printf("size=%ld\n", sum);
- fclose(fp);
- free(buff);
- }
- static void test_mmap_read()
- {
- FILE *fp = NULL;
- fp = fopen(FILE_NAME, "rb+");
- char *buff = (char *)malloc(1024);
- int len;
- size_t sum = 0;
- int readsize;
- size_t fsize;
- size_t size;
- fseek(fp,0,SEEK_END);
- fsize=ftell(fp);
- fseek(fp,0,SEEK_SET);
- size = fsize;
- fclose(fp);
- int ffd = open(FILE_NAME, O_RDWR|O_CREAT,0666);
- char *ptr=(char *)mmap(NULL, size, PROT_READ, MAP_SHARED, ffd, 0);
- close(ffd);
- char *readPtr = NULL;
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 100; n++) {
- readPtr = ptr;
- size = fsize;
- while(size){
- readsize = size > 1024 ? 1024 : size;
- memcpy(buff, readPtr, readsize);
- size -= readsize;
- readPtr += readsize;
- sum += 1024;
- }
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "test_mmap_read elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- free(buff);
- munmap(buff, fsize);
- printf("size=%ld\n", sum);
- }
运行test_mmap f 和test_mmap m
- ~/test_perf$ ./show_perf.sh ./test_mmap f
- run ./test_mmap f
- test_file_read elapsed milliseconds: 2245
- size=10485760000
- Performance counter stats for './test_mmap f':
- 74,743,510 cache-references # 36.454 M/sec
- 35,690,848 cache-misses # 47.751 % of all cache refs
- 8,925,687,804 instructions
- 1,367,859,141 branches # 667.137 M/sec
- 3,955,388 branch-misses # 0.29% of all branches
- 117 faults # 0.057 K/sec
- 219 context-switches # 0.107 K/sec
- 2050.342526 task-clock (msec) # 0.909 CPUs utilized
- 0 migrations # 0.000 K/sec
- 2.256351930 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_mmap m
- run ./test_mmap m
- test_mmap_read elapsed milliseconds: 489
- size=10485760000
- Performance counter stats for './test_mmap m':
- 62,951,973 cache-references # 127.169 M/sec
- 18,601,851 cache-misses # 29.549 % of all cache refs
- 1,502,833,265 instructions
- 147,082,645 branches # 297.121 M/sec
- 24,354 branch-misses # 0.02% of all branches
- 1,718 faults # 0.003 M/sec
- 8 context-switches # 0.016 K/sec
- 495.025615 task-clock (msec) # 0.995 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.497508855 seconds time elapsed
利用缓存命中提高性能
cache-misses
- 小结构体遍历: test_cache_miss s
- 大结构体遍历: test_cache_miss b
- 数组遍历: test_cache_miss a
- vector遍历: test_cache_miss v
- 按行顺序遍历: test_cache_miss a
- 按列顺序遍历:test_cache_miss i
- #include
- #include
- #include
- #include
- //#pragma pack(64)
- typedef struct {
- int cnt;
- std::string str;
- char resv[24];
- }algin_data_t __attribute__((aligned(64)));
- //#pragma pack()
- typedef struct {
- int cnt;
- std::string str;
- }small_data_t;
- typedef struct {
- int cnt;
- char str[128];
- }big_data_t;
- static void test_small_struct()
- {
- std::vector<small_data_t> dat(10000);
- int num=0;
- for (int i = 0; i < 10000; i++) {
- for (auto &e:dat) {
- e.cnt = num++;
- }
- }
- }
- static void test_algin_struct()
- {
- std::vector<algin_data_t> dat(10000);
- int num=0;
- for (int i = 0; i < 10000; i++) {
- for (auto &e:dat) {
- e.cnt = num++;
- }
- }
- }
- static void test_big_struct()
- {
- std::vector<big_data_t> dat(10000);
- int num=0;
- for (int i = 0; i < 10000; i++) {
- for (auto &e:dat) {
- e.cnt = num++;
- }
- }
- }
- static void test_vector_foreach()
- {
- std::vector
- int num=0;
- for (int cnt = 0; cnt < 100; cnt++) {
- for (int i = 0; i < 10000; i++) {
- for (int j = 0; j < 64; j++) {
- dat[i][j] = num++;
- }
- }
- }
- }
- static int dat_array[10000][64];
- static void test_array_foreach()
- {
- int num=0;
- for (int cnt = 0; cnt < 100; cnt++) {
- for (int i = 0; i < 10000; i++) {
- for (int j = 0; j < 64; j++) {
- dat_array[i][j] = num++;
- }
- }
- }
- }
- static void test_array_inv_foreach()
- {
- int num=0;
- for (int cnt = 0; cnt < 100; cnt++) {
- for (int i = 0; i < 64; i++) {
- for (int j = 0; j < 10000; j++) {
- dat_array[j][i] = num++;
- }
- }
- }
- }
- int main(int argc, char **argv)
- {
- if(argc <= 1) {
- printf("exe b or exe s\n");
- return 0;
- }
- printf("small=%d algin:%d\n", sizeof(small_data_t), sizeof(algin_data_t));
- switch (argv[1][0])
- {
- case 's': test_small_struct(); break;
- case 'b': test_big_struct(); break;
- case 'a': test_array_foreach(); break;
- case 'v': test_vector_foreach(); break;
- case 'i': test_array_inv_foreach(); break;
- case 'l': test_algin_struct(); break;
- default:break;
- }
- return 0;
- }
- ~/test_perf$ ./show_perf.sh ./test_branch_miss s
- run ./test_branch_miss s
- Performance counter stats for './test_branch_miss s':
- 35,237 cache-references # 1.035 M/sec
- 15,563 cache-misses # 44.167 % of all cache refs
- 127,110,597 instructions
- 31,639,756 branches # 929.747 M/sec
- 67,240 branch-misses # 0.21% of all branches
- 111 faults # 0.003 M/sec
- 0 context-switches # 0.000 K/sec
- 34.030495 task-clock (msec) # 0.969 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.035105508 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss b
- run ./test_branch_miss b
- Performance counter stats for './test_branch_miss b':
- 38,823 cache-references # 20.861 M/sec
- 12,309 cache-misses # 31.705 % of all cache refs
- 2,843,103 instructions
- 485,745 branches # 261.009 M/sec
- 15,449 branch-misses # 3.18% of all branches
- 102 faults # 0.055 M/sec
- 0 context-switches # 0.000 K/sec
- 1.861031 task-clock (msec) # 0.679 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.002742285 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss a
- run ./test_branch_miss a
- Performance counter stats for './test_branch_miss a':
- 45,370 cache-references # 0.627 M/sec
- 15,784 cache-misses # 34.790 % of all cache refs
- 121,528,996 instructions
- 30,681,381 branches # 423.988 M/sec
- 4,005,835 branch-misses # 13.06% of all branches
- 111 faults # 0.002 M/sec
- 2 context-switches # 0.028 K/sec
- 72.363755 task-clock (msec) # 0.975 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.074219125 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss v
- run ./test_branch_miss v
- Performance counter stats for './test_branch_miss v':
- 31,512 cache-references # 9.504 M/sec
- 12,034 cache-misses # 38.189 % of all cache refs
- 2,857,202 instructions
- 488,248 branches # 147.256 M/sec
- 14,946 branch-misses # 3.06% of all branches
- 103 faults # 0.031 M/sec
- 0 context-switches # 0.000 K/sec
- 3.315638 task-clock (msec) # 0.678 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.004890918 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss i
- run ./test_branch_miss i
- Performance counter stats for './test_branch_miss i':
- 31,792 cache-references # 13.768 M/sec
- 13,951 cache-misses # 43.882 % of all cache refs
- 2,864,321 instructions
- 489,395 branches # 211.938 M/sec
- 14,898 branch-misses # 3.04% of all branches
- 103 faults # 0.045 M/sec
- 0 context-switches # 0.000 K/sec
- 2.309145 task-clock (msec) # 0.704 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.003280504 seconds time elapsed
- #!/bin/sh
- echo "run $* "
- perf stat -B -e cache-references,cache-misses,instructions,branches,branch-misses,faults,context-switches,task-clock,migrations $*
- 热点数据紧凑合并 : ./test_together
- 热点数据分散合并 : ./test_together
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- static const int array_size = 1024;
- struct Dat_One{
- int buff_one[array_size];
- int buffer_two[array_size];
- };
- static Dat_One dat_one;
- struct Dat_Two{
- int buff_one;
- int buffer_two;
- };
- static Dat_Two dat_two[array_size];
- static int do_func(int dat)
- {
- static int sum = 0;
- sum++;
- return dat;
- }
- static void test1()
- {
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 10000; n++)
- for (int j = 0; j < array_size; j++) {
- dat_one.buffer_two[j] = do_func(dat_one.buff_one[j]);
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "big struct : elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- }
- static void test2()
- {
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 10000; n++)
- for (int j = 0; j < array_size; j++) {
- dat_two[j].buffer_two= do_func(dat_two[j].buff_one);
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "small struct : elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- }
- int main(int argc, char **argv)
- {
- int cpu_index =0;
- if(argc >= 3) cpu_index=atoi(argv[2]);
- cpu_set_t set;
- CPU_ZERO(&set);
- CPU_SET(cpu_index, &set);
- sched_setaffinity(0, sizeof(set), &set);
- test1();
- test2();
- return 0;
- }

- 增加无用数据减少cache冲突: test_Tmat 2 && test_Tmat 3
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- //(critical stride) = (number of sets)*(line size) = (total cache size) / (number of ways).
- //: (set) = (memory address) / (line size) % (number of sets)
- //cat /sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
- //cat /sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
- //answer : https://stackoverflow.com/questions/11413855/why-is-transposing-a-matrix-of-512x512-much-slower-than-transposing-a-matrix-of
- //sudo perf stat -e cache-misses ./test_Tmat 2
- #define MATSIZE_512 (4096UL) //L1 cache miss
- #define MATSIZE_513 (4096UL+16)
- static void transpose_mat512()
- {
- const size_t alloc_size = MATSIZE_512*MATSIZE_512;
- std::cout << alloc_size << std::endl;
- char *total_mem = (char *)malloc(alloc_size);
- assert(total_mem != nullptr);
- char (*mat_512)[MATSIZE_512] = (char (*)[MATSIZE_512])total_mem;
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 10; n++)
- for (int i = 1; i < MATSIZE_512; i++)
- for (int j = 0; j < i; j++) {
- int temp = mat_512[i][j];
- mat_512[i][j] = mat_512[j][i];
- mat_512[j][i] = temp;
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "mat512x512 elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- free(total_mem);
- }
- static void transpose_mat513()
- {
- const size_t alloc_size = MATSIZE_513*MATSIZE_513;
- char *total_mem = (char *)malloc(alloc_size);
- assert(total_mem != nullptr);
- char (*mat_513)[MATSIZE_513] = (char (*)[MATSIZE_513])total_mem;
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 10; n++)
- for (int i = 1; i < MATSIZE_513; i++)
- for (int j = 0; j < i; j++) {
- int temp = mat_513[i][j];
- mat_513[i][j] = mat_513[j][i];
- mat_513[j][i] = temp;
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "mat513x513 elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- free( total_mem);
- }
- int main(int argc, char **argv)
- {
- int cpu_index =0;
- if(argc >= 3) cpu_index=atoi(argv[2]);
- cpu_set_t set;
- CPU_ZERO(&set);
- CPU_SET(cpu_index, &set);
- sched_setaffinity(0, sizeof(set), &set);
- switch(argv[1][0]) {
- case '2' : transpose_mat512();break;
- case '3' : transpose_mat513();break;
- }
- return 0;
- }
- ~/test_perf$ ./show_perf.sh ./test_Tmat 2
- run ./test_Tmat 2
- 16777216
- mat512x512 elapsed milliseconds: 2721
- Performance counter stats for './test_Tmat 2':
- 99,403,455 cache-references # 36.646 M/sec
- 55,481,043 cache-misses # 55.814 % of all cache refs
- 4,075,121,270 instructions
- 252,150,019 branches # 92.958 M/sec
- 728,994 branch-misses # 0.29% of all branches
- 8,297 faults # 0.003 M/sec
- 20 context-switches # 0.007 K/sec
- 2712.515229 task-clock (msec) # 0.995 CPUs utilized
- 1 migrations # 0.000 K/sec
- 2.725778361 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_Tmat 3
- run ./test_Tmat 3
- mat513x513 elapsed milliseconds: 816
- Performance counter stats for './test_Tmat 3':
- 4,054,160 cache-references # 4.947 M/sec
- 2,411,165 cache-misses # 59.474 % of all cache refs
- 4,499,294,985 instructions
- 172,637,350 branches # 210.638 M/sec
- 73,871 branch-misses # 0.04% of all branches
- 8,360 faults # 0.010 M/sec
- 5 context-switches # 0.006 K/sec
- 819.594449 task-clock (msec) # 0.996 CPUs utilized
- 1 migrations # 0.001 K/sec
- 0.822494459 seconds time elapsed
branch-misses
- 随机数组遍历条件执行: test_branch_miss a
- 随机数组排序后遍历条件执行: test_branch_miss s
- likely和unlikely干预分支预测: test_branch_miss n ; test_branch_miss l
- #include
- #include
- #include
- #include
- #include
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
- static int dat_array[10000];
- static void test_array_foreach()
- {
- int num=0;
- for (int i = 0; i < 10000; i++) {
- dat_array[i]=rand()%512;
- }
- for (int cnt = 0; cnt < 1000; cnt++) {
- for (int i = 0; i < 10000; i++) {
- if( dat_array[i] > 256) {
- dat_array[i]=num++;
- }
- }
- }
- }
- volatile int test_a;
- static inline void test_no_use()
- {
- test_a = 1000;
- test_a += 1;
- test_a *= 10;
- test_a /= 3;
- test_a <<= 1;
- }
- static void test_array_sort_foreach()
- {
- int num=0;
- for (int i = 0; i < 10000; i++) {
- dat_array[i]=rand()%512;
- }
- std::sort(dat_array, dat_array+10000);
- for (int cnt = 0; cnt < 1000; cnt++) {
- for (int i = 0; i < 10000; i++) {
- if( dat_array[i] > 256) {
- dat_array[i]=num++;
- }
- }
- }
- }
- static void test_nolikely_foreach()
- {
- int num=0;
- for (int i = 0; i < 10000; i++) {
- dat_array[i]=rand()%512;
- }
- for (int cnt = 0; cnt < 10000; cnt++) {
- for (int i = 0; i < 10000; i++) {
- if( dat_array[i] > 50) {
- dat_array[i]=num;
- num+=2;
- test_no_use();
- }else {
- dat_array[i]=num;
- num++;
- }
- }
- }
- }
- static void test_likely_foreach()
- {
- int num=0;
- for (int i = 0; i < 100000; i++) {
- dat_array[i]=rand()%512;
- }
- for (int cnt = 0; cnt < 1000; cnt++) {
- for (int i = 0; i < 10000; i++) {
- if(likely( dat_array[i] > 50)) {
- dat_array[i]=num;
- num+=2;
- test_no_use();
- }else {
- dat_array[i]=num;
- num++;
- }
- }
- }
- }
- int main(int argc, char **argv)
- {
- if(argc <= 1) {
- printf("exe b or exe s\n");
- return 0;
- }
- switch (argv[1][0])
- {
- case 's': test_array_sort_foreach(); break;
- case 'a': test_array_foreach(); break;
- case 'n': test_nolikely_foreach(); break;
- case 'l': test_likely_foreach(); break;
- default:break;
- }
- return 0;
- }
- ~/test_perf$ ./show_perf.sh ./test_branch_miss a
- run ./test_branch_miss a
- Performance counter stats for './test_branch_miss a':
- 37,087 cache-references # 0.527 M/sec
- 13,650 cache-misses # 36.805 % of all cache refs
- 121,502,626 instructions
- 30,676,994 branches # 435.643 M/sec
- 4,005,535 branch-misses # 13.06% of all branches
- 110 faults # 0.002 M/sec
- 0 context-switches # 0.000 K/sec
- 70.417747 task-clock (msec) # 0.979 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.071961280 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss s
- run ./test_branch_miss s
- Performance counter stats for './test_branch_miss s':
- 34,839 cache-references # 0.856 M/sec
- 15,265 cache-misses # 43.816 % of all cache refs
- 127,107,931 instructions
- 31,638,325 branches # 777.609 M/sec
- 67,152 branch-misses # 0.21% of all branches
- 112 faults # 0.003 M/sec
- 0 context-switches # 0.000 K/sec
- 40.686661 task-clock (msec) # 0.966 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.042110582 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss n
- run ./test_branch_miss n
- Performance counter stats for './test_branch_miss n':
- 46,054 cache-references # 0.111 M/sec
- 20,105 cache-misses # 43.655 % of all cache refs
- 4,304,097,649 instructions
- 600,785,471 branches # 1452.078 M/sec
- 34,768 branch-misses # 0.01% of all branches
- 110 faults # 0.266 K/sec
- 7 context-switches # 0.017 K/sec
- 413.741881 task-clock (msec) # 0.994 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.416110095 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_branch_miss l
- run ./test_branch_miss l
- ./test_branch_miss: Segmentation fault
- Performance counter stats for './test_branch_miss l':
- 41,754 cache-references # 9.202 M/sec
- 15,556 cache-misses # 37.256 % of all cache refs
- 3,663,840 instructions
- 688,072 branches # 151.649 M/sec
- 16,502 branch-misses # 2.40% of all branches
- 109 faults # 0.024 M/sec
- 2 context-switches # 0.441 K/sec
- 4.537274 task-clock (msec) # 0.035 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.129464292 seconds time elapsed
利用cpu乱序执行与内存、指令重排提高性能
- cpu乱序执行 (无数据依赖遍历与有数据依赖遍历): test_reorder 4 ; test_reorder 5
- volatile原理: mfence
- 原子操作原理:
- cpu指令重排带来的多线程问题: test_reorder 1 ; test_reorder 2
- 内存重排带来的无锁编程问题
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #define barrier() __asm__ __volatile__("": : :"memory")
- #define mfence() __asm__ __volatile__("mfence": : :"memory")
- //https://en.cppreference.com/w/cpp/atomic/memory_order#Release-Consume_ordering
- static sem_t sem[2];
- static int X, Y;
- static int r1, r2;
- static void t1_run(void)
- {
- sem_wait(&sem[0]);
- X=1;
- //mfence();
- r1=Y;
- }
- static void t2_run(void)
- {
- sem_wait(&sem[1]);
- Y=1;
- //mfence();
- r2=X;
- }
- static void test_order_once()
- {
- static int num = 0;
- static int round = 0;
- round++;
- X = 0;
- Y = 0;
- std::thread t1(t1_run);
- std::thread t2(t2_run);
- sem_post(&sem[0]);
- sem_post(&sem[1]);
- t1.join();
- t2.join();
- if ((r1 == 0) && (r2 == 0)) {
- num++;
- printf("reorder: %d, iterator: %d\n", num, round);
- }
- }
- /
- static std::atomic<int> aX;
- static std::atomic<int> aY;
- static int err_num = 0;
- static void load_aY_to_aX()
- {
- sem_wait(&sem[0]);
- r1 = aY.load(std::memory_order_relaxed);
- aX.store(r1, std::memory_order_relaxed);
- }
- static void load_aX_then_store_aY()
- {
- sem_wait(&sem[1]);
- r2 = aX.load(std::memory_order_relaxed);
- aY.store(42, std::memory_order_relaxed);
- }
- static void test_order_relaxed_once()
- {
- static int num = 0;
- static int round = 0;
- round++;
- aX = 0;
- aY = 0;
- std::thread t1(load_aY_to_aX);
- std::thread t2(load_aX_then_store_aY);
- sem_post(&sem[0]);
- sem_post(&sem[1]);
- t1.join();
- t2.join();
- if ((r1 == 42) && (r2 ==42)) {
- printf("reorder: %d, iterator: %d\n", ++num, round);
- }
- }
- /
- static std::atomic
- static int data;
- static void producer()
- {
- std::string* p = new std::string("Hello");
- data = 42;
- ptr.store(p, std::memory_order_release);
- }
- static void consumer()
- {
- std::string* p2;
- while (!(p2 = ptr.load(std::memory_order_acquire)));
- assert(*p2 == "Hello"); // never fires
- assert(data == 42); // never fires
- }
- static void relese_acquire_test()
- {
- std::thread t1(producer);
- std::thread t2(consumer);
- t1.join();
- t2.join();
- }
- static void test_auto_add()
- {
- const int size = 1000;
- float list[size], sum = 0; int i;
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 100000; n++)
- for (i = 0; i < size; i++) sum += list[i];
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "test_auto_add elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- }
- static void test_dependency_add()
- {
- const int size = 1000;
- float list[size], sum1 = 0, sum2 = 0;
- int i;
- auto start = std::chrono::high_resolution_clock::now();
- for (int n = 0; n < 100000; n++) {
- for (i = 0; i < size; i+=2) {
- sum1 += list[i];
- sum2 += list[i+1];
- }
- sum1 += sum2;
- }
- auto end = std::chrono::high_resolution_clock::now();
- size_t use_time = std::chrono::duration_cast
- std::cout << "test_auto_add elapsed milliseconds: " << use_time << std::endl;
- std::flush(std::cout);
- }
- int main(int argc, char **argv)
- {
- sem_init(&sem[0], 0, 0);
- sem_init(&sem[1], 0, 0);
- switch(argv[1][0]) {
- case '1' : while(true) test_order_once(); break;
- case '2' : while(true) test_order_relaxed_once();;break;
- case '3' : while(true) relese_acquire_test();;break;
- case '4' : test_auto_add();;break;
- case '5' : test_dependency_add();;break;
- }
- return 0;
- }
- ~/test_perf$ ./show_perf.sh ./test_reorder 4
- run ./test_reorder 4
- test_auto_add elapsed milliseconds: 310
- Performance counter stats for './test_reorder 4':
- 41,274 cache-references # 0.132 M/sec
- 21,390 cache-misses # 51.824 % of all cache refs
- 1,004,169,232 instructions
- 200,905,980 branches # 640.344 M/sec
- 118,085 branch-misses # 0.06% of all branches
- 113 faults # 0.360 K/sec
- 0 context-switches # 0.000 K/sec
- 313.746779 task-clock (msec) # 0.995 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.315352555 seconds time elapsed
- ~/test_perf$ ./show_perf.sh ./test_reorder 5
- run ./test_reorder 5
- test_auto_add elapsed milliseconds: 159
- Performance counter stats for './test_reorder 5':
- 38,816 cache-references # 0.238 M/sec
- 18,949 cache-misses # 48.817 % of all cache refs
- 854,311,607 instructions
- 100,877,665 branches # 617.780 M/sec
- 117,673 branch-misses # 0.12% of all branches
- 113 faults # 0.692 K/sec
- 0 context-switches # 0.000 K/sec
- 163.290585 task-clock (msec) # 0.992 CPUs utilized
- 0 migrations # 0.000 K/sec
- 0.164629185 seconds time elapsed
至于以上实验为什么会有这些测试结果。后续补上 ,先上班~~~~~~
-
相关阅读:
CNN - nn.Conv1d使用
数据库1= =
十、【Vue-Router】两个新生命周期钩子 activated/deactivated
JSONObject和JSONArray的基本使用
单应用多语言切换(语言国际化)
攻防世界安卓逆向练习
python+django+mysql鲜花水果购物网站毕业设计毕设开题报告
clickhouse技术总结待续
跨浏览器测试需要进行的测试与评估
【算法专题】双指针
- 原文地址:https://blog.csdn.net/sdewenking/article/details/126655606
